- The paper presents UEC-RL, a unified framework integrating targeted exploration with entropy stabilization to overcome premature convergence and training instability in RL.
- It employs adaptive temperature adjustments and replay mechanisms to selectively enhance low-probability actions and consolidate beneficial solutions.
- Empirical results demonstrate a 37.9% relative accuracy gain over GRPO and notable improvements in Pass@k metrics across text and multimodal reasoning benchmarks.
Unified Entropy Control for RL: Targeted Exploration and Stabilization in LLMs and VLMs
Motivation and Background
Reinforcement learning (RL) based post-training is a principal paradigm to refine reasoning capabilities in LLMs and VLMs, with Group Relative Policy Optimization (GRPO) gaining prominence due to its efficiency and competitive performance. However, empirical observations have highlighted critical shortcomings in GRPO: rapid entropy collapse leads to premature convergence and loss of output diversity, while highly variable settings (notably in multimodal reasoning) induce unstable training dynamics, undermining robust solution discovery.
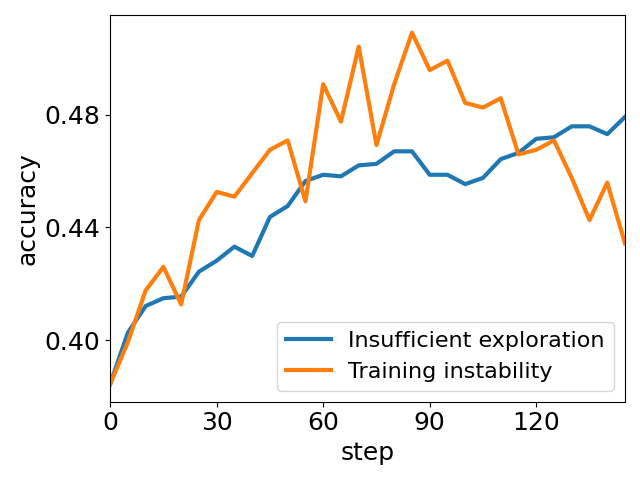
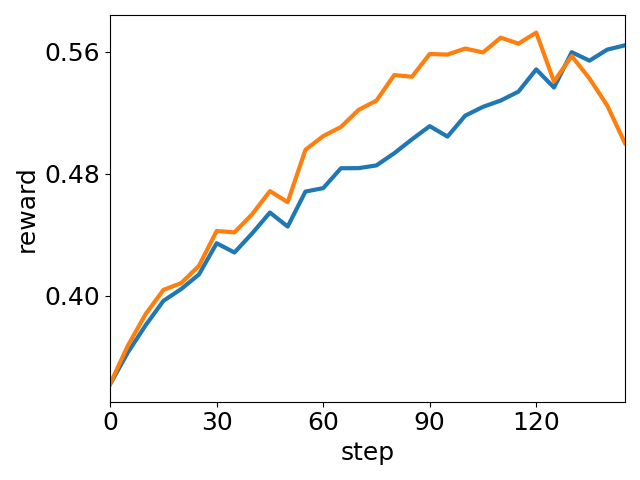
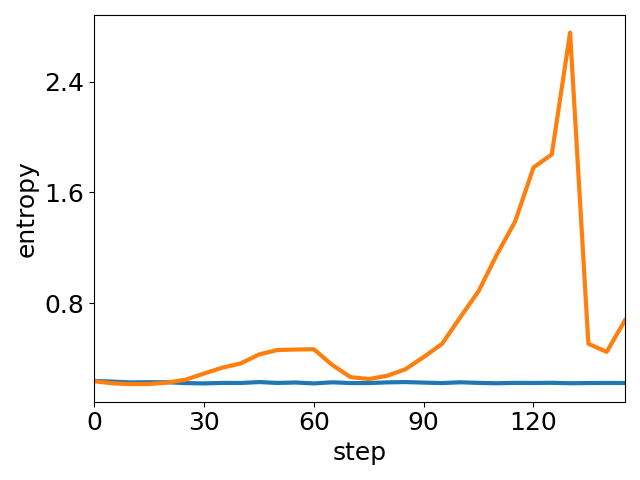
Figure 1: Two prominent optimization issues of GRPO on Geometry3K: insufficient exploration (entropy collapse) and unstable training dynamics.
