Self-Optimizing Multi-Agent Systems for Deep Research
Abstract: Given a user's complex information need, a multi-agent Deep Research system iteratively plans, retrieves, and synthesizes evidence across hundreds of documents to produce a high-quality answer. In one possible architecture, an orchestrator agent coordinates the process, while parallel worker agents execute tasks. Current Deep Research systems, however, often rely on hand-engineered prompts and static architectures, making improvement brittle, expensive, and time-consuming. We therefore explore various multi-agent optimization methods to show that enabling agents to self-play and explore different prompt combinations can produce high-quality Deep Research systems that match or outperform expert-crafted prompts.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper shows how to build a “Deep Research” AI that can answer tough questions by searching the web, reading many documents, and writing a careful, well-cited report. Instead of relying on people to hand-craft long, fragile instructions for the AI, the authors teach the AI to improve its own instructions through practice—so it can get better on its own.
What questions did the researchers ask?
The authors wanted to find out:
- Can a team of AI agents (each with a role like planner, reader, or writer) learn to do deep research more effectively by improving their own instructions?
- Can automatic “prompt optimization” match or beat prompts written by human experts?
- Which self-improvement method works best for this kind of multi-agent research system?
How did their system work?
Think of this AI like a well-organized research team working on a group project:
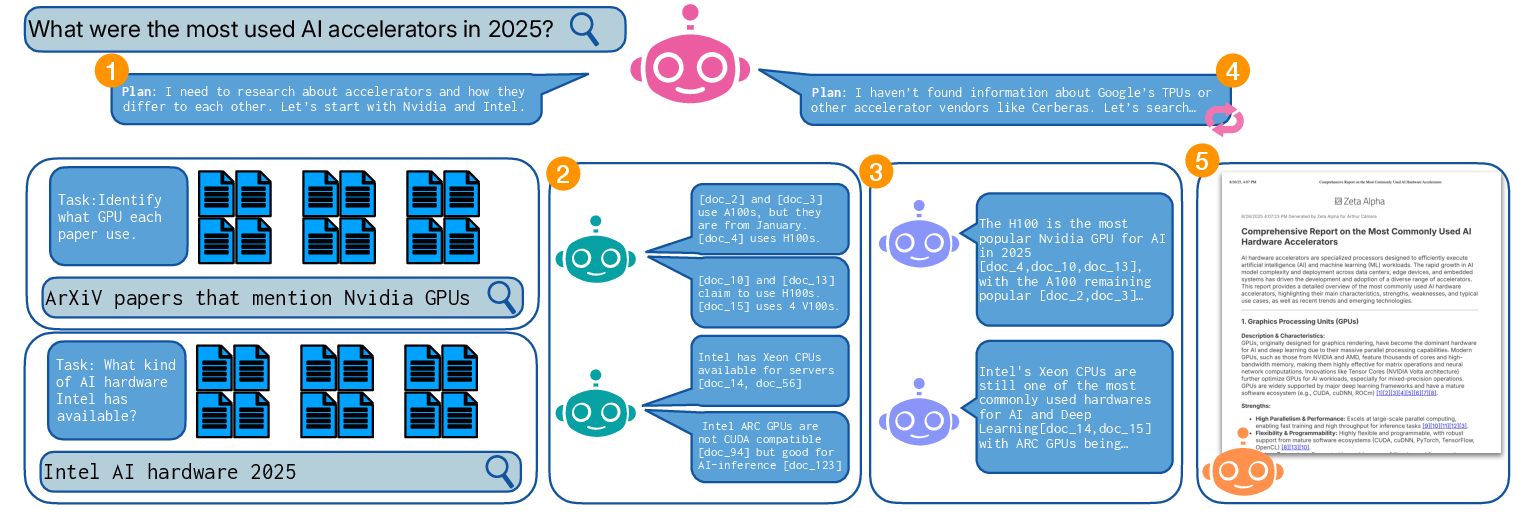
- Orchestrator (the project manager): Breaks a big question into smaller tasks and search queries, then decides when to keep researching and when to start writing.
- Readers (the researchers): In parallel, they read lots of documents, pull out useful facts, and save the source for each fact.
- Aggregator (the editor): Merges the readers’ notes, removes duplicates, highlights conflicts, and produces small mini-reports per task.
- Writer (the author): Uses all the mini-reports to write one clear, source-backed final report.
Behind the scenes, a “citation manager” keeps track of where every fact came from, so the final report has proper references.
How did they teach the system to improve itself?
