- The paper demonstrates that Nano Banana 2 achieves competitive performance against state-of-the-art IR models, excelling in both perceptual and quantitative metrics.
- The methodology underscores the critical role of prompt engineering, showing that longer, fidelity-guided prompts notably reduce semantic drift and enhance restoration precision.
- The study identifies limitations, including prompt sensitivity, stochastic output variations, and over-generation artifacts, which guide future improvements in unified image restoration.
Evaluation of Nano Banana 2 as a Unified Image Restoration Model
Introduction
The study "Can Nano Banana 2 Replace Traditional Image Restoration Models? An Evaluation of Its Performance on Image Restoration Tasks" (2604.03061) systematically examines the capability of Nano Banana 2, a general-purpose, generative text-guided image editing model, for classical and challenging image restoration (IR) scenarios. The research addresses a core question in low-level vision: can high-capacity, instruction-driven generative models subsume the role of specialist IR networks traditionally designed for specific degradations (denoising, deblurring, super-resolution, artifact removal, etc.)?
The authors provide a rigorous empirical analysis focusing on prompt engineering, fidelity versus perceptual trade-offs, robustness across degradation types and scenes, and benchmarking against state-of-the-art (SOTA) IR methods. The study demonstrates that prompt design critically governs restoration behavior, highlights strong quantitative and qualitative results, explores generalization and failure modes, and discusses implications for the evolution of unified vision models.
Prompts, Fidelity, and Restoration Behavior
Prompt formulation was shown to be instrumental in guiding Nano Banana 2's restoration output. The study designs 12 carefully crafted prompts varying in length (short/long) and in explicitness regarding fidelity constraints.
Longer prompts consistently enhance both distortion-oriented metrics (PSNR, SSIM, LPIPS) and no-reference perceptual metrics (MUSIQ, MANIQA, CLIP-IQA), particularly for complex tasks such as text and surveillance restoration.

Figure 1: Long prompts, by supplying more contextual and task cues, yield more precise and detail-consistent image restorations, especially in scenarios with high informational ambiguity.
Fidelity constraints embedded in prompts suppress semantic drift and hallucination, encouraging reconstructions that preserve structure and meaning, quantified by reductions in severe semantic deviations (from 2 infidelity cases per prompt without fidelity constraints, to 0.5 with fidelity cues).

Figure 2: Prompts with explicit fidelity constraints mitigate semantic artifacts, producing results with greater structural and semantic accuracy.
Nevertheless, prompt engineering does not fully resolve model infidelity, as cases of semantic deviation can persist even with strong fidelity cues.

Figure 3: Despite explicit fidelity constraints in prompts, Nano Banana 2 can still hallucinate or alter input content, indicating intrinsic generative model limitations.
Furthermore, the model exhibits a distinct perception–distortion trade-off. Prompts that prioritize fidelity achieve superior PSNR/SSIM, while purely perceptual prompts maximize not-reference metrics but risk unattested, over-enhanced details and semantic shifts.
Stability, Over-Generation, and Output Consistency
The stability analysis demonstrates that Nano Banana 2 is generally consistent across repeated runs for a given prompt and input, but is susceptible to substantial stochastic variations and non-deterministic outputs on complex, ill-posed cases.

Figure 4: In inherently ambiguous or severely degraded scenarios, repeated runs of Nano Banana 2 with identical inputs can produce visible color shifts, scale changes, and structural instabilities.
Additionally, over-generation is frequently encountered: the model amplifies textures, creates unrealistic fine detail, or introduces visually plausible-yet-unsupported structures, especially absent strong fidelity guidance.

Figure 5: Over-generation artifacts include exaggerated textural content and implausible fine structures, limiting reliability in restoration tasks requiring strict content preservation.
Comparative experiments cover diverse scenes (e.g., small faces, crowd, hands/feet, text) and multiple degradations (motion blur, old films, surveillance noise). Nano Banana 2 consistently achieves superior or highly competitive results, particularly excelling in full-reference metrics (SSIM, LPIPS), demonstrably surpassing or matching SOTA IR models like HYPIR, TSD-SR, PiSA-SR, and DiffBIR.

Figure 6: Across highly challenging degradation and scene types (motion blur, old film, surveillance, small faces, hands, text), Nano Banana 2 delivers clearer, structurally-coherent outputs and maintains semantically consistent content.
The user study substantiates these findings: human raters consistently prefer Nano Banana 2's outputs for perceptual quality, awarding it the highest mean score and tightest distribution across examined systems.
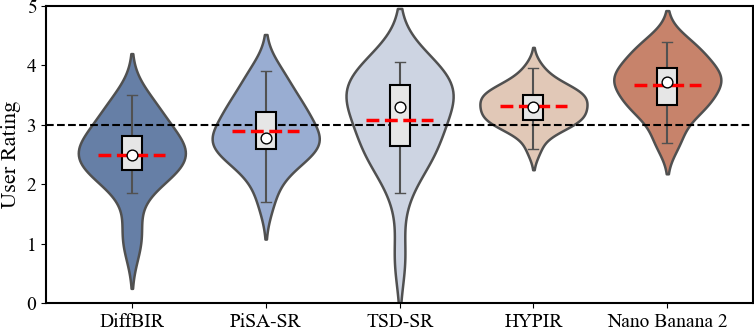
Figure 7: User study results reveal Nano Banana 2's restoration outputs are consistently rated as most perceptually convincing and preferred over competing models.
Limitations, Robustness, and Theoretical Implications
Despite strong generalization and competitive quantitative gains, the research identifies several limitations:
- Prompt Sensitivity: Restoration quality is non-trivially dependent on prompt choice and often requires iterative human intervention and engineering to avoid artifacts or hallucination.
- Stochastic Variability: In complex cases, repeated generations yield non-deterministic outputs, creating practical challenges for applications where reproducibility is required.
- Over-Generation and Infidelity: The model may invent plausible but fictitious structures or fail to accurately reconstruct lost semantics when input is highly ambiguous or information-poor.
These failure modes underscore critical challenges in controlling deep generative systems for restoration. Theoretical implications include a need for more robust prompt-grounded conditioning, hybridization with traditional constraint mechanisms, and deeper understanding of perception–fidelity trade-offs as models become more unified and generalist. Additionally, human-centric evaluation, rather than sole reliance on automated metrics, is highlighted as essential for future model assessment.
Future Directions in Unified AI Vision
Nano Banana 2's performance marks a significant step toward the unification of low-level vision tasks under broad, instruction-driven generative frameworks. Future advances are anticipated in several directions:
- Enhanced controllability and fidelity via cross-modal, constraint-enforced guidance, possibly fusing model-based and generative paradigms.
- Robust prompt engineering with automated, adaptive prompt optimization for downstream IR applications.
- Improved output determinism through structured stochasticity control and better uncertainty quantification.
- Methodological advances in perceptual/semantic evaluation to align model outputs with human judgment in practical deployment scenarios.
Conclusion
This study provides an in-depth, quantitative and qualitative assessment of Nano Banana 2 in image restoration, demonstrating that general-purpose, high-capacity generative models can act as credible, unified restoration engines for a diverse spectrum of tasks. Restoration outcomes hinge critically on prompt engineering and fidelity guidance; pure generative paradigms bring both potential and new risks, particularly with over-generation and semantic drift. Addressing limitations in controllability and stability will be essential for widespread, reliable adoption of such unified models in real-world vision systems.