Hallucinations Undermine Trust; Metacognition is a Way Forward
Abstract: Despite significant strides in factual reliability, errors -- often termed hallucinations -- remain a major concern for generative AI, especially as LLMs are increasingly expected to be helpful in more complex or nuanced setups. Yet even in the simplest setting -- factoid question-answering with clear ground truth-frontier models without external tools continue to hallucinate. We argue that most factuality gains in this domain have come from expanding the model's knowledge boundary (encoding more facts) rather than improving awareness of that boundary (distinguishing known from unknown). We conjecture that the latter is inherently difficult: models may lack the discriminative power to perfectly separate truths from errors, creating an unavoidable tradeoff between eliminating hallucinations and preserving utility. This tradeoff dissolves under a different framing. If we understand hallucinations as confident errors -- incorrect information delivered without appropriate qualification -- a third path emerges beyond the answer-or-abstain dichotomy: expressing uncertainty. We propose faithful uncertainty: aligning linguistic uncertainty with intrinsic uncertainty. This is one facet of metacognition -- the ability to be aware of one's own uncertainty and to act on it. For direct interaction, acting on uncertainty means communicating it honestly; for agentic systems, it becomes the control layer governing when to search and what to trust. Metacognition is thus essential for LLMs to be both trustworthy and capable; we conclude by highlighting open problems for progress towards this objective.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What Is This Paper About?
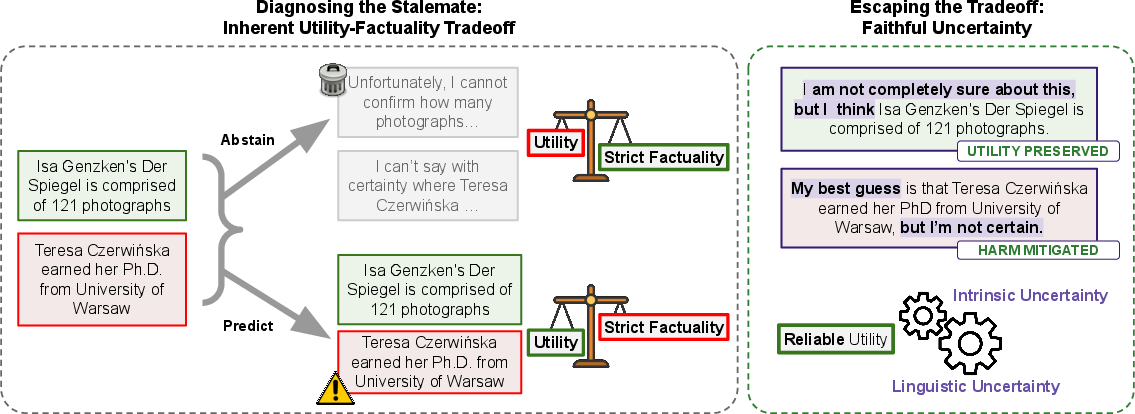
This paper talks about a big problem in AI: sometimes chatbots confidently say things that are wrong. People call these mistakes “hallucinations.” The authors explain why getting rid of these mistakes entirely is very hard. Then they suggest a practical fix: teach AI to notice and honestly tell us when it’s unsure. This skill—knowing what you know and what you don’t—is called metacognition. The idea is that AI can stay helpful and also be more trustworthy by clearly showing its uncertainty instead of pretending to know everything.
What Questions Are the Authors Asking?
- Why do AI systems still make confident mistakes even on simple fact questions?
- Has recent progress mainly come from cramming in more facts, rather than teaching AI to recognize when it doesn’t know something?
- Is there a better way than “answer everything” or “refuse a lot”? Could AI say, “Here’s my best guess, and I’m only 60% sure”?
- How should this “know-your-own-uncertainty” skill guide AI agents that use tools like web search (when to search, what to trust)?
How Did They Study This?
The paper is a research overview and a proposal, not a single big experiment. Here’s what they did:
- They reviewed many recent studies about AI mistakes and confidence.
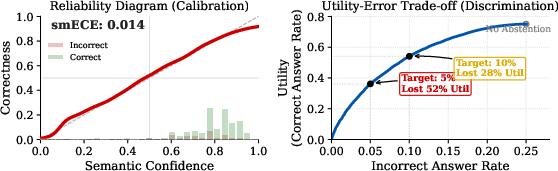
- They showed a simple simulation to explain a key idea: even if an AI’s confidence is “calibrated” (its 60% confidence means it’s right about 60% of the time on average), it can still be bad at telling which specific answers are right or wrong. That means to lower mistakes a lot, you might have to throw away many good answers too. The authors call this the “utility tax.”
