- The paper demonstrates that dual-mode entropy regularization decouples exploration and exploitation, preserving accuracy while fostering diverse outputs.
- It introduces a split into normal and high-entropy modes with collaborative rollout sharing, optimizing both task performance and creative generation.
- Empirical evaluations on reasoning and creative tasks show statistically significant improvements over conventional entropy maximization methods.
Policy Split: Dual-Mode Entropy Regularization for LLM Reinforcement Learning
Motivation and Problem Analysis
Conventional entropy-guided reinforcement learning for LLMs aims to balance exploration and exploitation by directly incentivizing higher entropy in policy rollouts. While this strategy mitigates entropy collapse and can yield marginal diversity improvements, recent analyses highlight a persistent performance degradation as increased entropy tends to undermine the task accuracy of high-performing Large Reasoning Models (LRMs). The mechanism is particularly problematic for post-training "low-entropy" LRMs whose knowledge is already robust; enforcing higher entropy on such models frequently degenerates outputs, as illustrated by empirical observations of accuracy drop with naïve entropy regularization.
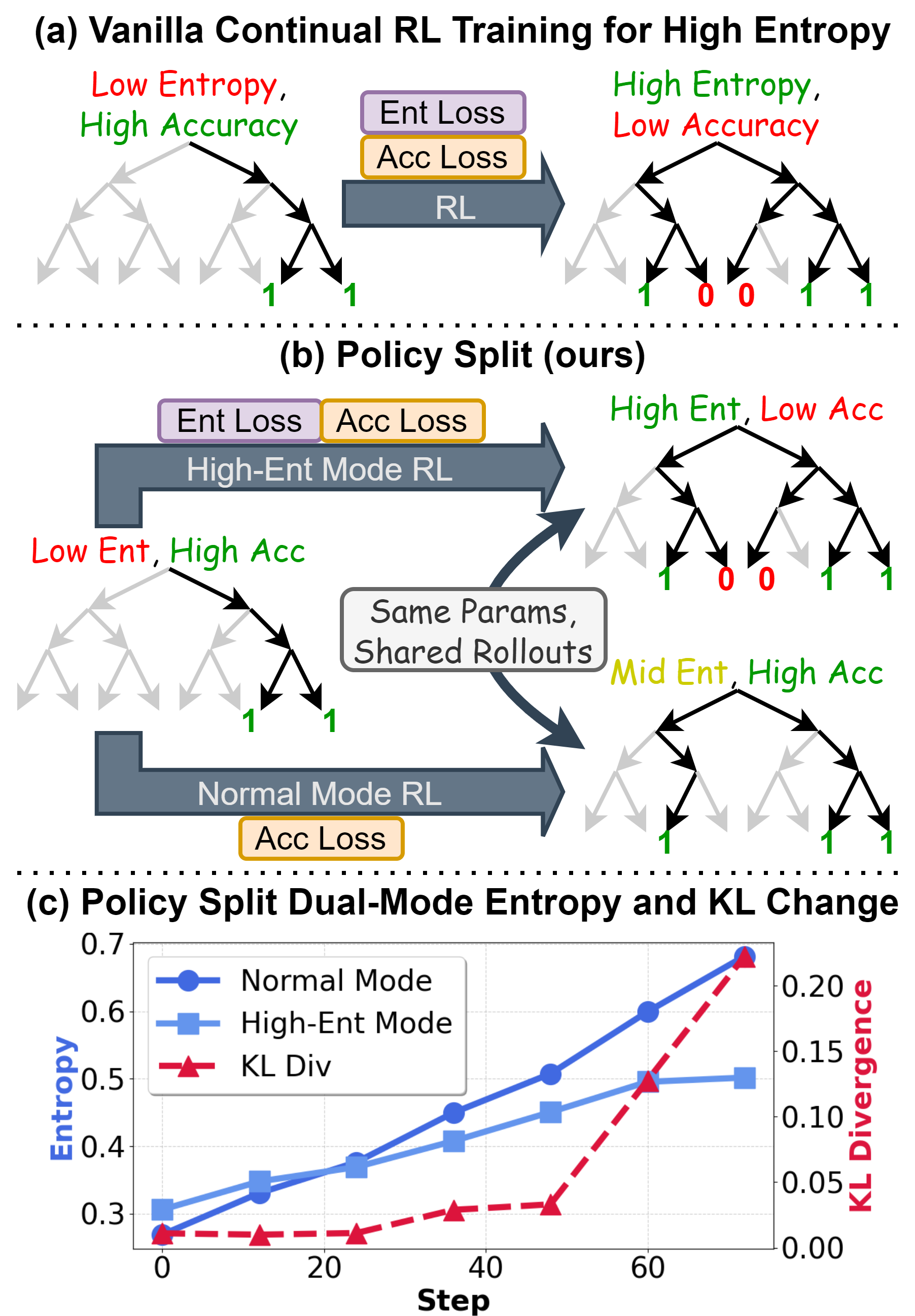
Figure 1: (a) Standard entropy-driven RL methods induce accuracy loss when maximizing entropy indiscriminately. (b) Policy Split bifurcates the policy into independently optimized normal and high-entropy modes. (c) Dual-mode entropy regularization engenders large KL divergence and distinct entropy statistics between modes.