Each agent follows a “prompt,” which is just a set of instructions written in plain language. Instead of humans rewriting these prompts by hand, the system practices on training questions and updates its own prompts using feedback. The paper tried two main optimization strategies:
- TextGrad (like learning from a coach’s notes): The team answers some practice questions. An AI “judge” scores the answers using a checklist (called a rubric). Then another AI reads the agents’ step-by-step traces and the judge’s feedback to write critiques of the prompts and suggest improvements. The prompts are revised, and the cycle repeats, always trying to climb toward better performance.
- GEPA (Genetic-Pareto, like evolving a team): Imagine making many slightly different versions of the team’s instruction cards. You keep the ones that do best on at least some questions (like keeping athletes who are top in a particular event), and you drop versions that are worse in every way. Then you mix and refine the winners’ prompts and test again. Over time, this evolution-style process finds stronger prompts faster.
How did they test it?
- Dataset: 109 expert-written computer science questions from ScholarQA (with rubrics that say what a good answer should include).
- Splits: 29 training, 30 development, 50 test questions.
- Scoring: An AI “judge” graded each answer on rubric items (mainly content) plus three extras: matching the target audience level, using citations, and including short quoted excerpts. Scores range from 0 to 1.
- Starting points: They tried both “minimal” one-line prompts and a polished expert prompt that had been refined for over a year.
What did they find, and why is it important?
Big picture: Letting the agents improve their own prompts worked—and worked best when starting from very simple prompts.
Key results:
- Starting from minimal prompts:
- TextGrad raised the score from 0.513 to 0.654.
- GEPA did even better: 0.685 with the default setup, and 0.705 with a custom tuning prompt tailored to deep research.
- Starting from an expert prompt:
- Improvements were smaller (there’s less room to grow).
- TextGrad nudged performance from 0.667 to 0.672.
- GEPA reached 0.670 (default) and 0.701 (custom), the best overall.
- A general-purpose prompt optimizer from OpenAI didn’t help as much in this setup, likely because it didn’t use task-specific rubrics or the agents’ traces.
Why this matters:
- The system can reach or beat expert-crafted instructions without months of human tweaking.
- It adapts more easily when the model or the domain changes (e.g., from computer science to medicine), cutting costs and time.
What could this change in the real world?
- Faster, more reliable research assistants: Companies and labs could deploy high-quality research agents more quickly, even when starting from a blank slate.
- Less fragile systems: Automatic optimization makes the system more robust when underlying models or tasks change.
- A path to broader automation: The same approach could help tune not just prompts, but tools, settings, and even code for complex AI systems.
Limits and what’s next
- Limits: The tests were done on one domain (computer science), with a small dataset and one main model family. Also, AI-judged scores can be biased, and the study didn’t include statistical significance tests.
- What’s next: Optimize more than prompts (like tools and architecture), rely less on human-written rubrics by generating training signals automatically, and try these methods on other agent tasks beyond deep research.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, phrased to guide actionable follow-up work:
- External validity across domains: Evaluate optimized agents on non-CS domains (e.g., biomedical, legal, finance) and on domain-specific corpora to assess transfer and robustness to domain shift.
- Cross-model transferability: Test whether prompts optimized on GPT‑4.1‑mini transfer to other families/sizes (e.g., GPT‑5, Claude, Llama, Qwen) without re-optimization, and quantify degradation and recovery costs.
- Context-window sensitivity: Systematically study performance when traces are truncated or compressed for smaller context windows; compare trace summarization/compression strategies.
- Statistical rigor and stability: Report multiple runs with different random seeds, confidence intervals, and significance tests; quantify run-to-run variance and optimizer instability.
- Human-grounded evaluation: Incorporate blinded expert judgments (with inter-annotator agreement) for factuality, faithfulness to sources, coverage, and clarity; compare against LLM-as-judge scores.
- Judge overfitting and Goodhart’s law: Evaluate with diverse judges (different models/vendors) and ensemble/cross-judge protocols to detect gaming of a single judge’s preferences.
- Grounding and citation accuracy: Audit whether citations truly support claims via human checks or automated evidence support metrics; measure false attribution and dangling citation rates.
- Retrieval and reader effectiveness: Measure retrieval recall/precision and reader extraction accuracy; analyze how optimizer changes affect what is retrieved/used vs. ignored.
- Failure mode analysis: Categorize common errors (e.g., hallucinated claims, plan decomposition errors, redundant tasks, premature stopping) and identify which agent most contributes.
