- The paper introduces MoRFI, a robust pipeline using sparse autoencoders to detect monotonic shifts in latent activations during fine-tuning.
- It demonstrates that single-latent steering can recover up to 85% of forgotten pre-trained facts, highlighting the causal role of specific activations.
- The study shows that post-training hallucinations stem from disrupted knowledge access rather than loss, paving the way for targeted inference-time interventions.
MoRFI: Monotonic Sparse Autoencoder Feature Identification
Introduction
Monotonic Relationship Feature Identification (MoRFI), as presented in "MoRFI: Monotonic Sparse Autoencoder Feature Identification" (2604.26866), addresses fundamental questions regarding how LLMs integrate new knowledge during post-training and how such integration gives rise to hallucinations. The paper focuses on discovering and mechanistically attributing latent directions in the residual stream of transformers that causally modulate the retention and retrieval of pre-trained knowledge. MoRFI departs from existing approaches by providing a robust, statistically principled pipeline for feature selection via monotonic trend validation over controlled fine-tuning conditions, operationalized using pre-trained sparse autoencoders (SAEs).
Context and Motivation
During pre-training, LLMs aggregate a vast amount of factual and relational knowledge via next-token prediction. However, instruction tuning, supervised fine-tuning (SFT), and reinforcement learning from human feedback (RLHF) introduce additional knowledge that may not be grounded in the model’s parametric space, frequently resulting in hallucinations. Prior studies have shown that fine-tuning with unfamiliar data increases hallucination rates (Gekhman et al., 2024, Kang et al., 2024). Although it is well-established that LLMs typically struggle to assimilate factual content outside of pre-training, understanding the precise internal mechanisms driving hallucinations and knowledge accessibility remains incomplete.
Methodology
MoRFI’s approach is predicated on the observation that fine-tuning with increasing proportions of unknown facts disrupts retrieval behavior in LLMs. The central technique is to use SAEs to obtain latent representations of the residual stream activations across model checkpoints fine-tuned under varying controlled conditions (mixtures of known and unknown facts or increasing epochs). The methodology proceeds as follows:
- Controlled Fine-Tuning: LLMs (Llama 3.1 8B, Gemma 2 9B, Mistral v03 7B) are fine-tuned on closed-book QA datasets derived from EntityQuestions, with synthetic mixtures designed to systematically vary the proportion of unknown facts and the number of epochs.
- Activation Tensor Construction: A 4D tensor A is constructed, capturing activations over samples, property configurations (e.g., % unknown facts), latent feature dimensions, and timesteps.
- Monotonic Trend Detection: The MoRFI algorithm leverages bootstrapped statistical tests (Spearman and Mann-Kendall) to robustly filter latents whose activations exhibit consistent monotonic increase or decrease along the controlled variable.
- Impact Assessment: Identified latents are causally attributed by steering the residual activations along these directions and measuring test accuracy recovery, especially for facts verifiably known by the base model but forgotten after fine-tuning.
The selection pipeline ensures statistical rigor by requiring trends to be both significant and consistent across resampled replicate conditions, thus minimizing false discovery of features merely correlated with prompt batches.
Key Results
Knowledge Retention and Hallucinations
Extended fine-tuning on mixtures with higher proportions of unknown facts leads to pronounced, monotonic degradation in retrieval of pre-trained knowledge, observed consistently across all model architectures.
