Achieving Gold-Medal-Level Olympiad Reasoning via Simple and Unified Scaling
Abstract: Recent progress in reasoning models has substantially advanced long-horizon mathematical and scientific problem solving, with several systems now reaching gold-medal-level performance on International Mathematical Olympiad (IMO) and International Physics Olympiad (IPhO) problems. In this paper, we introduce a simple and unified recipe for converting a post-trained reasoning backbone into a rigorous olympiad-level solver. The recipe first uses a reverse-perplexity curriculum for SFT to instill rigorous proof-search and self-checking behaviors, then scales these behaviors through a two-stage RL pipeline that progresses from RL with verifiable rewards to more delicate proof-level RL, and finally boosts solving performance with test-time scaling. Applying this recipe, we train a 30B-A3B backbone with SFT on around 340K sub-8K-token trajectories followed by 200 RL steps. The resulting model, SU-01, supports stable reasoning on difficult problems with trajectories exceeding 100K tokens, while achieving gold-medal-level performance on mathematical and physical olympiad competitions, including IMO 2025/USAMO 2026 and IPhO 2024/2025. It also demonstrates strong generalization of scientific reasoning to domains beyond mathematics and physics.
First 10 authors:
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper shows a simple, step‑by‑step way to turn a general AI reasoning model into an Olympiad‑level problem solver for math and physics. The authors start with a good, medium‑sized model (about 30 billion parameters) and teach it to write clear, correct proofs, check its own work, and keep improving its solutions. The final model, called SU‑01, reaches gold‑medal performance on real International Mathematical Olympiad (IMO) and International Physics Olympiad (IPhO) problems, while also staying strong on science questions beyond math and physics.
What questions does the paper ask?
- Can we take a strong but general AI model and, with a simple and unified recipe, make it solve tough Olympiad problems that require long, careful proofs?
- Can the same training approach work for both math and physics (and even help with other sciences)?
- How can we make the model not just guess final answers, but actually produce complete, checkable proofs?
How did they do it?
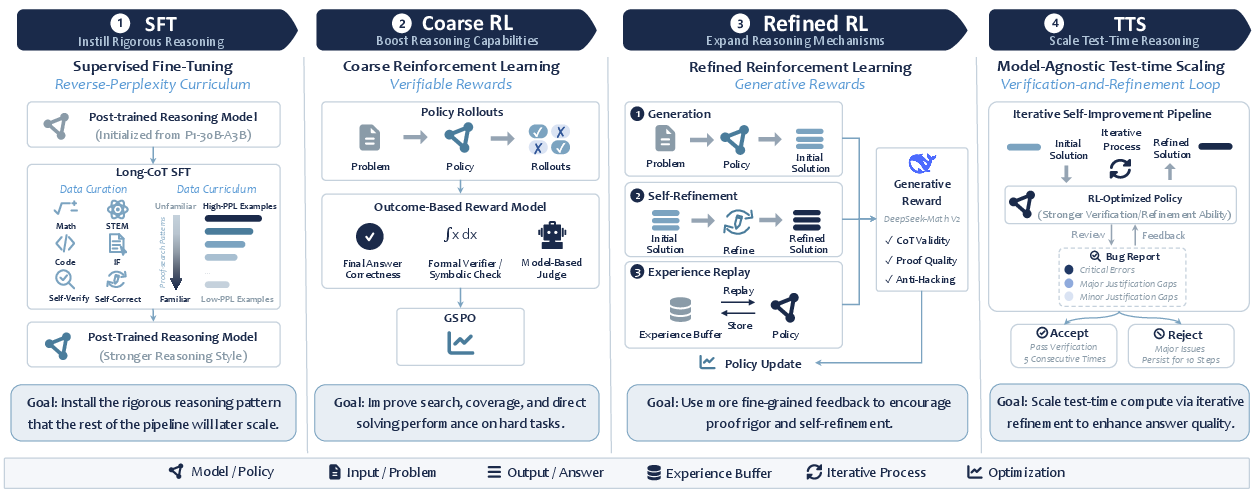
Think of training the model like coaching a smart student to win Olympiad medals. The coaching has three stages:
Stage 1: Supervised Fine‑Tuning (SFT) — “Learn from examples”
- What it is: The model reads many high‑quality, step‑by‑step solutions (including how to verify and fix its own work) and learns to imitate this rigorous style.
