- The paper introduces Target Policy Optimization, decoupling target distribution formation from parameter adaptation to achieve fixed-point convergence in RL.
- It standardizes candidate scores and applies a closed-form KL-regularized improvement operator to enhance convergence speed and policy alignment.
- Empirical results across bandit, sequence, and LLM tasks demonstrate TPO's robustness and superior performance under sparse reward conditions.
Introduction and Motivation
Target Policy Optimization (TPO) introduces a new approach for reinforcement learning (RL) in group-based settings, where multiple model completions are sampled for a context and scored. Standard policy-gradient methods such as PPO, GRPO, and DG entangle the redistribution of probability mass toward desirable completions with optimizer specifics—leading to update instability, especially under sparse reward regimes. TPO decouples the formation of the target distribution from parameter adaptation, instantiating a closed-form KL-regularized improvement operator on the candidate simplex.
Methodology
TPO constructs the target distribution q for a set of K candidates y1,...,yK in context x by standardizing scores si (producing ui), then setting:
qi∝pioldexp(ui/η)
where piold is the behavior policy snapshot and η is a temperature hyperparameter. The policy πθ is fit to K0 using cross-entropy, yielding a loss gradient of K1. This gradient vanishes exactly at K2, establishing a fixed point absent in typical policy-gradient approaches. Standardization of scores ensures the target depends solely on within-group ranking, removing dependence on absolute score scale.
Empirical Results
Tabular and Neural Bandits
On synthetic tabular bandit tasks, TPO exhibits superior convergence and maintains lowest misalignment to the oracle policy gradient direction (Figure 1).
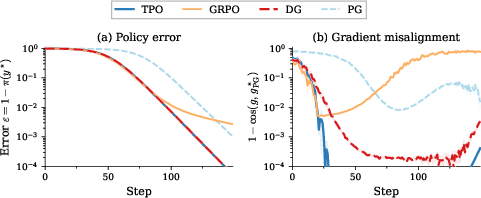
Figure 1: Single-context symmetric bandit (K3); TPO converges rapidly and stays closest to the oracle policy-gradient direction.
In MNIST contextual bandit experiments, TPO achieves fastest convergence and lowest final error, particularly excelling on examples dominated by a single confusing label (Figure 2).
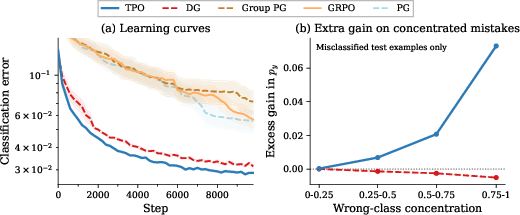
Figure 2: MNIST contextual bandit; TPO converges fastest and reaches lowest error.
On token reversal tasks with dense per-token reward, TPO consistently outpaces GRPO, DG, and PPO on all vocabulary sizes, demonstrating robust scaling as task difficulty increases (Figure 3).
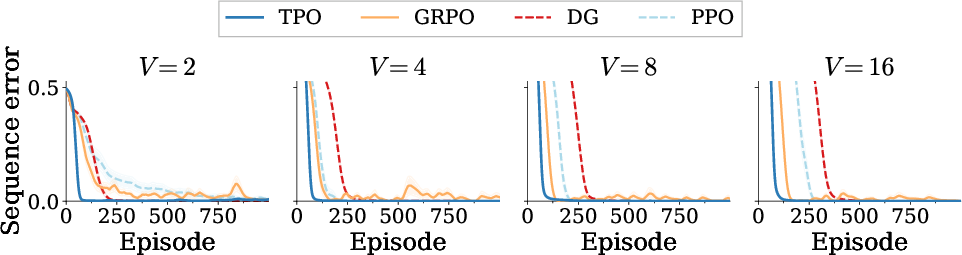
Figure 3: Token Reversal; TPO achieves lowest error across increasing vocabulary sizes.
Across eight sequence variants with both bag-of-tokens and sequential rewards, TPO maintains fast convergence and achieves the highest success rate under sparse reward, where baselines fail (Figure 4).