- They looked at real benchmarks where top models either:
- answer a lot and make more mistakes, or
- refuse a lot to avoid mistakes (but then they’re less useful).
- They propose “faithful uncertainty”: the AI’s words about uncertainty (like “I might be wrong”) should match its internal uncertainty signal (how unsure it actually is).
- They give concrete recommendations for testing and improving this skill.
Here are a few key terms explained in everyday language:
- LLM: A supercharged autocomplete trained on huge amounts of text.
- Hallucination: A confident wrong answer.
- Calibration: On average, the AI’s stated confidence matches how often it’s correct.
- Discrimination: Being able to tell, for each specific question, which answers are likely right vs. wrong.
- Hedging: Phrases like “I’m not sure” or “I’m about 70% confident.”
- Metacognition: Knowing what you know and what you don’t know (and acting on it).
- Agentic system: An AI that can use tools (like search) and make decisions about when and how to use them.
What Did They Find or Argue?
- Completely eliminating hallucinations is very hard. Today’s models can often say how confident they are on average (calibration), but they’re not good enough at separating the right answers from the wrong ones one-by-one (poor discrimination). This creates a tough tradeoff:
- If the AI refuses whenever it’s unsure, it avoids mistakes but becomes less helpful.
- If it answers more, it stays helpful but makes more confident mistakes that hurt trust.
- A better framing: think of hallucinations as confident errors. That creates a third option besides “answer everything” and “refuse a lot”: answer, but honestly express uncertainty when you have it. Then an error becomes a “hypothesis” rather than a misleading claim.
- “Faithful uncertainty” is the goal: the AI’s wording (“I’m 60% sure”) should honestly reflect its internal state. This is realistic because the AI always has access to its own internal signals, even if it doesn’t know the absolute truth of the world.
- For AI agents that use tools (like web search), metacognition is essential. Without knowing when it’s unsure, an agent can’t:
- decide when to search (it might search too often or not enough),
- or weigh new information against what it already “believes.”
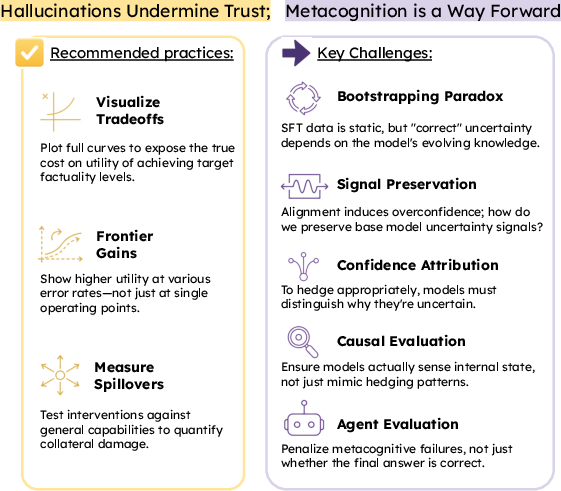
- The authors list practical research challenges, such as:
- Teaching uncertainty without freezing it to old facts (the AI’s knowledge changes over time).
- Keeping uncertainty signals intact during alignment and fine-tuning (these steps can make models overconfident).
- Explaining why the AI is unsure (because the question is unclear? because it lacks knowledge?).
- Testing that the AI truly “looks inside” (and isn’t just hedging based on easy shortcuts like “rare names = hedge”).
- Evaluating agents on process control (e.g., did they search when they should? did they avoid trusting bad sources?), not just final correctness.
To help the field measure progress fairly, they recommend:
- Showing the full “utility vs. error” tradeoff curve (how much helpfulness you lose to reach a target error rate), not just one cherry-picked score.
- Proving real gains at the same error rate (more utility with equal reliability).
- Checking for side effects (does a “safer” model become less helpful in other tasks?).
Why Is This Important?
- Trust: People lose trust when AI sounds sure but is wrong. Honest uncertainty signals let users judge whether to double-check, seek sources, or move on.
- Usefulness: Instead of refusing too much, the AI can still offer helpful guesses—but clearly labeled as guesses.
- Safety: As models get more advanced, it’s harder for users to spot mistakes. Clear uncertainty becomes a safety requirement.
