- The paper introduces an RL-optimized module that extracts explicit, aspect-oriented preference memory to improve product reranking performance.
- It demonstrates that decoupling query inputs from structured memory extraction yields up to +10.61 accuracy points over traditional concatenation methods.
- The approach enhances scalability, interpretability, and cross-domain transfer, setting a new standard for personalized e-commerce systems.
MemRerank: Preference Memory for Personalized Product Reranking
Motivation
Current LLM-based shopping agents and agentic RS architectures attempt to leverage long user interaction histories in the pursuit of personalization. However, the naïve approach of concatenating raw purchase histories into LLM prompts leads to increased noise, context-window saturation, and suboptimal performance due to the lack of structure and relevancy bias. Existing memory-augmented strategies from general-purpose LLM agent frameworks are not directly optimized for preference signal distillation pertinent to ranking and decision tasks in e-commerce. There is a clear gap: developing explicit, compact, and highly actionable preference memory to support downstream LLM-based reranking under realistic e-commerce constraints.
MemRerank introduces a dedicated preference memory extraction module. The extractor ingests a user's purchase history and outputs structured, query-independent shopping preferences tailored for both within-category and cross-category behavioral modeling. This memory is injected into the downstream reranking pipeline, enabling the LLM reranker to leverage abstracted user preference signals alongside the current query and candidate products.
