- The paper introduces a hierarchical pattern language that decouples millisecond-level reflex actions from slow semantic reasoning to improve system resilience.
- It presents four architectural patterns—hybrid affordance integration, adaptive visual anchoring, visual hierarchy synthesis, and semantic scene graph—to address UI drift and semantic uncertainty.
- The evaluation demonstrates that decoupling control loops reduces operational latency while enhancing robustness and explainability for enterprise automation.
A Pattern Language for Resilient Visual Agents: Architectural Separation of Fast Reflex and Probabilistic Reasoning
Introduction
The engineering of visually grounded software agents for enterprise automation faces fundamental architectural challenges due to the conflicting requirements for deterministic, low-latency interaction and robust, high-level semantic reasoning. "A Pattern Language for Resilient Visual Agents" (2604.28001) addresses this dichotomy by proposing a hierarchical architectural pattern language that decomposes agent systems into orthogonal layers, thereby isolating fast control from slow, semantically rich supervision. This essay presents a technical analysis of the paper, focusing on its architectural principles, the four proposed design patterns, key trade-offs, evaluation, and implications for resilient agentic automation.
Architectural Principles and Bimodal Failure Modes
The motivation arises from the inadequacy of both classic RPA and monolithic vision-language-action (VLA) models. Deterministic automation (classic RPA) is computationally efficient but highly brittle: even trivial UI changes (layout shifts, pop-ups) cause catastrophic open-loop failures, as execution is predicated on static selectors or absolute coordinates. Conversely, contemporary VLAs such as UI-TARS [qin2025ui], OmniParser [lu2024omniparser], and CogAgent [hong2024cogagent] deliver semantic robustness by interpreting raw pixels, but at the expense of inference latency, probabilistic outputs, and architectural entanglement leading to high maintenance overhead and prohibitive runtime costs.
These technical tensions are formalized in the paper as four "architectural forces":
- Time (latency vs. semantic depth),
- Cost (compute and API expenditure),
- Reliability (determinism vs. adaptability),
- Explainability (auditability and diagnosis of decision failures).
A paradigm shift is advocated: agents are to be perceived not as scripted processes but as embodied entities operating through virtual perception and effectors, bridging the "Sim2Real" gap via explicit separation of reflex (System 1) and reasoning (System 2; after [kahneman2011thinking]). Foundationally, the reference design draws from behavior-based robotics [brooks2003robust], autonomic control loops (MAPE-K [kephart2003vision]), and ecological perception [gibson1979ecological], thereby imposing modular control hierarchies that localize and contain technical debt [sculley2015hidden, parnas1972criteria].
The Hierarchical Reference Architecture
The centerpiece of the paper is the introduction of a hierarchical software architecture, depicted below, that achieves architectural isolation between fast, deterministic control loops and slow, probabilistic cognitive supervision.
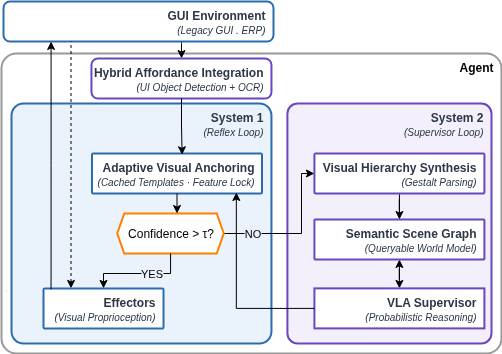
Figure 1: The hierarchical reference architecture showing separation of reflex (UI Objects) and reasoning (VLA / System 2).
The architecture comprises three asynchronous loops:
- Reflex Loop: Fast, deterministic execution using cached visual anchors and local perception primitives.
- Structural Loop: Mediation layer to transform unstructured GUI percepts into hierarchical, planner-consumable UI representations.
- Supervisor Loop: High-latency, probabilistic reasoning—typically a VLA model—invoked on demand for recovery, perceptual repair, and high-level planning.
This design supports amortized inference, enabling cost-effective, millisecond-level batch automation by invoking heavy reasoning only when the fast path fails (e.g., upon UI drift or low perceptual confidence).
The Four Architectural Patterns
1. Hybrid Affordance Integration Pattern
Problem: Single-modal perception (vision or text) introduces fragility through hallucinated or undetected affordances, resulting in semantic misapprehension (e.g., mistaking a non-actionable colored area as a button).
