GLM-5V-Turbo: Toward a Native Foundation Model for Multimodal Agents
Abstract: We present GLM-5V-Turbo, a step toward native foundation models for multimodal agents. As foundation models are increasingly deployed in real environments, agentic capability depends not only on language reasoning, but also on the ability to perceive, interpret, and act over heterogeneous contexts such as images, videos, webpages, documents, GUIs. GLM-5V-Turbo is built around this objective: multimodal perception is integrated as a core component of reasoning, planning, tool use, and execution, rather than as an auxiliary interface to a LLM. This report summarizes the main improvements behind GLM-5V-Turbo across model design, multimodal training, reinforcement learning, toolchain expansion, and integration with agent frameworks. These developments lead to strong performance in multimodal coding, visual tool use, and framework-based agentic tasks, while preserving competitive text-only coding capability. More importantly, our development process offers practical insights for building multimodal agents, highlighting the central role of multimodal perception, hierarchical optimization, and reliable end-to-end verification.
First 10 authors:

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces GLM-5V-Turbo, an AI model that can understand and use both words and visuals (like images, videos, webpages, and app screens). Think of it as a smart assistant with eyes and hands, not just a voice: it can look at pictures, read screens, plan what to do, use tools on the internet, and write code. The big idea is to make visual understanding a built‑in part of the model’s thinking and actions, not an add‑on.
What questions were they trying to answer?
The team focused on simple, practical questions:
- How do we build an AI that sees, thinks, and acts in real software and web environments—not just chats?
- How can the “seeing” part (vision) and the “thinking” part (language/reasoning) learn together so the model can plan and use tools better?
- How can we train this safely and efficiently across many types of tasks (recognizing objects, reading screens, searching the web, writing code, clicking buttons, etc.)?
How did they build and train it?
They combined several ideas so the model’s “eyes,” “brain,” and “hands” work smoothly together.
A new set of “eyes” for the model: CogViT
- CogViT is a vision encoder—the part of the model that looks at images and turns them into something the AI can understand.
- It was trained in two steps: 1) Practice filling in missing parts of images (like a smart puzzle) while learning from strong “teacher” models. 2) Learn to match images with the right text descriptions across different sizes and languages.
- Result: better at fine details (like small text on a chart) and spatial layout (where things are on a page).
Faster, image-friendly “talking”: MMTP
- MMTP (Multimodal Multi-Token Prediction) helps the model predict several words at once, which makes it faster.
- Challenge: how do you handle image information in a system designed for text? The team used a simple “placeholder” image token (like a special symbol that means “there’s an image here”) so the model can stay fast and stable while still using what it saw.
Training by “practice with feedback” (reinforcement learning)