Preference memory extraction is decoupled from query input, focusing on globally salient and repetitive patterns (e.g., brand affinities, budget, specific feature or usage priorities) as opposed to transient session events. Critical design choices involve memory structure (aspect-oriented, actionable, evidence-backed fields) and the separation of within-category and cross-category histories to balance fine-grained and global preference modeling.
RL-based Memory Optimization
The core innovation is the RL-style training of the LLM memory extractor via Guided Reward Policy Optimization (GRPO). The reward function tightly binds extractor improvements to downstream reranking success in the 1-in-5 selection protocol, integrating both:
- Format reward: verifying the syntactic and structural integrity of the generated memory
- Reranking reward: assessing the impact of the memory on 1-in-5 reranker accuracy, averaged over multiple rollouts.
This approach obviates the need for expensive, manually annotated gold preference memory and ensures the alignment of memory representations with the most discriminative and reusable preference signals for personalized ranking.
Benchmark Construction
A new benchmark is established by integrating Amazon-Review-2023 and Amazon-C4, yielding high-coverage purchase histories, LLM-curated product search queries, and rigorously sampled candidate pools with positive and hard negative judgments. The 1-in-5 selection paradigm is adopted for controlled setwise reranking, aligning evaluation granularity with operational ranking workflows in both research and industry.