Solution: Architect a multimodal fusion layer that acts as a perceptual arbiter, integrating outputs from parallel, lightweight vision (UI element detectors) and OCR streams, projecting entities onto a shared coordinate system. Disagreement between modalities is isolated as uncertainty, triggering epistemic actions (hover verification) and audited by downstream logic. This directly mitigates explainability failures and sensory confounds [gidey2025affordance].
2. Adaptive Visual Anchoring Pattern
Problem: The high performance of template-matching or embedding-based anchoring is offset by brittleness under UI drift, while VLAs, though robust, introduce untenable latency ("drift-latency dilemma").
Solution: Introduce a fallback connector separating System 1 (template/anchor-based fast matching) from System 2 (slow VLA recovery). When anchor confidence drops below a threshold (τ<0.9), reflex execution is inhibited; System 2 engages for perceptual recovery by updating the anchor cache using semantically grounded VLA inference, restoring fast-path operation for subsequent tasks. This resolves the trade-off between speed and adaptability through asymmetric, event-triggered supervision.
3. Visual Hierarchy Synthesis Pattern
Problem: Sensors produce a flat set of percepts; planners require a hierarchical and contextual model for robust command addressing. Global layout shifts or content reordering break absolute references, resulting in ambiguity.
Solution: Insert a mediation layer employing Gestalt-inspired grouping principles [xiange2007web, xu2016identifying]. Detected elements are parsed into hierarchical UI structures (trees of forms, tables, controls), supporting relative addressing (e.g., "click the 'Submit' in 'Login_Form'") and robust plan invariance under UI translation, scaling, and dynamic content.
4. Semantic Scene Graph Pattern
Problem: Complex, long-horizon tasks demand an explicit, inspectable world model to verify action preconditions and contextual constraints, which flat perceptions cannot provide.
Solution: Construct a static, queryable semantic scene graph wherein nodes encode semantic entities and edges represent spatial/functional constraints and relationships. Action planners and safety verifiers query this world model to enforce constraints, increasing operational reliability and providing observability for failure analysis.
Evaluation and Architectural Trade-Offs
Scenario-based evaluation (SAAM [kazman1994saam]) demonstrates efficacy under a canonical "UI drift" scenario typical in legacy ERP automation. Under a perturbation (a button moves, a destructive action is introduced in its place, and the visual style of the target button changes), classic RPA fails catastrophically. End-to-end VLA approaches succeed semantically but deliver throughput inadequate for enterprise-scale batch operations (~10s per item, 3 hours for 1000 invoices). The proposed hierarchical architecture amortizes VLA inference cost over multiple tasks through reflex cache updates, localizing slow inference to exceptional cases and preserving millisecond-level per-item latency and strict safety.
A formal cost/latency model is introduced:
Costavg=CostReflex+PDrift×CostSupervisor
For low PDrift, the operational cost of the agent system approaches that of classical RPA, while achieving the resilience and adaptability of state-of-the-art VLAs.
Implications and Future Directions
This pattern language has significant implications for the design of resilient, economically viable visual agents:
- Architectural Modularity: Isolates high-latency, non-deterministic perception models, allowing for independent development, regression testing, and evolution of fast execution components—resolving the CACE (Changing Anything Changes Everything) anti-pattern [sculley2015hidden].
- Explainable and Testable Agents: The semantic scene graph provides a substrate for explicit safety verification, auditability, and semantic contract testing.
- Scalable Cognitive Automation: Enables enterprise automation in non-instrumented environments (Citrix, VNC, legacy desktops) where API or DOM access is unavailable.
Future work includes systematic benchmarking against state-of-the-art monolithic and end-to-end VLA agent architectures to establish quantitative cost, latency, and resilience profiles across broader industrial applications.
Conclusion
The paper advances the software architecture of visually grounded agents by advocating and formalizing a pattern language that explicitly separates fast reflexive execution from slow probabilistic reasoning. This design achieves operational resilience, high throughput, and auditability in the face of UI drift and semantic uncertainty. The reference architecture and its pattern language directly address longstanding technical debts in GUI automation, clarifying pathways toward scalable, robust, and explainable cognitive automation for legacy and future enterprise systems (2604.28001).