- Agent-level ablations: Quantify the marginal impact of optimizing each agent (orchestrator vs reader vs aggregator vs writer); test targeted vs round-robin optimization schedules.
- Orchestrator stopping policy: Study and learn stopping criteria (vs fixed compute limits), including uncertainty-aware or cost-aware stopping, and their effect on quality/cost trade-offs.
- Efficiency and cost reporting: Provide end-to-end token counts, latency, and dollar cost per query and per optimization round; measure sample efficiency to reach target performance.
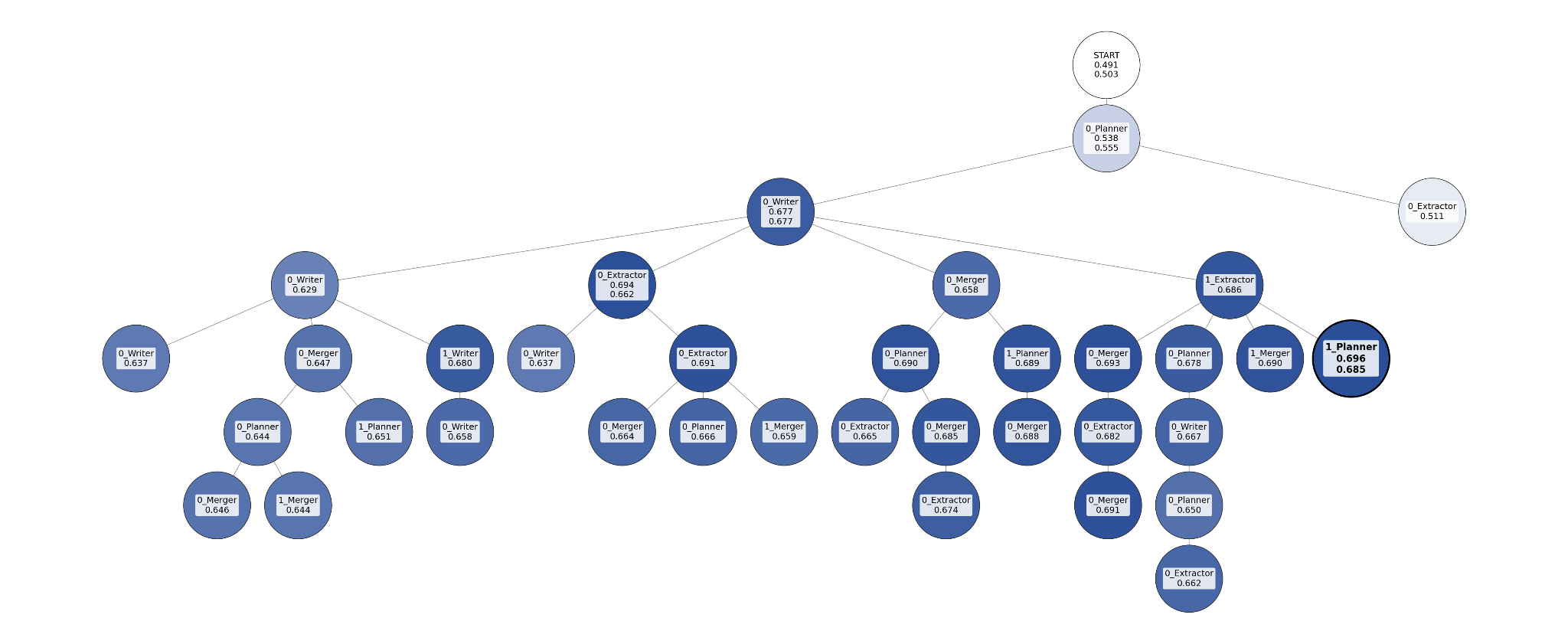
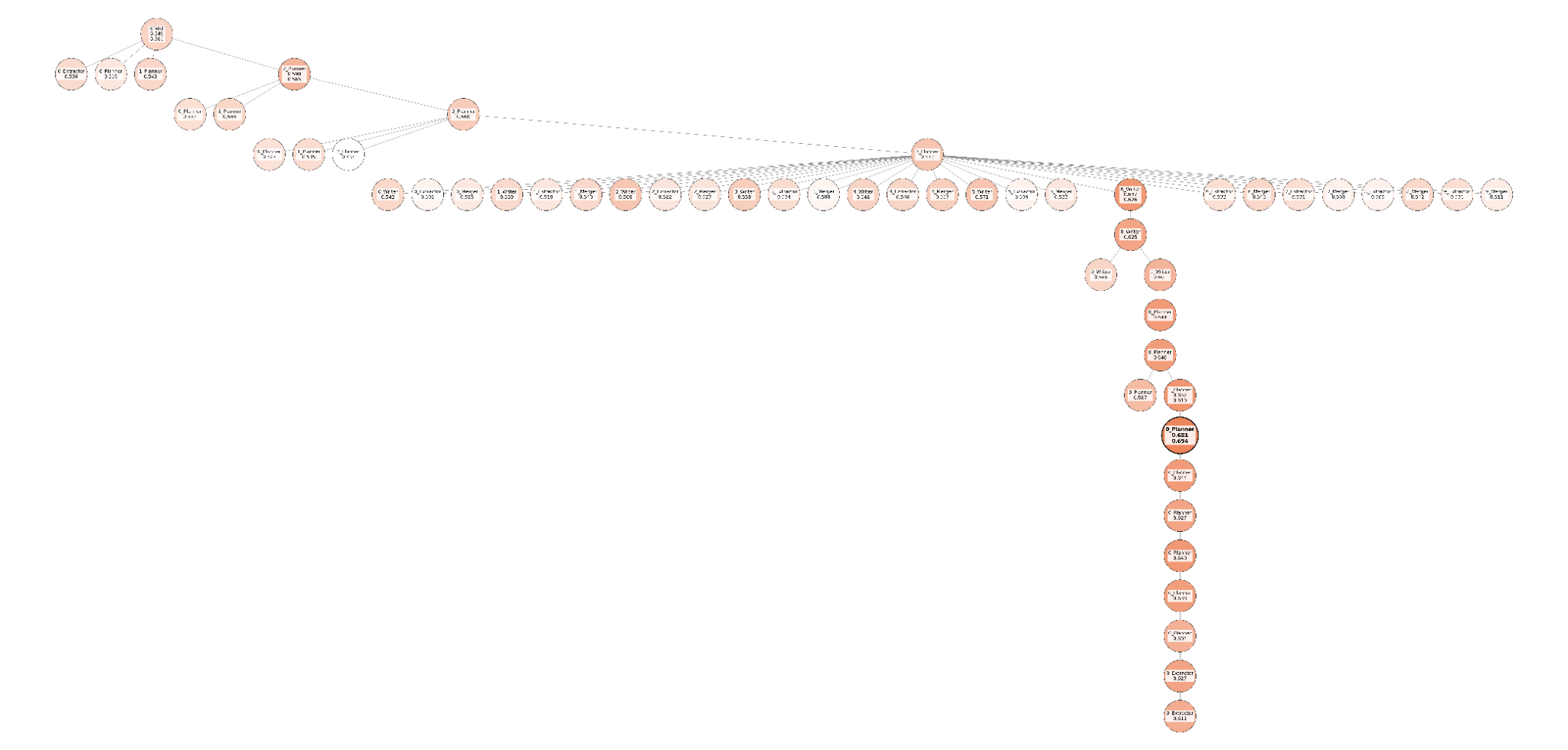
- Exploration efficiency metrics: Beyond tree visualizations, quantify exploration diversity/novelty, convergence speed, and population quality over time for GEPA vs TextGrad.
- GEPA implementation details: Disclose genetic operator design (mutation types/rates, crossover usage), population size, selection pressure, and pruning rules; ablate each component.
- Multi-objective optimization: Explicitly optimize and analyze trade-offs among rubric coverage, citation coverage, brevity, and cost (Pareto curves), rather than a single weighted sum.
- Evaluation weighting sensitivity: Justify or calibrate the 60/10/20/10 weighting; test sensitivity of conclusions to alternative weightings and task-specific utility functions.
- Reproducibility and artifacts: Release code, seeds, data splits, final optimized prompts, exploration logs, and GEPA configuration to enable replication.
- Dataset scale and diversity: Move beyond 109 CS queries; test on full OpenScholar, ResearchRubrics, DeepResearchGym task suites, and real-world industrial queries.
- Cross-index generalization: Evaluate with different retrieval indices (web, scholarly, enterprise) and measure robustness to corpus/domain shifts and index freshness.
- Tooling breadth: Optimize tool selection/parameters (search engines, retrievers, re-rankers, citation resolvers) and compare against hand-chosen toolchains.
- Memory management strategies: Compare alternative memory/summarization/long-context strategies and quantify their effect on long-horizon tasks and citation fidelity.
- Adversarial robustness: Test against noisy/hostile web content (prompt injection, misinformation, paywalls) and evaluate mitigations (content sanitization, verifier agents).