- After basic training, the model practiced over 30 kinds of tasks: spotting things in pictures, reading charts, solving math problems with images, using tools, navigating apps, and writing code.
- It received feedback from automatic checkers (“judges”) to learn what worked.
- This broad practice helps the model improve across many areas at once and learn general strategies (not just memorize one task).
A stronger training “gym”
- They redesigned their training system so it can:
- Handle mixed tasks (single-step and multi-step).
- Overlap steps to save time (while one batch runs, another is checked).
- Manage memory well for pictures and videos (which are big).
- Balance workloads so long or short videos don’t slow everything down.
More tools and real-world integrations
- The model can call visual tools (crop images, draw boxes, read webpages, search by image, etc.) and connect to agent frameworks like Claude Code and AutoClaw. This turns it from a “chatbot” into an actor that can see a screen, decide next steps, and execute them.
A new test: ImageMining
- ImageMining checks whether a model can “think with images” and “search deeply with images.”
- Tasks often require zooming in on a detail, cropping, then searching the web with that visual clue—like a detective chasing leads through pictures, not just text.
What did they find, and why is it important?
GLM-5V-Turbo performed strongly on many real tasks where seeing and acting matter. In plain terms:
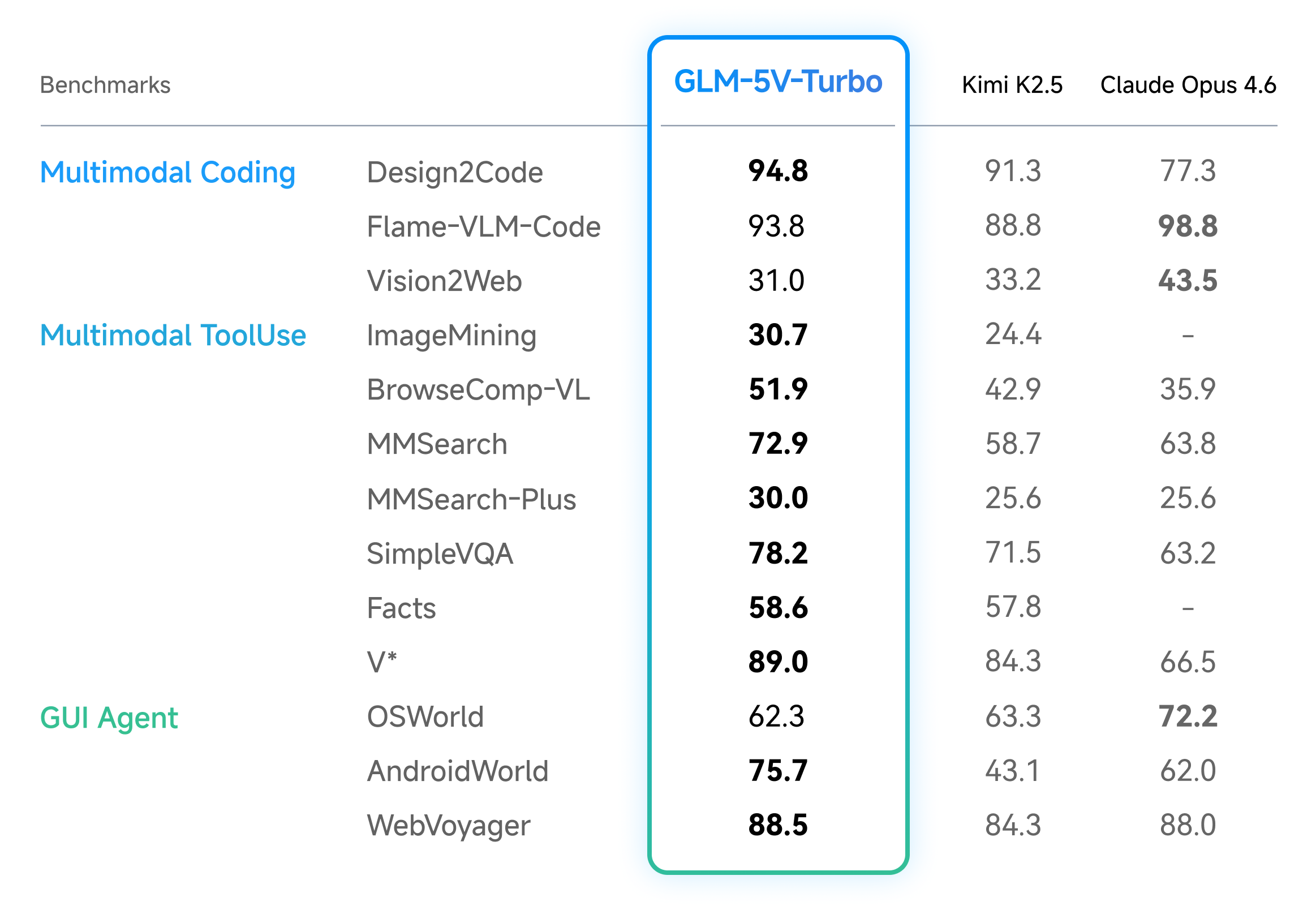
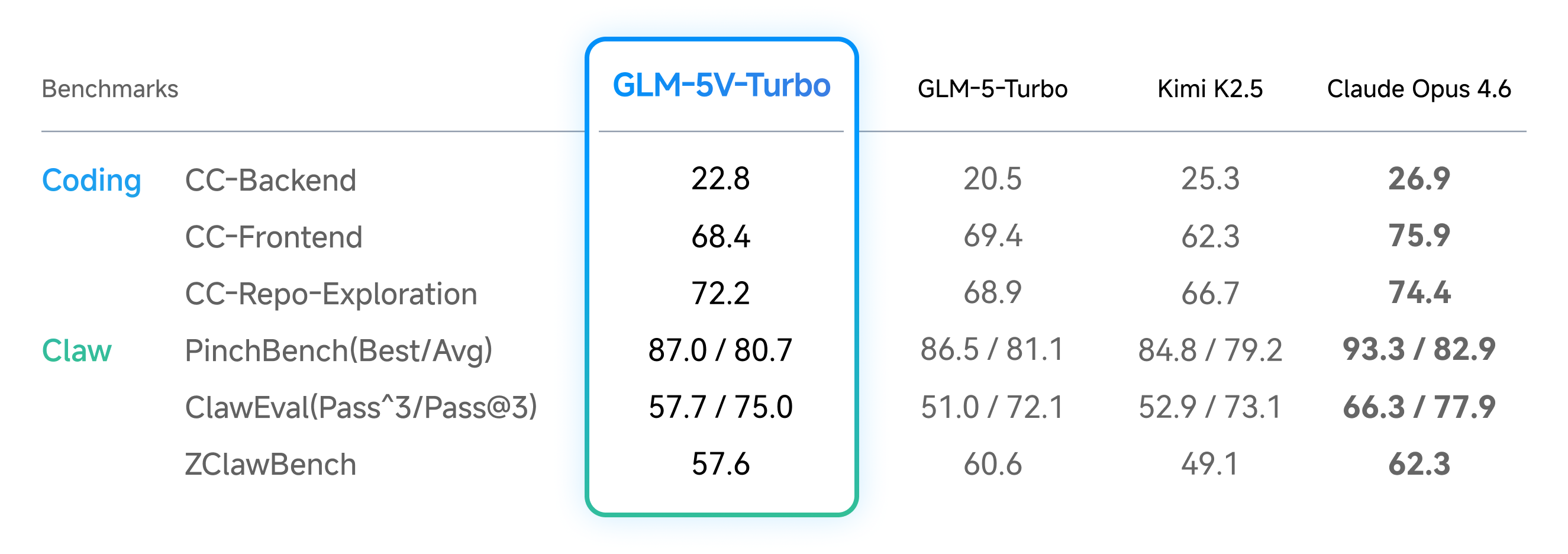
- It’s good at turning designs into working code, and it keeps strong text-only coding ability.
- It can use tools to search the web with both text and images, read webpages, and gather evidence from visuals.
- It can act as a GUI agent: understanding app screens, clicking the right buttons, and following multi-step plans.
Why it matters:
- Many real jobs (researching online, building websites, analyzing PDFs, exploring apps) are visual and interactive. A model that can see, plan, and act directly on screens is much closer to a helpful digital coworker than one that only chats.
Here are a few concrete capabilities this model showed:
- Multimodal coding: It can look at a UI design and generate clean frontend code that matches the layout and style.
- Visual tool use: It can crop images, highlight elements, and search by image to track down facts or sources.
- GUI tasks: It can navigate app or website interfaces step by step, using screenshots and structured actions.
- Deep research: It can gather text and images from multiple sources, then produce a well-structured, evidence-backed report or slide deck.
What does this mean for the future?
If AI can natively see and act, it can help with:
- Building software from mockups and specs faster.
- Doing “deep research” that uses figures, charts, and screenshots—not just text.
- Automating multi-step computer tasks (like a careful assistant who follows on-screen instructions).
The paper also shares lessons and challenges:
- Perception first: Better “seeing” leads to better decisions. Many failures start with misreading a screen or an image.
- Learn in layers: Training small skills (like “find the button”) helps big skills (like “finish the whole task”) work better and more reliably.
