- The paper proposes Reasoning Memory, a procedural retrieval framework that extracts and reuses over 32M subroutine pairs from reasoning traces.
- It demonstrates robust improvements in math, science, and code tasks, achieving up to 19.2% accuracy gains and outperforming standard RAG methods.
- The methodology emphasizes aligning retrieved procedural subroutines with active subgoals, paving the way for meta-learning in multi-step reasoning.
Procedural Knowledge Datastores for Scalable LLM Reasoning
Introduction and Motivation
Current approaches to test-time scaling in reasoning-tuned LLMs (e.g., DeepSeek R1, QwQ, OpenAI’s o1 series) focus almost exclusively on token budget allocation for extending stepwise “thinking,” with little to no systematic mechanism for reusing procedural knowledge extracted from prior reasoning traces. While standard retrieval-augmented generation (RAG) pipelines have seen significant utility in factual knowledge tasks, their transfer to reasoning models is limited. This is due to the inherently procedural and compositional nature of multi-step reasoning, particularly in math, science, and code domains. Existing RAG systems typically retrieve factual documents and background context, which is only weakly aligned with the local trajectory and subproblem decomposition required for stepwise reasoning.
The paper "Procedural Knowledge at Scale Improves Reasoning" (2604.01348) addresses these persistent limitations by introducing Reasoning Memory, a large-scale procedural RAG framework. The primary innovation is the extraction, indexing, and test-time reuse of over 32M compact and self-contained procedural subroutines derived from public reasoning trajectories. This work demonstrates robust accuracy improvements over both document-level and template-based RAG, as well as strong baselines for compute-matched test-time scaling. Gains are explained by improved alignment of retrieved procedures with the active subgoal sequence within long reasoning traces.
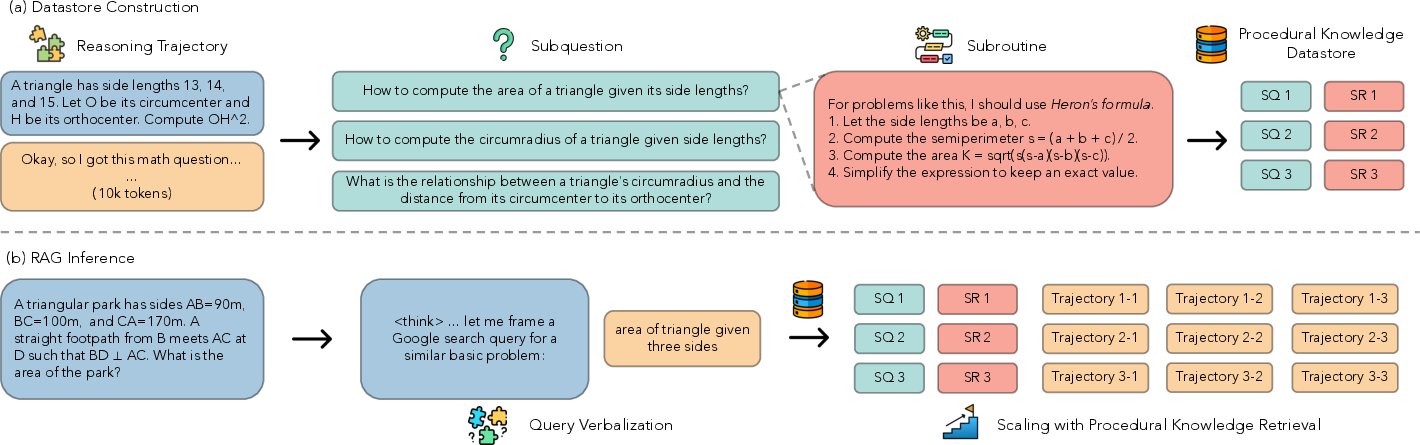
Figure 1: Illustration of the Reasoning Memory framework. (a) Procedural knowledge is extracted from public reasoning trajectories into a large-scale datastore; (b) at inference, models retrieve contextually aligned subroutines to guide and scale reasoning through in-thought procedural retrieval.
Limitations of Standard Document RAG and Empirical Diagnosis
Despite the appeal of document-level RAG for enhancing factual recall, empirical analysis demonstrates that reasoning models benefit minimally from retrieved general documents. Applying CompactDS-style RAG to instruction-tuned models yields modest, reliable improvements on challenging benchmarks (AIME, GPQA-Diamond, LiveCodeBench). However, the same retrieval-augmented setup provides either marginal gains or regresses accuracy for state-of-the-art reasoning models, despite their baseline outperformance in zero-retrieval settings.
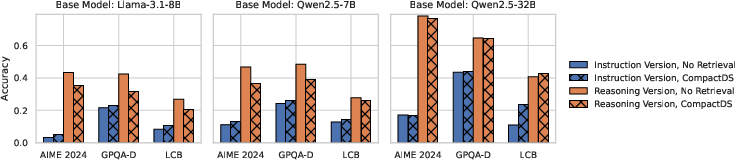
Figure 2: Standard document RAG yields positive gains for instruction-tuned models, but little to negative impact on reasoning models, highlighting poor contextual alignment.
To understand this result, controlled knowledge injection with synthesized, problem-matched paragraphs reveals that procedural guidance is consistently more effective than factual background when injected into the thought stream. This motivates the design of retrieval at the level of problem-aligned procedures rather than documents.
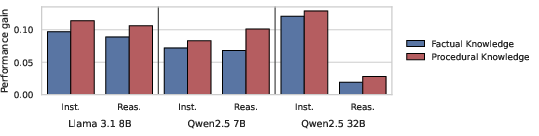
Figure 3: Relative performance gains from synthesized knowledge, showing consistently stronger effect for procedural relative to factual knowledge across tasks and model families.