Category-agnostic and category-targeted (mainly Electronics) setups are supported, with precise measurement of within-category and cross-category history utilization.
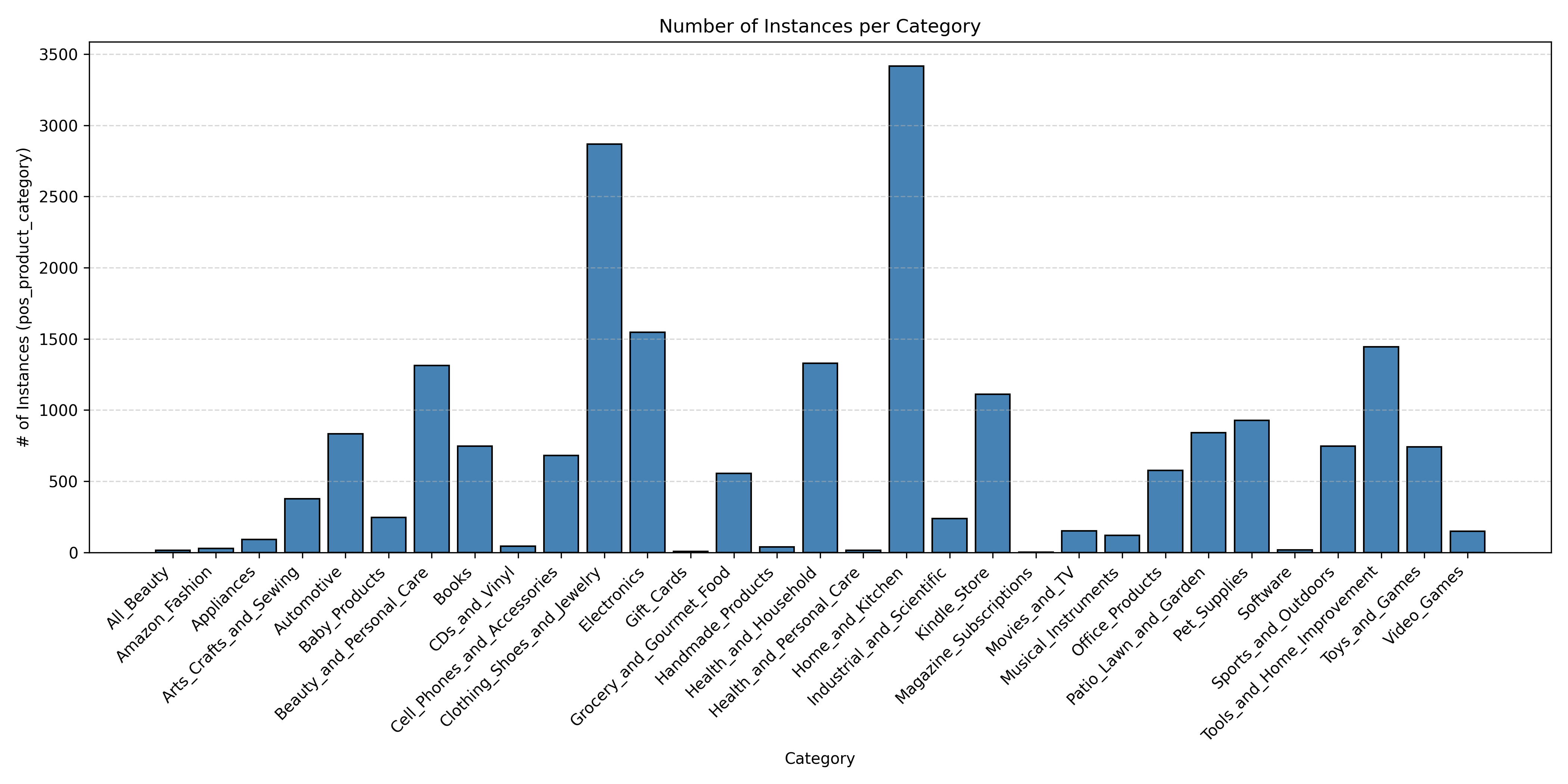
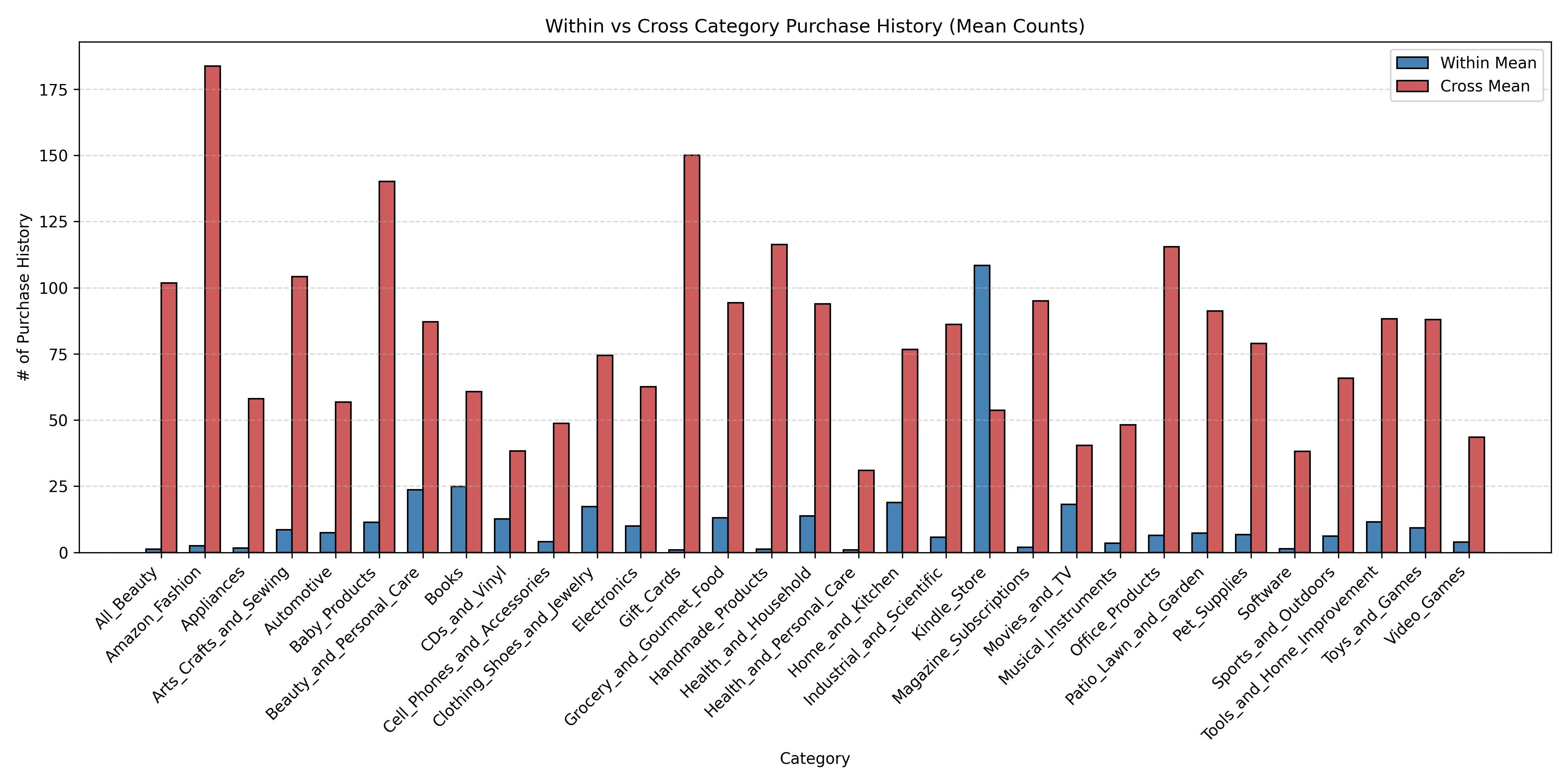
Figure 1: Distribution of positive test instances per category, demonstrating evaluation focus and data imbalance.
Empirical Evaluation
MemRerank is systematically compared against several baselines, including raw product context augmentation, off-the-shelf LLM-extracted memories, and leading external memory agents (MR.Rec, Mem0). Multiple reranking backends (GPT-4.1-mini, o4-mini) and detailed ablations on memory structure, prompt design, and context length are investigated.
Key findings include:
- Substantial accuracy gains: MemRerank yields up to +10.61 accuracy points (absolute) over the no-memory baseline and consistently dominates both direct history concat and non-RL memory-extraction pipelines.
- Memory quality is critical: Off-the-shelf extractors sometimes degrade reranking performance compared to no explicit memory. RL-tuned extraction is essential.
- Prompt structure matters: An intermediate, aspect-guided but flexible prompt with explicit evidence grounding (v3) outperforms rigid (checklist) or unconstrained formulations. Alignment of aspect discovery and concise, actionable summaries is essential.