- Clear goals and checks: For long, multi-step tasks, you need clear instructions and reliable ways to verify success.
- Open problems remain:
- Strategy discovery: How can the model invent better plans rather than copy human examples?
- Memory for visuals: Images and videos are big—how do we remember the right visual details over long tasks?
- Model + harness: Real ability depends on both the model and the system around it (tools, memory, verification), which need to evolve together.
In short, GLM-5V-Turbo is a strong step toward AI that doesn’t just talk—it sees, plans, and gets things done in real, visual computer environments.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated, concrete list of what the paper leaves missing, uncertain, or unexplored, to guide future research:
- CogViT transparency and reproducibility:
- Missing architectural specifics (e.g., parameter counts, patch sizes, depth/width, training steps) and ablation studies (e.g., effect of QK-Norm, Muon, NaFlex) to enable independent replication.
- Absent quantitative, controlled comparisons against SOTA encoders on standard public leaderboards with exact metrics and datasets.
- Two-stage vision pretraining design choices:
- No ablations on teacher selection or mixing (SigLIP2 vs DINOv3 vs alternatives), masking ratios, or data-mixture proportions to justify the adopted recipe.
- Effects of the 8B bilingual image-text corpus composition (domains, quality filtering, licensing) on generalization, bias, and legality are unreported.
- MMTP with shared <|image|> token:
- Unquantified information loss from collapsing all visual tokens to a single learnable token at the MTP head; unclear impact on tasks requiring fine-grained visual conditioning during decoding.
- Ablation is only on a 0.5B model; it remains unknown whether the observed stability/performance benefits hold at larger scales and across task families.
- No comparison of MMTP inference latency/throughput vs. alternatives (e.g., direct visual embedding pass-through) in real agent loops.
- Video and temporal modeling:
- The paper reports MVBench gains but does not describe how video is represented (frame sampling, temporal encoders, aggregation) or how memory over time is handled.
- Lack of evaluations in streaming or real-time video settings and on long-duration temporal reasoning benchmarks.
- Multi-task RL coverage vs. forgetting:
- Catastrophic forgetting in capabilities not covered by RL is acknowledged but unmeasured; no mitigation (e.g., rehearsal, EWC, constrastive regularizers) is evaluated.
- No quantitative study of how RL task coverage breadth/weighting shapes generalization boundaries or how proxy tasks transfer across domains.
- Reward modeling and verifier reliability:
- Sparse detail on reward aggregation strategies, quality control, and calibration of model-based judges; susceptibility to reward hacking and verifier exploitation remains untested.
- No cross-judge agreement studies, error taxonomies, or sensitivity analyses showing how verifier noise affects RL outcomes.
- Hierarchical optimization vs. monolithic training:
- Although advocated, no controlled experiments compare hierarchical curricula against monolithic end-to-end training on identical tasks/data to quantify stability/efficiency gains.
- Tool-use generalization and robustness:
- The model integrates multiple proprietary tools (zai_*), but generalization to unseen tool APIs, schema changes, and tool failures is not evaluated.
- Robustness to dynamic webpages, DOM drift, CAPTCHAs, network errors, and adversarial page content (e.g., prompt injection in HTML/JS) is untested.
- Long-horizon multimodal memory:
- While identified as a bottleneck, no concrete mechanisms or experiments are provided for visually faithful memory/summary, retrieval, or compression over extended trajectories.
- No benchmarks or metrics for evaluating multimodal memory fidelity (preservation of layout, spatial relations, or temporal states) under tight context budgets.
- Safety, security, and alignment in agentic settings:
- No systematic evaluation of defenses against prompt injection, data exfiltration, sensitive-content handling, or unsafe code execution when browsing/using tools.
- Absence of red-teaming results, refusal behaviors, or policy-compliance metrics in multimodal, tool-enabled contexts.
- Biases and fairness:
- Cross-lingual coverage is limited to Chinese-English; performance and bias across other languages, scripts, and regions are unexamined.
- Tools such as person recognition raise fairness/privacy concerns; the paper provides no bias audits or mitigation strategies.
- Efficiency and cost:
- Large-batch (64K) pretraining and large-scale RL infrastructure are described, but compute budgets, energy consumption, and cost-performance trade-offs are not reported.
- End-to-end agent latency (planning + perception + tool calls) and throughput in practical deployments are unquantified.
- Data and benchmark openness:
- Core pretraining and RL datasets (beyond ImageMining) are not released or sufficiently described for replication; potential contamination with evaluation sets is not addressed.
- ImageMining’s scale (217 cases) and curation process may limit generality; leakage checks, inter-annotator agreement, and difficulty calibration are not reported.
- Interpretation of gains:
- Many reported improvements are relative to the authors’ prior models or in harness-specific conditions; controlled head-to-head comparisons with public baselines under identical tool/internet settings are lacking.
- Limited error analysis to attribute gains to perception, planning, or harness policies; no ablation on the harness’s contribution to benchmark scores.
- Model–harness entanglement:
- While acknowledged, the paper does not provide systematic methodology to disentangle model vs. harness contributions (e.g., swapping harness components, standardized harness-agnostic probes).
- No guidance on how harness designs should co-evolve with model capability regimes or how to benchmark across differing harnesses fairly.
- Generalization beyond GUIs and web:
- Transfer to non-web GUIs (e.g., desktop apps with custom rendering), embedded systems, or AR/VR interfaces is unexplored.
- Physical-world perception–action loops (robotics, egocentric vision) are out of scope but central to “native” agentic grounding.
- Error handling and recovery:
- The agent’s strategies for detecting, explaining, and recovering from tool failures, OCR errors, or misperception are not characterized or benchmarked.
- Hallucination and factuality:
- Although self-critique is mentioned for GUI tuning, there is no quantitative evaluation of hallucination rates in multimodal generation, especially for visually grounded claims.
- Explainability and strategy discovery:
- Open question remains on how to induce and verify emergent agentic strategies (sub-agent decomposition, multi-agent collaboration); no experiments or metrics are proposed.