- Smarter agents: Metacognition helps agents use tools well—search when needed, stop when not, and make better decisions with conflicting evidence.
Final Takeaway and Impact
The paper’s big message is simple and practical: we may not reach zero mistakes anytime soon, but we can build AI that knows—and says—when it’s unsure. Like a good doctor who separates a firm diagnosis from a tentative guess, an AI with metacognition can be both trustworthy and useful. If researchers and developers aim for “faithful uncertainty” alongside adding more knowledge, we can make assistants and agents that are safer, more honest, and easier to rely on in everyday life.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper proposes “faithful uncertainty” and metacognition as a path beyond the utility–factuality trade-off, but leaves several concrete gaps and open problems unaddressed:
- Quantifying the discrimination gap: What are the upper bounds on achievable AUROC for knowledge-intensive QA across diverse domains, languages, and model families, and are observed ceilings architectural, data, or objective-induced?
- Mechanistic source of poor discrimination: Which internal representations, training dynamics, or objective terms degrade instance-level separability between correct and incorrect answers, and can targeted representation learning improve it?
- Causal link between reasoning and hallucinations: Why do longer reasoning chains increase hallucinations and degrade abstention, and which training or decoding modifications reverse this without sacrificing problem-solving gains?
- Formalization of “faithful uncertainty”: What is a precise, task-agnostic definition and metric suite for instance-level faithfulness (beyond calibration) that is reliable, reproducible, and not gameable by style-mimicking hedges?
- Ground truth for intrinsic uncertainty: How should “intrinsic uncertainty” be operationalized and measured (e.g., repeated sampling, ensembles, logit-based proxies) with acceptable variance and compute cost?
- Dynamic data infrastructure: How to build SFT/RLHF datasets with labels that adapt to the model’s evolving knowledge boundary, avoiding stale supervision that induces hallucinated confidence or uncertainty?
- Uncertainty-preserving alignment: What alignment/RL algorithms preserve or improve intrinsic uncertainty signals (both calibration and discrimination) while meeting safety/helpfulness targets?
- Preventing Goodharting of uncertainty: How to design losses and rewards so models cannot inflate or suppress hedges strategically to score well on faithfulness metrics without genuine introspection?
- Confidence attribution: How to disentangle and label epistemic vs. aleatoric vs. normative uncertainty, and map each reliably to distinct, informative linguistic hedges and control actions?
- Localized uncertainty in long-form outputs: Methods and standards for span-level uncertainty tagging (e.g., token/phrase/date-level) and evaluation of its accuracy and user utility.
- Reliable utility metrics: How to quantify the value of hedged answers (risk-adjusted utility) for users and decision-making, beyond binary correctness and refusal rates?
- Standardizing Utility–Error curves: What benchmarks, protocols, and target operating points should be adopted to make Utility–Error trade-off curves comparable across papers and domains?
- Cross-task spillovers: How do hallucination-mitigation and uncertainty-expression interventions affect unrelated capabilities (coding, math, creative writing), and how should holistic cost be reported?
- Robustness of metacognition: How stable are intrinsic and linguistic uncertainty under distribution shift, adversarial prompts, prompt-injection, and tool failures?
- Adversarial uncertainty manipulation: Can attackers induce under-hedging (false confidence) or over-hedging (paralysis) reliably, and what defenses and audits detect such manipulation?
- Human factors in uncertainty communication: How do users interpret hedges (phrasing, numerics, ranges), what levels are acceptable by domain/stakes, and how to calibrate language to human perception across cultures and languages?
- Mapping numeric to linguistic uncertainty: What psycholinguistic mappings align stated probabilities with user-understood verbal hedges, and how to keep them consistent across contexts?
- Agent control policies from uncertainty: How to turn intrinsic uncertainty into robust control decisions (when to search, verify, stop, or escalate), jointly optimizing accuracy, latency, and cost?
- Arbitration between priors and retrieved evidence: When internal beliefs conflict with retrieved content, how should the agent weigh, reconcile, and communicate the conflict, and when should it defer?
- Benchmarks for metacognitive agents: What process-based, model-dependent evaluations penalize metacognitive failures (unnecessary retrieval, source credulity, premature halting) independently of lucky final correctness?
- API standards for metacognitive signals: What interfaces should expose confidence, uncertainty type, and rationale to orchestrators, and how should downstream tools consume and act on them?
