- The paper presents ESL-Bench, a synthetic benchmark that uses explicit event-driven models to create realistic, multi-year patient trajectories with transparent causal structures.
- It utilizes a hybrid pipeline combining LLM-driven narrative planning with algorithmic simulation to ensure temporal coherence and plausible physiological constraints.
- Evaluation reveals that DB-native agents outperform memory-based systems, underscoring the need for structured temporal reasoning in complex health agent tasks.
ESL-Bench: An Event-Driven Synthetic Longitudinal Benchmark for Health Agents
Motivation and Benchmark Design
ESL-Bench addresses the acute challenge of evaluating longitudinal health agents, which must operate over multi-year, multi-modality patient trajectories comprising continuous wearable device streams, sparse clinical exams, and discrete life events. Prior real-world datasets are restricted by privacy constraints, lack definitive ground truth for temporally grounded attribution, and typically do not provide multi-source data with necessary interpretability. Existing synthetic data generators (Synthea, TimeGAN, SynTEG) often sacrifice event-level causal mechanisms, distributional plausibility, or individual-trajectory interpretability.
The ESL-Bench methodology operationalizes events as first-class objects—each patient’s data are synthesized as a stochastic baseline plus a superposition of explicit events. Each event is parameterized with temporal kernels (sigmoid onset and exponential fade-out), signed per-indicator effect sizes, and bounded by physiological constraints, ensuring transparent causal structure, auditability, and ground-truth programmatic recovery.