- Reverse‑perplexity curriculum: Imagine sorting practice problems from “most unfamiliar” to “most familiar” for the model. Each training pass starts with the unusual ones first. This helps the model adapt to new, proof‑focused habits without forgetting what it already knows.
- Data: About 340,000 solution “trajectories” (long, explained answers), mostly under 8,000 tokens, covering math, science, coding, and instruction‑following. Some examples include “self‑verification” (checking a solution) and “self‑refinement” (fixing errors found during checking).
Plain‑language analogy: This is like giving the student lots of marked‑up past solutions, plus red‑pen checklists that show how to spot and correct mistakes, starting with examples that feel the most different from their current style.
Stage 2: Reinforcement Learning (RL) — “Practice with feedback”
Two levels of practice, both giving the model feedback and rewards:
- Coarse RL (answer‑based rewards):
- The model tries many solutions to a problem; if the final answer is correct (checked by rules or tools), it gets a reward. This encourages better searching and coverage of solution ideas.
- Analogy: Using an answer key to quickly check whether the final result is right.
- Refined RL (proof‑quality rewards):
- Now the reward looks at the entire proof, not just the final answer. A separate “judge” model scores whether the reasoning is valid, complete, and rigorous.
- Self‑refinement: If a solution fails, it is turned into a “fix this proof” task so the model practices critiquing and repairing its own work.
- Experience replay: If the model rarely produces a great proof on a hard problem, that rare success is saved and replayed in future training—like keeping a “wins notebook” so the student can study and repeat their best ideas.
- Analogy: A teacher grades the full proof, not just the answer, and makes the student rework mistakes. The student also reviews their best past solutions to cement good habits.
Stage 3: Test‑Time Scaling (TTS) — “Multiple drafts with self‑checking”
- When solving a very hard problem, SU‑01 doesn’t just produce one shot. It loops through: 1) Solve, 2) Verify, 3) Refine, 4) Judge, and repeats as needed.
- The model can sustain very long solution processes (over 100,000 tokens), re‑reading its own drafts, finding errors, and improving the proof until it passes its own checks.
- Analogy: For a contest problem, the student writes a draft, self‑checks, revises, and repeats until the solution is tight enough to survive strict grading.
What did they find, and why does it matter?
- Strong benchmark scores:
- On answer‑checkable tasks (like AIME and other math tests), SU‑01 performs on par with top similar‑size models, and often better on competition‑style math sets. This shows it hasn’t lost its basic problem‑solving power.
- On proof‑focused tasks (where the whole solution is graded), SU‑01 is best among similar‑size models in direct mode, and jumps much higher with test‑time scaling. This means the model truly learned to write solid, complete proofs, not just guess answers.
- Real Olympiad problems:
- Physics: SU‑01 crosses the IPhO gold medal score lines in 2024 and 2025 even without the extra test‑time loop; with it, scores improve further.
- Math: With the test‑time loop, SU‑01 earns 35 points on both IMO 2025 and USAMO 2026—the IMO gold threshold, and 10 points above the USAMO gold line. On USAMO 2026, 35 matches the highest reported human total that year.
- Why this matters: These are not just small benchmarks; they’re real contests that demand deep, careful reasoning and airtight solutions.
- Generalization beyond math and physics:
- Even though later training focused on math and physics, the model also improved on research‑style science questions (physics, chemistry, biology). This suggests the approach teaches general “good reasoning” habits, not just tricks for specific contests.
What does this mean for the future?
- A simple, unified recipe works: Starting from a good general model, you can teach rigorous, Olympiad‑level reasoning using three straightforward steps—learn from examples, practice with feedback, and spend more “thinking effort” at test time with self‑checks.
- Smaller models can go far: You don’t always need the biggest model if you train and test it the right way.
- Beyond contests: The same skills—proof discipline, self‑verification, and refinement—are useful for scientific research, coding, and any field that needs careful step‑by‑step thinking.
- Practical impact: This could lead to AI assistants that produce not only correct answers, but also clear, trustworthy explanations that stand up to expert review—helpful for education, advanced study, and real research.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, phrased to guide actionable follow-up research.
- Data transparency and reproducibility: The paper does not release or fully enumerate the 338K SFT trajectories and ~25K RL prompts (8,967 verifiable; 16,287 non-verifiable), making it difficult to verify decontamination, deduplication, and domain coverage or to replicate the exact training mixture.