- Minimizing compute for intrinsic signals: What low-cost proxies (e.g., speculative decoding, partial ensembles, activation features) approximate intrinsic uncertainty with acceptable fidelity?
- Active learning for “honest mistakes”: How to efficiently discover and fix regions where the model is confidently wrong (beyond passive knowledge expansion), and measure correction persistence?
- Cross-model and cross-run consistency: How consistent are intrinsic uncertainty estimates across seeds, temperatures, and sibling models, and can calibration transfer between models?
- Multimodal and multilingual generalization: Do the discrimination gap and faithful-uncertainty methods transfer to multimodal tasks and low-resource languages with sparse tail knowledge?
- Data contamination controls: How to ensure tail-knowledge benchmarks are free from training contamination so discrimination and uncertainty measurements reflect true long-tail behavior?
- Theoretical limits vs. empirical headroom: Under what assumptions (data distributions, architectures, objectives) can discrimination approach AUROC ≥ 0.95, and are current ceilings fundamental or contingent?
- Governance and auditing of uncertainty: What auditing protocols and regulatory thresholds should define acceptable hedging behavior by domain (e.g., medical, legal), and how to certify compliance?
- Privacy and abuse considerations: Does exposing metacognitive signals leak sensitive model internals or enable prompt inference, and how to safeguard against exploitation?
- Interplay with tool reliability: How should metacognitive policies adapt when tools are slow, noisy, or censored, and how to detect and recover from tool-induced miscalibration?
- Reproducibility of faithfulness evaluations: What seeds, sampling settings, and reporting standards are necessary so faithfulness and Utility–Error results are comparable and trustworthy?
Practical Applications
Immediate Applications
The following applications can be deployed with today’s models and toolchains by leveraging existing uncertainty proxies (e.g., log probabilities, semantic entropy, self-consistency variance) and product/UI design patterns that communicate and act on uncertainty.
- Industry — Software and Search: Confidence-annotated answers in chatbots and search assistants. Present span-level uncertainty highlights, confidence badges, and “verify/source” actions; gate factual claims behind citations when confidence is low; enable “low-uncertainty mode” that refuses or defers. Tools/products: UI components for hedging, span-highlighting, source panels; decoding wrappers that expose token logprobs or self-consistency. Assumptions/dependencies: Access to token-level scores or sampling; basic calibration checks; user education to interpret uncertainty.
- Industry — Agentic Retrieval (cost/reliability): Adaptive tool invocation based on uncertainty. Route to web search, RAG, or databases only when semantic entropy/self-consistency crosses a threshold; stop searching when confidence rises or retrieved evidence conflicts with high-confidence priors. Tools/products: Metacognitive controller middleware for LangChain/LlamaIndex; “search-on-low-confidence” policy modules. Assumptions/dependencies: Reliable uncertainty proxy; conflict detection (e.g., answer–evidence mismatch).
- Industry — Customer Support: Honest deferral and escalation. Bots hedge on tail questions, propose alternatives, and escalate to human agents when confidence is low; surface internal KB passages for verification. Tools/products: Escalation policies keyed on uncertainty; confidence-aware workflows in Zendesk/ServiceNow. Assumptions/dependencies: SLAs that reward correct escalation; domain KB quality.
- Software Engineering: IDE uncertainty overlays and test-first workflows. Annotate generated code lines with an uncertainty heatmap; auto-prioritize unit tests where model uncertainty is highest; block merge when uncertainty remains above threshold without tests. Tools/products: VS Code/JetBrains plugins; CI gates; “uncertainty-to-tests” generators. Assumptions/dependencies: Access to n-best samples/self-consistency; developer buy-in for guardrails.
- Healthcare (non-diagnostic, low-stakes settings): Triage assistants that hedge and cite. For administrative and guideline lookups, assistants add confidence statements and link to sources; trigger clinician review when below a threshold. Tools/products: EHR-integrated copilot with confidence banners and source links. Assumptions/dependencies: Strict scope (no autonomous diagnosis); audit logging; clinical governance.
- Finance/Legal Drafting: Source-required suggestions under low confidence. Drafting assistants insert inline hedges and require citations before finalization; route uncertain sections to human review. Tools/products: Word/Docs add-ons; redline workflows keyed on uncertainty. Assumptions/dependencies: Model risk policies; audit trails; document retention.