Figure 1: Structure and evaluation design of the event-driven synthetic longitudinal benchmark.
Data Generation Framework
The benchmark comprises 100 synthetic users, each with a 1–5 year trajectory containing:
- Profile: structured JSON with demographics, chronic conditions, lifestyle, and medication history.
- Trajectory plan: a multi-phase narrative arc guiding event scheduling.
- Device stream: daily measurements (e.g., HR, steps, sleep, weight).
- Sparse exam records: clinically relevant snapshots.
- Event log: explicit event metadata (start/end, affected indicators, signed impact, onset/fade windows).
- Audit report: conformance, plausibility, and completeness metrics.
Data synthesis follows a hybrid pipeline. LLM modules generate sparse semantic content (profile, event narrative, exam metadata), while algorithmic simulation produces dense indicator dynamics under hard constraints.
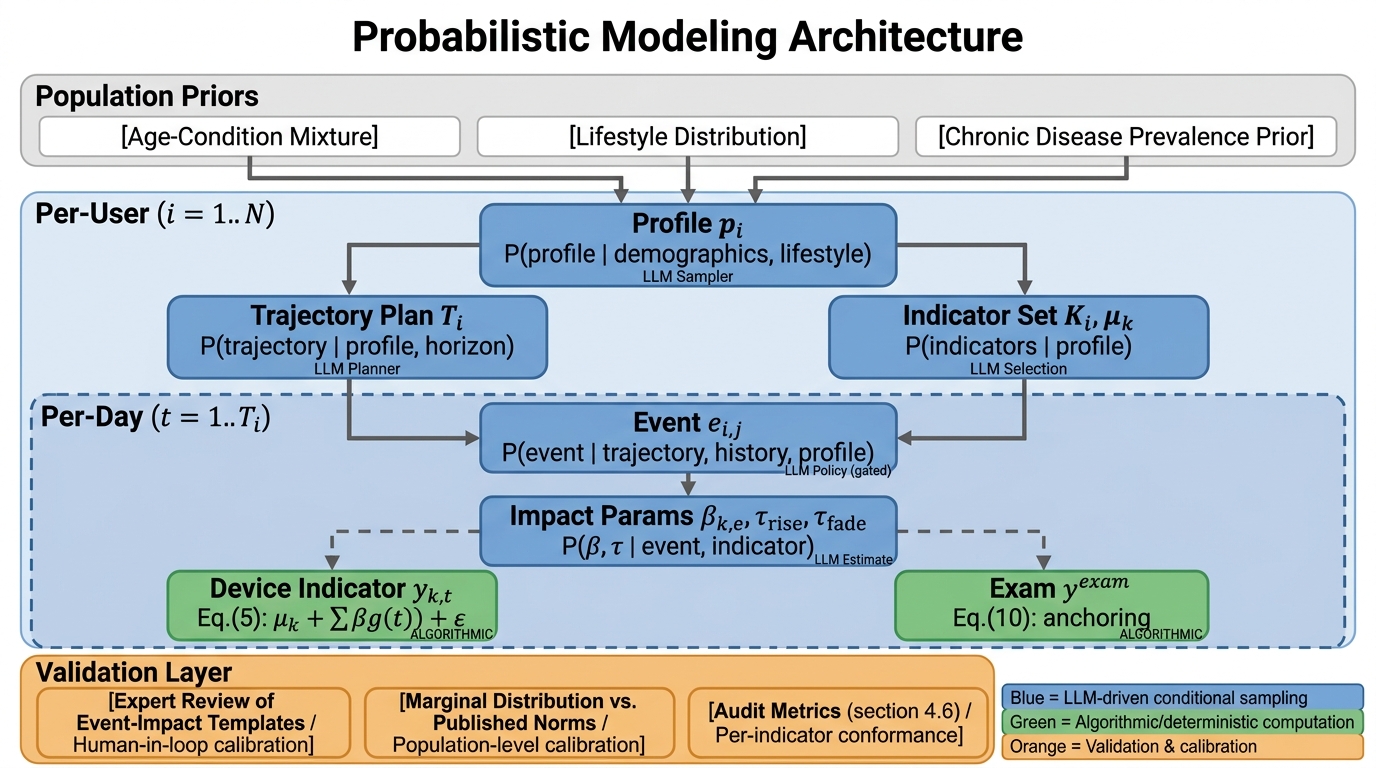
Figure 2: Internal probabilistic modeling architecture: blue nodes—LLM-driven conditional sampling; green nodes—algorithmic simulation; orange nodes—validation mechanisms.
Trajectory planning is performed via LLMs to ensure coherent longitudinal arcs and realistic phase transitions; daily device values are modeled as constrained dynamical systems with additive event impulses, mean reversion, and day-level correlated noise. Event effects are superposed with soft caps to prevent implausible stacking, and simulation operates in a transform domain (log, logit) to mitigate boundary artifacts.
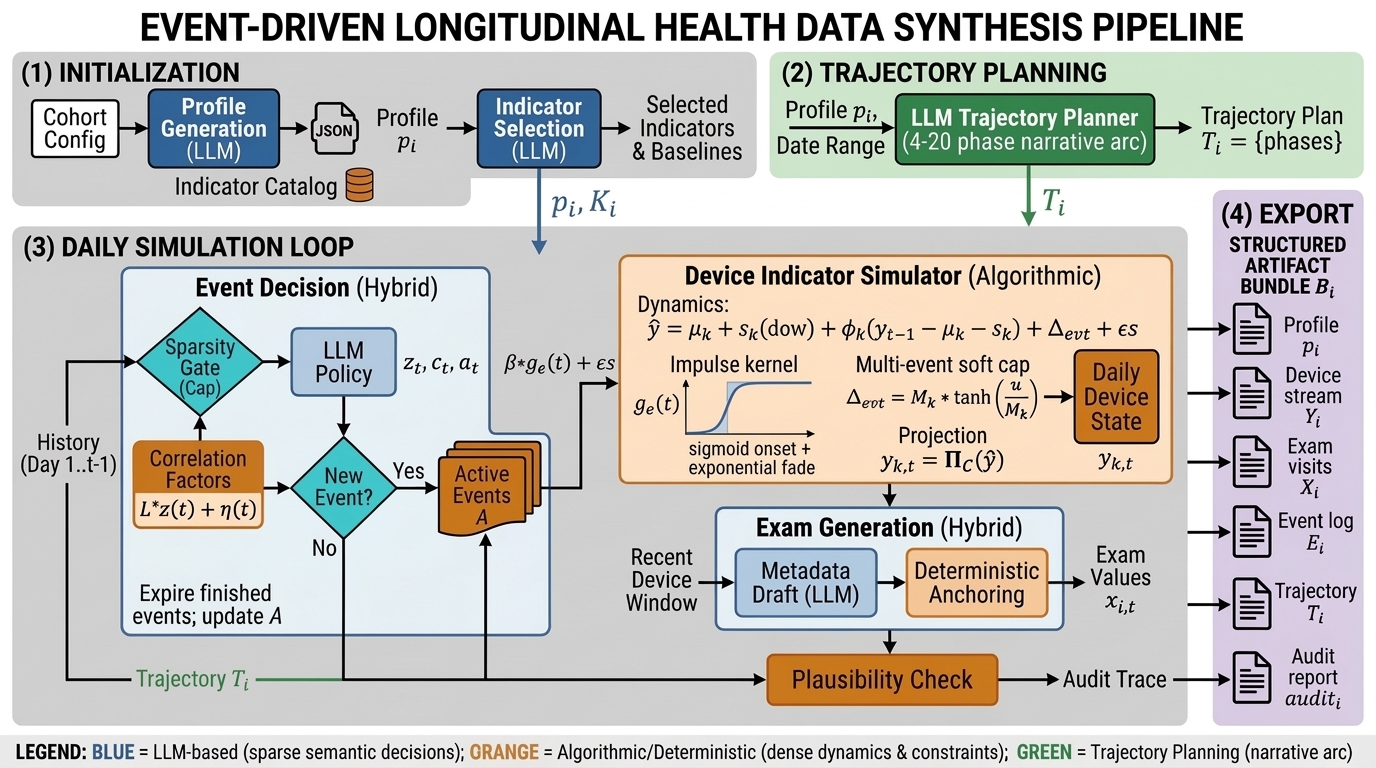
Figure 3: Hybrid generation pipeline: LLM-driven semantic decisions and algorithmic simulation of device indicators.