- Security and privacy of training data:
- Legal/ethical handling of the 8B bilingual image-text corpus (copyright, PII, biometric data) is not documented; privacy-preserving training practices are unspecified.
- Scaling laws and transfer:
- No scaling analyses (data/model/compute) for multimodal RL or MMTP; transfer learning behavior across modalities/tasks as a function of scale remains unknown.
- Deployment reliability:
- Absence of stress tests under extreme conditions (low-res/occluded images, noisy OCR, device constraints) and of monitoring/rollback strategies for production agents.
- Formal evaluation protocols:
- Lack of standardized, controlled evaluation protocols that fix tool availability, network state, and judge policies to ensure reproducibility across labs.
- Release artifacts:
- It is unclear which components (model weights, CogViT encoder, RL Gym, verifiers, tools) will be released, hindering community verification and extension.
These gaps highlight concrete avenues for future work: publish reproducible specs and datasets; quantify MMTP trade-offs; develop and evaluate multimodal memory and safety defenses; run controlled, harness-agnostic benchmarks; and study scaling, bias, and robustness systematically.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that can be built today using GLM-5V-Turbo’s capabilities, tools, and integrations (e.g., Z.ai tools, Claude Code, AutoClaw/OpenClaw). Each item notes relevant sectors and key dependencies that may impact feasibility.
Industry
- Multimodal RPA and GUI automation for operations
- Sectors: software, IT operations, customer support, finance back-office
- What: Automate complex desktop/web workflows by perceiving on-screen elements and executing actions via AutoClaw/OpenClaw; navigate dashboards, browser-based CRMs/ERPs, and forms; validate outcomes with screenshots.
- Tools/workflows: AutoClaw + GLM-5V-Turbo as vision-language controller; BrowseComp-VL style browsing; zai_read_webpage, zai_load_image_from_url; model-guided screenshotting and on-image annotations (e.g., zai_draw_image_bounding_boxes).
- Dependencies/assumptions: Stable browser/OS harness; permissioned access to systems; clear task specification and verifiers; organization-approved automation policies; GPU availability for vision-heavy inference.
- Design-to-code and rapid web/app prototyping
- Sectors: software, product design, martech
- What: Convert UI mockups/screenshots into HTML/CSS/JS; reproduce websites from screenshots; generate slide decks and web pages from PRDs and visual references.
- Tools/workflows: Design2Code capability; Vision2Web-style specification and workflow-based verification; zai_generate_web_html, submit_plan, apply_edits, zai_generate_web_outline/slide_html.
- Dependencies/assumptions: Consistent UI assets; agreed verification (visual/functional); integration with Claude Code for filesystem/terminal operations; rights to reuse referenced media.
- Enterprise document processing and analytics with visual grounding
- Sectors: finance, consulting, compliance, legal, healthcare admin
- What: Parse reports with charts/tables, extract data via OCR/visual grounding, and produce interleaved summaries or briefings where figures are embedded alongside text.
- Tools/workflows: OCR/Chart understanding gains (CharXiv, OCRBench); multimodal deep research tools (zai_dr_open_url_mm, zai_dr_visit_img); figure/table cropping and insertion; interleaved markdown generation.
- Dependencies/assumptions: Data privacy controls; document variety (layouts, languages); access to internal repositories; human-in-the-loop verification for regulated contexts.
- Visual product and media search by image
- Sectors: e-commerce, media, DAM (digital asset management)
- What: Identify products from photos, find visually similar items, locate original sources or usage rights.
- Tools/workflows: zai_search_web_by_image, zai_search_similar_images, zai_search_web_images; on-image cropping before search to isolate entities; “Deep-Wide-Search” strategy validated by ImageMining.
- Dependencies/assumptions: Internet access; search API quotas; content licensing policies.
- Automated UI testing and visual regression checks
- Sectors: software QA, DevOps
- What: Use fine-grained perception and grounding to locate UI elements, execute actions, and compare UI states across builds; detect visual layout and interaction regressions.
- Tools/workflows: GUI-agent competencies (OSWorld/AndroidWorld); image annotation and pointing; trajectory-level action prediction; workflow-based verification for pass/fail.
- Dependencies/assumptions: Stable test environments; golden baselines; CI/CD integration.
- Code assistant with visual context
- Sectors: software engineering
- What: Pair text-only coding strength with multimodal cues (e.g., screenshots of failing UIs, design references) for bug fixes, feature implementation, and repo exploration.
- Tools/workflows: Claude Code integration; CC-Bench-V2 capabilities; repository exploration and local execution; UI-to-code for front-end parity.
- Dependencies/assumptions: Secure local runtime; guardrails for file/system access; developer review.
- Competitive/market intelligence reports with embedded evidence
- Sectors: corporate strategy, marketing, consulting
- What: Generate text-image interleaved reports featuring screenshots, figures, and web-captured evidence; create slide decks from multimodal sources.
- Tools/workflows: Multimodal deep research loop (planning → browsing → screenshotting → extraction → synthesis); zai_dr_search, images_lens; automated slide/outline generation.
- Dependencies/assumptions: Web access; content usage rights; company style templates.
Academia
- Figure-aware literature reviews and teaching materials
- What: Compile surveys and lecture slides that preserve diagrams, charts, and tables; extract and annotate key visual evidence from papers.
- Tools/workflows: Document-grounded generation; figure cropping/insertion; interleaved markdown/PPT generation.
- Dependencies/assumptions: Access to publishers’ content; proper citation and fair-use policies.
- Benchmarking and agent evaluation with ImageMining
- What: Use ImageMining to evaluate and compare multimodal search and perception-planning-execution loops; probe tool-usage precision (cropping, magnification).
- Tools/workflows: ImageMining benchmark; multimodal tool-use tasks; clear task specs and verifiers.
- Dependencies/assumptions: Reproducible harness; standardized tool stacks; dataset licensing.
- Prototyping multimodal RL systems
- What: Adopt the VLM RL Gym for building heterogeneous single-/multi-step tasks with unified reward orchestration; experiment with hierarchical optimization and on-policy distillation.
