Demystifying Manifold Constraints in LLM Pre-training
Abstract: The empirical success of LLM pre-training relies heavily on heuristic stabilization techniques, such as explicit normalization layers and weight decay. While recent constrained optimization approaches that explicitly restrict weights may improve numerical stability and performance, the mechanism and motivation for adding constraints still remain elusive. This paper systematically demystifies the role of explicit manifold constraints in LLM pre-training. By introducing the Msign-Aligned Constrained Riemannian Optimizer (MACRO)-a provably convergent, single-loop optimization framework-our study disentangles weight regularization heuristics from interacting mechanisms like RMS normalization and decoupled weight decay. Theoretical analyses and comprehensive empirical evaluations reveal that manifold constraints independently bound forward activation scales and enforce stable rotational equilibrium, thereby subsuming the roles of these heuristic mechanisms. Evaluations on large-scale LLM architectures demonstrate that MACRO achieves highly competitive performance while rigorously preserving the theoretical guarantees of exact Riemannian optimization.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper looks at a simple question behind training LLMs: can we keep training stable and effective by gently “holding” the model’s weights on a safe shape, instead of relying on lots of extra tricks? The authors show that if you constrain weights to live on certain geometric shapes (like spheres), you can steady the model’s internal signals, reduce the need for common stabilizers (like normalization layers and weight decay), and still get strong performance. They introduce a new optimizer called MACRO that does this efficiently and with mathematical guarantees.
What questions did the authors ask?
In friendly terms, the authors wanted to find out:
- Do geometric “guard rails” on weights (called manifold constraints) by themselves make training stable and good, without needing as many add‑on tricks?
- How do different constraints compare: ones that limit the worst possible stretching of signals versus ones that limit average energy?
- What happens when you combine (or remove) common tools like normalization layers and weight decay with these constraints?
- Can we design a practical, fast optimizer that keeps weights on these shapes and still comes with solid theory?
How did they study it? (Methods in simple terms)
Think of each weight matrix in a neural network layer like a stretchy sheet that turns input vectors into output vectors. If that sheet can stretch too much in any direction, signals can blow up or vanish as they pass through layers. The authors propose to keep that sheet lying on a fixed shape, so it can’t stretch or shrink in unsafe ways.
They focus on a few “shapes” (constraints):
- Spectral sphere: keeps the maximum stretch in any direction capped (think: the tightest the sheet can pull).
- Frobenius sphere: keeps the average energy of the sheet fixed (think: overall “size” stays constant).
- Oblique manifolds: keep each row or column at a fixed length (think: each feature’s contribution stays steady).
To make this work in practice, they design an optimizer called MACRO:
- Imagine you’re walking on a curved surface (the constraint shape). Riemannian optimization is the math of taking steps that stay on that surface. MACRO computes a direction to go downhill on the surface and then “retracts” back onto the surface so you never wander off.
- It picks a “steepest descent direction” that respects the shape (using a matrix sign trick to aim your step) and scales every update so that the ratio between how much you move and how big your weights are is tightly controlled.
- It’s “single‑loop,” meaning it doesn’t need slow inner correction loops. That makes it efficient for big models.
- The authors also prove a standard kind of convergence guarantee: as you train longer, you get closer to a stationary point at a known rate.
What did they find, and why is it important?
Here are the main results, in plain language:
- Different constraints control different kinds of scale:
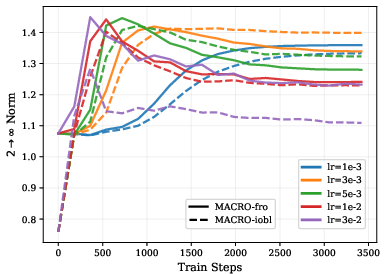
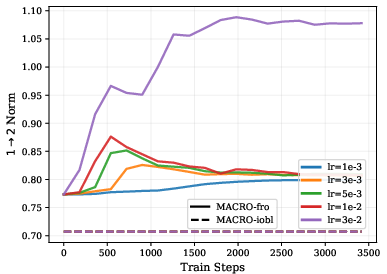
- Spectral sphere tightly caps the worst‑case amplification of signals (the absolute most any input can be stretched). This gives a strong safety guarantee.
- Frobenius sphere controls the average scale of signals. It’s good for typical behavior but less strict about rare extreme cases.
- Constraints overlap with normalization layers:
- RMSNorm and similar layers are like volume knobs that rescale activations. The constraints already keep activations in a healthy range.
