- The paper introduces a Behavioral Integrity Verification (BIV) framework that compares declared and implemented capabilities in AI skills.
- It employs dual extraction tracks using deterministic parsing and static code analysis to identify deviations and uncover potential security threats.
- Evaluation on nearly 50,000 skills demonstrates high detection performance (F1=0.946), highlighting critical supply-chain risks and documentation gaps.
Behavioral Integrity Verification for AI Agent Skills: A Technical Summary
Motivation and Problem Definition
Third-party "skills" for LLM agents increasingly extend agent functionality with privileged capabilities such as filesystem access, credential management, network calls, or process execution. This third-party extensibility, paralleling historical vulnerabilities in mobile apps and browser extensions, introduces significant supply-chain security and compliance risks. Notably, agent skills frequently express functional commitments in multiple modalities: metadata, code, and natural-language instructions. This split enables a description-implementation gap, where a skill's declared behavior diverges from its runtime actions, including latent attack surfaces like prompt injections, obfuscated kill chains, and silent exfiltration.
The paper formalizes this challenge as the Behavioral Integrity Verification (BIV) problem: reconciling declared capabilities (from metadata) with actual implemented capabilities (from code and instructions), by reducing cross-modal matching to a typed set comparison over a shared 29-capability taxonomy. This structural analysis enables static, pre-install auditing that identifies both accidental documentation errors and adversarial intent.
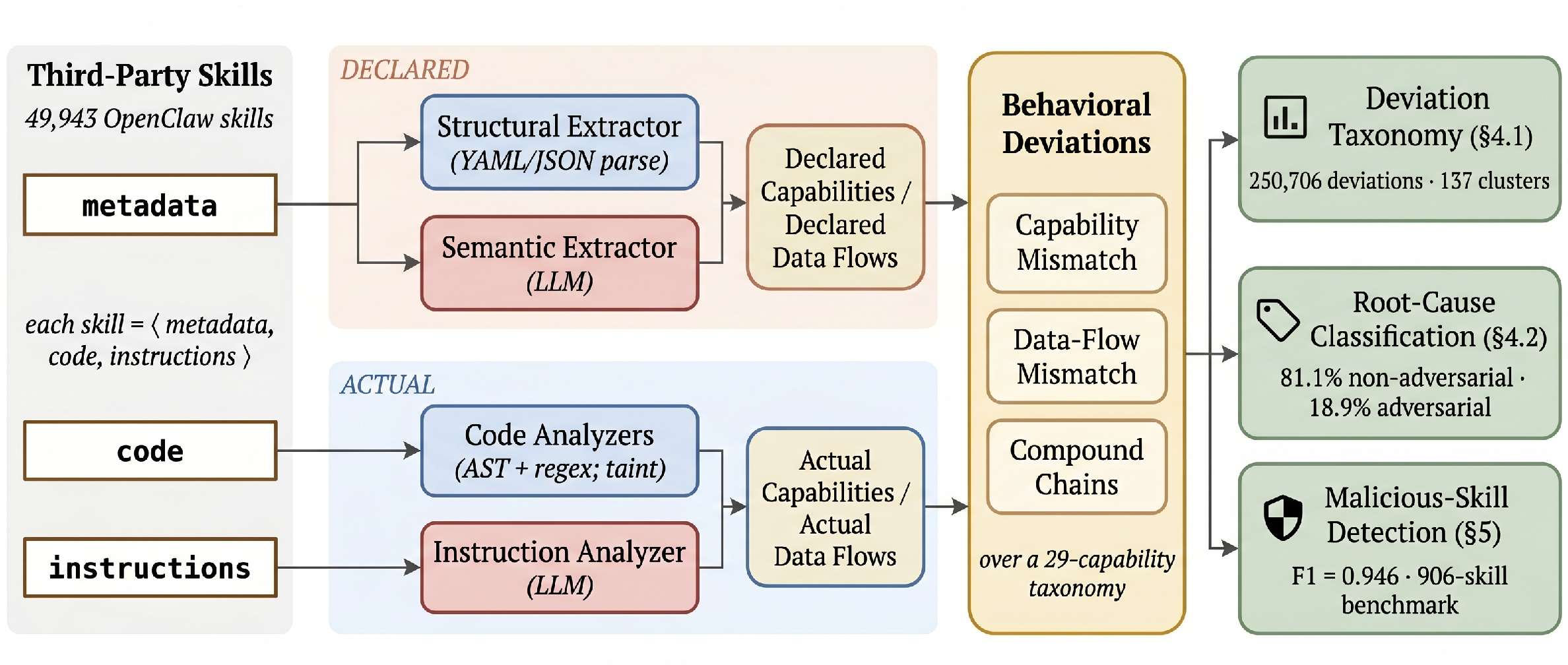
Figure 1: BIV processes a third-party skill along symmetric declared-behavior (metadata) and actual-behavior (code + instructions) tracks, converging on a 29-capability taxonomy and extracting behavioral deviations for downstream analysis.