Prior explorative RL interventions—such as entropy bonuses, modified advantage functions, or clip-higher variants—have failed to jointly mitigate both premature collapse and instability. These methods often introduce undesirable bias or variance, cannot adapt exploration to instance difficulty, and lack explicit entropy regulation mechanisms that can both enable and constrain policy entropy as required.
UEC-RL Framework
Unified Entropy Control for Reinforcement Learning (UEC-RL) introduces a bidirectional entropy regulation mechanism, combining targeted exploration with stabilization to maintain entropy in an optimal operating range.
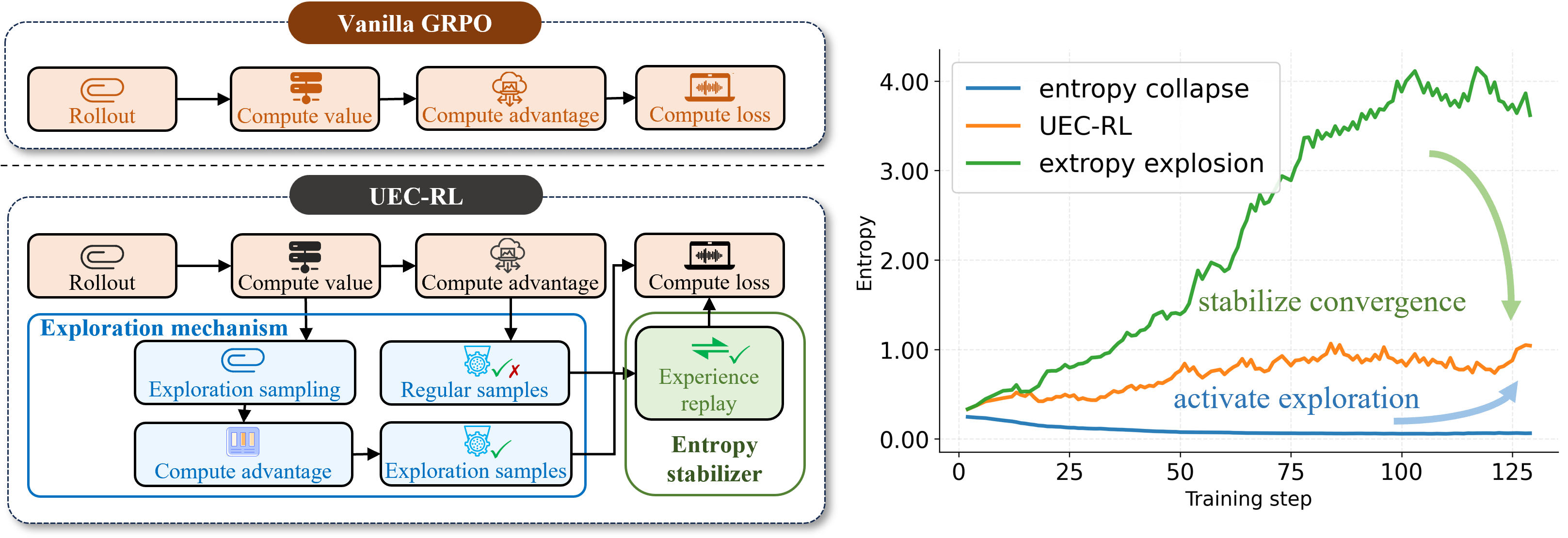
Figure 2: Illustration of UEC-RL. UEC-RL balances exploration and stabilization, keeping entropy within an optimal operating range.
Targeted Exploration
UEC-RL implements targeted exploration by:
- Identifying prompts that are under-solved—specifically, those for which the policy fails to produce a correct output across initial group samples.
- Temporarily raising the sampling temperature for these prompts, thereby softening the output distribution and enabling greater access to low-probability, potentially informative trajectories.
- Filtering exploratory samples to retain only those with positive advantage, ensuring that only reward-relevant diversity influences policy updates.