- Prompt length and structure: Analyze how prompt verbosity/structure evolves during optimization and its marginal benefit vs cost and context consumption.
- Batch-size and budget sensitivity: Vary mini-batch sizes and optimization budgets to map stability/performance curves and identify cost-effective regimes.
- Self-play formalization: Define and test genuine self-play mechanisms (e.g., competing planners/readers or tournament selection) beyond reflective prompt evolution; measure incremental gains.
- Broader baselines: Compare against other optimizers and learning methods (OPRO, AutoPDL, GAPO, PromptBreeder, RL with rubrics such as DR‑Tulu) under identical settings.
- Judge–agent coupling: Avoid using the same model family for agents and judge; quantify biases when the judge shares or differs from the agent’s training and style.
- Longitudinal maintenance: Measure how optimized systems degrade under model upgrades or domain drift, and the efficiency of periodic re-optimization or warm-start strategies.
- Ethical/safety considerations: Assess risks (privacy in enterprise retrieval, harmful content generation) and evaluate effectiveness of guardrails or policy constraints.
- Citation and bibliography quality: Evaluate real-world bibliographic accuracy (deduplication, canonicalization, broken links) and their impact on user trust.
Practical Applications
Immediate Applications
The paper introduces a modular, multi-agent Deep Research (DR) architecture (orchestrator, parallel readers, aggregator, writer) and shows that self-optimization via GEPA/TextGrad can reliably improve system quality with less manual prompt engineering. The following are deployable now with human oversight and appropriate tooling.
- Enterprise evidence-backed report generation (Software/Enterprise Search)
- Description: Generate long-form, citation-backed internal reports by searching across intranets, wikis, ticketing systems, and document repositories.
- Tools/workflows: Integrate the orchestrator/reader/aggregator/writer pipeline with enterprise search; add citation management and de-duplication. Use GEPA-based prompt optimizer to adapt agents to company jargon and domains.
- Assumptions/dependencies: Access to a long-context LLM and internal indexes; governance for data privacy; rubric definitions for evaluation; human-in-the-loop review for high-stakes outputs.
- Competitive intelligence and market landscape scanning (Finance/Industry)
- Description: Compile weekly/monthly market briefs with sources from news, filings, blogs, patents, and standards.
- Tools/workflows: Parallel readers scan hundreds of documents; aggregator reconciles conflicting claims; writer produces a brief with references.
- Assumptions/dependencies: Web access and licensing; budget for LLM calls; curated rubrics to score coverage/accuracy.
- Scientific literature reviews and survey drafts (Academia/Healthcare)
- Description: Draft literature reviews with citation coverage and inline excerpts; surface gaps and conflicting findings.
- Tools/workflows: Connect readers to arXiv/PubMed/library APIs; use aggregator to de-duplicate; writer compiles “References.”
- Assumptions/dependencies: Domain expertise for validation; risk controls for hallucinations; content access rights.
- Policy briefs and regulatory monitoring (Public sector/Compliance)
- Description: Produce rapid, evidence-based briefs on policy questions; track regulation changes and synthesize impacts.
- Tools/workflows: Orchestrator plans per-topic tasks; scheduled runs monitor target sources; rubric-aligned judging for completeness.
- Assumptions/dependencies: Curated source lists; versioned audit trails; human policy analyst oversight.
- Legal research memos and case synthesis (Legal)
- Description: Aggregate statutes, case law, and secondary sources into memos with accurate citations.
- Tools/workflows: Readers integrated with legal databases; strict citation and excerpt requirements enforced by the pipeline.
- Assumptions/dependencies: Jurisdiction-specific coverage/licensing; attorney review; clear scope limits to avoid UPL risks.
- Customer support knowledge maintenance (Software/IT Ops)
- Description: Mine tickets and docs to update KB articles, FAQs, and runbooks with provenance.
- Tools/workflows: Readers ingest tickets/PRs/logs; aggregator synthesizes; writer proposes updates for approval.
- Assumptions/dependencies: Access to internal systems; change management; on-call workflows for review.
- Engineering RFCs and design docs (Software/Standards)
- Description: Prepare RFC drafts by consolidating API docs, standards, and prior designs with source links.
- Tools/workflows: Orchestrator decomposes into sub-questions (trade-offs, alternatives); writer constructs structured drafts.
- Assumptions/dependencies: Up-to-date documentation sources; team review process.
- Newsroom backgrounders and research dossiers (Media)
- Description: Quickly compile background briefs with traceable sources and quotes.