Framework Architecture and Extraction Pipeline
The BIV pipeline is derived from two parallel extractor tracks per skill artifact s=(M,C,I):
- Declared track: Deterministic parsing of structured fields (YAML, JSON, markdown) is complemented by LLM-based extraction of capabilities from free-form metadata, with strict hallucination control. Both feed into a structured set of declared capabilities D(s)⊆T.
- Actual track: Static code analysis (AST, regex, literal patterns) over code and instructions detects implemented capabilities and data-flow chains, forming A(s)⊆T plus compound kill-chain flags. An LLM also parses instructions to surface prompt-injection and override motifs missed by deterministic analysis.
The pipeline’s output is a structured evidence tuple Φ(s) capturing declared/actual capability sets, source-to-sink data flow, and compound-threat motifs. Deviation is strictly defined as the symmetric set difference D(s)△A(s), enabling downstream applications.
Large-Scale Deviation Characterization
Applied to 49,943 skills from the OpenClaw registry, BIV extracted 250,706 deviations—with 80.0% of skills exhibiting description-implementation gaps. Deviation explanations are clustered using LLM embeddings and UMAP/HDBSCAN, yielding a 137-cluster taxonomy over seven capability categories and surfacing four novel compound threat categories invisible to single-pattern scanning. Deviations are predominantly under-specification (implemented but undeclared capabilities), concentrating operational risk on silent privilege escalation.
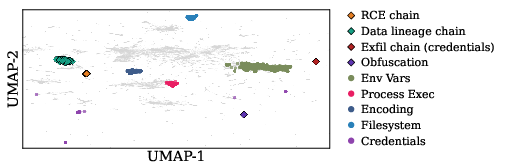
Figure 2: UMAP projection of clustered deviation embeddings reveals nine compact, well-separated representatives—highlighting both primitive capabilities and novel compound threats.
Filesystem, Process Execution, and Credentials dominate under-specification. Over-specification clusters (declared but not implemented) are tied to template residue and documentation lag. Compound clusters articulate multi-step adversarial motifs such as exfiltration, RCE chains, and obfuscation—notably, exfiltration chains (FILE_READ → NETWORK_SEND) and download-write-execute droppers.
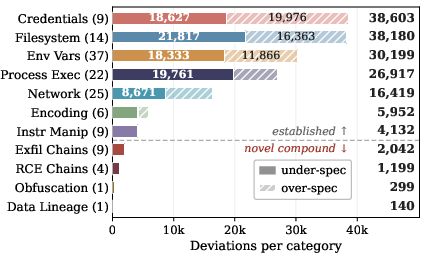
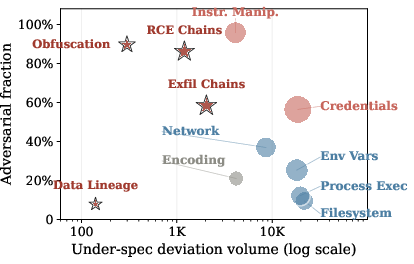
Figure 3: Left—deviation volume by category, split by direction. Right—relative adversarial fraction within each category; compound chains have the highest adversarial signatures.
Root-Cause and Intent Taxonomy
A hybrid rule-based plus LLM classifier assigns deviations to 36-leaf branches across adversarial and benign/non-adversarial categories. Rule-based intent labeling efficiently handles unambiguous cases using capability and structural evidence, while LLM analysis resolves multi-deviation chains and ambiguous cases jointly.
The results indicate a strongly asymmetric landscape: 81.1% of deviations stem from developer oversight or documentation errors, while 18.9% are linked to adversarial intent. Within adversarial cases, Data Theft/Espionage is the most prevalent, overwhelmingly due to credential or data exfiltration—whereas malicious financial, destructive, or social engineering threats are rare. Instruction-level threat deviations are extremely adversarial (≈96%).