- Tools/workflows: Unified task/reward abstraction; asynchrony and stage-overlap pipeline; memory and load-balancing techniques for ViT-heavy workloads.
- Dependencies/assumptions: GPU clusters; verifier infrastructure (rule-based/model-based judges); engineering capacity.
Policy/Government
- Multimodal document triage and public briefings
- What: Process policy documents, reports, and public datasets with embedded charts/maps; generate briefings that ground claims in extracted visuals.
- Tools/workflows: OCR/Chart understanding; interleaved report and PPT generation.
- Dependencies/assumptions: Records management policies; provenance tracking; human oversight in high-stakes outputs.
- Fact-checking and OSINT with image-grounded search
- What: Verify events, locations, and sources via image-based geolocation and cross-site retrieval.
- Tools/workflows: Spatio-temporal reasoning; zai_search_web_by_image; localized cropping to refine queries.
- Dependencies/assumptions: Secure connectivity; audit trails; handling of sensitive content.
Daily Life
- Personal research and presentation drafting
- What: Create school/work presentations or blogs from mixed sources (webpages, PDFs, images), embedding screenshots/figures automatically.
- Tools/workflows: Interleaved markdown/PPT generation; multimodal browsing and evidence gathering.
- Dependencies/assumptions: Content rights; internet access.
- On-the-go image recognition and search
- What: Identify plants/landmarks, find where an image came from, or locate similar visuals.
- Tools/workflows: zai_recognize_plant/location/person; web-by-image search; in-image cropping first for accuracy.
- Dependencies/assumptions: Mobile capture quality; network access; regional content policies.
- Accessibility helpers for on-screen content
- What: Describe GUIs, charts, and images to assist users with visual impairments; guide step-by-step interactions.
- Tools/workflows: GUI grounding and pointing; screen comprehension; narrated instructions.
- Dependencies/assumptions: Reliable screen-capture; latency constraints; safety and privacy requirements.
Long-Term Applications
These opportunities require further research, scaling, or system design (e.g., multimodal-native memory, strategy emergence, tighter harness co-design) before broad deployment.
Industry
- End-to-end autonomous enterprise agents across heterogeneous apps
- Sectors: finance ops, customer success, IT automation
- What: Agents that manage multi-application workflows with on-the-fly planning, verifiable subgoal decomposition, and adaptive tool-use over long horizons.
- Likely enablers: Hierarchical optimization pipelines; robust task specifications and verifiers; model–harness co-design for reliability.
- Dependencies/assumptions: Auditable decision logs; policy-compliant automation; long context and memory beyond text-centric summaries.
- Multimodal-native memory services
- Sectors: platform/ML infrastructure
- What: Memory systems that compact and retrieve “what was seen” (layout, spatial relations, video temporal change) alongside “what was said,” enabling long-horizon multimodal reasoning.
- Likely enablers: Visual state summarization and retrieval; ViT-aware memory compaction; cross-modal indexing.
- Dependencies/assumptions: New algorithms for visual compression without losing task-relevant detail; standardized APIs.
- AR/VR copilot overlays for task guidance
- Sectors: field service, manufacturing, healthcare workflows
- What: Real-time visual perception and step-by-step overlays for procedures, inspections, and troubleshooting.
- Likely enablers: CogViT’s fine-grained spatial perception; on-device or edge inference; stable latency and safety tooling.
- Dependencies/assumptions: Wearable hardware; secure on-prem inference; domain-specific validation.
- Robotics and embodied agents
- Sectors: logistics, manufacturing, service robots
- What: Transfer fine-grained perception and hierarchical planning to physical manipulation and navigation.
- Likely enablers: Integration with robot stacks; sensor fusion beyond images (depth, tactile); safety verifiers.
- Dependencies/assumptions: Real-world control policies; sim-to-real transfer; rigorous safety certification.
- Fully automated web development from rich specifications
- Sectors: software, no-/low-code platforms
- What: Build production-grade sites/apps from PRDs, mockups, assets, and reference pages with workflow-based verification.
- Likely enablers: Vision2Web-style pipelines; stronger functional and visual verification loops; tighter CI integration.
- Dependencies/assumptions: Testable specs; human QA gates; governance for code quality and security.
Academia
- Strategy-emergent agent training
- What: Methods that let agents discover qualitatively new planning and action patterns beyond human seeded trajectories; use multi-task RL with diverse cold starts.
- Likely enablers: Diverse trajectory generation; on-policy distillation; curriculum and hierarchical RL.
- Dependencies/assumptions: Compute and data diversity; robust evaluation protocols to detect genuine strategy shifts.
- Standardized, controlled benchmarks for long-horizon multimodal tasks
- What: Datasets and harnesses that pair clear task specs with reliable, multi-stage verifiers to produce reusable optimization signals.
- Likely enablers: Expansion of ImageMining-style datasets and Vision2Web’s workflow-based verification.
- Dependencies/assumptions: Community consensus on specs; reproducible tool stacks; licensing.
Policy/Government
- Auditable autonomous decision systems for public services
- What: Multimodal agents executing complex back-office and citizen-facing workflows with verifiable decision trails and robust guardrails.
- Likely enablers: Clear task definitions and outcome verifiers; model-harness co-shaping of capability boundaries; safety governance frameworks.
- Dependencies/assumptions: Regulatory approvals; privacy-by-design; red-teaming for multimodal failure modes.
- Privacy-preserving, on-prem visual agents
- What: Deploy agents that process sensitive images/documents on secure infrastructure with strict data residency.
- Likely enablers: Efficient ViT/memory management (MMTP, topology-aware partitioning) adapted for edge/on-prem clusters.
- Dependencies/assumptions: Hardware investment; MLOps maturity; compliance audits.
Daily Life
- Persistent personal desktop agents
- What: Agents that manage apps on your behalf over weeks/months, remembering visual states and prior decisions across sessions.
- Likely enablers: Multimodal-native memory; reliable GUI grounding across software updates; safe action verifiers.