Reasoning Memory: Large-Scale Procedural Datastore and Retrieval Pipeline
Datastore Construction
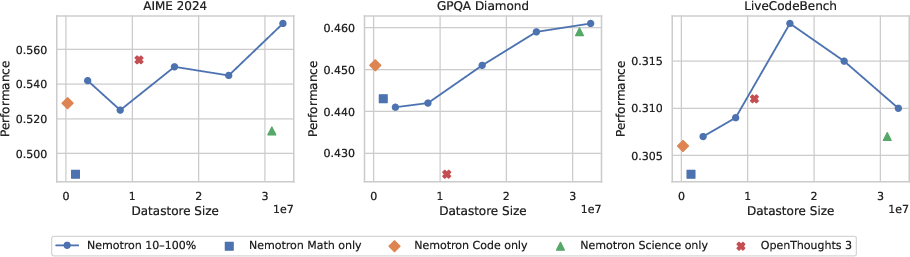
The core of Reasoning Memory is the creation of a datastore comprising 32 million (subquestion, subroutine) pairs. Publicly released reasoning corpora (e.g., Nemotron V1) are decomposed using a two-stage prompting pipeline. Each step in a problem-solving trajectory is mapped to a concise, generalizable subquestion, and a corresponding high-level procedural outline abstracted from specific calculations or failed branches. This decomposition increases relevance and controllability during retrieval and in-context use.
In-Thought Active Retrieval
During inference, models are prompted to verbalize the current subgoal in a concise, search-oriented format mid-“thought,” generating a query for the datastore. A small set of top-k retrieved procedural subroutines is then injected directly into the reasoning stream. This procedure maintains alignment with the ongoing chain-of-thought and allows the model to integrate procedural priors as needed; reasoning is thus driven by contextual guidance rather than generic external content.
Test-Time Scaling and Trajectory Selection
As token budget or sampling budget (m) increases, Reasoning Memory scales by exploring diverse retrieved subroutines rather than allocating all budget to extending a single chain. Multiple trajectories are generated per subroutine, and a two-stage length-based filtering heuristic (preferring shorter, more confident chains) is applied to select the most promising answers.
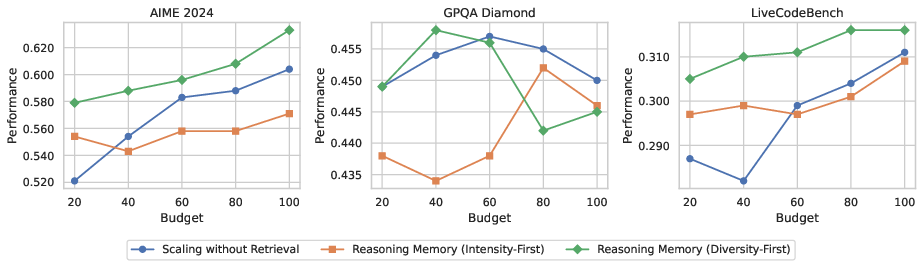
Figure 4: Performance scaling as a function of inference (sampling) budget, comparing Reasoning Memory and retrieval-free length scaling baselines. Gains from procedural retrieval persist and amplify with increased compute.
Experimental Results
Extensive experiments across math (AIME 2024/2025, MATH500), science (GPQA-Diamond), and code (LiveCodeBench) demonstrate that Reasoning Memory delivers:
Ablation Studies
Ablations confirm the necessity of both subroutine-level decomposition and self-verbalized active queries. Indexing by original question rather than subgoal, or bypassing query generation, consistently degrades performance. Generation of the datastore with smaller teacher models yields only minor performance drop, indicating that most procedural knowledge derives from the source trajectory’s diversity. Evaluation of multiple uncertainty criteria for trajectory selection finds simple trace length is a robust proxy for selecting confident solutions across domains.
Implications and Future Directions
The results demonstrate that test-time scaling in reasoning models is no longer just about increasing "chain-of-thought" length or brute-force sample diversity. The explicit surfacing, parameterization, and retrieval of procedural priors leads to substantial improvements in complex multi-step tasks across diverse domains. The methodology provides an alternative to scaling model parameters or post-training over larger corpora by accumulating reusable procedural knowledge as external memory.
From a theoretical perspective, this points toward the operationalization of problem-solving as a form of meta-learning, where trajectory decomposition and retrieval act as a mechanism for compositional generalization. These findings open pathways for future work in:
- Dynamic or active procedural knowledge accumulation: Continuously updating the procedural memory with high-value subroutines encountered during deployment.
- Self-improving retrieval: Training end-to-end retrievers specialized to align with the intermediate subgoals of the current thought state.
- Domain-expansion and cross-modal procedural knowledge: Extending this pipeline to multimodal or cross-lingual procedural knowledge, enabling broader generalization.
- Integration with reinforcement learning: Utilizing reward signals from successful/failed retrievals to refine both datastore composition and trajectory selection mechanisms.
Conclusion
Reasoning Memory demonstrates that large-scale, explicit procedural knowledge retrieval is essential for generalization and sample-efficient reasoning in LLMs. Retrieval and in-thought reuse of stepwise subroutines yield consistent, significant improvements across challenging reasoning-intensive benchmarks. The paradigm advances RAG from factoid augmentation to the compositional reuse of procedural strategies, constituting a practical framework for scalable, adaptive, and data-efficient reasoning in next-generation LLMs.
[Full paper: (2604.01348)]