- The paper introduces an all-modality generative recommendation paradigm using large-scale multi-modal datasets (TencentGR-1M/10M) to model user behavior in advertising.
- The methodology applies a causal Transformer with InfoNCE loss and multi-round evaluation protocols, using metrics like HitRate@10 and NDCG@10 to assess performance.
- The challenge spurs innovations such as action conditioning, semantic ID extraction, and hybrid optimization to address scalability, latency, and real-world deployment constraints.
Tencent Advertising Algorithm Challenge 2025: All-Modality Generative Recommendation
Introduction
The Tencent Advertising Algorithm Challenge 2025 introduces an all-modality generative recommendation paradigm in the industrial advertising context, formalized through the release of the TencentGR-1M and TencentGR-10M datasets (2604.04976). Addressing the scarcity of large-scale, fully multi-modal public benchmarks for generative recommendation systems (GRSs), this competition targets the modeling of user behavior sequences with collaborative identifiers and fine-grained multi-modal (text and vision) representations, thus aligning with the practical demands and privacy standards of real-world advertising applications.
Dataset Construction and Multi-modal Coverage
TencentGR-1M and TencentGR-10M derive from de-identified Tencent Ads logs, carefully constructed to guarantee the inclusion of collaborative IDs and extensive multi-modal embeddings distilled from advanced text and vision models. The preliminary dataset comprises over one million user sequences with up to 100 ad interactions each, while the final dataset expands to over ten million users and incorporates both click and conversion events, enforcing industrial-scale diversity and behavioral heterogeneity.
Key distinctions include: explicit target construction, inclusion of conversion events as rare but high-value labels, and the adoption of coverage-maximized multi-modal embedding extraction. Six embedding models, including both language and vision transformers, underpin the dense multi-modal representation schema, and coverage analysis demonstrates high embedding availability across both datasets.
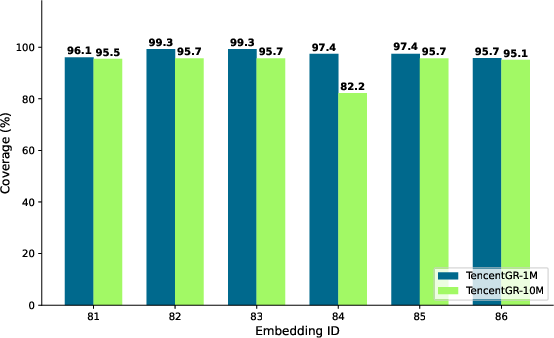
Figure 1: Coverage analysis of multi-modal embeddings across TencentGR-1M and TencentGR-10M under multiple feature extraction pipelines.
Competition Framework and Evaluation Protocol
The challenge employs a multi-round structure: an initial phase for next-click prediction on TencentGR-1M and a subsequent phase on TencentGR-10M, which differentiates both clicks and conversions at sequence and item level. Rigorous rules enforce single-model methodological clarity, prohibit model ensembling, and require autoregressive or generative architectures.
Evaluation protocols are meticulously designed to align with real-world advertising ROI: click and conversion events are separated and weighted in leaderboard metrics. In the preliminary round, HitRate@10 and NDCG@10 (standard top-K ranking metrics) are linearly combined, whereas the second round employs weighted variants (with conversions receiving a relevance weight of 2.5), driving methods to prioritize conversion-centric predictions.
All-Modality Generative Baseline and Modeling Paradigm
The released baseline exemplifies the generative sequence modeling formulation. Feature construction fuses user and item categorical, sparse, and dense (multi-modal) embeddings through concatenation and MLP projection. A causal Transformer backbone encodes the user token-prepended sequence, with output user representations predicting the next item via similarity scoring over a large candidate pool. Item embeddings are pre-computed and cached; retrieval leverages approximate nearest neighbor (ANN) search via Faiss, achieving tractable serving at industrial scale.
The model is trained using InfoNCE loss, with behavior-type-dependent weights in the final round, effectively connecting sequence modeling and retrieval by jointly optimizing for the next likely target (click or conversion) against uniformly sampled negatives.