- Dependencies/assumptions: OS-level permissions; trust and safety guardrails; local compute or private-cloud options.
- Lifelong personal knowledge bases built from screenshots, videos, and documents
- What: Organize, retrieve, and reason over a visual history (e.g., receipts, dashboards, whiteboard photos).
- Likely enablers: Visual indexing and summarization; privacy-preserving storage; cross-device sync.
- Dependencies/assumptions: Storage/security; user controls for retention; effective retrieval UX.
Notes on Cross-Cutting Assumptions and Dependencies
- Toolchain availability: Many “zai_” tools are accessible via Z.ai; alternatives or custom tools may be needed in private deployments.
- Connectivity and quotas: Multimodal deep search relies on web access and API limits; offline or on-prem deployments will need local corpora and search.
- Accuracy and safety: Fine-grained perception errors can propagate to planning and execution; high-stakes use requires human oversight and verifiers.
- Language coverage: Pretraining emphasizes Chinese–English; performance may vary for other languages without additional adaptation.
- IP and content rights: Image scraping and embedding in outputs must follow licensing and fair-use policies.
- Compute: Vision-heavy workloads demand GPUs and optimized memory pipelines (e.g., MMTP, topology-aware partitioning) for scale and latency.
Glossary
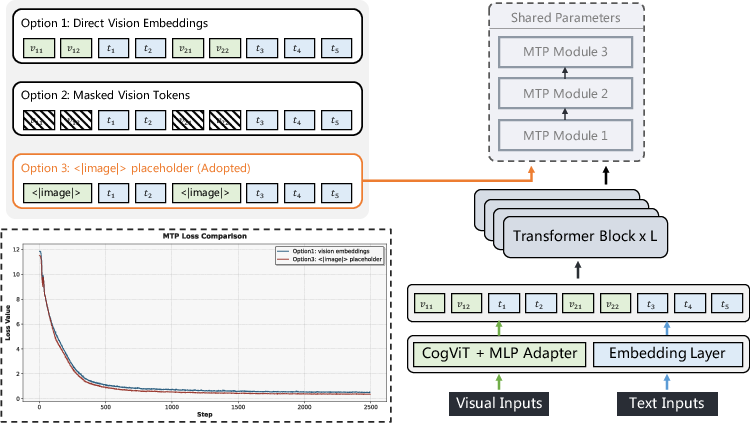
- ablation study: An experimental analysis where components are systematically removed or altered to assess their impact on performance. "Empirically, according to the ablation study on a 0.5B model, the <|image|>-based design achieves lower training loss and more stable convergence than directly using visual embeddings."
- activation memory: The memory required to store intermediate activations during neural network forward/backward passes. "This prevents activation memory from scaling linearly with the number of images in the naïve way, and substantially reduces runtime memory pressure while preserving overall computational efficiency."
- agentic capability: A model’s ability to autonomously plan, decide, and act in interactive environments. "As foundation models are increasingly deployed in real environments, agentic capability depends not only on language reasoning, but also on the ability to perceive, interpret, and act over heterogeneous contexts such as images, videos, webpages, documents, GUIs."
- all-to-all communication: A distributed systems communication pattern where each node exchanges data with all others. "After load balancing across DP groups, precise dispatch is carried out through asynchronous all-to-all communication, so that each rank receives only the partition it actually needs."
- attention computation: The process of computing attention scores in transformer architectures. "Additionally, we introduce QK-Norm to normalize query and key vectors before attention computation, effectively mitigating logit explosion and ensuring stability at scale."
- bilingual (Chinese-English) image-text corpus: A dataset containing aligned images and texts in two languages, used for cross-lingual training. "…utilizing an 8-billion bilingual (Chinese-English) image-text corpus to enhance cross-lingual understanding."
- bin-packing: Grouping variable-sized items into bins to optimize resource utilization, here for batching variable sequences. "For the variable-length sequences produced during rollout, we additionally perform joint bin-packing over both sequence length and ViT token count, leading to better-balanced micro-batches for both compute and memory pressure."
- bidirectional distributed implementation: A distributed training setup that processes data in both directions to improve efficiency. "…using the sigmoid-based SigLIP loss, combined with a bidirectional distributed implementation for efficiency;"
- contrastive image-text pretraining: Training to align visual and textual representations by bringing matched pairs closer in embedding space and pushing mismatched pairs apart. "The second stage shifts to contrastive image-text pretraining to align visual and textual features in a shared embedding space."
- context budget: The available capacity (e.g., tokens) for storing past context in models with limited context windows. "Compared with text, images and especially videos consume context budget much more aggressively, making them expensive to retain over long trajectories."
- context parallelism: A parallelism strategy that partitions sequences across devices to scale context length or throughput. "…this design remains naturally compatible with existing partitioning strategies such as sequence parallelism and context parallelism…"
- cosine decay schedule: A learning rate schedule that decays the rate following a cosine function. "We optimize with Muon optimizer with a cosine decay schedule."
- CPU offloading: Moving certain computations or tensors to CPU memory to reduce GPU memory pressure. "…combining targeted recomputation with CPU offloading."
- CP (context parallelism) partitioning: Partitioning workloads by segments of the input sequence across devices. "To address this, we move CP and TP partitioning upstream into the data-loading stage and align partition boundaries with downsample groups…"
- cross-modal alignment: Ensuring representations from different modalities (e.g., vision and language) are compatible or aligned. "To balance representation learning with cross-modal alignment, we employ a two-stage pretraining recipe."
- data-source tag: Metadata attached to training samples indicating their origin to enable per-source metric tracking. "To improve observability in mixed-task training, each sample also carries a data-source tag, allowing source-specific metrics such as reward and pass@k to be aggregated across parallel groups and reported separately."
- DINOv3: A self-supervised vision model used as a teacher for extracting texture features. "…dual teacher models: SigLIP2 for semantic representations and DINOv3 for texture features."
- distillation-based masked image modeling: A training approach where a student reconstructs masked image regions using teacher-provided features. "In the first stage, we use distillation-based masked image modeling to strengthen visual representations."