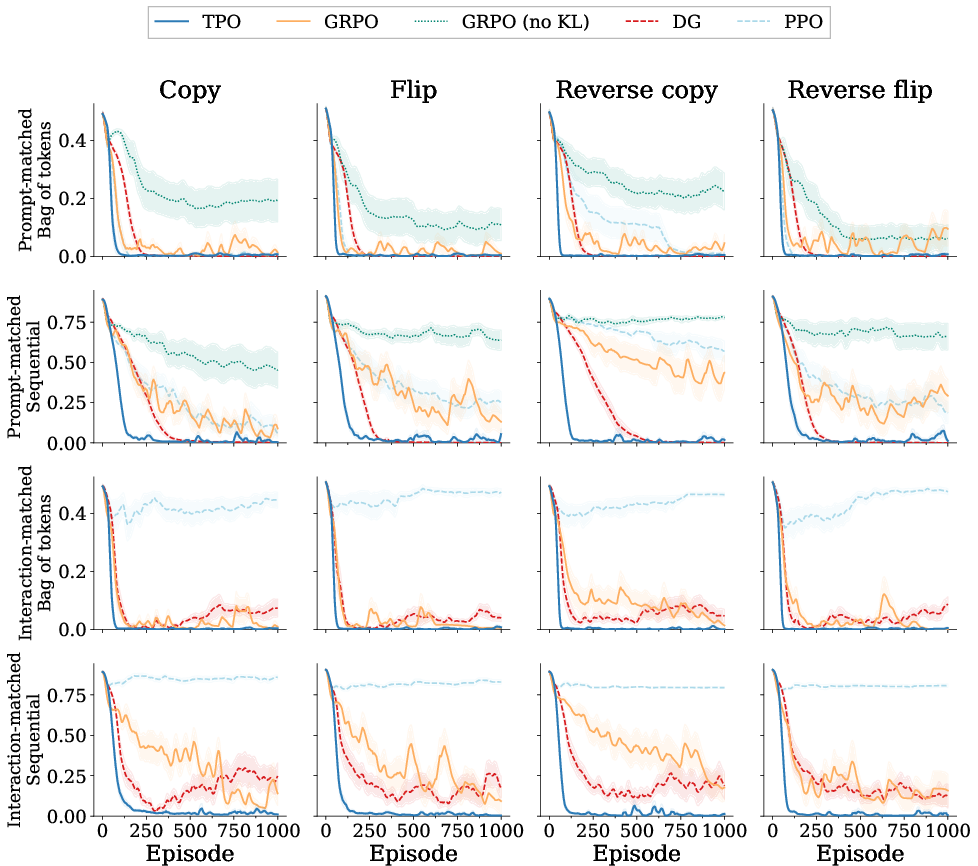
Figure 4: Task variations; TPO dominates across target logics and reward structures.
Sparse Credit Assignment
With terminal reward provided only after a full sequence, TPO delivers lowest error across sequence lengths—even as GRPO, DG, and PPO performance degrades sharply (Figure 5).
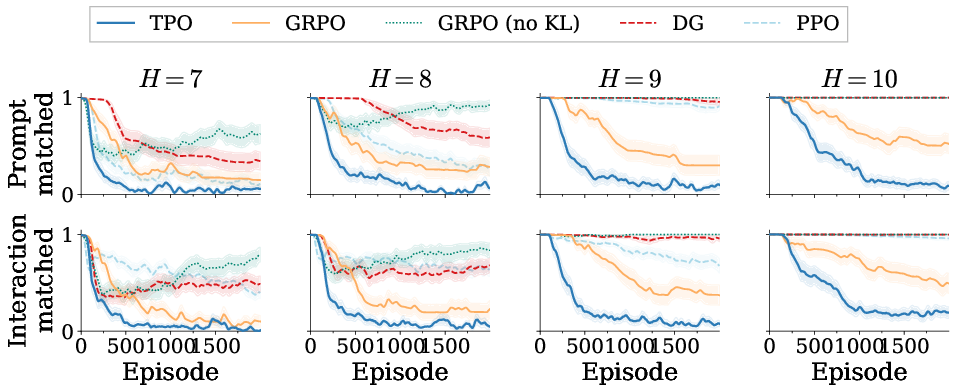
Figure 5: Terminal reward regime; TPO achieves the lowest exact-match error under prompt-matched and interaction-matched budgets.
Ablations isolating TPO's elements (score anchor, target matching) confirm that the full method is required for optimal learning; removing any key component significantly deteriorates performance (Figure 6).
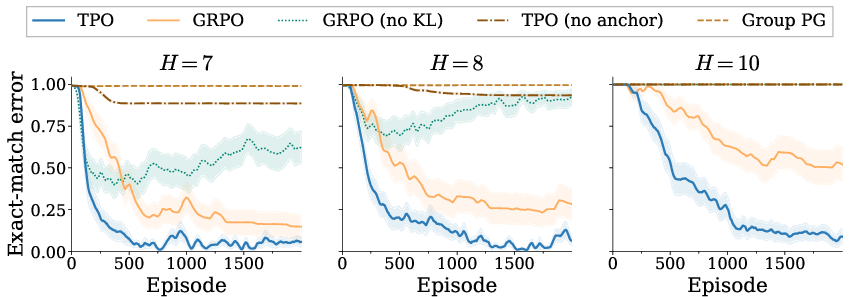
Figure 6: Ablation studies; removal of TPO's anchor, KL penalty, or target matching degrades learning.