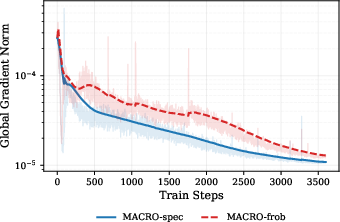
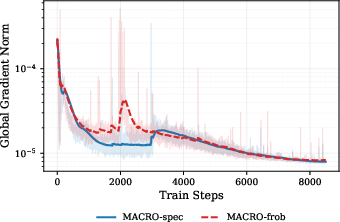
- In tests, when the authors removed the learnable normalization layers, a popular optimizer (Muon) sometimes failed at normal learning rates. MACRO stayed stable and performed well, especially with the spectral sphere.
- This shows constraints can reduce reliance on normalization layers for stability.
- Constraints also replace what weight decay is doing:
- Weight decay slowly shrinks weights and changes how updates behave over time, but it’s a bit heuristic and can cause late‑training quirks.
- With constraints, MACRO fixes two key “geometry” properties from the start:
- The relative learning rate (how big each step is compared to the weight size) is locked to a simple rule. This makes training smoother and avoids late‑stage spikes.
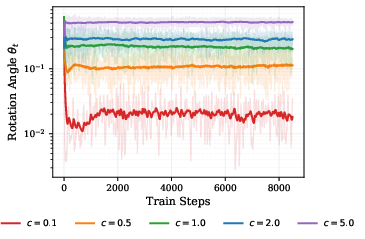
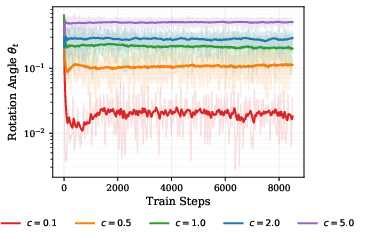
- The “rotation angle” between consecutive weights is controlled. On Frobenius spheres it’s basically fixed; on spectral spheres it adapts based on how separated the top singular values are. Either way, the turning behavior is stable and predictable.
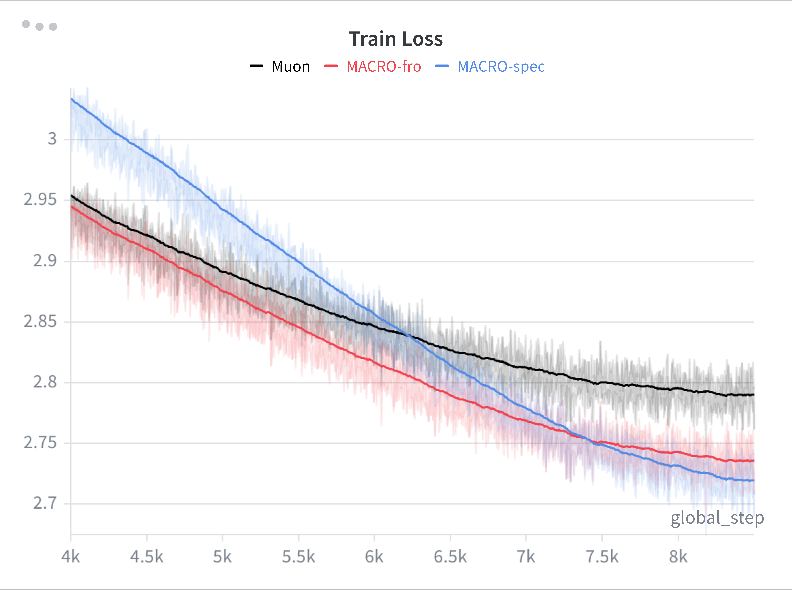
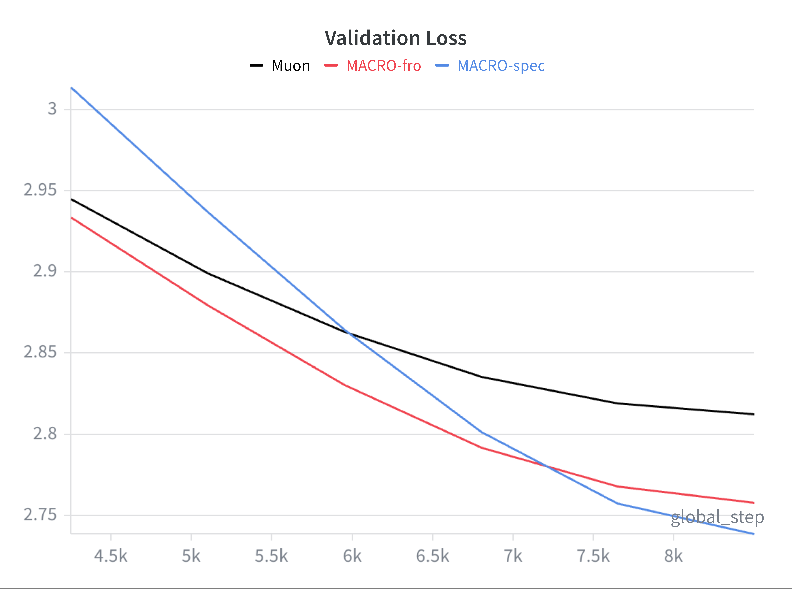
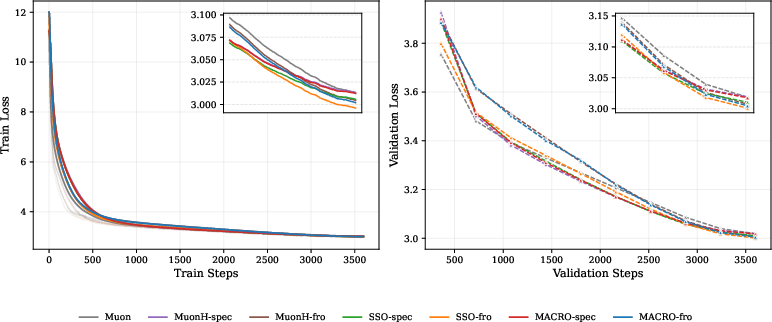
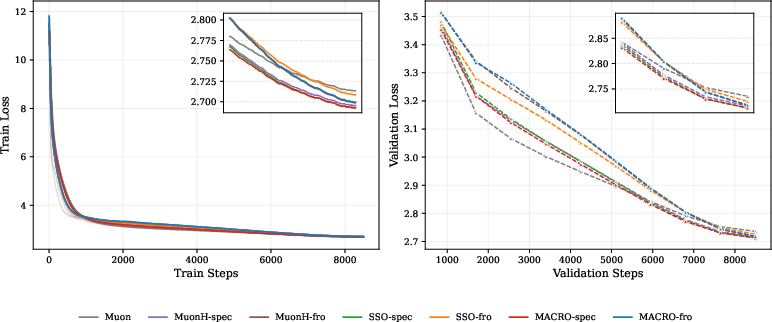
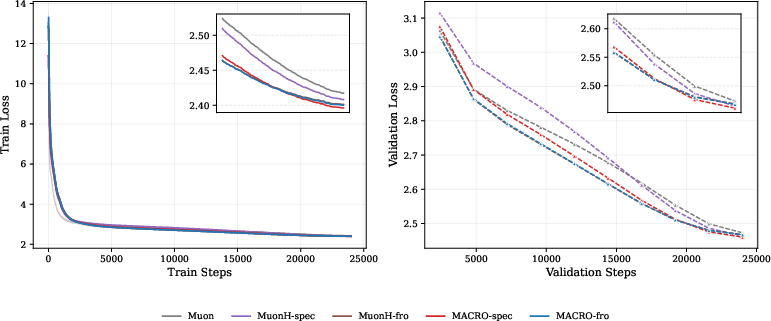
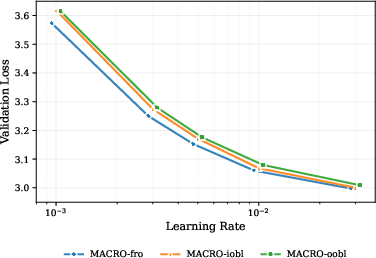
- It works at scale:
- On LLMs around 120M, 330M, and 1B parameters (QWEN3‑like setups), MACRO matched or slightly beat strong baselines. It also compared well to other constraint‑based methods while being faster than expensive “double‑loop” approaches.
- With normal architectures (that include RMSNorm), spectral and Frobenius constraints performed similarly. Without learnable norms, spectral had a clearer stability edge.