- DP (data parallel) groups: Replicas of model parameters across devices processing different mini-batches, used for scaling training. "After load balancing across DP groups, precise dispatch is carried out through asynchronous all-to-all communication…"
- embedding space: The vector space in which data from one or more modalities are represented. "The second stage shifts to contrastive image-text pretraining to align visual and textual features in a shared embedding space."
- end-to-end verification: Validating the entire pipeline of an agentic process from input to final outcome. "…highlighting the central role of multimodal perception, hierarchical optimization, and reliable end-to-end verification."
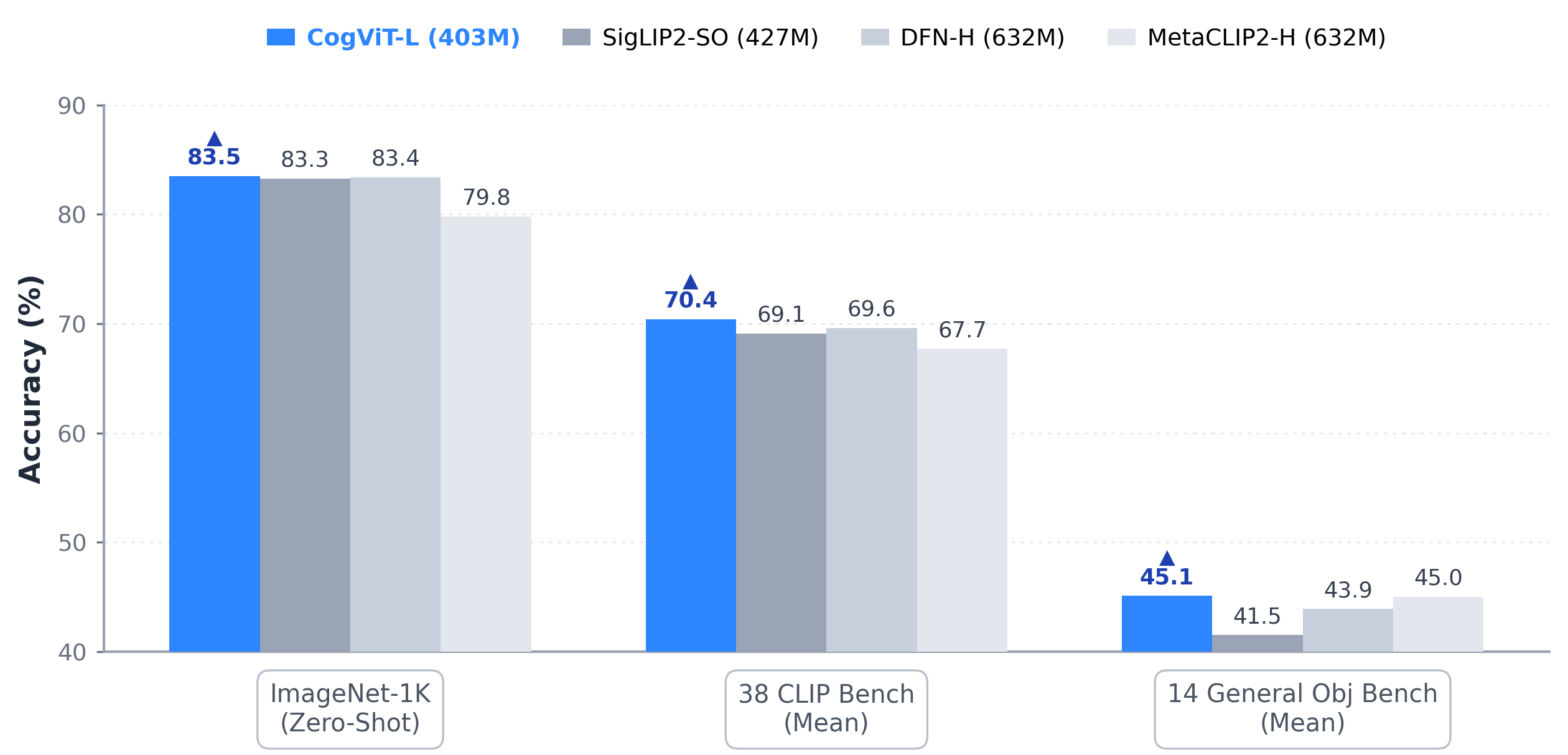
- fine-grained understanding: Detailed perception of objects, attributes, and spatial relations in images beyond coarse semantics. "We develop CogViT, a novel parameter-efficient vision encoder tailored for multimodal perception and downstream agent-oriented tasks. It delivers strong capabilities in general object recognition, fine-grained understanding, as well as geometric and spatial perception."
- foundation models: Large pre-trained models designed to be adapted for a wide range of downstream tasks. "Recent advances in foundation models have driven a shift from language understanding to agentic real-world interaction…"
- GUI grounding: Linking textual references to specific GUI elements or locations on a screen. "…spanning element perception, GUI grounding, single-step action prediction, and trajectory-level action prediction…"
- harness design: The surrounding system components (tools, memory, workflows) that enable a model to act effectively. "…the growing entanglement between model capability and harness design."
- hierarchical optimization: Training across multiple levels of task granularity to build complex capabilities efficiently. "Agent capability can be more efficiently built through hierarchical optimization."
- image grounding (2D): Associating textual phrases with specific 2D regions in an image. "…the model improves on tasks such as 2D image grounding and pointing…"
- image special token (<|image|>): A shared learnable placeholder token representing visual inputs to simplify processing. "Compared with directly passing visual embeddings to the MTP head, using the <|image|> token removes the need to propagate visual embeddings across pipeline-parallel stages…"
- logit explosion: Extremely large pre-softmax values that can destabilize training. "…effectively mitigating logit explosion and ensuring stability at scale."
- long-horizon tasks: Tasks requiring many steps or extended interactions to complete. "The key to constructing, evaluating, and optimizing end-to-end long-horizon tasks lies in clear task specification, reliable outcome verification, and controlled evaluation procedures."