Each exam record is anchored to device trends, ensuring cross-source consistency. Audit mechanisms guarantee conformance, completeness, and plausibility, with deterministic enforcement of physiological bounds and explicit reporting of violations.
Benchmark Taxonomy and Evaluation
Each user is paired with 100 evaluation queries, yielding a total of 10,000 queries stratified by two axes:
- Dimension: Lookup, Trend, Comparison, Anomaly, Explanation (mirroring real clinical reasoning tasks).
- Difficulty tier: Easy, Medium, Hard (calibrated empirically via agent performance bands).
All queries are generated deterministically from the event–indicator–time graph; ground-truth answers are programmatically computable.
The scoring protocol is two-stage: (1) programmatic matching against JSON schemas and tolerances, and (2) LLM rubric evaluation (GPT-4.1 judge), scoring value correctness, reasoning, evidence clarity, and format compliance.
Dataset Statistics
The cohort covers a wide demographic and chronic condition spectrum (mean age 43, 98% with ≥1 chronic condition), with high event concurrency and diversity (mean events/user: 188, mean duration: 88 days but median 4 days, average concurrent events/day: 9). 159 device indicators and 322 exam indicators are included per user, with audit metrics confirming perfect conformance, zero violations post-projection, and full cross-source consistency.
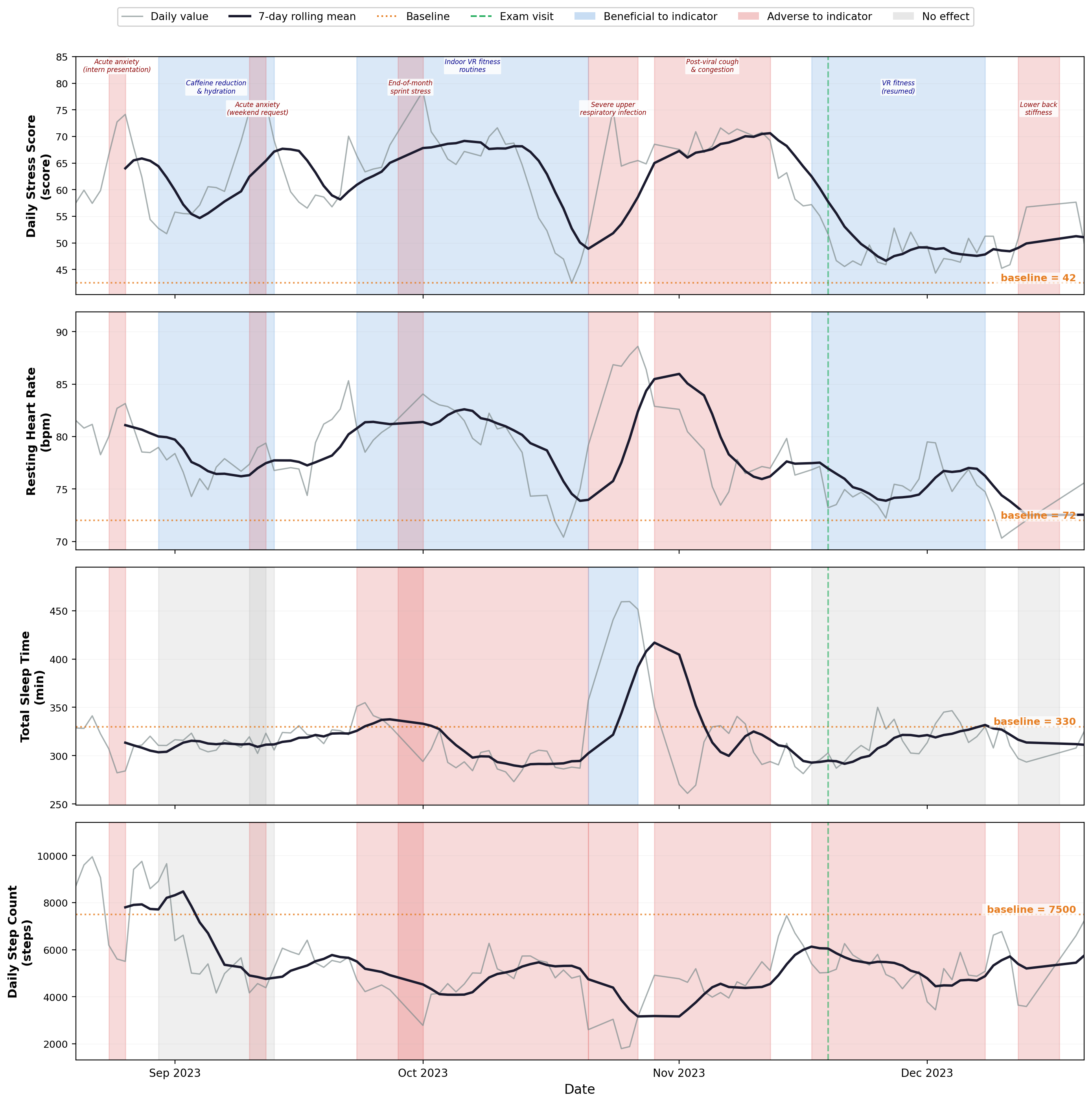
Figure 4: Four-month trajectory excerpt illustrating device indicator dynamics, event effects, rolling means, personalized baselines, and exam anchoring.
Experimental Results
Thirteen baseline methods—spanning LLM w/ tools, DB-native agents, and memory-augmented RAG—are evaluated. DB agents consistently outperform Memory RAG baselines (DB: 48–58%, RAG: 30–38% accuracy), with the largest gap in Comparison and Explanation queries where structured temporal reasoning and multi-hop evidence attribution are requisite. LLM w/ tools demonstrate model-dependent variance (Gemini 3 Flash: 62.9%, GPT-5.2: 45.4%), driven by tool-use proficiency and prompt design.
Accuracy degrades sharply across difficulty tiers: Easy (56–76%), Medium (23–72%), Hard (22–55%), confirming that harder tasks expose fundamental architecture limitations. Dimension-level breakdown shows Trend queries are easiest for LLMs (aggregation, time-series statistics), while Explanation remains the hardest overall.