Entropy Stabilization
Stabilization is achieved using a replay mechanism:
- Buffering high-advantage trajectories (including those discovered via exploration) and periodically replaying them, thereby consolidating reliable solution patterns and actively reducing entropy as learning progresses.
- This explicit replay of informative samples shifts probability mass toward desirable behaviors and counteracts excessive or unproductive exploration.
The framework is theoretically justified through covariance analysis of natural policy gradients, demonstrating that temperature-driven sampling on difficult prompts proactively induces entropy increase when low-probability, high-advantage actions exist. The replay mechanism then induces entropy reduction once reliable responses are identified and reinforced.
Empirical Results
Performance on Text and Multimodal Reasoning
Across standard text reasoning (AIME24, AIME25, MATH, GSM8K, Minerva, ARC, MMLU) and multimodal reasoning (MathVision, MathVerse, MathVista, We-Math) benchmarks, UEC-RL consistently outperforms GRPO, DAPO, KL-cov, and entropy-advantage variants. Notably, on Geometry3K, UEC-RL yields a 37.9% relative accuracy gain over GRPO, indicating marked improvement in both exploration efficiency and convergence stability.
UEC-RL also delivers significant gains on Pass@k metrics, demonstrating that its policy optimizes not only for higher first-attempt accuracy (Pass@1) but also for a broader and higher-quality distribution over correct solutions.
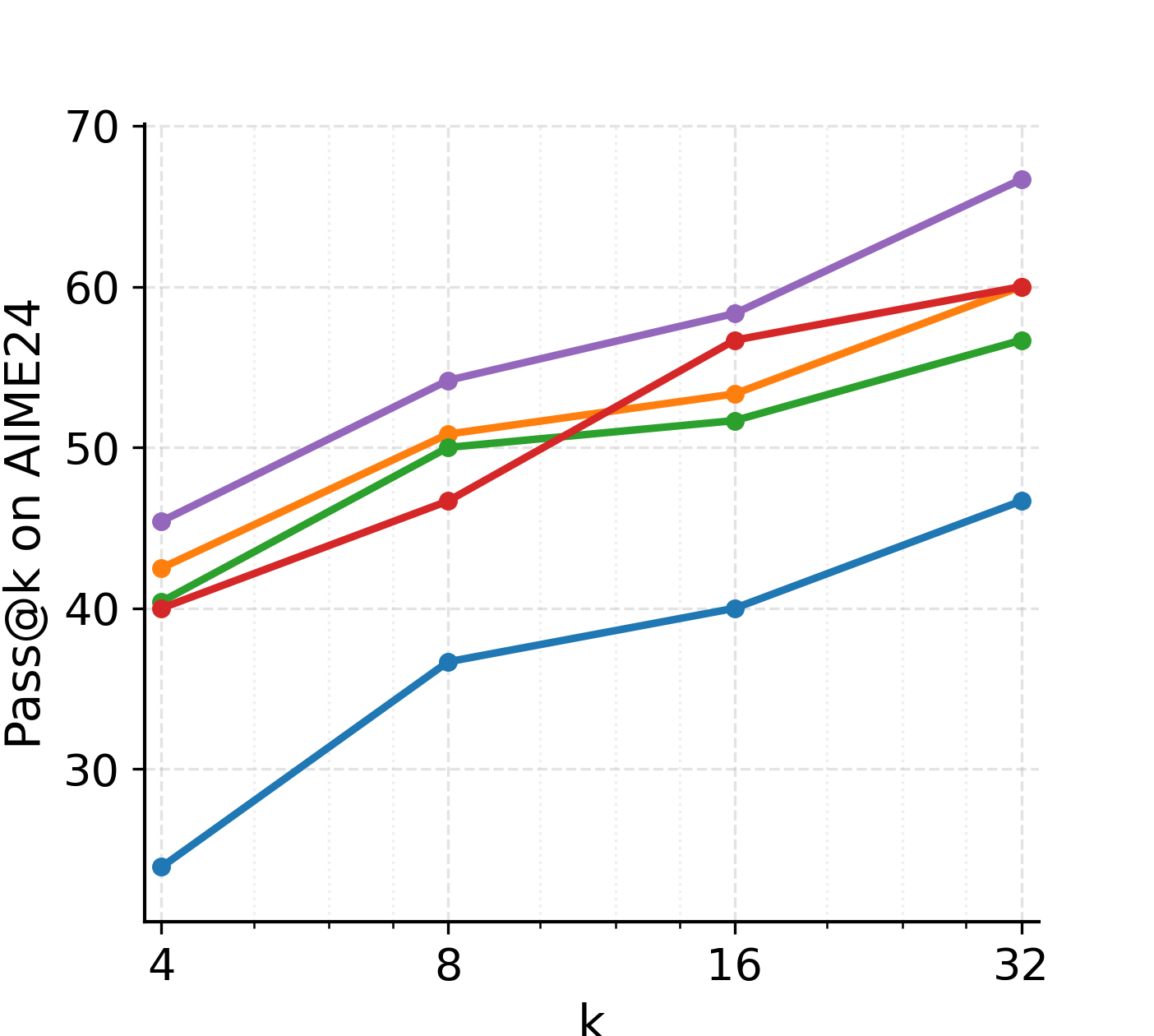
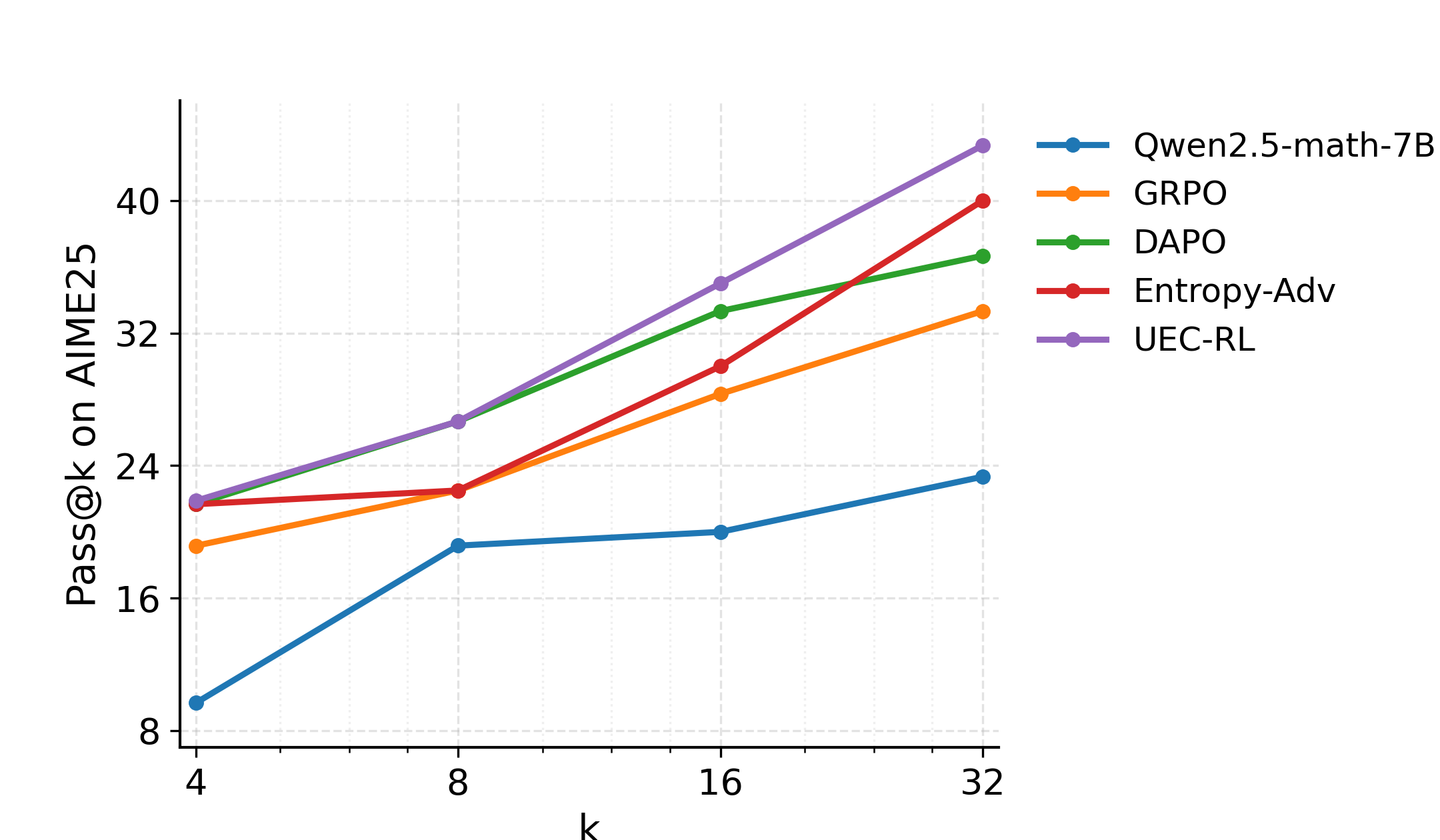
Figure 3: Pass@k performance on the AIME24 and AIME25 benchmarks. UEC-RL consistently improves the success rate across different values of k.