- Contamination auditing: While decontamination is mentioned, no quantitative leakage audit is reported for benchmark (AnswerBench, ProofBench) or competition problems (IMO 2025, USAMO 2026, IPhO). A hash-based and semantic-similarity audit against all training sources and generated SFT data is needed.
- Quality of synthetic SFT supervision: A large portion of SFT supervision is generated by DeepSeek-V3.2-Speciale, but the paper does not quantify its error rate, conceptual coverage, or the fraction of retained trajectories after filtering; no manual audit is provided to estimate residual noise.
- SFT length mismatch: SFT caps responses at 8,192 tokens, yet the model runs >100K-token reasoning at inference. There is no ablation on how this length mismatch affects stability, error rates, or hallucination patterns in ultra-long contexts.
- Positional encoding and long-context stability: The paper does not specify the positional embedding scheme, extrapolation method (e.g., RoPE scaling, ALiBi), or failure modes at >32K, >64K, and >100K tokens—nor provide degradation curves as a function of context length.
- Reverse-perplexity curriculum robustness: The reverse-PPL ordering is proposed but not ablated against alternatives (random, ascending-PPL, per-domain ordering), nor is it evaluated for sensitivity to the initial policy, re-scoring per epoch, or domain-induced biases.
- Curriculum side-effects: The paper does not test whether reverse-PPL ordering causes catastrophic forgetting in non-math/non-physics domains or induces excessive conservatism in surface style versus genuine reasoning gains.
- RL hyperparameter clarity: Group size K, clipping ε, temperature, sampling budgets, and rollout lengths for GSPO are not reported; their influence on stability and performance is unknown.
- Small number of RL updates: Only “200 RL steps” are reported; the effective token-level training signal (rollouts per step, batch sizes, average output length) and convergence diagnostics remain unspecified, hindering reproducibility and interpretation.
- Reward-model dependence and bias: Refined RL uses DeepSeekMath-V2 as a binary proof judge for math (and apparently not physics). No judge-accuracy evaluation, bias calibration, or adversarial stress test is provided (e.g., deceptive-but-wrong proofs that exploit model-judge priors).
- Physics proof reward gap: The paper states “except for physics prompts” when using the math proof reward model, but does not describe the alternative reward system for physics proofs—leaving unclear how proof-level rigor was optimized for physics.
- Verifier fallback ambiguity: Coarse RL uses a cascade ending with gpt-oss-120b for ambiguous cases. The false positive/negative rates of each verifier stage and their aggregate effect on reward correctness are not quantified.
- Anti-hack safeguards: “Anti-hack preprocessing” removes malformed outputs before the reward model, but there is no systematic catalog of exploit classes or a red teaming evaluation demonstrating the safeguards’ sufficiency against reward hacking.
- Experience replay design space: Replay thresholds (e.g., 0 < n+(q) < 2; retire at n+(q) ≥ 4), ratio ρ = 0.25, and lowest-entropy selection are introduced without ablations; it is unknown whether these choices prematurely bias learning toward conservative solutions or reduce exploration.
- Self-refinement schedule: The refinement trigger τref = 0.5 and insertion ratio ηref = 0.2 are not justified by sensitivity studies; it remains unclear how different schedules trade off stability vs. improvement, or whether recursive refinement (currently disabled) would help.
- Frozen MoE router: Freezing the MoE router during RL stabilizes replay but may limit capacity utilization or expert specialization for proof subskills; no comparison is provided against partial or adaptive router updates.
- Generalization beyond math and physics: Despite claims of transfer, absolute scores on Chemistry/Biology remain modest. There is no analysis of which reasoning primitives transfer and which domain-specific skills are missing, nor experiments adding minimal domain supervision or tools.
- Tool integration gap: The approach is purely LLM-based; it does not explore integration with formal proof assistants (Lean/Isabelle), CAS (SymPy), or domain tools (geometry verifiers), which could strengthen proof checking and reduce reliance on noisy reward judges.
- TTS budget and cost-effectiveness: Test-time scaling achieves large gains but the paper lacks a thorough compute-cost profile (iterations, parallel runs, tokens per stage), cost–performance trade-offs, and sensitivity to hyperparameters (temperatures, stopping rules).