- Education: “Think-with-uncertainty” classroom workflows. LMS prompts that require the model to state confidence, alternatives, and verification plans; grading rubrics reward responsible use over blind certainty. Tools/products: LMS plugins; assignment templates. Assumptions/dependencies: Instructor training; student guidance on interpreting uncertainty.
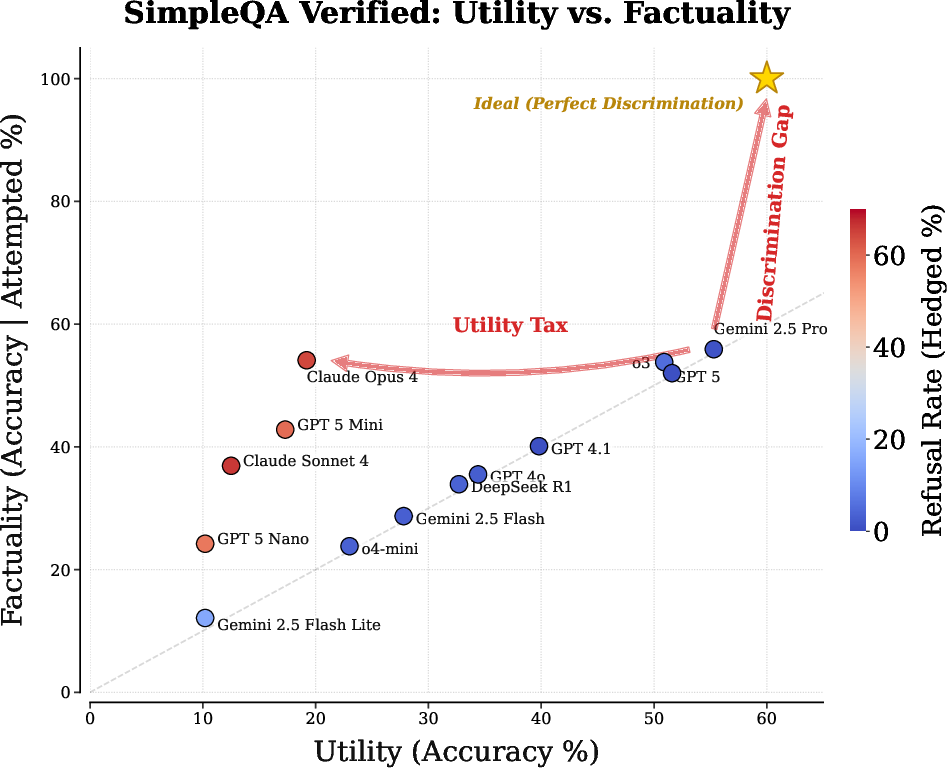
- Product Analytics and Evaluation: Utility–Error dashboards. Monitor accuracy, refusal, and the full Utility–Error trade-off curve across domains; detect drift in post-training that degrades uncertainty quality. Tools/products: Reliability dashboards; offline evaluation scripts (e.g., SimpleQA Verified). Assumptions/dependencies: Ground-truth subsets; standardized logging.
- Policy and Governance (org-level): Procurement and internal standards that require uncertainty disclosure. Mandate confidence signaling and escalation for high-risk use cases; track “attempted accuracy” and Utility–Error curves in model risk reviews. Tools/products: RFP clauses; internal AI-use policies. Assumptions/dependencies: Minimal measurement standard; governance forums.
- Safety-Critical Gating: Dual-review on low confidence. Require a second model, external retrieval, or human approval when uncertainty exceeds threshold; record decisions for audit. Tools/products: Approval queues; risk-tiered routing. Assumptions/dependencies: Clear thresholds; latency budgets.
Long-Term Applications
These depend on further research, scaling, and standardization—especially in faithful mapping from intrinsic to linguistic uncertainty, “uncertainty-preserving” alignment, and agent architectures that use uncertainty as a control signal.
- Training and Alignment — Uncertainty-Preserving Post-Training. Develop alignment methods (SFT/RLHF/RLAIF) that maintain or enhance intrinsic uncertainty signals rather than overconfident mode-seeking; dynamic SFT that labels uncertainty relative to the model’s current state. Tools/products: “UPA” (uncertainty-preserving alignment) recipes; dynamic data generation pipelines. Assumptions/dependencies: Access to base models; online labeling infra; new objectives/rewards.