Training Dynamics and Efficiency
On in-domain analysis with Geometry3K, UEC-RL maintains entropy and response length dynamics that are both more stable and more informative than those of baseline methods, avoiding both sudden collapse and divergence. This is achieved with superior training efficiency, measured by reduced step time relative to GRPO.
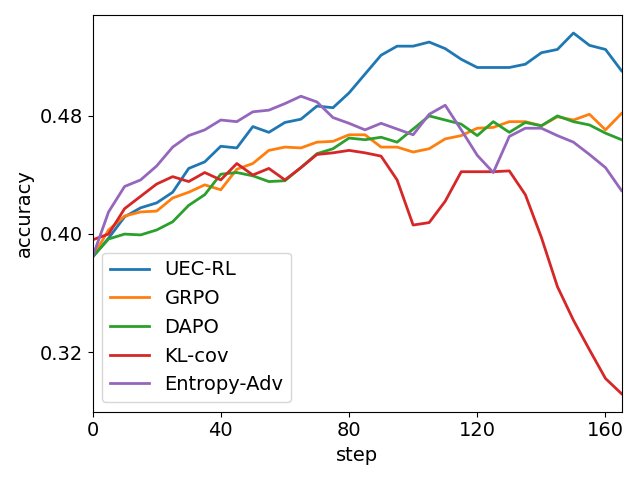
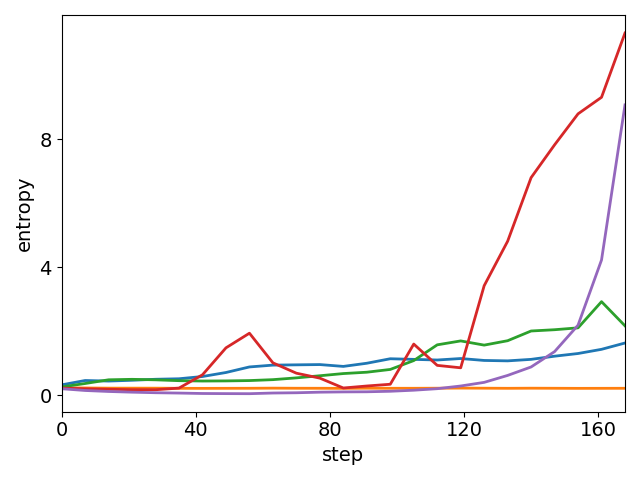
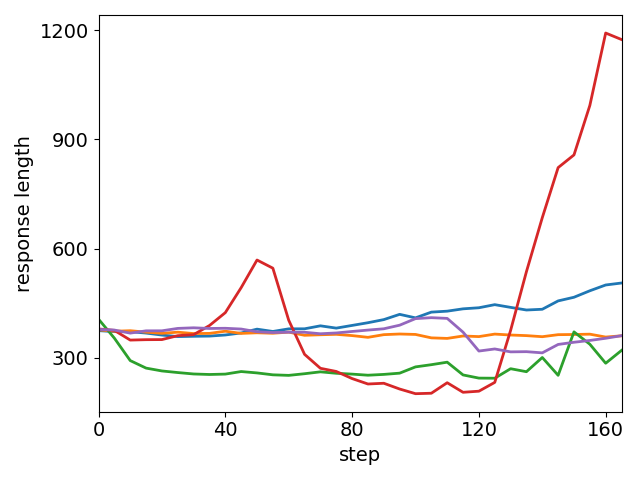
Figure 4: Results on Geometry3K. UEC-RL achieves the best accuracy, exhibits more stable entropy and response-length dynamics, and also demonstrates excellent training efficiency with lower per-step cost than GRPO.