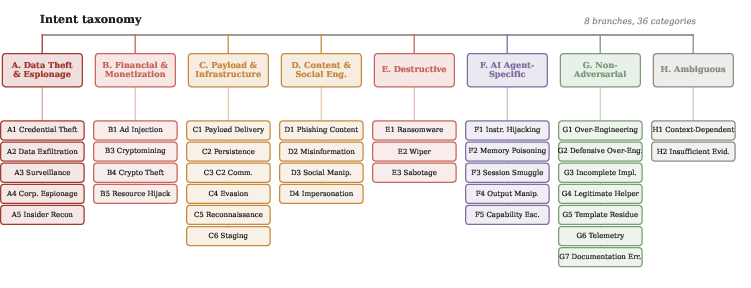
Figure 4: The 8-branch, 36-leaf intent taxonomy delineates adversarial, non-adversarial, and ambiguous threat classes.
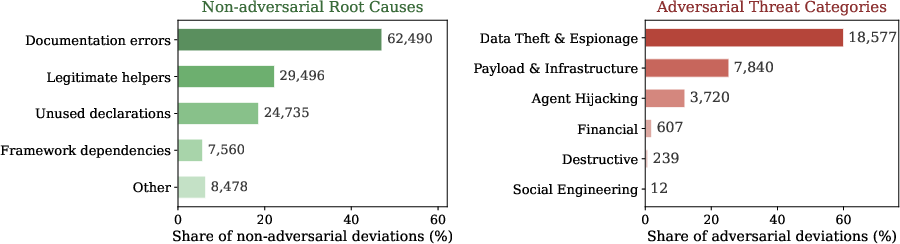
Figure 5: Distribution of intent classification across 163,754 deviations—adversarial threats are sharply concentrated, while benign classes suggest distinct remediation strategies.
At the skill level, 5.0% of skills involve compound, multi-stage attack chains warranting mandatory review, while another 16.8% trigger contextual review due to single-stage or suspicious indicators. The kill-chain distribution is top-heavy: two motifs—steal_exfil and hijack_exfil—account for the vast majority, streamlining triage.
Malicious Skill Detection: Case Study
Malicious-skill detection is demonstrated via an LLM judge consuming structured BIV evidence, with a relaxed-veto override predicate ensuring high-confidence structural threats cannot be rationalized away. On a 906-skill benchmark (404 malicious, 502 benign) spanning real-world and synthetic threats, the BIV detector achieves:
- F1 = 0.946 (recall 0.978, precision 0.917, FPR 7.2%; Claude Sonnet 4.5 backend)
- Outperforms rule-based baselines (F1=0.44) and LLM-only (F1=0.93) auditors, especially on real-world malware
- The relaxed-veto override fires only on compound, high-severity undeclared capabilities, avoiding false-positive explosion
The detection lift is attributable to structured evidence and the override mechanism, especially in adversarially crafted or obfuscated malware.
Implications and Future Directions
Practically, BIV enables static, scalable compliance and security auditing before agent-skill installation, surfacing both unintentional documentation drift and adversarial embedding. The structural evidence tuple is composable: deviation taxonomy, root-cause analysis, and detection are projections of the same pipeline, eliminating the need for separate, modality-specific tools.
Theoretically, the reduction of behavioral verification to typed set comparison enables reproducibility, auditability, and extensibility—generalizing to other modality-mixed extension ecosystems. BIV’s compositional approach suggests a shift from monolithic, black-box detection towards structured extraction pipelines whose evidence can be repurposed for multiple governance strategies.
Potential avenues for future work include:
- Dynamic analysis augmentation: Integrate lightweight sandboxed execution to close coverage holes from static limitations (dynamic dispatch, runtime reflection, and obfuscation).
- Cross-platform generalization: Portability studies for skill ecosystems in alternate agent platforms or application spheres.
- Longitudinal ecosystem drift: Monitor deviation taxonomies and intent surfaces over time as skill registries evolve.
- Red-team evaluation: Benchmark robustness against adversaries adapting extraction-aware evasion.
Conclusion
BIV delivers a typed, auditable framework for behavioral integrity verification across LLM agent skills, scaling from compliance audits to adversarial detection with a single evidence extraction pass. Registry-scale application reveals that unintentional specification drift dominates deviation frequency, though a core of adversarially composed skills establishes a persistent attack surface. BIV’s structured, compositional methodology provides a foundation for both large-scale governance and operational security in agent-extended AI ecosystems.