Empirical evidence thus motivates decoupling the exploration-exploitation dilemma into explicit, jointly-optimized modes. The Policy Split paradigm operationalizes this approach, aiming to maximize the utility of high-entropy rollouts for exploration without sacrificing the correctness requirements addressed by low-entropy, exploitation-optimized policies.
Policy Split: Methodology
Policy Split instantiates dual-mode policy optimization inside a unified LLM. By leveraging system prompt-based control, the paradigm enables seamless context-conditioned policy bifurcation into a normal mode (task accuracy focus) and a high-entropy mode (exploration focus). Crucially, parameter sharing preserves model capacity, while the loss landscape is shaped by dual-mode entropy regularization.
In the high-entropy mode, a dedicated natural language system prompt explicitly instructs the model to emphasize cognitive and textual diversity. The core insight, supported by ablations, is that prompting alone is insufficient to trigger high-entropy behaviors without targeted loss modifications; explicit entropy and cross-mode divergence rewards are necessary to shape the desired output distributions.
Dual-mode entropy regularization is formalized as follows: the normal mode optimizes the standard (GRPO) reward-centric advantage, while the high-entropy mode incorporates an augmented advantage containing (a) an explicit entropy bonus and (b) a KL divergence term penalizing overlap with the normal policy. Entropy advantage scaling and clamping are used to stabilize the resulting gradients.
Rollout sharing is employed so that informative (e.g., correct or creative) outputs of one mode are available for cross-policy credit assignment, imposing collaborative learning between modes.
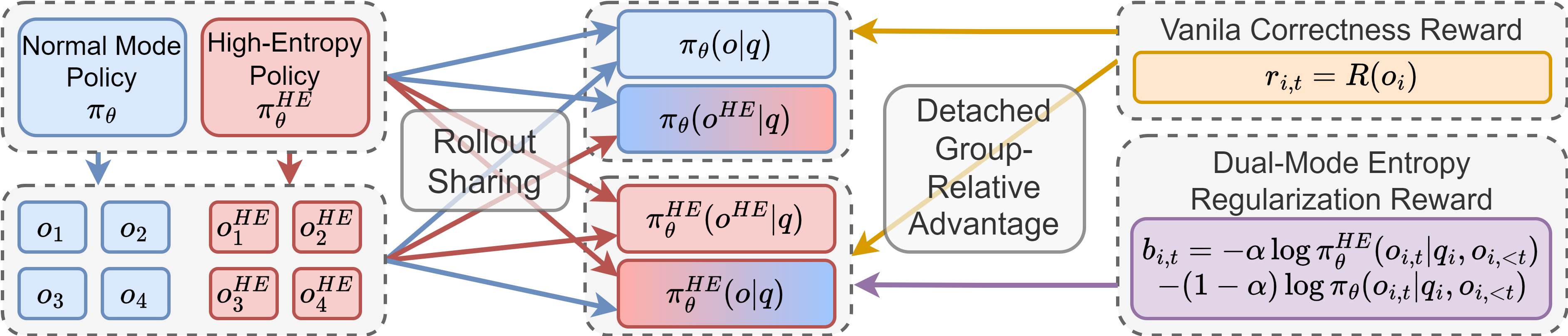
Figure 2: The Policy Split dual-mode RL training pipeline, leveraging prompt-based mode switching and collaborative rollout sharing.