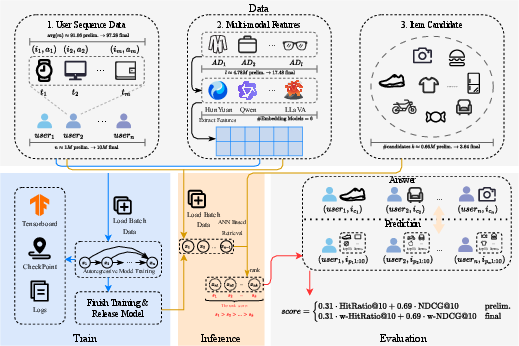
Figure 2: Structural illustration of the competition pipeline detailing data partitioning, sequence modeling, multi-modal feature extraction, and the autoregressive training/inference/evaluation flow.
Model Innovations in Top Solutions
Awarded solutions reveal substantial progress and innovation in generative recommendation with multi-modal content:
- First place: Multi-modal autoregressive model with Qwen backbone and per-position action-conditioning. Integration of FiLM layers, positional and periodic Fourier features, and residual quantized k-means (RQ-KMeans) for semantic ID construction enhanced long-tail generalization. Hybrid optimization and efficient end-to-end vector generation provided strong retrieval performance.
- Second place: Encoder–decoder architecture enriched with gated MLPs, GNN augmentation of interaction graphs, conditional generation, and two-stage pretraining/fine-tuning. Advanced feature composition and post-processing for interaction history exclusions yielded robust scores.
- Third place: Decoder-only Transformer trained with large-scale negative sampling and explicit action conditioning, systematically examining scaling laws (negative sampling rate, depth/width, and embedding dimensions) for generative recommendation models. Findings emphasized the paramount importance of model and loss scale over minor architecture choices.
- Technical Innovation Award: A unified decoder jointly generating next item and action, combining InfoNCE with action prediction loss. The approach incorporated state-of-the-art sequence modeling tools (FlashAttention, SwiGLU, Mixture-of-Experts) and a novel code-collision resolution for robust semantic ID extraction.
Practical and Theoretical Implications
The release of TencentGR-1M/10M and the structured evaluation of all-modality GRSs establish a new industrial benchmark facilitating the empirical study of sequence modeling, multi-modal representation, and advanced semantic identifier tokenization techniques. With dataset sizes, modality coverage, labeling strategies (conversion emphasis), and privacy constraints closely mirroring production scenarios, this benchmark offers a rigorous standard for subsequent method development and ablation.
The strong performance gains from action conditioning, advanced semantic quantization, negative sampling strategies, and hybrid optimization techniques—evidenced in top participant solutions—underscore the field's shift towards integrating explicit behavioral intent with joint contrastive learning and dense retrieval. These outcomes emphasize the open research question of scaling generative approaches under real-world constraints (negative pool size, memory, latency) and offer guidance for future deployment in high-throughput recommendation.
Future Impact and Development Trajectories
TencentGR provides the community with robust open-source baselines and tooling suitable for exploring the intersection of generative modeling, multi-modality, and privacy-preserving data construction. It will likely catalyze further work on conditional sequence modeling, modality fusion, scalable negative mining, hybrid generative-discriminative inference, and production-grade end-to-end retrieval pipelines. Research will increasingly focus on optimizing trade-offs among model scale, annotation granularity, real-time serving latency, and interpretability of semantic ID formation, propelling deployment strategies for next-generation recommender systems in high-value domains.
Conclusion
Tencent Advertising Algorithm Challenge 2025 introduces and benchmarks all-modality generative recommendation in an industrial advertising context, providing large-scale, privacy-conforming datasets (TencentGR-1M/10M) and advanced evaluation protocols prioritizing both clicks and conversions. The competition surfaces new state-of-the-art paradigms in neg-sampled, sequence-conditioned, multi-modal, and action-disentangled GRSs, creating a foundational platform for theoretical and practical advancements in next-generation recommendation.