- Tools/workflows: High-recall retrieval; aggregator highlights conflicts; writer outputs factbooks.
- Assumptions/dependencies: Editorial standards; source reliability scoring.
- Compliance and audit preparation (Finance/Healthcare)
- Description: Assemble audit-ready evidence trails and control narratives with citations.
- Tools/workflows: Task templates per control; citation management ensures provenance; versioned outputs.
- Assumptions/dependencies: Secure data handling; alignment to audit frameworks; human sign-off.
- Curriculum-aligned study guides and reading lists (Education)
- Description: Generate annotated reading lists and study notes with citations and excerpts.
- Tools/workflows: Rubrics encode learning objectives and expertise alignment; writer adapts complexity.
- Assumptions/dependencies: Curriculum mapping; educator review; age-appropriate content filters.
- RAG-to-DR upgrades for existing assistants (Software/AI Platforms)
- Description: Enhance single-turn RAG agents with iterative planning, parallel reading, and aggregation to handle complex tasks.
- Tools/workflows: Drop-in orchestrator/reader/aggregator modules; GEPA-driven prompt optimization for target domains.
- Assumptions/dependencies: Search/tool integrations; evaluation harness; long-context model availability.
- PromptOps/MLOps for agent pipelines (AI Tooling)
- Description: Productize GEPA/TextGrad as a “prompt optimizer” for multi-agent systems with dev/test splits and LLM-as-judge evaluation.
- Tools/workflows: Versioned prompt evolution, Pareto-based selection, budget-aware optimization; dashboards for trace inspection.
- Assumptions/dependencies: Well-specified rubrics; compute budget; monitoring for regression/bias.
- VC/PE due diligence memos (Finance)
- Description: Create first-draft diligence reports with sources on technology, team, market, and risks.
- Tools/workflows: Orchestrated tasks per diligence dimension; aggregator reconciles claims; writer assembles memo.
- Assumptions/dependencies: Reliable public and subscription data; analyst validation.
Long-Term Applications
These leverage the same architecture and self-optimization approach but require further research, scaling, validation, or ecosystem maturity.
- Self-optimizing agent systems beyond prompts (Software/AI)
- Description: Automatically evolve architectures, tool choices, and code (not just prompts), in the spirit of Darwin–Gödel Machine.
- Tools/products/workflows: Auto-selection of tools, module topologies, and hyperparameters; long-running self-play/tournaments.
- Assumptions/dependencies: Robust safety/guardrails; reproducible evaluation; interpretable changes.
- Clinically validated evidence synthesis for care decisions (Healthcare)
- Description: Systematic reviews and guideline summarization for clinical use with regulatory acceptance.
- Tools/products/workflows: PRISMA-like pipelines, bias assessments, conflict reconciliation; audit logs.
- Assumptions/dependencies: Prospective validation; regulatory approval; domain-tuned models; strict human oversight.
- Autonomous policy analysis and draft assistance at scale (Government)
- Description: Continuous monitoring and synthesis across jurisdictions; impact analyses and draft recommendations.
- Tools/products/workflows: Standardized rubrics, traceable citations, stakeholder-specific expertise alignment.
- Assumptions/dependencies: Governance frameworks; transparency mandates; multidisciplinary review panels.
- First-draft legal briefs and e-discovery triage (Legal)
- Description: Triage and summarize discovery corpora; draft sections with precise citations/excerpts.
- Tools/products/workflows: Advanced PDF/scan parsing, privilege filters, chain-of-custody logs.
- Assumptions/dependencies: Data security; admissibility standards; jurisdictional constraints.
- Auto-updating knowledge pages (e.g., Wikipedia-like) with editorial workflows (Media/Education)
- Description: Maintain living knowledge pages via scheduled DR runs and human curation.
- Tools/products/workflows: Change detection, diff-based updates, confidence scoring.
- Assumptions/dependencies: Editorial acceptance; anti-vandalism measures; licensing compliance.
- Cross-lingual deep research and synthesis (Global/Multilingual)
- Description: Gather and reconcile evidence across languages and regions.
- Tools/products/workflows: Multilingual retrieval/translation, cross-lingual coreference, bias checks.
- Assumptions/dependencies: High-quality multilingual models; source reliability estimation.
- Model-agnostic adaptation layer for foundation model churn (AI Platforms)
- Description: Continuous GEPA optimization to maintain quality when underlying LLMs change.
- Tools/products/workflows: Canary tests, automatic re-optimization triggers, rollback mechanisms.