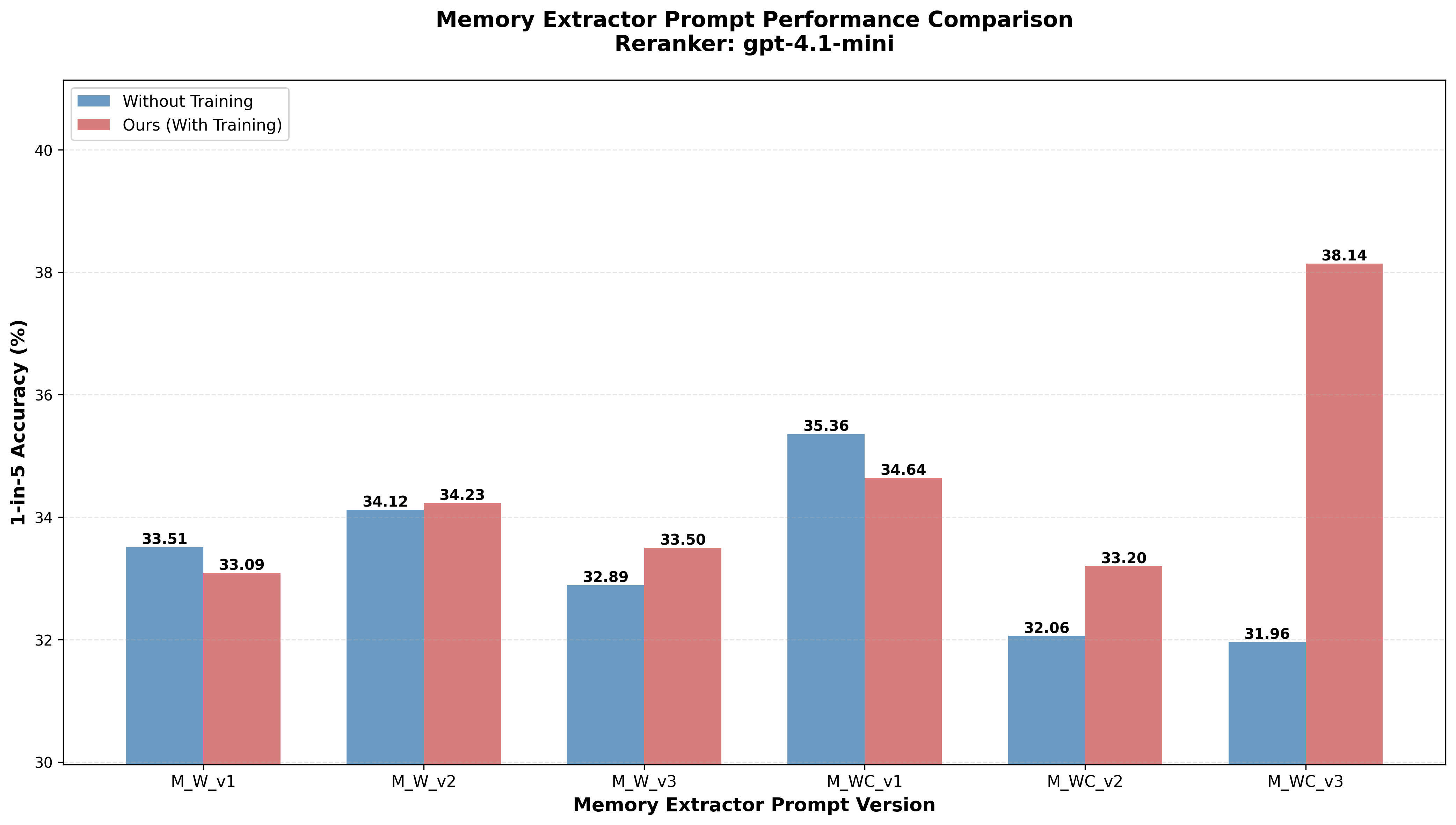
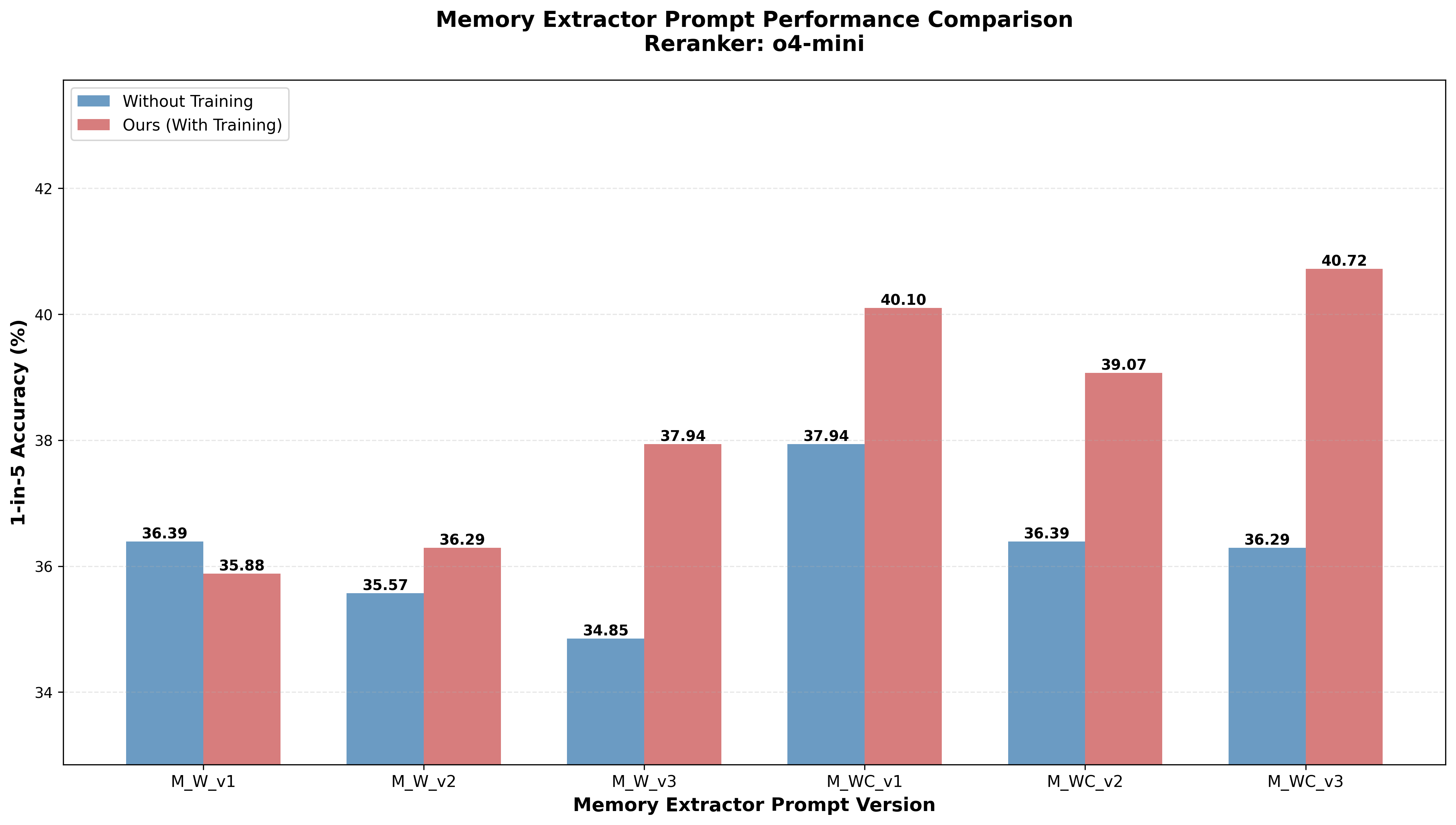
Figure 2: Comparison of different memory extraction prompt variants and effect on downstream reranking accuracy.
- "Think" tags synergize with memory: Forcing the reranker to perform explicit stepwise reasoning based on preference memory provides additional gains, especially when the memory is highly structured and RL-aligned.
- Naïve history scaling is nonmonotonic: Simply providing more context does not always help and often introduces detrimental noise, particularly for weaker models.
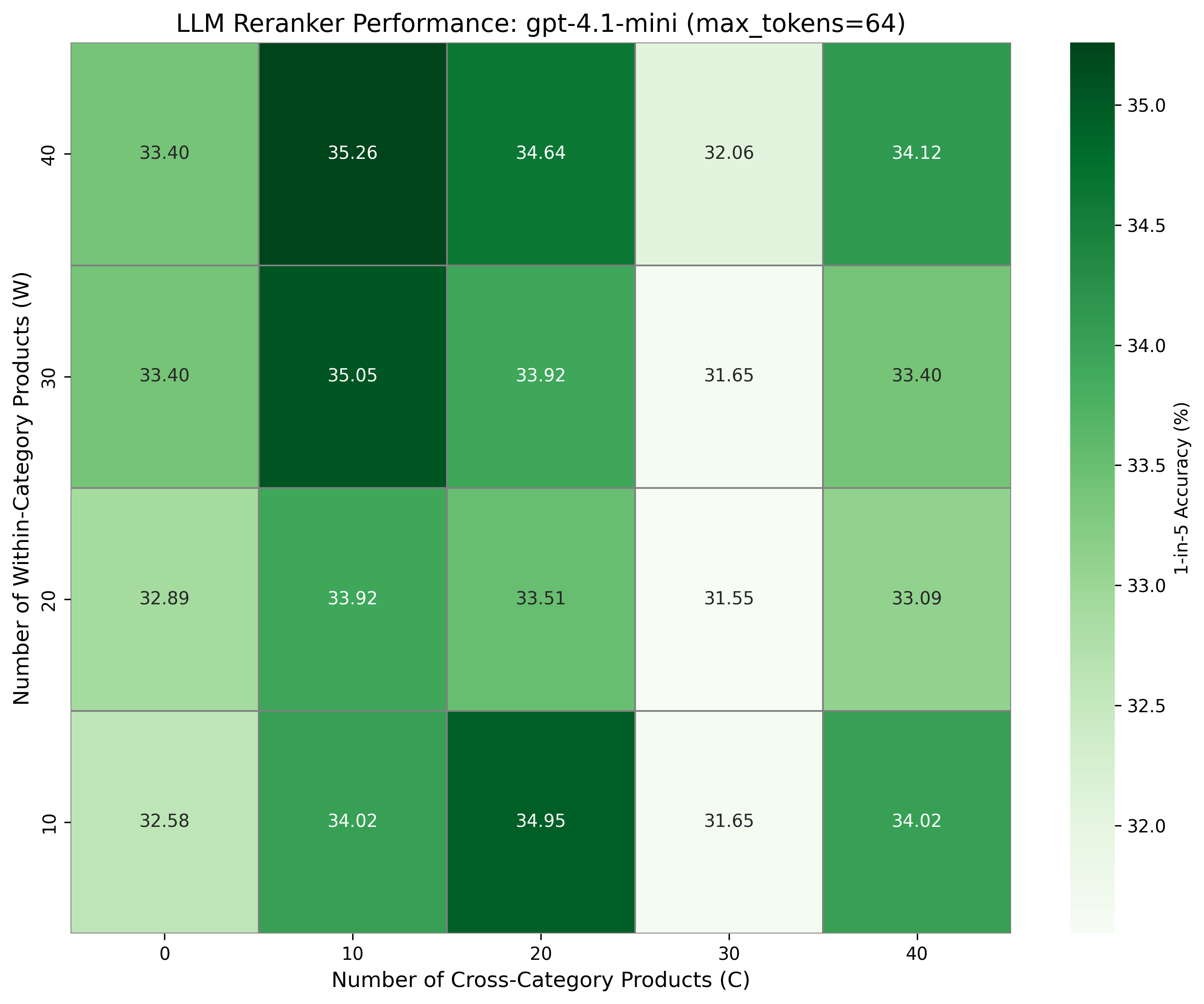
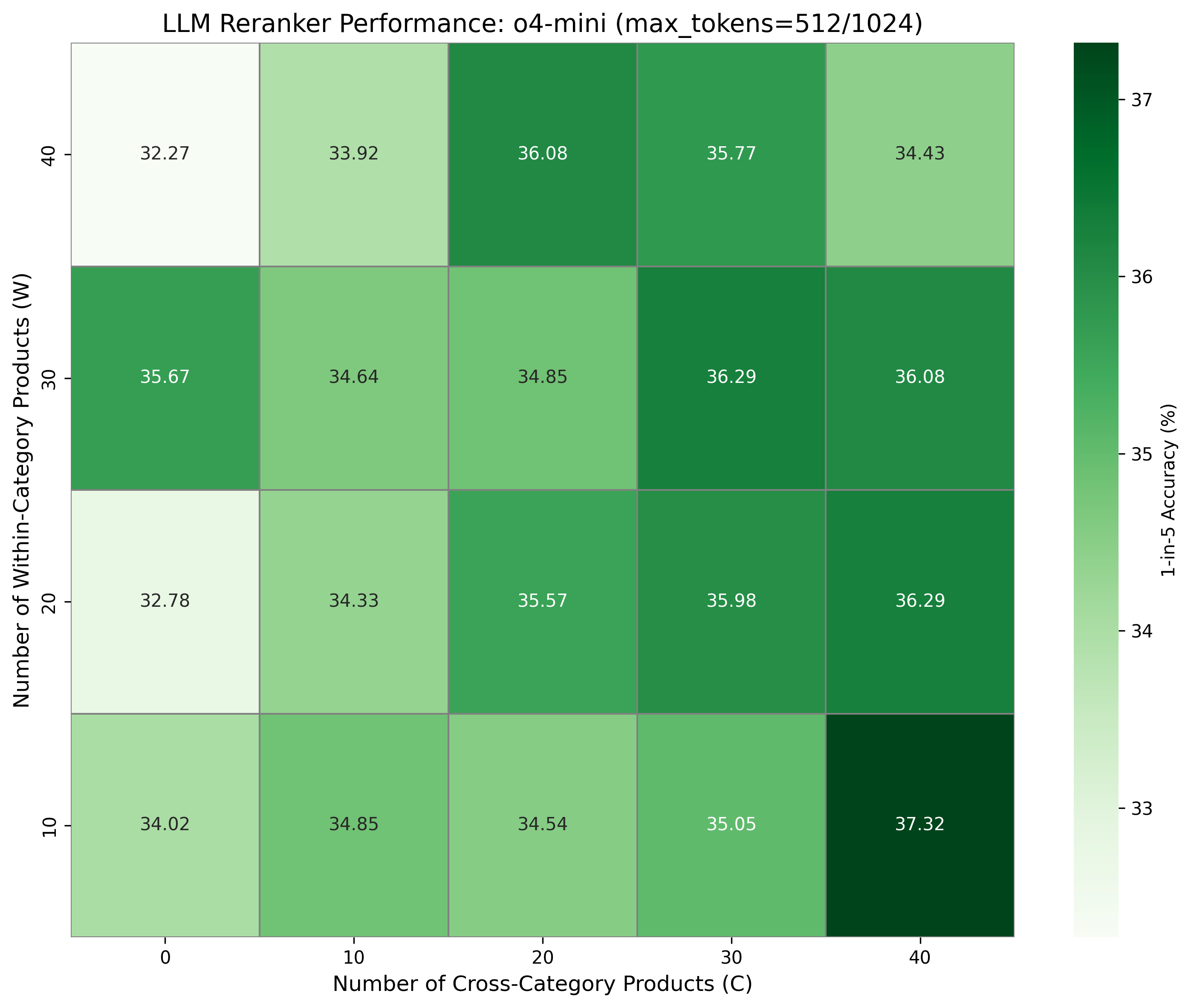
Figure 3: Reranker accuracy as a function of provided within-category and cross-category purchase history lengths.
Methodological Implications