- Self-verification loop reliability: The same model performs solve–verify–refine; potential confirmation bias and convergence to self-consistent-but-wrong proofs are not stress tested (e.g., by cross-verifier models or external checkers).
- Human grading protocol transparency: For competition TTS results, “human experts” graded solutions, but the protocol lacks details on rubric, inter-rater agreement, blinding, and reconciliation—limiting confidence in the reported full-credit claims.
- Failure mode analysis depth: Only brief case studies are presented. A systematic taxonomy of failures (e.g., missing invariants, case completeness, non-local dependencies, combinatorial structure preservation) is missing, as are targeted interventions validated by ablation.
- Scaling across model sizes: The recipe is demonstrated on a single 30B-A3B backbone; there are no scaling-law experiments across smaller and larger models to characterize data/RL/TTS budgets needed for given performance targets.
- Compute reporting: Claims of “lower training cost” are not backed by precise FLOP counts, wall-clock times, GPU types, and batch sizes for SFT, RL, and TTS—preventing fair comparison with baselines.
- Domain and language coverage: Training/evaluation is primarily in English, with sources from various communities; cross-lingual robustness, and performance on non-English olympiad problems, are not assessed.
- Multimodal reasoning: Many olympiad and physics problems involve diagrams/figures; the approach is text-only and does not address multimodal inputs or figure-grounded reasoning.
- Partial-credit alignment: Refined RL uses a binary proof reward; no exploration is done on partial-credit or rubric-aligned reward shaping that mirrors human grading (e.g., stepwise credit for lemmas/cases).
- Benchmark robustness: ProofBench/AnswerBench automatic grading reliability and sensitivity to solution style are not discussed; no sanity checks via alternative graders or human audits are reported.
- Distribution shift and risk: The paper does not explore robustness under adversarial or out-of-distribution olympiad-style tasks (e.g., novel topics, intentionally tricky “pathological” problems), nor calibration under test-time distribution shifts.
- Safety and misuse: There is no discussion of the societal risks of releasing an olympiad-level solver, including academic integrity, competitive fairness, or mechanisms for responsible use.
- Legal/licensing constraints: Use of AoPS content, training books, and third-party generated data (and reward/judge models) may be subject to licensing restrictions; the paper does not clarify legal compliance or redistribution rights.
- Reusability of the reward models: The math reward model (DeepSeekMath-V2) and gpt-oss-120b are external; if unavailable or updated, reproducibility and future training stability may be impacted—no fallback or open-source equivalent is proposed.
- Extensibility to research-level tasks: Although SU-01 leads similar-size models on FrontierScience-Research, absolute performance remains low. The paper does not explore which additional signals (e.g., modeling tools, citation-grounded judging, datasets) are most effective to close the gap.
- Attribution of gains: Aside from a high-level “progressive” plot, the paper lacks controlled ablations isolating contributions from reverse-PPL SFT, RLVR, proof-level RL, self-refinement, replay, and TTS—leaving causal attribution uncertain.
- Geometry-specific reasoning: The pipeline does not analyze geometry-specific weaknesses or the value of specialized geometry tools (e.g., symbolic geometry solvers), despite geometry being a frequent IMO failure mode (e.g., IMO P6).
Practical Applications
Immediate Applications
The following applications can be deployed with current methods and tooling described in the paper (reverse-perplexity SFT, RL with verifiable and proof-level rewards, experience replay, and test-time verification–refinement loops). Each item lists sectors, example tools/workflows, and key dependencies or assumptions.
- Bold: Olympiad- and advanced-STEM proof tutor and coach
- Sectors: Education, EdTech
- Tools/workflows: An SU-01-powered “Proof Coach” that generates hints, detects gaps via self-verification, and guides refinement for contest math/physics problems; instructor dashboards to visualize proof-search traces and bug reports.
- Dependencies/assumptions: Access to long-context inference (potentially >100K tokens) for harder problems; guardrails to avoid leaking full solutions when only hints are desired; content decontamination for fair use in training.
- Bold: Automated proof grading with structured feedback
- Sectors: Academia (university math/physics), EdTech
- Tools/workflows: Batch grading with Math-Verify and a proof reward model to score rigor and completeness; rubric mapping that converts proof-level scores into course-specific grades; flagging borderline cases for TA review.