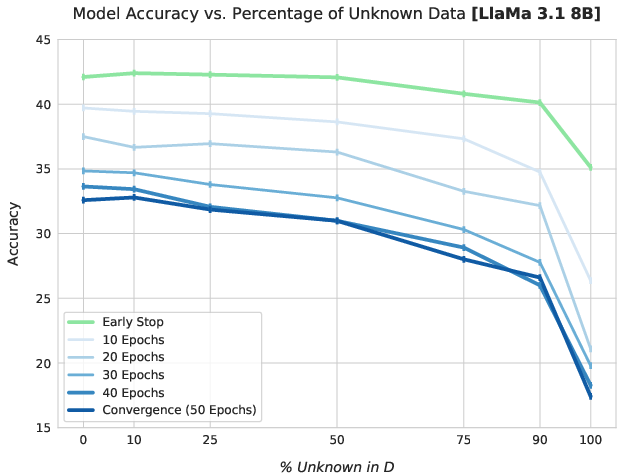
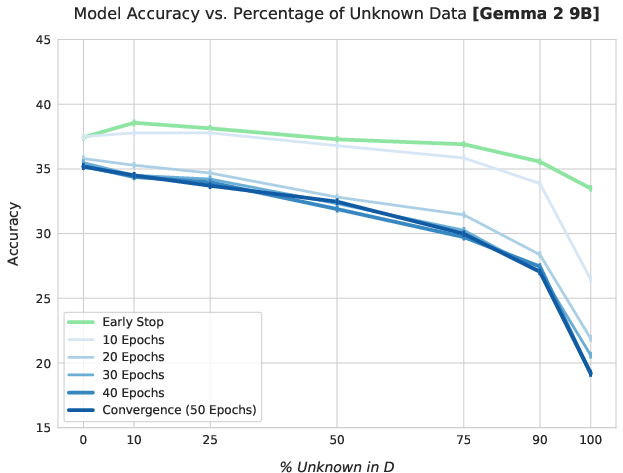
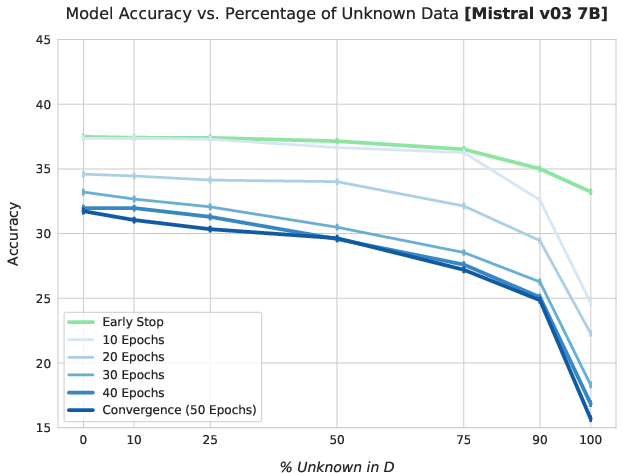
Figure 1: Test accuracy consistently declines on Llama 3.1 8B as the proportion of unknown facts in fine-tuning increases and as more epochs are used.
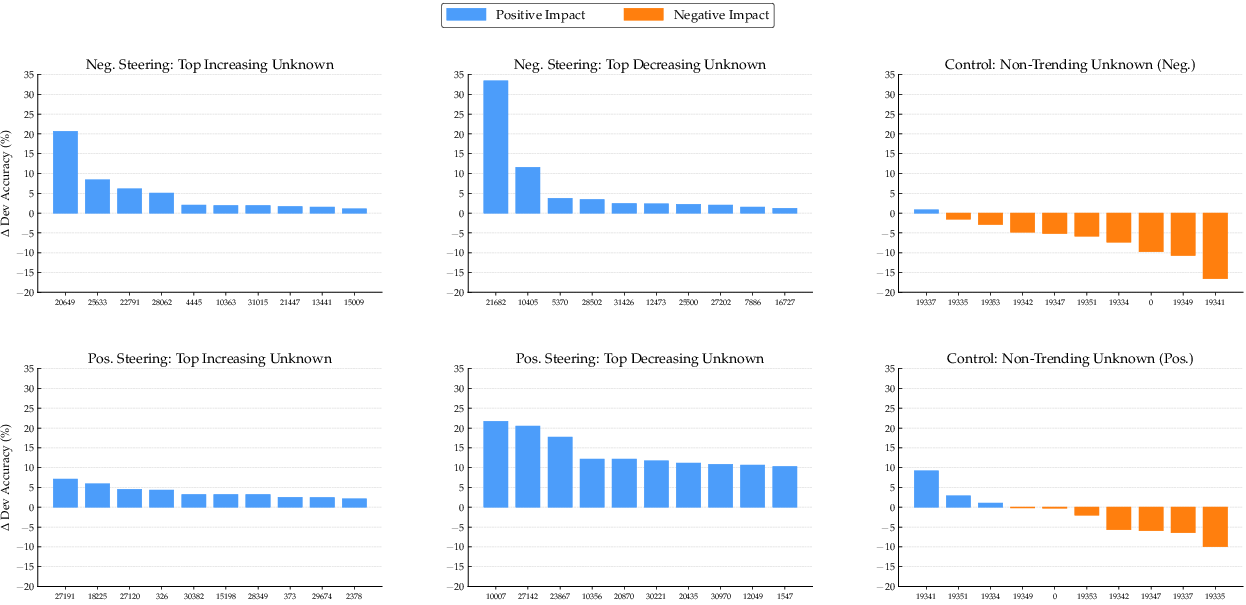
Identification and Causal Attribution of Latents
MoRFI identifies latents whose activations change monotonically with exposure to unfamiliar knowledge. Critically:
Latent Structure and Generalization
Steering along the composite direction, defined as the mean shift in SAE activations from pre-training to full unknown exposure, produces generalizable accuracy gains:
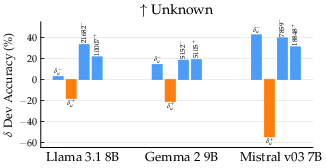
Figure 3: Steering with the composite direction, δu, restoring accuracy in hallucinating checkpoints for all models. The effect is consistent, but single-latent steering outperforms composite interventions, underscoring sparsity.
Cosine similarity analysis of the top latents confirms that impactful features are generally non-redundant and distributed, rather than clustering tightly in latent space.
Similarity of Feature Subspaces
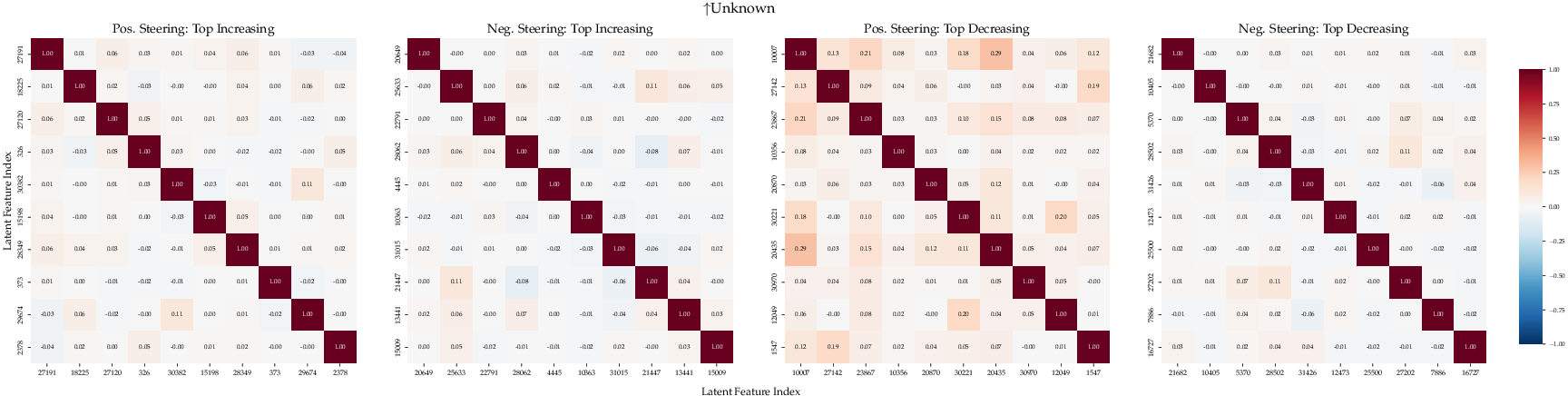
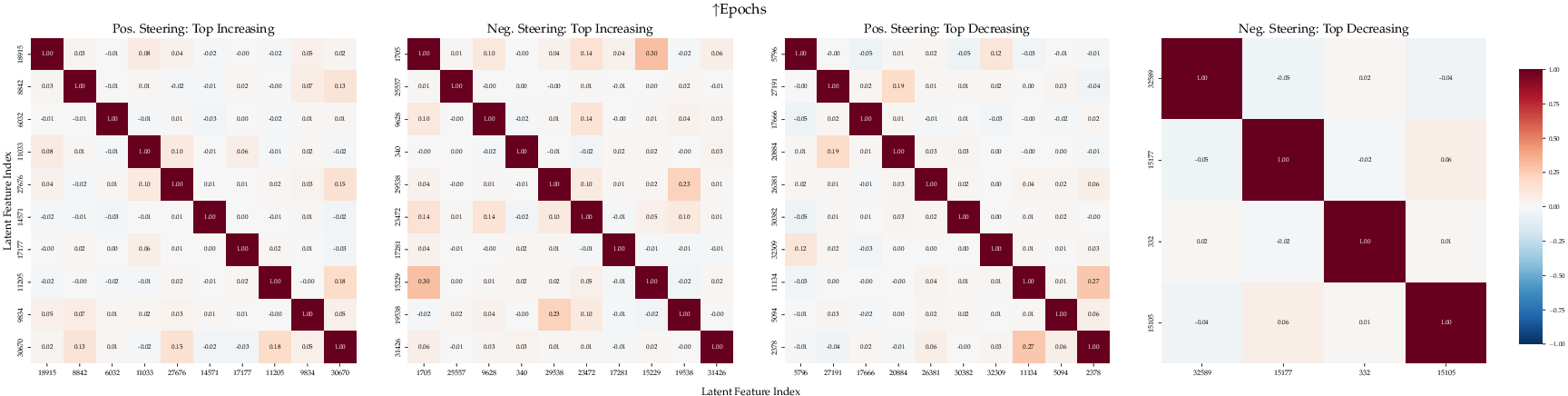
Figure 4: Cosine similarity of top-10 latents (unknown/epochs) surfaced by MoRFI on Llama 3.1 8B. The low within-group similarity indicates that these features span a broad subspace of the residual stream’s representation.