The introduction of query-independent, explicitly RL-tuned preference memory establishes a new standard for agentic personalization pipelines, where memory summarization is not an auxiliary afterthought but a targeted adaptation step optimized for downstream selection. The framework demonstrates that generic memory-augmented approaches are insufficient for product reranking—instead, alignment through policy optimization delivers actionable memories that maximize utility. RL reward design directly tied to ultimate ranking objectives is notably more effective than heuristic or static criterion.
Practical and Theoretical Implications
- Scalability and efficiency: RL-trained memory extractors generalize to arbitrary-length histories, reducing LLM context window waste and inference cost compared to full-history approaches or brute-force context packing.
- Interpretability: The compact, aspect-structured, evidence-aligned summaries offer a natural interface for user inspection, debugging, or downstream editing, promoting transparency and diagnosability.
- Compositionality and transfer: Decoupling preference memory extraction opens the possibility of cross-task transfer—memory modules extracted in one context (e.g., browsing, conversation) are reusable in multiple downstream ranking or dialogue scenarios.
- Generalization limits: The present work restricts evaluation to the Electronics category and shortlists; scaling to large-candidate pools and multi-domain generalization remains an outstanding challenge area.
Future Directions
Immediate extensions include:
- Scaling to broader product verticals and exploiting denser behavioral signals (e.g., temporal dynamics, review content, multimodal evidence).
- Integrating memory extraction with online/interactive user feedback, supporting memory editing and real-time adaptation.
- Developing compositional memory architectures with hierarchical or multimodal blocks for richer personalized reasoning.
- Applying similar RL-based memory distillation pipelines for other agentic tasks (e.g., conversational assistants, VLM-based buying guides).
Conclusion
MemRerank advances the state of the art in personalized product reranking by formalizing explicit, RL-optimized preference memory as a foundational primitive. The demonstration that such memory—rather than raw or heuristically distilled context—is the most effective information bottleneck for personalized LLM-based reranking has strong implications for both agentic system design and theoretical understanding of preference abstraction in LLMs. The experimental results establish the critical role of memory structure, prompt engineering, and policy-aligned training in driving real gains in agentic personalization performance.
Figure 1: Category-level distribution of positive instances in the evaluation split, supporting insights on data allocation.