- Assumptions/dependencies: Long-context local/cloud models; stable evaluation sets.
- End-to-end scientific discovery support (Academia/R&D)
- Description: Hypothesis mapping, grant drafting, and automated screening/inclusion pipelines for systematic reviews.
- Tools/products/workflows: Synthetic/self-generated rubrics (e.g., Dr. Tulu/ResearchRubrics), Elo-style evaluations.
- Assumptions/dependencies: Acceptance of LLM-judged pipelines; integration with citation databases; human governance.
- Real-time crisis information synthesis (Emergency management)
- Description: Aggregate multi-source updates during disasters with provenance and confidence flags.
- Tools/products/workflows: Streaming retrieval, budget-constrained planning, triage queues.
- Assumptions/dependencies: Reliable live data feeds; robust latency/cost controls; coordination protocols.
- Audit bots with immutable traceability (Finance/Corporate governance)
- Description: Automated compilation of compliance evidence with tamper-evident logs and chain-of-custody.
- Tools/products/workflows: Cryptographic logging, differential analysis of changes, regulator-ready exports.
- Assumptions/dependencies: Standards alignment; legal acceptance; secure infra.
- Personalized, citation-aware tutors (Education)
- Description: Tutors that research and cite, adjusting depth/complexity to learner profiles.
- Tools/products/workflows: Expertise alignment rubrics; content scaffolding; parent/teacher dashboards.
- Assumptions/dependencies: Safety/content controls; curriculum integration; accessibility.
- On-prem, privacy-preserving DR with long-context local models (Enterprise)
- Description: Run the full DR and optimization stack within secure environments.
- Tools/products/workflows: Deployment on private GPUs/CPUs; local indexes; offline optimization.
- Assumptions/dependencies: Availability of long-context local LLMs; hardware investment; MLOps maturity.
- Rubric and meta-prompt marketplaces and standards (Ecosystem/Standards)
- Description: Shared, sector-specific rubric libraries and meta-prompt templates with benchmarking/certification.
- Tools/products/workflows: Public benchmarks, interop standards, governance bodies.
- Assumptions/dependencies: Community adoption; clear licensing; consensus on evaluation best practices.
Notes on feasibility across applications:
- The paper’s gains were demonstrated on a CS dataset with LLM-as-judge; generalization to other domains requires new rubrics and validation.
- Long-context models materially improved outcomes; deployments should select models with sufficient context windows and acceptable cost/latency.
- LLM-as-judge may introduce biases; for critical uses, incorporate human review and/or hybrid evaluation.
- Data privacy, security, and licensing constraints must be addressed for enterprise and regulated domains.
Glossary
- Aggregator agent: An agent that merges evidence from multiple readers into concise task-level mini-reports. Example: "an aggregator agent (aggregator) consolidates these snippets into task-level mini-reports"
- Agent execution trace: The recorded sequence of an agent’s actions, tool calls, and outputs during a run, used for analysis and optimization. Example: "The evaluation signal and the agent execution trace are then fed into an LLM that produces a 'loss'."
- Backward pass: The phase that aggregates feedback to derive update signals (gradients) for prompt refinement. Example: "In a backward pass, the losses across are aggregated (e.g., concatenated) to form a 'gradient'."
- Candidate system: A specific set of agent prompts (e.g., orchestrator, reader, aggregator, writer) being evaluated/optimized. Example: "The optimization process outputs an updated prompt for the selected agent, yielding a new candidate system "
- Citation coverage: An evaluation metric measuring how many claims are supported by citations. Example: "citation coverage (20%)---the fraction of claims backed by a citation"
- Context windows: The maximum token capacity that a model can process in a single input sequence. Example: "their shorter context windows (400,000 and 32,768 tokens, respectively, versus 1,047,576 for GPT-4.1-mini)"
- Deep Research: A multi-step paradigm where agents iteratively plan, retrieve, and synthesize evidence to answer complex questions. Example: "a multi-agent Deep Research system iteratively plans, retrieves, and synthesizes evidence across hundreds of documents"
- De-duplication: The process of removing repeated or overlapping evidence or citations. Example: "de-duplicates overlapping evidence"
- Development split: A held-out data subset used to select and compare candidates during optimization. Example: "it selects the best current system as evaluated on a development split."
- Elo-style tournaments: A comparative evaluation framework using Elo ratings to rank systems via ongoing pairwise matches. Example: "long-running Elo-style tournaments"
- Frontier LLM: The most capable available LLM used to drive feedback and optimization. Example: "where the frontier LLM itself is the optimization operator"
- Genetic algorithm: An evolutionary search procedure that selects, mutates, and recombines candidate solutions. Example: "by a genetic algorithm from a population of reasonably good solutions."