Error analysis reveals systematic failures in temporal window alignment, indicator-level chunk retrieval, and evidence consolidation—especially in memory-based RAG—underscoring the importance of explicit temporal structures and structured access for longitudinal health workloads.
Implications and Future Directions
The ESL-Bench synthesis and evaluation framework demonstrates that structured temporal reasoning, rather than generic language understanding, is the principal bottleneck for longitudinal health agent architectures. DB-native agents leveraging explicit event–indicator graphs and structured APIs are far more robust for multi-hop queries and evidence attribution. Memory-based retrieval methods underperform, particularly when required to aggregate temporally distant chunks or resolve cross-source joins.
Practically, ESL-Bench provides an open, reproducible, and programmatically verifiable testbed for agent development, diagnostic evaluation, and benchmarking. Theoretical implications include a necessary-condition argument: failure modes under synthetic controlled dynamics are predictive of failures on real-world noisy data, thus agent architectures passing ESL-Bench are more likely to generalize, contingent on data fidelity.
Future developments may include: real-cohort calibration of event frequencies and indicator distributions, richer cross-indicator constraints (beyond noise factors), irregular device sampling and non-wear modeling, incremental partial-credit metrics, and multimodal expansion to imaging and free-text notes. Multilingual query support and more stringent privacy auditing are also critical.
Conclusion
ESL-Bench operationalizes explicit event-driven synthesis and evaluation for longitudinal health agents, bridging critical gaps in temporal reasoning diagnostics, interpretability, and ground-truth attribution. Empirical results reveal that architectures incorporating structured API access and event-driven graphs are superior for complex temporal tasks, with memory-augmented retrieval showing substantive deficits. The benchmark sets a scalable foundation for advancing health agent capabilities and driving research in temporally structured agent reasoning.