This distributed structure suggests that critical knowledge-access activations are not trivially localizable but are spread across the feature space.
Theoretical and Practical Implications
The results provide direct evidence that post-training on out-of-support knowledge disrupts retrieval pathways rather than erasing underlying parametric knowledge. This aligns with emerging views in mechanistic interpretability: forgetting in LLMs is predominantly an issue of accessibility rather than parameter-level erasure (Ferrando et al., 2024, Modell et al., 23 May 2025). It further implies that hallucination mitigation can, in principle, be performed through inference-time activation steering, re-establishing access to suppressed knowledge—an alternative to expensive and potentially destabilizing re-training protocols.
MoRFI also sets a new standard for interpretability pipelines in model diffing and behavior attribution:
- By bootstrapping and validating monotonic trends, it robustly disambiguates global, dataset-induced shifts from prompt artifacts and random fluctuations.
- Its success across Llama, Gemma, and Mistral families demonstrates architectural generality.
- The observed sparsity of critical latents supports investigating rank-constrained or minimal interventions for future applications in safety, alignment, and controlled knowledge editing.
Future Directions
Two important avenues are emergent from this research:
- Geometry of Knowledge Manifolds: The observed overshooting and tolerance to perturbations in the residual stream suggest the presence of higher-dimensional manifolds for knowledge access in activation space—posing open questions for geometric manifold analysis and region-based interpretability (Shafran et al., 2 Feb 2026, Modell et al., 23 May 2025).
- Cross-Task and Cross-Model Alignment: The pipeline lays the groundwork for causal, sparse model editing. Extensions could tie SAE-extracted latents to specific behavioral or safety attributes (e.g., factuality, refusal, or misalignment), using analogs of MoRFI to isolate pathways for fine-grained output control.
Conclusion
MoRFI establishes an algorithmically principled, statistically robust pipeline for identifying and mechanistically attributing residual stream directions in transformer LLMs that mediate access to pre-trained knowledge. It conclusively demonstrates that hallucinations induced by unfamiliar post-training data are due to disruptions in accessibility, not loss of the underlying knowledge, and that targeted intervention via single-latent activation steering can recover lost capabilities. This work provides actionable insights for the development of interpretability and editing tools necessary for reliable, controllable, and safe deployment of LLMs.