In short, the constraints directly keep layer outputs from blowing up, make optimization steps well‑behaved, and can simplify the training recipe.
What does this mean going forward? (Implications)
- Simpler, more reliable training: By baking stability into the geometry of the weights, you may need fewer hand‑tuned tricks like heavy normalization and weight decay. That can make training more robust and predictable.
- Better understanding of what stabilizes LLMs: The paper clarifies that a big part of “why training works” is about controlling how much layers can stretch signals. Doing that with constraints is principled and transparent.
- Practical benefits: MACRO is efficient and comes with theory, so it’s a good candidate for large‑scale pre‑training. It can also help avoid late‑training instability that sometimes appears with standard weight decay.
- Future directions: The authors used one global radius per constraint; smarter, layer‑specific radii could further improve performance. There’s also room to tailor constraints to different modules (attention vs. MLP) for even better results.
Overall, the big takeaway is that carefully chosen geometric constraints on weights can stand in for several stabilization tricks, keep training steady, and deliver competitive or better performance—making LLM pre‑training both more principled and more robust.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of unresolved issues that future researchers could address.
- [Theory] Convergence guarantees do not cover the spectral-sphere case used in key experiments: the analysis assumes a compact C3 manifold and replaces the spectral sphere with a gap-constrained surrogate. Derive guarantees that handle the true spectral-sphere set (including repeated top singular values) and quantify behavior near eigenvalue multiplicities.