- GEPA: An optimization method (Genetic-Pareto) that evolves prompts using Pareto-guided selection and reflective updates. Example: "For \ac{GEPA}, the candidate system is selected using a Pareto-based procedure"
- Hand-engineered prompts: Prompts crafted manually by experts rather than learned algorithmically. Example: "hand-engineered prompts and static architectures"
- High recall: A retrieval setting tuned to capture as much relevant information as possible, even at the expense of precision. Example: "This stage is designed for high recall, allowing hundreds of documents to be inspected in parallel."
- Hill-climbing operator of backpropagation: A greedy improvement heuristic analogous to incremental ascent used as inspiration for prompt search. Example: "uses a greedy strategy inspired by the hill-climbing operator of backpropagation"
- LLM-as-judge: An evaluation approach where an LLM scores outputs against rubrics. Example: "we employ an LLM-as-judge approach."
- Meta-prompt: A prompt that takes outputs and (optionally) traces as input and returns targeted suggestions to improve another prompt. Example: "fed into a 'meta-prompt' that produces suggestions for improving the prompt of a chosen agent."
- Mini-batch: A small subset of training examples used per optimization step for efficiency. Example: "We then sample a mini-batch and generate answers"
- Orchestrator agent: The planner/controller that decomposes the query into tasks and coordinates other agents. Example: "an orchestrator agent coordinates the process"
- Pareto 'support': The number of instances where a candidate appears on the Pareto frontier, used to bias selection. Example: "with probability proportional to their Pareto 'support' (i.e., the number of instances in which they appear on the frontier)"
- Pareto-based procedure: A selection strategy that prioritizes non-dominated solutions across multiple objectives. Example: "selected using a Pareto-based procedure"
- Patience limit: A stopping rule that halts optimization after a set number of unimproved rounds. Example: "we set a patience limit of 2 (i.e., the number of consecutive rounds with no improvement on the development set before stopping)."
- Prompt optimization: Algorithmic refinement of prompts using feedback signals rather than manual engineering. Example: "towards a more algorithmic 'prompt optimization' process."
- Provenance: The origin or source of evidence, enabling traceability of claims. Example: "ensuring that each claim in the final report can be traced to its provenance."
- Reader agents: Parallel agents that ingest retrieved documents and extract task-relevant evidence. Example: "Multiple parallel reader agents then analyze these documents in batches, extracting task-relevant information according to the instructions defined by the orchestrator."
- Reflection-to-refinement pattern: An iterative loop where outputs are critiqued and used to refine prompts. Example: "both follow a similar reflection-to-refinement pattern"
- Retrieval-Augmented Generation (RAG): A method that augments generation with retrieved context to answer questions. Example: "traditional Retrieval-Augmented Generation (RAG)"
- Round-robin fashion: A cyclic scheduling method that rotates which component is updated next. Example: "selected in a round-robin fashion."
- Rubric criteria: Itemized requirements that define what constitutes a good answer for each query. Example: "the set of rubric criteria used to evaluate candidate answers"
- Self-play: A process where agents improve by exploring and iterating on their own strategies or configurations. Example: "allowing the system to self-play and explore variations and combinations of agent prompts"
- Strictly dominated candidates: Solutions that are worse than others on all considered objectives. Example: "prunes strictly dominated candidates (i.e., candidates that are not the best on any query)"
- TextGrad: A prompt-optimization approach that treats edits as textual gradients guided by evaluations and traces. Example: "TextGrad uses a greedy strategy inspired by the hill-climbing operator of backpropagation"
- Textual gradient descent: Updating prompts by aggregating text-based critiques analogous to gradient descent. Example: "updated via 'textual gradient descent.'"
- Tool call: A structured invocation of an external tool (e.g., a search engine) initiated by an agent. Example: "a search query (formulated as a tool call)"
- Topology optimization methods: Techniques that optimize the structure or connectivity of multi-agent systems, not just their prompts. Example: "and topology optimization methods"
- Trace lengths: The token lengths of recorded execution traces used during optimization. Example: "required drastically reducing trace lengths and batch sizes"
- Writer agent: The component that composes the final long-form report by integrating aggregated evidence with citations. Example: "\circnum{5} call a writer agent (pink), which combines all merged information into a long-form report."
Collections
Sign up for free to add this paper to one or more collections.