LLM RLVR
At billion-parameter scale, TPO demonstrates clear early-learning advantages versus GRPO, particularly on reasoning tasks where GRPO fails entirely or learns much slower (Figure 7).
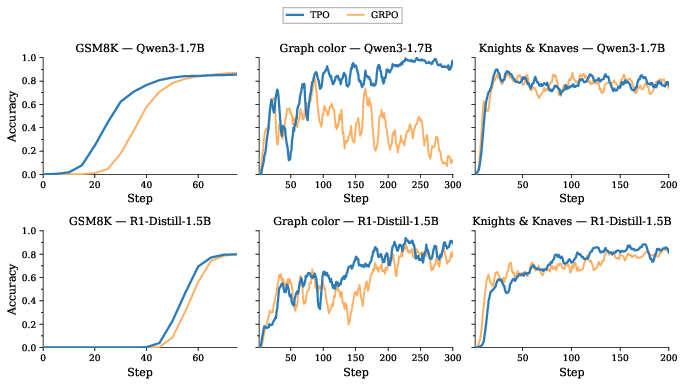
Figure 7: LLM RLVR; TPO achieves rapid learning and superior scores on GSM8K and Reasoning Gym tasks.
Analytical Properties
TPO's loss gradient self-extinguishes as the policy matches the constructed target, in contrast to persistent gradient activity in policy-gradient methods that lack a fixed point (Figure 8).
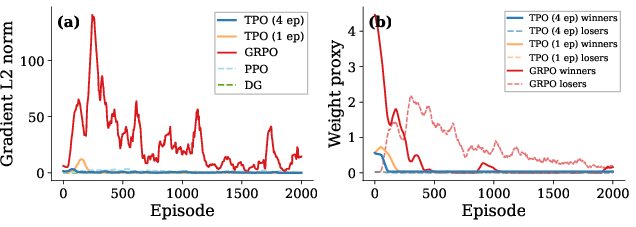
Figure 8: TPO's gradient collapses post-convergence; GRPO's persists, indicating lack of fixed point.
Signal allocation analysis shows TPO rapidly eliminates neutral groups (those with no informative completions), focusing update budget on informative groups and accelerating learning (Figure 9).
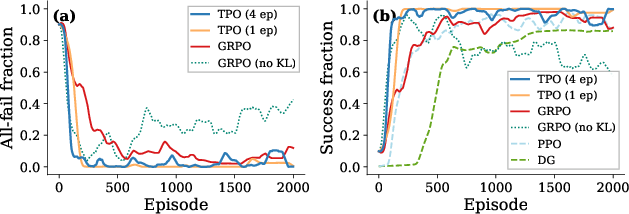
Figure 9: TPO correctly ignores zero-signal groups early in training, concentrating on informative candidates.
Group-size sweeps reinforce TPO's robustness: performance improves smoothly as candidate count increases, unlike GRPO which behaves non-monotonically (Figure 10).
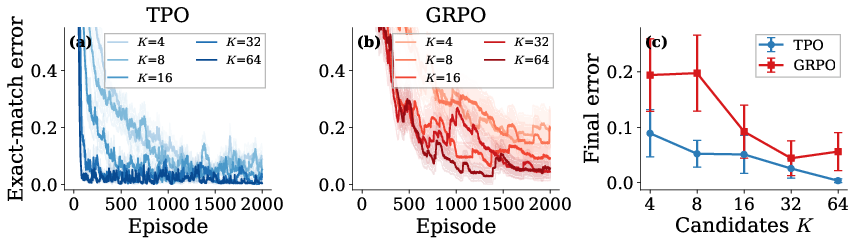
Figure 10: TPO adapts robustly to increasing group sizes; GRPO's performance is inconsistent.
Zero-variance group masking in GRPO severely degrades performance, confirming the necessity of proper anchor mechanisms for group-based RL (Figure 11).
