- The paper introduces a taxonomy for multi-agent video recommenders that modularizes system components to overcome scalability and alignment challenges.
- It demonstrates how specialized agents for perception, reasoning, and feedback collaboratively address the multimodal complexity and dynamic user preferences in video recommendations.
- The paper identifies open challenges in scalability, multimodal grounding, and evaluation alignment, paving the way for hybrid RL-LLM architectures and lifelong personalization.
Multi-Agent Video Recommenders: Taxonomy, Architectures, and Research Frontiers
Introduction
The paper "Multi-Agent Video Recommenders: Evolution, Patterns, and Open Challenges" (2604.02211) provides a comprehensive survey of the recent paradigm shift in video recommender systems (RS) from monolithic, single-objective models to compositional, multi-agent architectures. These systems leverage specialization and collaboration among agents to address the intrinsic complexity of video recommendation—especially in the presence of high-dimensional multimodal content and volatile user preferences—an area where single-model approaches reach clear scalability and alignment limits. The survey establishes a taxonomy of collaborative patterns, integrates insights from multi-agent reinforcement learning (MARL), LLM-based agentic systems, and multimodal foundation models, and identifies persistent challenges and future research vectors for this emerging class of recommender systems.
The Motivation for Multi-Agent Video Recommenders
Traditional video recommenders based on collaborative or content-based filtering, deep sequential models, and single-agent RL, operate under static optimization objectives—often maximizing engagement metrics such as click-through rate or watch time. These pipelines, while efficient, fail to express or reconcile multi-objective tradeoffs like diversity, fairness, and explainability, and are constrained by the context window limitations of LLMs when applied to high-dimensional modalities such as video.
The intrinsic complexity of video recommendation arises from the "modality gap": the inability of a single foundation model to perform reasoning over a user's full history of raw, multimodal video interactions. Multi-agent decompositions resolve this by modularizing the system into specialized agents: perception agents compress video content, reasoning agents operate over compact semantic representations, and feedback agents adapt based on user and system signals. This modular, distributed cognition bypasses context length bottlenecks and enables dynamic adaptation, explainability, and system robustness.
Collaborative Multi-Agent Patterns for Video Recommendation
The paper proposes a taxonomy of multi-agent video recommender patterns, grouped by their coordination and collaboration paradigms. Each pattern addresses distinct challenges in scaling, alignment, and computation.
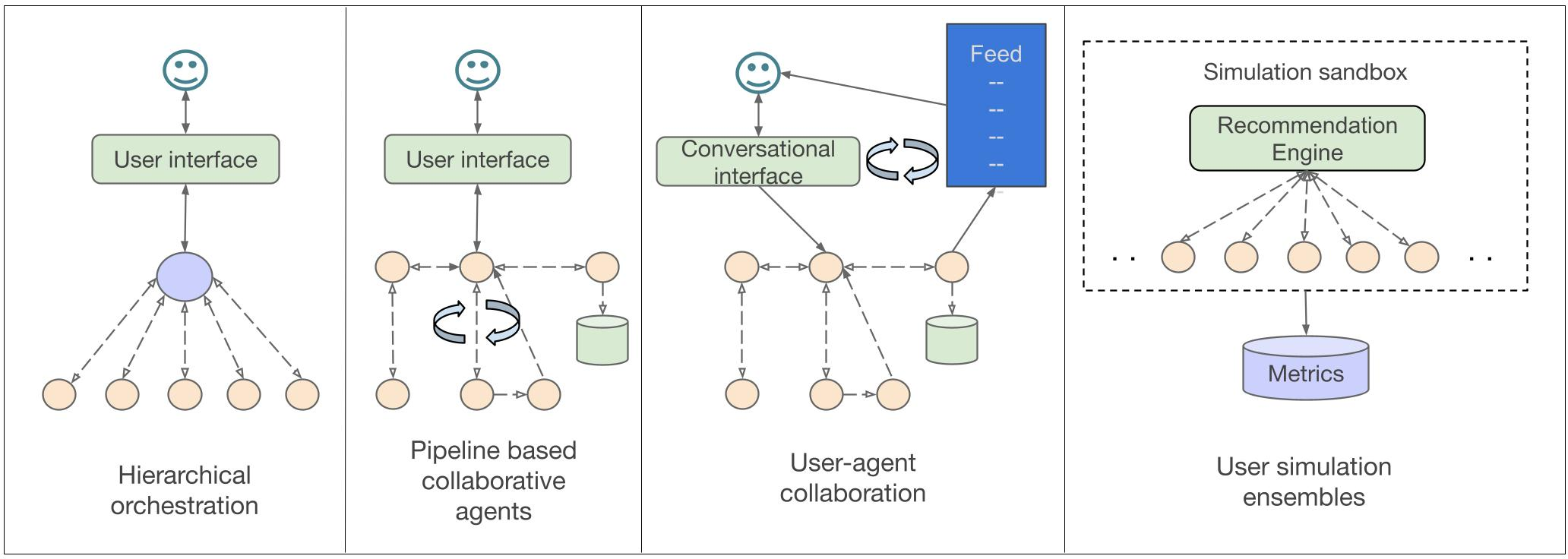
Figure 1: Taxonomy and representative examples of collaborative multi-agent patterns in video recommendation, covering hierarchical, pipeline, user-collaborative, and ensemble architectures.