- micro-batches: Small sub-batches processed sequentially to fit memory constraints during large-batch training. "…leading to better-balanced micro-batches for both compute and memory pressure."
- model-based judges: Learned evaluators used to assess outputs and provide rewards or feedback. "…while model-based judges are invoked asynchronously through APIs; their outputs are then combined into rewards through configurable aggregation strategies…"
- module-specific learning rates: Different learning rates assigned to distinct model components. "We continue to optimize with Muon, assigning module-specific learning rates and decay schedules to the vision, text, and projection components."
- multi-step tasks: Tasks that require multiple sequential actions or stages. "…support both single-step and multi-step tasks…"
- multi-token prediction (MTP): Predicting multiple future tokens per step to improve efficiency or training signals. "In standard text-only MTP, prefix tokens can be passed into the MTP head directly through token IDs and embedded with the word embedding layer."
- Multimodal Multi-Token Prediction (MMTP): An extension of MTP that handles both text and visual inputs. "We propose Multimodal Multi-Token Prediction (MMTP), a multimodal extension of multi-token prediction (MTP)…"
- multi-task RL: Reinforcement learning conducted over multiple task types jointly. "This multi-task RL setting also exhibits several properties that we have consistently observed…"
- NaFlex: A variable-resolution input scheme preserving aspect ratios for vision encoders. "…replacing the fixed 224 × 224 resolution with the NaFlex scheme to process variable-size inputs while preserving original aspect ratios;"
- OCR: Optical Character Recognition, extracting text from images. "…OCR (+4.2% on OCRBench)…"
- on-policy distillation: Transferring behaviors from the current policy to a student or consolidated model during RL. "Taken together, these observations suggest that multi-task collaborative RL, including on-policy distillation, is not merely a tool for improving individual capabilities…"
- pipeline-parallel stages: Splitting a model across devices by layers to process different micro-batches in a pipeline. "…using the <|image|> token removes the need to propagate visual embeddings across pipeline-parallel stages…"
- positional information: Encoding of token or patch positions used to preserve ordering or spatial relationships. "The third preserves visual positional information, but replaces all visual tokens with a shared learnable <|image|> special token…"
- projection components: Layers that map modality-specific features into a shared representation space. "…assigning module-specific learning rates and decay schedules to the vision, text, and projection components."
- proxy tasks: Auxiliary tasks used to train capabilities that transfer to more complex targets. "Even when a target capability cannot be easily formulated directly as an RL task, semantically or structurally related proxy tasks may provide useful optimization signals."
- QK-Norm: Normalization applied to query and key vectors in attention to stabilize training. "Additionally, we introduce QK-Norm to normalize query and key vectors before attention computation…"
- reference model: A fixed or separately maintained model used for comparisons or as a baseline during RL. "For the reference model, parameters remain resident on CPU memory, are asynchronously prefetched to GPU immediately before reference forward, and are released right after use…"
- reinforcement learning (RL): A learning framework where agents learn by receiving rewards from their actions’ outcomes. "In the agent era, training infrastructure faces much stricter demands on both efficiency and stability, especially in large-scale multi-task multimodal reinforcement learning (RL)."
- rollout inference: Generating trajectories or action sequences by running the current policy during RL. "We restructure the training pipeline to decouple rollout inference, reward evaluation, batch construction and weight transfer…"
- rule-based verifiers: Deterministic evaluators that check outputs against explicit rules. "Rule-based verifiers are executed locally and synchronously…"
- sequence parallelism: Distributing different parts of a long sequence across devices to increase effective context or throughput. "…compatible with existing partitioning strategies such as sequence parallelism and context parallelism…"
- SigLIP loss: A sigmoid-based contrastive loss used to align image and text representations. "…using the sigmoid-based SigLIP loss, combined with a bidirectional distributed implementation for efficiency;"
- SigLIP2: A contrastive vision-LLM used as a teacher for semantic representations. "…dual teacher models: SigLIP2 for semantic representations and DINOv3 for texture features."
- student ViT: A Vision Transformer model trained to learn from teacher features. "Specifically, we train the student ViT to reconstruct the masked regions…"
- supervised fine-tuning (SFT): Refining a pre-trained model on labeled data for specific tasks. "Compared with the cross-domain trade-offs often seen in SFT, RL tends to show weaker interference across domains…"
- TP (tensor parallelism) partitioning: Splitting individual tensor computations across devices to parallelize large layers. "To address this, we move CP and TP partitioning upstream into the data-loading stage and align partition boundaries with downsample groups…"
- topology-aware partitioning: Partitioning that accounts for hardware or data topology to minimize communication and imbalance. "For visual inputs such as long videos, where sequence lengths vary significantly, we further introduce a topology-aware partitioning and dynamic load-balancing scheme."
- trajectory-level action prediction: Predicting sequences of actions across an entire interaction trajectory. "…spanning element perception, GUI grounding, single-step action prediction, and trajectory-level action prediction…"
- unified VLM RL Gym: A common environment interface for training vision-LLMs with RL across diverse tasks. "We build a unified VLM RL Gym that provides a consistent environment interface for both single-step and multi-step tasks…"
- ViT (Vision Transformer): A transformer-based architecture for processing images by dividing them into patches. "Specifically, we train the student ViT to reconstruct the masked regions…"
- visual embeddings: Vector representations of visual inputs produced by a vision encoder or projector. "Compared with directly passing visual embeddings to the MTP head, using the <|image|> token removes the need to propagate visual embeddings across pipeline-parallel stages…"
- vision encoder: A neural network component that converts images into feature embeddings. "We develop CogViT, a novel parameter-efficient vision encoder tailored for multimodal perception and downstream agent-oriented tasks."
- vision-LLM (VLM): A model jointly processing visual and textual inputs. "We build a unified VLM RL Gym that provides a consistent environment interface for both single-step and multi-step tasks…"
Collections
Sign up for free to add this paper to one or more collections.