Ablation and Component Analysis
UEC-RL introduces key tunable parameters controlling exploration strength (t′) and stabilizer capacity (s′). An extensive parameter sweep reveals that:
- Increasing t′ raises policy entropy, enabling deeper exploration but risking noisy solutions if not accompanied by adequate stabilization.
- Expanding the replay buffer (s′) enhances stabilization, controlling entropy and improving reliability.
The best empirical performance is observed at a balanced regime, where entropy is dynamically adjusted but kept within a moderate range.
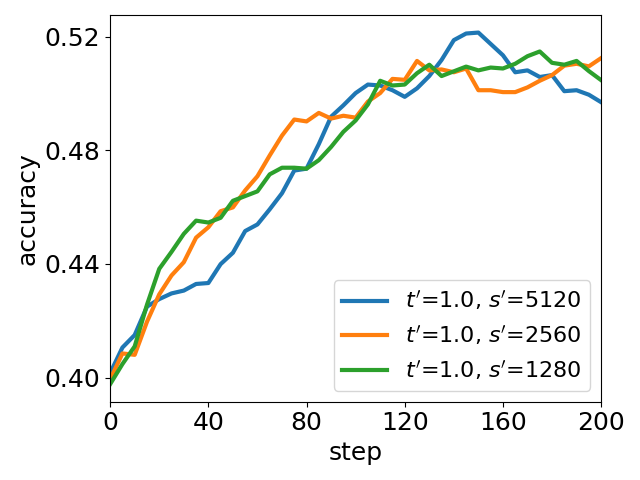
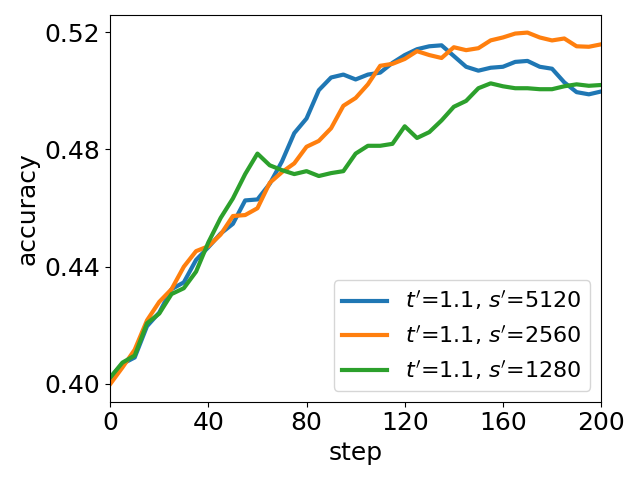
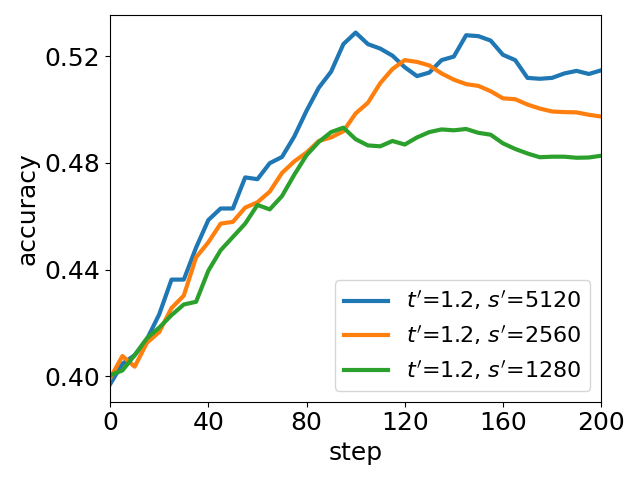