- Confidence Attribution and Rich Epistemics. Disentangle epistemic (knowledge gaps), aleatoric (prompt ambiguity), and normative (policy) uncertainty; output structured “why uncertain” fields to drive targeted actions (e.g., ask for clarification vs retrieve vs abstain). Tools/products: Uncertainty schema/ontology; structured uncertainty APIs. Assumptions/dependencies: Advances in interpretability and representation learning; evaluation of attribution correctness.
- Agent Architectures with Uncertainty-as-API. Make metacognition the control layer for planning, tool selection, stopping, conflict resolution, and trust arbitration between internal beliefs and retrieved evidence. Tools/products: Agent SDKs exposing confidence to planners; uncertainty-aware tree search; “verify-then-decide” harnesses. Assumptions/dependencies: Stable uncertainty signals under chain-of-thought; process-based evaluation.
- Sector Standards and Certification. Regulatory or industry standards that require faithful uncertainty in high-stakes deployments (healthcare, finance, aviation, energy), including “uncertainty passports” documenting operating characteristics (e.g., Utility–Error curves by domain). Tools/products: Compliance test suites; ISO-like guidance; third-party audits. Assumptions/dependencies: Consensus benchmarks; regulators with technical capacity.
- Healthcare CDS (regulated): Metacognitive clinical decision support. Systems that triage, propose differential diagnoses with explicit confidence and rationale, and trigger verification (labs/imaging) or specialist review when appropriate. Tools/products: CDS modules integrated with EHR and order sets. Assumptions/dependencies: Rigorous trials; FDA/EMA clearance; liability frameworks.
- Finance Model Risk Management: Confidence-aware model governance. Require Utility–Error curves, abstention policies, span-level uncertainty, and escalation thresholds in MRM; alerting on drift in discrimination/faithfulness. Tools/products: Risk dashboards; continuous validation pipelines. Assumptions/dependencies: Regulatory adoption; standardized metrics.
- Robotics and Autonomous Systems: Self-assessment for perception and planning. Use uncertainty to trigger active sensing, slow-down/stop behaviors, or re-plan; arbitrate between onboard estimates and map/cloud info. Tools/products: Uncertainty-aware planners; active perception controllers. Assumptions/dependencies: Real-time, stable uncertainty estimates; safety certification.
- Energy and Critical Infrastructure: Hedge-aware forecasting and control. Grid forecasting models emit confidence that drives reserve margins or human review; anomaly triage tied to uncertainty. Tools/products: Ops consoles with uncertainty overlays; automated reserve scheduling. Assumptions/dependencies: Domain calibration; simulation-based validation.
- Multimodal Trust Layers. Vision–language systems that highlight uncertain regions in images/videos, request additional views, or defer before making factual claims. Tools/products: VLMs with pixel/region-level uncertainty maps; guided capture flows. Assumptions/dependencies: Robust spatial uncertainty estimation; human factors research.
- Reliability-as-a-Service. Independent services that expose cross-model uncertainty scoring, span hedging, and Utility–Error optimization; plug-in evaluators for procurement. Tools/products: Metacognitive scoring APIs; procurement evaluation kits. Assumptions/dependencies: Vendor-neutral access; standardized interfaces.
- Education and Assessment at Scale. Credentials that evaluate a learner’s ability to use AI metacognitively (ask for uncertainty, verify, and cite) and systems that coach students to plan verification based on uncertainty. Tools/products: Proctoring with uncertainty-aware tasks; formative feedback agents. Assumptions/dependencies: Assessment design; academic integrity norms.
- Auditing, Logging, and Legal Defensibility. Immutable logs capturing confidence, sources, and actions taken; supports incident response and liability mitigation when errors occur. Tools/products: Tamper-evident logs; “explainable uncertainty” reports. Assumptions/dependencies: Privacy/compliance; storage/retention policies.
- Benchmarks and Leaderboards Focused on Reliable Utility. Public leaderboards that report Utility–Error curves, attempted accuracy, and faithfulness metrics (linguistic vs intrinsic uncertainty alignment), not just raw accuracy. Tools/products: Open datasets (tail facts, conflict scenarios); standardized scoring. Assumptions/dependencies: Community buy-in; testbed maintenance.
- Hardware/Runtime Support for Introspection. Model and runtime designs that expose logits, confidence features, and internal signals safely to downstream controllers without leaking sensitive data. Tools/products: Secure logit APIs; on-device introspection modules. Assumptions/dependencies: Vendor cooperation; privacy-preserving interfaces.