- [Theory] The convergence rate assumes unbiased stochastic gradients with bounded variance and smoothness; modern LLM training uses momentum, adaptive preconditioning, mixed precision, and data-parallel aggregation that violate these assumptions. Extend theory to momentum/adaptive methods and mixed-precision noise.
- [Theory] The “tangent space” and projection for the spectral sphere are used heuristically despite non-manifold structure. Formalize valid tangent-like constructions, or provide robust algorithms when the leading singular value is non-unique.
- [Theory] Current bounds focus on stationarity rates; there is no analysis of optimization geometry under nonconvex objectives (e.g., implicit bias, margin/max-margin behavior) induced by different manifolds. Characterize the solution bias introduced by Frobenius vs spectral constraints.
- [Theory] Forward-scale control is analyzed for a single linear layer; multi-layer residual networks with attention, gating, and parameter-free norms are not theoretically treated. Develop end-to-end stability guarantees that account for residual connections, RoPE, attention softmax, and SwiGLU (or other) nonlinearities.
- [Constraint design] A single global radius r is used for all layers; experiments show a small but persistent gap without learnable norms. Devise adaptive, per-layer (or per-parameter-group) radius schedules driven by activation/gradient statistics and study their effect on stability and generalization.
- [Constraint design] The proposed radius selection relies on assumptions such as high stable rank and λ_min(Σ_X)=Ω(1) with T≥d. Validate and/or relax these assumptions in regimes with short contexts, highly anisotropic inputs, or low stable rank during training.
- [Constraint design] The spectral constraint fixes the top singular value at R but leaves the tail unconstrained; study whether this induces undesirable anisotropy, mode collapse, or harms expressivity in deeper layers, and whether additional penalties on the spectrum tail are beneficial.
- [Constraint design] Oblique constraints were briefly compared and found inferior under matched Frobenius norms; investigate alternative per-row/column radius schedules or hybrid constraints (e.g., spectral+row) that might better suit different modules (Q/K/V vs MLP projections).
- [Architecture interplay] “Normalization-free” results still require parameter-free RMS norms and QK-norm; the minimal set of required normalizations remains unclear. Can manifold constraints alone eliminate both learnable and parameter-free norms (including QK-norm) without instability?
- [Architecture interplay] The Norm-Gated SwiGLU change is introduced to maintain stability without learnable norms; quantify its impact on gradient flow, expressivity, and inference-time behavior, and test whether other nonlinearities (e.g., GELU, ReLU, SiLU) behave differently under constraints.
- [Architecture interplay] The analysis targets linear layers; attention mechanisms (including softmax scaling and head aggregation) and positional encodings (RoPE) may introduce additional scale sensitivities. Provide theory and targeted constraints for Q/K/V/O and attention logits.
- [Weight decay] The claim “weight decay is not needed” is not fully stress-tested across tasks and scales. Systematically ablate weight decay across optimizers, datasets, and model sizes (including long training runs) to quantify generalization and stability differences.
- [Weight decay] MACRO “locks” the relative learning rate to c·η_t and enforces rotational behavior; there is no guidance for selecting c beyond coarse sweeps. Develop principled procedures to tune or adapt c online, including per-layer choices and safety bounds.
- [Weight decay] Rotational analysis focuses on the leading singular directions (spectral sphere) or a global Frobenius angle. Characterize rotation dynamics across the full spectrum and subspaces, especially when singular values are clustered.
- [Scalability/compute] msign requires SVD-like computations per step; overhead and memory costs at scale (e.g., >7B parameters, large hidden sizes) are not quantified. Benchmark wall-clock throughput, memory use, and communication overhead vs AdamW/Muon on multi-node, tensor/pipeline-parallel training.
- [Scalability/compute] Practical approximations to msign (e.g., truncated or randomized SVD, low-rank surrogates) are not analyzed theoretically or empirically. Evaluate approximation-quality vs compute trade-offs and their effects on stability/convergence.
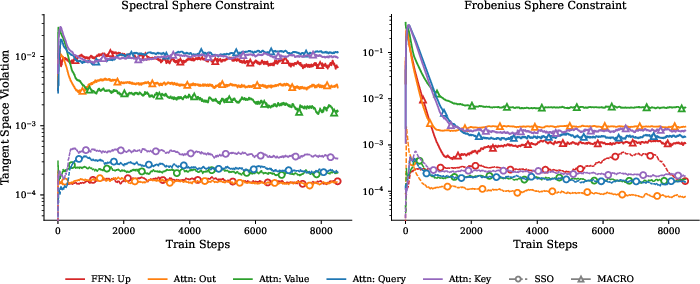
- [Scalability/compute] Double-loop methods (SSO/FSO) are omitted at 1B due to kernel limitations; quantify how closely MACRO adheres to constraints in practice (constraint violation over time) and whether tighter projections improve outcomes.