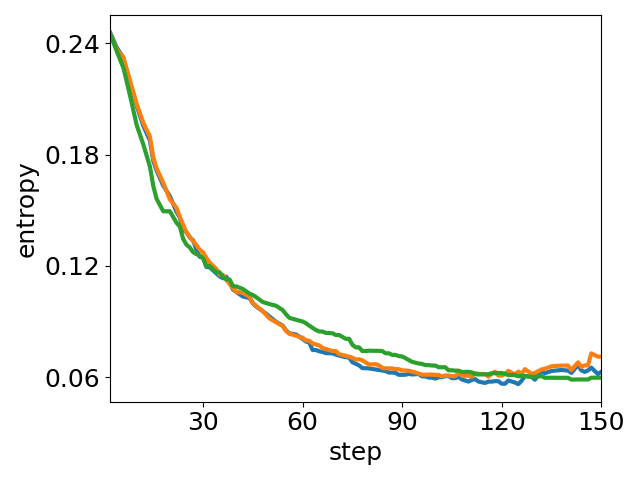
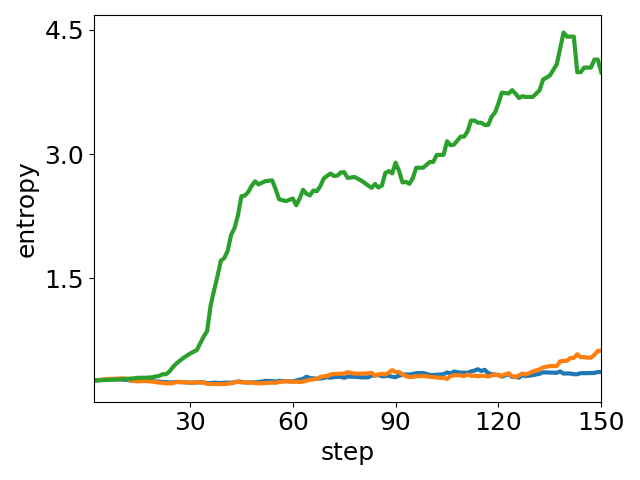
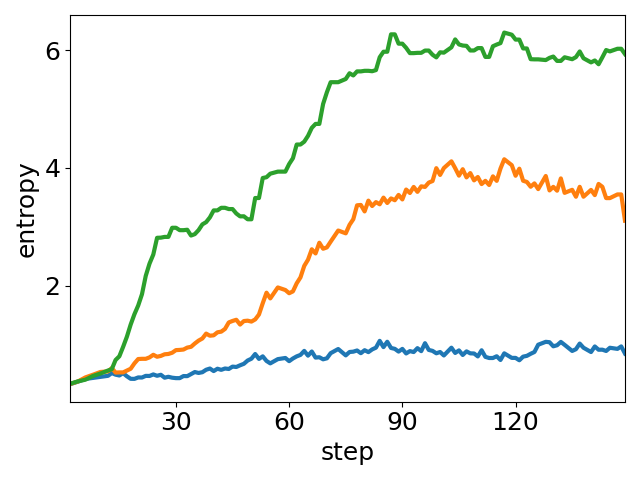
Figure 5: Ablation of parameter tuning: peak accuracy and average entropy under varying t′ and s′. Higher t′ boosts exploration (entropy↑), larger s′ aids stabilization (entropy↓), and best performance arises from the balance state of entropy.
Further, ablating either the exploration or stabilization module results in substantial performance degradation, confirming their complementary roles. Removal of exploration reinstates entropy collapse and local optimality; removal of the stabilizer induces excessive randomness and instability.