- Everyday Personal Assistants: Trust-by-design interactions. Assistants that give hypotheses with confidence, show key sources, and offer a “verification plan” (e.g., for travel visas, taxes, medical appointments), reducing over-reliance. Tools/products: Consumer UX paradigms for uncertainty; “verify with one tap.” Assumptions/dependencies: User literacy; minimal friction UX.
Cross-cutting assumptions and dependencies
- Access to intrinsic uncertainty signals: APIs must expose or approximate token logprobs, self-consistency, or semantic entropy; otherwise, weaker proxies limit fidelity.
- Faithfulness over calibration: Mapping internal uncertainty to language must be trained/evaluated to avoid performative hedging; requires new datasets and tests.
- Uncertainty-preserving alignment: RLHF/SFT often increases false confidence; new objectives that preserve/disentangle uncertainty are needed.
- Human factors and UX: Users must understand and act on uncertainty; design and education are critical to avoid alert fatigue or perceived incompetence.
- Governance and regulation: Adoption in high-stakes settings hinges on standards, audits, and liability frameworks that recognize uncertainty communication as a safety feature.
- Holistic evaluation: Report Utility–Error curves, attempted accuracy, and spillover effects to quantify the “utility tax” and avoid overfitting to refusal.
Glossary
- Abstention: The strategy or behavior of refusing to answer when uncertain, often used to reduce errors at the cost of utility. "and degrades abstention"
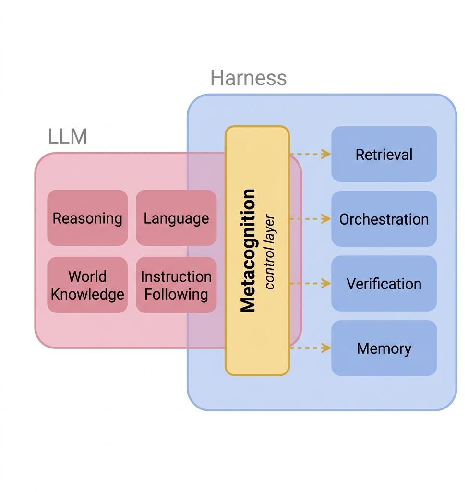
- Agent harness: The scaffold around an LLM that orchestrates tools and routing decisions during agent execution. "the agent harness, the scaffold that processes inputs, routes tool calls, and returns results."
- Agentic systems: LLM-based systems that act as agents, making decisions and invoking tools; metacognition serves as their control mechanism. "for agentic systems, it becomes the control layer governing when to search and what to trust."
- Aleatoric: Uncertainty arising from inherent ambiguity or noise in the input. "ambiguity in the prompt (aleatoric)"
- Alignment (techniques): Training and post-training methods that steer model behavior toward desired norms and safety constraints. "The failure of advanced alignment techniques, such as training models to ``confess'' errors"
- Attempted accuracy: Accuracy computed only over the subset of queries for which the model attempted an answer. "and attempted accuracy (correctness on the subset for which an answer was attempted)."
- AUROC: Area Under the Receiver Operating Characteristic curve, measuring a score’s ability to distinguish correct from incorrect answers. "we review AUROC values from the literature for the task of separating correct from incorrect answers using a model's confidence signal"
- Auto-regressive text generation: Sequential text generation where each token is predicted from previous tokens; implicated in structural limits on factuality. "extrinsic hallucinations are a structural inevitability of auto-regressive text generation."
- Calibration: Agreement between predicted confidence and empirical correctness rates. "calibration (confidence scores matching the probability of correctness) does not guarantee discrimination"
- Chain-of-thought: Explicit multi-step reasoning traces used during inference that can influence confidence and error rates. "By incentivizing extended chain-of-thought and persistence, these models essentially prioritize the completion of a reasoning path over abstention"
- Control layer: A metacognitive interface that governs when to search, verify, or trust internal vs. external information. "it becomes the control layer governing when to search and what to trust."
- Diagonalization: A theoretical technique used to prove impossibility results about universal truth verification. "utilized the Halting Problem and diagonalization arguments to prove that no computable model can universally verify truth"
- Discriminative power: The ability of a confidence signal to separate correct from incorrect answers at the instance level. "models may fundamentally lack the discriminative power to perfectly separate truths from errors."
- Discrimination: The instance-level separability of correct vs. incorrect predictions given a confidence score. "calibration does not imply discrimination."