- [Empirical scope] Results are limited to 120M–1B QWEN3-like models and validation loss; there is no evaluation on standard downstream benchmarks (e.g., MMLU, HellaSwag), long-context robustness, or multilingual/generalization tests. Expand empirical evaluation to realistic scales and tasks.
- [Empirical scope] Dataset details, token distributions, and data diversity are not fully described in the main text; performance under domain shift and OOD generalization remains untested. Evaluate cross-domain robustness and catastrophic forgetting behavior.
- [Empirical scope] Sensitivity to hyperparameters (r, c, learning-rate schedules) and interactions with common training techniques (gradient clipping, label smoothing, EMA) are not systematically studied. Provide response surfaces and recommended defaults.
- [Empirical scope] Interactions with widely used optimizers (AdamW, Adafactor, Shampoo) are only partially explored via Muon variants. Compare against strong baselines with tuned weight decay and normalization settings.
- [Robustness] Mixed-precision training (bf16/fp8), loss-scaling, and numerical stability of projections/SVDs are not examined; NaN prevention is shown only for a specific setting. Test robustness under extreme learning rates, long training, and low-precision regimes.
- [Robustness] Constraint behavior under distributed training errors (e.g., stochastic all-reduce noise, asynchrony) is unstudied. Analyze stability under realistic systems noise and partial synchronization.
- [Theory-to-practice] The stationarity result hides dimension-dependent constants and uses generic O(T-1/4) rates; tighter, problem-dependent rates (e.g., under PL or sharpness assumptions) and explicit constant dependencies are missing. Derive sharper rates or finite-time bounds that reflect deep-network structure.
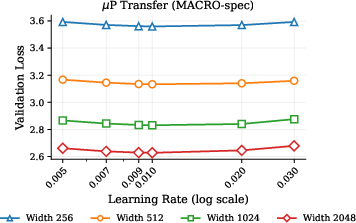
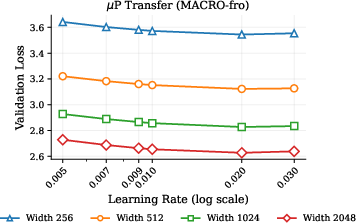
- [µP transfer] The paper asserts that locked relative updates enable strict µP transfer, with only brief empirical notes. Systematically validate µP transfer across widths/depths, including how radii should scale with width, and whether per-layer radii improve transfer.
- [Future design] Co-design of layer-specific geometric constraints (alluded to by the small gap without learnable norms) is left open. Explore automated policies that choose manifold types and radii per module (e.g., spectral for attention, Frobenius for MLP) based on training signals.
Practical Applications
Immediate Applications
Below are concrete ways the paper’s findings and MACRO optimizer can be applied right now, along with sector links, potential tools/workflows, and feasibility notes.
- Stabilize LLM pre-training without weight decay
- Sector: software/AI infrastructure, foundation model labs
- Potential tools/products/workflows:
- Replace AdamW/Muon’s weight-decay heuristics with MACRO’s manifold-constrained updates
- Training recipes that drop weight decay and monitor “relative learning rate” and “rotation angle” as first-class health metrics
- Assumptions/Dependencies:
- Efficient per-layer SVD or sign-operator routines (as in Muon) are available; cost acceptable relative to total training step time
- Empirically validated up to ~1B-parameter Qwen-like models in the paper; larger scales may need engineering
- Normalization-lite training recipes
- Sector: software/AI infrastructure
- Potential tools/products/workflows:
- Swap learnable RMSNorm for parameter-free normalizations and use Norm-Gated SwiGLU (provided in the paper) plus MACRO
- Simplify architecture configs; fewer trainable parameters; reduce tuning of norm hyperparameters
- Assumptions/Dependencies:
- Parameter-free RMS-scale ops and Norm-Gated SwiGLU operators must be implemented and numerically stable in your stack
- Paper shows small performance gap vs full RMSNorm; acceptable for many use cases
- More aggressive, safer learning-rate schedules
- Sector: MLOps, training operations
- Potential tools/products/workflows:
- LR schedules that exploit MACRO’s locked relative update magnitude (η_rel) to push higher initial LR with fewer divergences
- Reduced hyperparameter sweeps and fewer failed runs
- Assumptions/Dependencies:
- Monitoring of η_rel and step-to-step rotation to confirm regime; basic LR warmup still recommended
- Better stability in low-precision training (bf16/fp8) and long-context training
- Sector: AI infrastructure, hardware-accelerated training
- Potential tools/products/workflows:
- Combine MACRO’s activation-scale control with bf16/fp8 kernels and long-sequence training (e.g., RoPE + GQA)
- Fewer NaNs/overflows from unbounded activations in attention/MLP blocks
- Assumptions/Dependencies:
- fp8 readiness varies by hardware/software; the paper demonstrates stability logic but not explicit fp8 benchmarks
- Distributed training that is less fragile
- Sector: AI infrastructure (Megatron/DeepSpeed/DTensor ecosystems)
- Potential tools/products/workflows:
- Integrate MACRO into distributed pre-training pipelines; manifold constraints keep per-shard activation scales bounded