Experimental Validation
General Reasoning Tasks
Comprehensive evaluation is conducted on canonical mathematical and reasoning benchmarks (MATH-500, AIME-24/25, GPQA-Diamond, MMLU-Pro) across multiple Qwen3 model scales (1.7B, 4B, 8B). Policy Split consistently achieves the highest average accuracy and entropy metrics among all methods, with statistical significance (p<0.01). Notably, while direct entropy maximization baselines increase diversity at the expense of accuracy, Policy Split preserves or improves accuracy while still reviving model entropy. High-entropy mode achieves the greatest entropy, indicating successful behavioral decoupling.
Creative Generation Tasks
For open-ended creative writing, Policy Split’s high-entropy mode achieves SOTA diversity scores (N-gram, self-BLEU) and outperforms baselines in LLM-graded rubrics of creativity, originality, and imagery. Critically, this demonstrates practical advantages of dual-mode incentivization: the model can be prompted at test time to generate outputs optimized for creativity without impacting the task-general performance of the normal mode.
Behavioral Analysis
Quantitative analysis of policy statistics (accuracy, entropy, output length, KL divergence) reveals that Policy Split obtains orders-of-magnitude greater inter-mode divergence relative to vanilla RL or prompt-only approaches, satisfying the criterion of dual-mode behavioral separation. Moreover, best-of-N evaluations demonstrate that high-entropy rollouts produce unique correct responses that would otherwise be inaccessible, confirming the practical utility of exploration.
Prompt generalizability experiments show that Policy Split’s entropy control partially transfers to unseen but semantically similar prompting, although explicit training is needed for full generalization to opposite constraints (e.g., low-entropy mode).
Theoretical and Practical Implications
Policy Split introduces a tractable framework for multi-modal policy learning in LLM RL that does not require costly multi-head architectures or independent networks. Systematic decoupling of exploration and exploitation within a single model, combined with collaborative rollout sharing, can be interpreted as an information-theoretic regularization scheme, mitigating the destructive tradeoffs caused by monolithic entropy regularization. The method advances the practical steerability and utility of LLMs across diverse requirements—enabling, with a simple prompt, reliable toggling between accuracy and creativity at deployment time.
Practically, Policy Split is well-aligned with continual post-training scenarios where computational budget is constrained but enhanced model flexibility and steerability are desirable.
Limitations and Future Directions
Like other entropy-incentivized RL algorithms, Policy Split exhibits sensitivity to hyperparameters (entropy coefficient η); excessive incentivization yields training instability and output collapse. Future work should focus on theoretically grounded stability mechanisms, adaptive entropy coefficient scheduling, and improved prompt generalizability (e.g., to fully dynamic user-specified exploration-vs-exploitation needs). Multi-policy extensions beyond dual-mode, integration with reward modeling for safety/task alignment, and applications to multimodal LLMs present compelling avenues for continued research.
Conclusion
Policy Split establishes dual-mode entropy regularization as a powerful paradigm for LLM reinforcement learning, enabling simultaneous optimization for accuracy and creative exploration without cross-mode interference. The formulation yields strong empirical gains over state-of-the-art baselines, with simple deployment via prompting. Theoretical and empirical analyses suggest that policy bifurcation with collaborative learning provides robust mechanisms for flexible inference-time utility and exploratory skill acquisition, foreshadowing future developments in adaptive, multi-modal LLM control.