- Epistemic: Uncertainty stemming from lack of knowledge rather than input ambiguity. "lack of knowledge (epistemic)"
- Expected Calibration Error (ECE): A scalar metric summarizing calibration by averaging confidence–accuracy gaps across bins. "moving away from calibration-based metrics (ECE)"
- Extrinsic hallucinations: Model outputs that are factually incorrect with respect to real-world knowledge. "we specifically target extrinsic hallucinations -- generations that are factually incorrect with respect to real-world knowledge"
- Faithful uncertainty: Aligning a model’s verbalized uncertainty with its internal (intrinsic) uncertainty on a per-answer basis. "What is needed is faithful uncertainty: hedging that reflects the model's actual internal state for each specific answer."
- Halting Problem: A classical undecidability result invoked to argue limits on universal truth verification by LLMs. "utilized the Halting Problem and diagonalization arguments to prove that no computable model can universally verify truth"
- Intrinsic signals: Internal signals derived from a model’s own computations that can be used for training or control (e.g., rewards). "the success of intrinsic signals as rewards in reinforcement learning"
- Intrinsic uncertainty: The model’s internal confidence about its answer, often operationalized as likelihood of generating conflicting answers. "aligning linguistic uncertainty with intrinsic uncertainty."
- Linguistic calibration: Training or prompting methods that adjust how confidently a model expresses claims in language. "mitigating overconfidence via linguistic calibration"
- Linguistic uncertainty: The uncertainty communicated in the model’s text output (e.g., hedges like “might” or explicit probabilities). "aligning linguistic uncertainty with intrinsic uncertainty."
- Long-tail knowledge: Rare or sparsely represented facts that lie outside common, frequently seen data. "we focus on tasks that require ``long tail'' knowledge"
- Mechanistic interpretability: Methods that analyze internal circuits/representations to understand and steer model behavior. "recent work in mechanistic interpretability demonstrates the feasibility of distilling self-awareness and confidence directly from the model"
- Metacognition: A model’s capacity to assess and act on its own uncertainty or knowledge state. "This is one facet of metacognition---the ability to be aware of one's own uncertainty and to act on it."
- Mode-collapse: A degeneracy where a model sacrifices diversity or breadth to avoid errors. "inevitably forcing the model into mode-collapse."
- Mode-seeking behavior: A tendency in aligned models to produce overconfident, less diverse outputs concentrated on high-probability modes. "Standard alignment techniques tend to induce mode-seeking behavior"
- Omniscience Index: A combined metric that summarizes both accuracy and coverage/attempt rates. "using summary metrics like F1 or Omniscience Index"
- Parametric LLMs: LLMs that rely solely on knowledge encoded in their parameters, without external tools. "Parametric LLMs rely on their own parameters"
- Parametric reliability: The factual reliability of an LLM when operating from its internal parameters alone. "Instilling metacognition thus addresses not only parametric reliability, but provides the foundation for robust agentic behavior."
- Post-training: Alignment or instruction-tuning stages applied after pretraining that can modify confidence properties. "that are degraded during post-training"
- Reliability diagram: A plot comparing predicted confidence to empirical accuracy across bins to visualize calibration. "to match the reliability diagram in \citet{nakkiran2025trained} (Figure 1)."
- Semantic entropy: An uncertainty measure based on diversity in semantically equivalent generations. "using semantic entropy"
- Self-verification: A procedure where the model evaluates or critiques its own outputs to detect errors. "or self-verification"
- SmoothECE: A smoothed variant of Expected Calibration Error used to assess calibration quality. "measured w. SmoothECE;"
- Supervised fine-tuning (SFT): Training on labeled examples to elicit desired behaviors like hedging or refusals. "supervised fine-tuning (SFT)"
- Sycophancy: Over-deference to external sources or user cues, even when conflicting with internal knowledge. "or trusting sources that conflict with known knowledge (sycophancy)"
- Utility-Error Trade-off: The curve showing how reducing errors via abstention lowers usable output (utility). "The Utility-Error Trade-off curve illustrates the cost of fully eliminating hallucinations."
- Utility-Factuality Trade-off: The tension between providing many answers (utility) and minimizing incorrect ones (factuality). "The Utility-Factuality Trade-off."
- Utility tax: The loss of useful correct answers incurred when abstaining to avoid hallucinations. "This visualizes the utility tax: without very strong discrimination, eliminating hallucinations requires suppressing a massive volume of correct information."
Collections
Sign up for free to add this paper to one or more collections.