Hierarchical Orchestration
Hierarchical systems feature a manager-agent that orchestrates subordinate agents specialized on auxiliary objectives or domains. MMRF and MMAgentRec exemplify this pattern. In MMRF, a primary agent targets watch time, while auxiliaries handle interaction signals (like, comment, follow). Integration via an attentive collaboration module enables goal-weighted dynamic aggregation. This resolves competing objective tradeoffs but introduces risks of central bottlenecks or misaligned auxiliary incentives.
Pipeline-based Modular Collaboration
Here, agents form a processing pipeline: perception agents extract semantically dense representations from multimodal video, while downstream agents (e.g., user simulators, analysts) perform personalization, search, or reasoning. VRAgent-R1 and MACRec illustrate this modular, sequential composition. Although modularity enhances specialization and fault isolation, error propagation across pipeline stages risks end-to-end brittleness. Explicit feedback loops (RL) are commonly employed to align modular agents to user-centric reward signals.
User-Agent Interactive Collaboration
In this design, a user-facing interface is mediated by multiple internal agents empowering direct end-user agency. TKGPT, for example, enables users to modulate their content feed through natural-language dialogue, dynamically reconfiguring algorithmic parameters (topic distribution, relevance) via keyphrase-to-weight mapping, thus improving transparency and perceived user control over recommendations.
Simulation Ensemble Architectures
Simulation ensembles (e.g., Agent4Rec) deploy thousands of generative agents as synthetic users, initialized from real-world behavioral profiles and endowed with demographic/psychological attributes. These ensembles generate synthetic interaction data for offline evaluation, reinforcement learning, and social-mechanism studies (e.g., filter bubbles, conformity). Behavioral fidelity (such as low KL divergence to real user data) is a principal evaluation target, but such architectures incur steep computational costs and risk overfitting to initialization biases.
Agent-Centric Evaluation Protocols
Classical recommender evaluation relies on proxy metrics such as Precision@K and NDCG computed on user-item matching. In contrast, agent-based systems require agent-centric, multi-level evaluation:
- Task-Specific Quality: Per-agent performance on subtasks (e.g., perception accuracy via BERTScore, reasoning coherence via qualitative analysis).
- Coordination and Collaboration Efficiency: Communication overhead (tokens, messages, API calls), processing latency, and utility alignment among agents.
- System-Level Emergent Properties: Robustness to agent failures, adaptability to shifts, and the accurate emergence of macro phenomena (e.g., filter bubbles).
- Human Alignment and User-Centric Metrics: User satisfaction, explainability, agency, trust, and fairness—measured by user studies and exposure parity.
- Scalability and Economic Viability: Token and computational cost (per request/batch), training overhead (for RL), and practical limits for real-time deployment.
Challenges and Open Problems in MAVRS
The deployment and further evolution of MAVRS face persistent obstacles:
- Computational Cost and Scalability: LLM-driven multi-agent coordination incurs prohibitive inference and simulation costs. Token-sharing, distillation, and efficient agent design are critical for practical scaling.
- Multimodal Grounding and Deep Reasoning: Current systems rely on lossy text summaries due to the incapacity of LLMs to process dense video directly. There is an urgent need for tightly integrated multimodal agents and models capable of joint reasoning across video, audio, and text streams.
- Evaluation and Alignment: Offline metrics incompletely capture emergent, user-centric behaviors; synthetic user agents must be robustly validated against real-world irrationality and drift. Alignment remains unsolved, especially for long-horizon, compositional tasks.
- Controllability, Transparency, Trust: As agent autonomy increases, the risks of silent failures, goal divergence, and opacity grow. Mechanisms for explicit feedback, self-reflection, and value alignment are required.
- Incentive Alignment: With differentiated agent objectives, robust coordination mechanisms (potentially inspired by economic contracts or auction theory, but implementable via language-based incentives) are essential for harmonizing agent contributions to system-level objectives.
(Figure 2)
Figure 2: Schematic overview of the principal challenges for MAVRS and corresponding future research directions, as described in Section 5.
Future Research Frontiers
Hybrid RL-LLM Architectures: Future systems will likely feature LLMs as planners for high-level reasoning and natural language interaction, while RL agents optimize low-level recommendation policy, reward shaping, and rapid adaptation via feedback loops. “Planner–executor” hybridization may optimize the trade-off between explainability and adaptivity.
Lifelong Personalization: Moving from session-centric optimization to lifelong, federated learning is necessary for agents that support persistent, privacy-preserving personalization. This requires distributed and on-device agent architectures, as well as advanced memory and retrieval mechanisms.
Human-in-the-Loop Validation: Continuous user feedback, via dialog or interactive dashboards, should drive adaptive model supervision, enhance transparency, and support regulatory compliance regarding fairness and trustworthiness.
Self-Improving and Meta-Agent Architectures: The field is trending toward self-governing agent ecosystems where meta-agents autonomously monitor outcomes, identify distributional shifts, and update collective policies, achieving continual improvement and tighter alignment to long-term human values.
Conclusion
Multi-agent coordination marks a critical inflection point in the evolution of video recommender systems, addressing longstanding limitations in scalability, multimodality, explainability, and alignment. By formalizing a taxonomy of collaborative patterns, tracing the transition from rule-based MARL to LLM-driven agent frameworks, and highlighting open technical and socio-technical challenges, this paper provides a detailed roadmap for future research. As incentive design, efficient multimodal reasoning, agentic evaluation, and lifelong adaptation are mastered, MAVRS architectures are poised to become the dominant abstraction for trustworthy, transparent, and systematically improvable recommendation platforms.