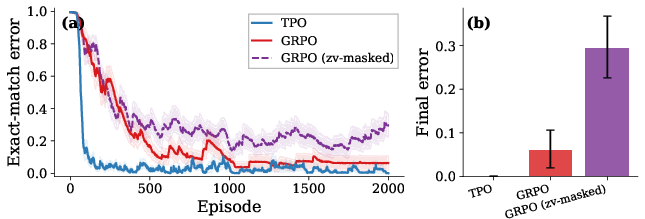
Figure 11: Masking zero-variance groups in GRPO reduces accuracy; TPO does not require explicit masking.
Stable multi-epoch batch extraction is possible with TPO, supporting aggressive data reuse without the instability seen in DG (Figure 12, 16).
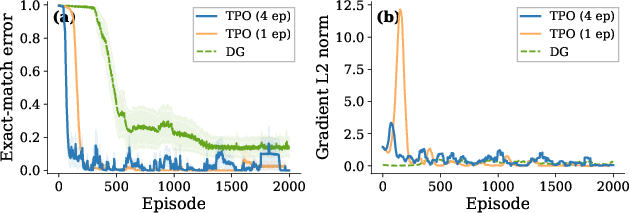
Figure 12: TPO's fixed target supports stable multi-epoch extraction.
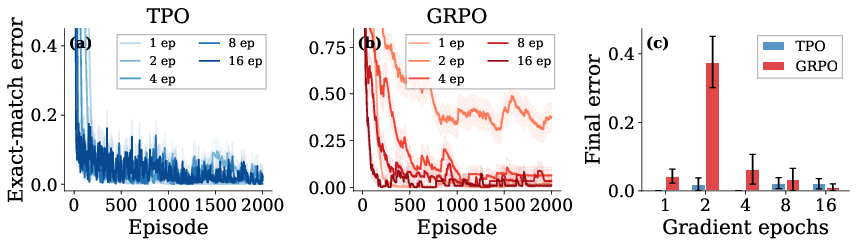
Figure 13: TPO's error remains low across epoch counts; GRPO is highly sensitive to this hyperparameter.
Temperature sweeps validate robustness: TPO operates reliably across a wide range, with only extreme values degrading performance (Figure 14).
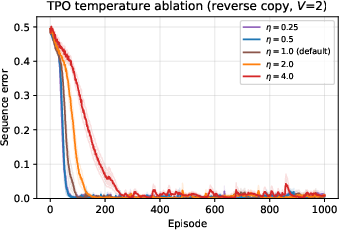
Figure 14: TPO is robust to temperature K4 across a wide range.
Multi-epoch DG diverges under repeated batch extraction, verifying that TPO's cross-entropy-to-target objective is structurally stabilizing (Figure 15).
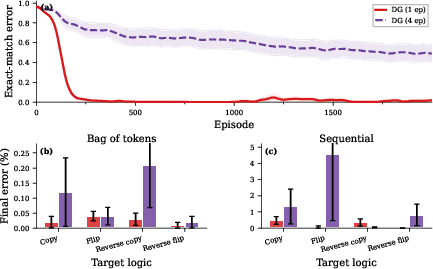
Figure 15: DG fails under multi-epoch update, highlighting TPO's stability advantage.
Theoretical and Practical Implications
TPO's fixed-point update mechanism constitutes a formal improvement operator on scored candidate sets, situating it as a principled successor to REPS and MPO but removing requirements for critics or constrained dual optimization. The practical value is highest in sparse-reward regimes—LLM RLVR, sequence prediction, and hard credit assignment—where standard policy-gradient approaches stall or require kludgy penalties/clipping.
The explicit separation between the desired redistribution of probability mass and the realization by optimizer mechanics makes TPO inherently robust to hyperparameter choices and batch extraction patterns. Task generalization, signal concentration, and stable multi-epoch reuse collectively advance RL training pipelines for both small and extremely large policies.
Limitations
TPO relies on candidate diversity: if sampled completions are uniformly poor, the improvement signal is limited. Per-context group-based RL remains costly in sequence prediction, requiring as many rollouts as candidates per context. Standardization can amplify tiny relative score variations in low-variance groups, potentially introducing unwanted difficulty bias. LLM-scale evaluation is currently restricted to 1.5–1.7B parameter models and a subset of tasks; scalability to 7B+ and harder domains remains to be studied.
Conclusion
Target Policy Optimization replaces scalar-weighted policy gradients with a cross-entropy fit to a score-tilted target on the candidate simplex. Across bandit, sequence, and LLM RLVR tasks, TPO matches baseline performance in easy regimes and outperforms all tested methods under sparse reward. Future developments include large-scale evaluation and integration with advanced off-policy engines, making TPO a central component for robust RL optimization (2604.06159).