- Fewer “instability hotspots” in tensor/pipeline parallel boundaries
- Assumptions/Dependencies:
- Availability of distributed-friendly SVD/sign ops or blockwise/groupwise approximations
- More stable fine-tuning on small or specialized datasets
- Sector: product teams fine-tuning models for domains (legal, biomedical, code)
- Potential tools/products/workflows:
- Use spectral or Frobenius sphere constraints plus MACRO to reduce reliance on delicate weight-decay tuning
- Faster iteration with fewer restarts for LoRA/full-parameter fine-tunes
- Assumptions/Dependencies:
- Choose constraint type: spectral for worst-case control; Frobenius for average-case; modest tuning of radius r per paper’s guidance
- Robustness-oriented training for safety-critical deployments
- Sector: healthcare, finance, public sector
- Potential tools/products/workflows:
- Use spectral sphere constraints to bound operator norms in key blocks for more controlled behavior under input shifts
- Pair with existing validation/hardening pipelines
- Assumptions/Dependencies:
- No formal certification in the paper; robustness benefits are theoretically motivated and need task-specific validation
- Training diagnostics using geometric signals
- Sector: MLOps, observability
- Potential tools/products/workflows:
- Add dashboards for “relative learning rate” and “rotation angle” across layers/blocks to detect instability early
- Assumptions/Dependencies:
- Lightweight logging of norms/angles; negligible overhead compared to full profiling
- Curriculum for optimization and geometry in DL
- Sector: academia, education
- Potential tools/products/workflows:
- Course modules and assignments demonstrating Riemannian optimization and manifold constraints through MACRO
- Comparative labs of Muon/MuonH/SSO vs MACRO
- Assumptions/Dependencies:
- Open-source reference implementation; small models (≤300M) fit academic compute
- Open-source integration
- Sector: software ecosystems
- Potential tools/products/workflows:
- Add MACRO to Hugging Face/Lightning/Composer as a drop-in optimizer with recipes for radius selection and monitoring
- Assumptions/Dependencies:
- Clean API for choosing spectral vs. Frobenius spheres; backends for projections/retractions
Long-Term Applications
These opportunities need further research, scaling, or engineering before broad deployment.
- Layer-specific and data-adaptive geometric constraints
- Sector: software/AI research
- Potential tools/products/workflows:
- Learn or schedule per-layer radii R and alignment factor c based on measured stable rank, spectral gaps, or gradient statistics
- Assumptions/Dependencies:
- New meta-optimization policies; guardrails to prevent constraint collapse; ablations on large models
- Scaling MACRO to multi-billion/trillion-parameter regimes
- Sector: foundation model labs
- Potential tools/products/workflows:
- Custom CUDA kernels for tangent projections, retractions, and matrix-sign approximations; mixed-precision SVD
- Assumptions/Dependencies:
- Engineering to keep per-step cost comparable to AdamW/Muon; kernel fusion and blockwise/groupwise designs
- Manifold-aware variants of Adam/Adafactor/Shampoo
- Sector: optimizer research
- Potential tools/products/workflows:
- Riemannian AdamW/Adafactor that respect constraints and keep η_rel and rotation regulated
- Assumptions/Dependencies:
- Convergence theory with momentum/preconditioning on manifolds; stability under stochasticity at scale
- Certified control of Lipschitz constants for safety and robustness
- Sector: healthcare, finance, autonomous systems
- Potential tools/products/workflows:
- Training pipelines that enforce spectral constraints end-to-end and report certifiable bounds on layer/operator norms
- Assumptions/Dependencies:
- Extensions beyond linear layers; efficient per-layer certification; task-level validation of safety benefits
- AutoML that exploits locked relative learning rate
- Sector: AutoML platforms
- Potential tools/products/workflows:
- Shrink HP search space (remove weight decay, narrow LR ranges); automatic selection of constraint type/radius
- Assumptions/Dependencies:
- Robust defaults for r, c across architectures; cross-task meta-analysis
- Cross-modal and control applications (vision, speech, robotics)
- Sector: robotics, autonomous systems, AV
- Potential tools/products/workflows:
- Apply spectral constraints to policy/value networks to bound activations and improve training stability of control stacks
- Assumptions/Dependencies:
- Validation on RL/IL workloads; interaction with target networks and off-policy updates
- Quantization-aware and compression-friendly training
- Sector: deployment/edge
- Potential tools/products/workflows:
- Train under spectral/Frobenius constraints to improve quantization robustness and calibration (e.g., 4–8 bit)
- Assumptions/Dependencies:
- Empirical studies linking constraint geometry to quantization error and calibration metrics
- On-device continual and federated learning with bounded updates
- Sector: mobile/IoT, federated learning
- Potential tools/products/workflows:
- Use locked η_rel to ensure bounded client updates, improving stability under heterogeneous data and low precision
- Assumptions/Dependencies:
- Communication-efficient implementations; privacy constraints; compatibility with FedAvg/FedOpt
- Green AI and policy reporting
- Sector: policy/ESG
- Potential tools/products/workflows:
- Standardized reporting that training with manifold constraints reduces failed runs/hyperparameter sweeps and energy use
- Assumptions/Dependencies:
- Measurement frameworks; third-party audits to translate stability gains into energy reductions
- Regulation-friendly training recipes
- Sector: policy/regulatory compliance
- Potential tools/products/workflows:
- Documented, geometry-regularized training procedures for high-assurance models (e.g., financial advice, clinical support)
- Assumptions/Dependencies:
- Industry standards around training process transparency; reproducibility protocols
- Continual learning with controlled drift
- Sector: enterprise ML, personalization
- Potential tools/products/workflows:
- Use rotational-equilibrium dynamics to reduce catastrophic drift when updating models over time
- Assumptions/Dependencies:
- Validation on real continual-learning benchmarks; interaction with replay/regularization methods
- Geometry-aware training observability products
- Sector: MLOps tooling
- Potential tools/products/workflows:
- Dashboards and alerts for spectral gaps, stable rank, rotations, and η_rel; policy triggers to adjust constraints on the fly
- Assumptions/Dependencies:
- Low-overhead metrics extraction; operator adoption in large-scale platforms
Notes on assumptions and dependencies common across applications
- Convergence guarantees rely on smooth losses, bounded-variance stochastic gradients, and (for full rigor) manifold regularity; spectral sphere requires a non-vanishing spectral gap for theory to strictly apply.
- Practicality hinges on efficient implementations of:
- Projections/retractions on chosen manifolds
- Matrix-sign (msign) computations (often via SVD); approximations or blockwise variants may be needed to control overhead
- The paper validates up to ~1B parameters on Qwen-like architectures. Exascale training will require kernel-level engineering and additional empirical validation.
- Choosing between spectral (worst-case control) and Frobenius (average-case control) constraints depends on risk tolerance and architecture; radius selection should follow the paper’s scaling guidance and monitored during training.
Glossary
- Affine parameter: A learnable scalar or vector that scales normalized activations in a normalization layer. "the RMSNorm layer~\cite{zhang2019rootmeansquarelayer} uses a learnable affine parameter, , to scale activations."
- Anisotropic rotation: Direction-dependent rotation where different subspaces rotate by different amounts during updates. "the Spectral sphere induces an adaptive, anisotropic rotation."
- Chinchilla-optimal token budget: A guideline for the number of training tokens optimal for a given model size. "Across all model sizes, our token budgets exceed the Chinchilla-optimal token budget."
- Decoupled weight decay: A regularization technique that shrinks weights independently of the gradient update. "Decoupled weight decay~\citep{loshchilov2019decoupledweightdecayregularization} is standard practice in model training."
- Embedded submanifold: A manifold that sits inside a higher-dimensional ambient space, inheriting its geometry. "For embedded submanifolds considered in this paper, Riemannian gradient is the projection of the Euclidean gradient to the tangent space"
- Frobenius norm: The square root of the sum of the squares of all entries of a matrix. "Moreover, denotes the Frobenius norm of ;"
- Frobenius sphere: The set of matrices with a fixed Frobenius norm. "Frobenius Sphere~\citep{wen2025hyperball}: Bounds the total Frobenius norm via ."
- Grouped-Query Attention (GQA): An attention variant that shares key/value projections across groups of queries to reduce compute/memory. "equipped with SwiGLU activations, Grouped-Query Attention (GQA), Rotary Positional Embeddings (RoPE), and pre-normalization RMSNorm."
- Hadamard product: Element-wise multiplication of two tensors of the same shape. "the Hadamard product fundamentally disrupts linear stability"
- Kronecker product: A block matrix product used to expand linear operations over sequences. "We can express this sequence-level operation using the Kronecker product: ."
- Linear Minimization Oracle (LMO): A procedure that returns the steepest descent direction under a given norm/constraint. "MACRO evaluates the Linear Minimization Oracle (LMO) on the Riemannian gradient."
- Lipschitz continuous gradient: A smoothness condition where the gradient does not change faster than a constant factor times the parameter change. "has -Lipschitz continuous gradient"
- Manifold constraints: Restrictions that force parameters (e.g., weights) to lie on a set with specific geometric structure. "This paper systematically demystifies the role of explicit manifold constraints in LLM pre-training."