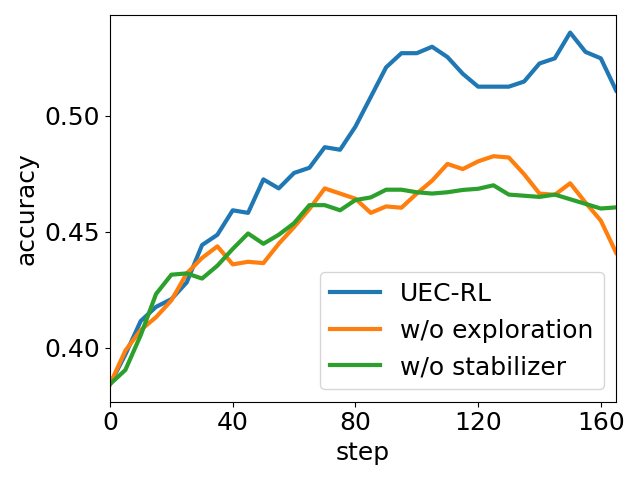
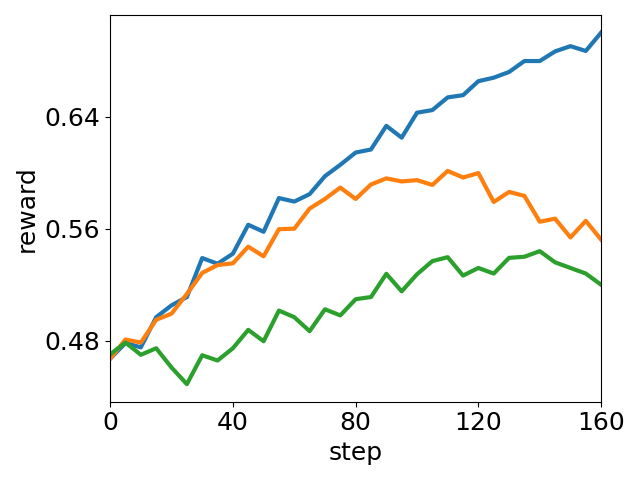
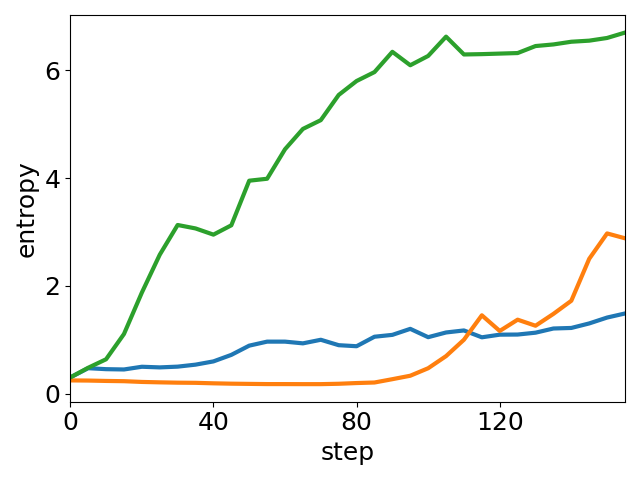
Figure 6: Module ablation of UEC-RL. Removing either exploration or stabilizer consistently degrades performance, highlighting their complementary roles in improving accuracy.
Implications and Future Directions
The UEC-RL paradigm validates the premise that effective RL-based alignment in reasoning-centric LLMs and VLMs requires dynamic, bidirectional entropy control, rather than static or unidirectional interventions. This approach generalizes across LLM and VLM architectures, task families, and modalities, as evidenced by results on a broad evaluation suite.
Practical implications are immediate for training robust, generalizable models for mathematical, scientific, and commonsense reasoning, particularly in scenarios where output diversity (for verification, self-refinement, or downstream exploration) is crucial. Theoretically, the UEC-RL principle suggests future directions such as:
- Automated difficulty-aware exploration scheduling.
- Adaptive entropy regime tuning with minimal manual intervention.
- Step-level or hierarchy-level entropy branching in agentic and multi-step reasoning systems, aligning with emerging approaches for modular and compositional AI reasoning.
- Application of unified entropy control in curriculum RL, off-policy learning, or multi-agent collaborative reasoning frameworks.
Conclusion
UEC-RL establishes a robust solution to entropy collapse and instability in RL-based training for LLMs and VLMs. By integrating targeted, difficulty-sensitive exploration with memory-based stabilization, it consistently surpasses baseline RL methods in accuracy, sample efficiency, and training dynamics. This work underscores the necessity of active, unified entropy control for scalable reasoning, and offers practical guidance for future work in RL-driven model post-training for advanced AI systems.
(2604.14646)