- Matrix Sign Operator: The factor UVT in the SVD W=UΣVT, capturing only singular vector directions. "\operatorname{msign}(W) denotes the Matrix Sign Operator of matrix ."
- Maximal Update Parametrization (μP): A scaling rule for hyperparameters that preserves training dynamics across model widths. "It also enables strict Maximal Update Parametrization (P) transfer."
- Msign-Aligned Constrained Riemannian Optimizer (MACRO): A single-loop, provably convergent optimizer that performs constrained Riemannian updates aligned with the matrix sign. "By introducing the Msign-Aligned Constrained Riemannian Optimizer (MACRO)—a provably convergent, single-loop optimization framework—"
- Nonconvex smooth stochastic optimization: Optimization of smooth objectives with noise, lacking convexity. "This matches the rate for general nonconvex smooth stochastic optimization"
- Nuclear norm: The sum of singular values of a matrix; dual to the spectral norm. "and denotes the nuclear norm of , which is the dual norm of ;"
- Oblique manifold: The set of matrices whose rows or columns each have fixed Euclidean norm. "Input (resp. Output) Oblique Manifold~\citep{gu2026manorestrikingmanifoldoptimization:} Restricts each input (resp. output) feature dimension to a fixed magnitude"
- Parameter-free normalization: Normalization layers without learnable scale or bias parameters. "we still insert a parameter-free RMSNorm immediately after the attention block"
- Pre-normalization: Placing normalization layers before the main block computation (e.g., attention/MLP). "pre-normalization RMSNorm."
- Projection (retraction): The mapping that returns a point in the ambient space back onto the manifold after an update. "and use to denote the projection (retraction) of onto the manifold ."
- QK-norm: A normalization applied to query/key tensors to stabilize attention logits. "alongside QK-norm to stabilize the pre-softmax logits."
- Relative learning rate: The ratio of the update magnitude to the parameter magnitude. "the relative learning rate, defined as the magnitude ratio "
- Riemannian gradient: The projection of the Euclidean gradient onto the tangent space of a manifold. "Riemannian gradient is the projection of the Euclidean gradient to the tangent space"
- Riemannian optimization: Optimization methods that account for manifold geometry by updating along tangent spaces and retracting. "rigorously preserving the theoretical guarantees of exact Riemannian optimization."
- RMSNorm: A normalization that scales activations by their root-mean-square without centering. "the RMSNorm layer~\cite{zhang2019rootmeansquarelayer} uses a learnable affine parameter, , to scale activations."
- Rotary Positional Embeddings (RoPE): A positional encoding that rotates query/key vectors to encode relative positions. "equipped with SwiGLU activations, Grouped-Query Attention (GQA), Rotary Positional Embeddings (RoPE), and pre-normalization RMSNorm."
- Singular value decomposition (SVD): Factorization of a matrix into orthogonal singular vectors and nonnegative singular values. "where is the singular value decomposition of ."
- Spectral gap: The difference between the largest and second-largest singular values. "the spectral gap ."
- Spectral norm: The largest singular value of a matrix. " denotes the spectral norm of a matrix "
- Spectral preconditioning: Conditioning updates using spectral information (e.g., via matrix sign) to improve optimization. "maintains the spectral preconditioning benefits of the Muon~\citep{jordan2024muon} optimizer."
- Spectral sphere: The set of matrices with a fixed spectral norm. "Spectral Sphere~\citep{xie2026controlledllmtrainingspectral:} Constrains the maximum singular value via ."
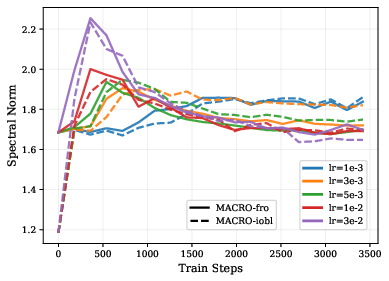
- Stable rank: A soft measure of matrix rank based on the ratio of Frobenius to spectral norms. "The weight matrix maintains a high stable rank"
- SwiGLU: A gated MLP activation variant combining Swish and linear gates. "For the SwiGLU activation, the Hadamard product fundamentally disrupts linear stability"
- Tangent space: The linear space of allowable directions at a point on a manifold. "we use to denote its tangent space at point ."
- Wedin sin Theta theorem: A perturbation bound relating changes in singular subspaces to the size of a matrix perturbation. "By Wedin theorem~\citep{davis1970rotation,wedin1972perturbation}, we provide the following bound"
- Weight decay: A regularization technique shrinking weights to control model complexity and dynamics. "weight decay~\cite{loshchilov2019decoupledweightdecayregularization} was originally proposed to improve generalization"
Collections
Sign up for free to add this paper to one or more collections.