- Dependencies/assumptions: Human-in-the-loop QA; course-specific rubrics; documented limitations on non-math domains; privacy controls for student submissions.
- Bold: Research manuscript “proof/derivation linter”
- Sectors: Academia, Publishing
- Tools/workflows: Overleaf/LaTeX plugin that runs a solve–verify–refine loop on stated theorems, lemmas, and derivations; structured bug reports (missing cases, unjustified steps, algebraic slips); cross-referencing checks across appendices and supplements.
- Dependencies/assumptions: Reliable LaTeX parsing; compute budget for long sequences; author consent; reward model calibration to reduce false positives.
- Bold: STEM content creation with verified solutions
- Sectors: EdTech, Publishing
- Tools/workflows: Automated generation of problem sets, solution manuals, and difficulty-graded variants; self-verification to filter flawed outputs; versioned solution banks with audit trails.
- Dependencies/assumptions: Strong decontamination to avoid copyright issues; human editorial review for final publication.
- Bold: Engineering calculation checker and unit/assumption validator
- Sectors: Energy, Manufacturing, Civil/Mechanical Engineering
- Tools/workflows: Stepwise verification of equations, boundary conditions, and unit consistency; structured reports on implicit assumptions and missing constraints; integration with Jupyter/CAE pipelines.
- Dependencies/assumptions: Domain-specific verifiers (symbolic solvers, unit systems); organization-specific standards for acceptable approximations.
- Bold: Spreadsheet and quantitative model audit assistant
- Sectors: Finance, Operations, Internal Audit
- Tools/workflows: Parse spreadsheets, rebuild implied models, verify calculations against canonical methods, and produce an audit log; scenario checks for edge cases.
- Dependencies/assumptions: Data connectors and provenance tracking; numeric tolerance settings; human sign-off for material findings.
- Bold: Code reasoning and repair with proof-oriented self-refinement
- Sectors: Software, Competitive programming
- Tools/workflows: IDE extension that proposes algorithms, generates tests, and refines code when tests or proofs fail; uses the same critique-and-repair loop as for proofs.
- Dependencies/assumptions: Secure sandboxing; reliable test generation; domain-specific reward models (e.g., for algorithmic correctness and complexity).
- Bold: Long-document mathematical QA and cross-reference checking
- Sectors: Academia, Publishing, Legal/Policy analysis (quantitative appendices)
- Tools/workflows: End-to-end checking across chapters/appendices (>100K tokens), consistency of notation, and reuse of lemmas/results.
- Dependencies/assumptions: Long-context serving infrastructure; robust document chunking and reconstruction.
- Bold: RL post-training toolkit for reasoners
- Sectors: ML/AI tooling (industry, research labs)
- Tools/workflows: Reverse-perplexity SFT curriculum, GSPO-based RLVR, refined proof-level rewards, experience replay, and anti-hack preprocessing; router-freezing for MoE stability.
- Dependencies/assumptions: Access to or training of domain reward models (e.g., DeepSeekMath-V2-class); verifiers (Math-Verify, symbolic CAS); compute scheduling for on-policy and replay mix.
- Bold: Test-time scaling orchestrator (solve–verify–refine)
- Sectors: Platform/LLMOps, Enterprise AI
- Tools/workflows: A reusable inference controller that manages iterative drafting, verification prompts, verdict gating, and budget allocation; plug-and-play verifiers (rule-based, generative, symbolic).
- Dependencies/assumptions: Cost controls for long-horizon inference; verifier ensemble configuration; monitoring to avoid feedback loops.
- Bold: Policy memo and internal analysis checker
- Sectors: Policy institutes, Government analytics, ESG/Climate teams
- Tools/workflows: Structured verification of quantitative claims, formulae, and scenario calculations in policy briefs; red-teaming with bug reports and alternative derivations.
- Dependencies/assumptions: Domain-specific datasets and calculators; reviewer oversight; clear scoping to avoid overreach beyond quantitative content.
- Bold: Lab protocol and stoichiometry checker (low-stakes)
- Sectors: Biotech/Pharma R&D, Academic labs
- Tools/workflows: Verify stoichiometric computations, units, and error propagation; checklist generation and self-verification of steps.
- Dependencies/assumptions: Chemistry/biology verifiers; restricted to preclinical/low-risk contexts; human approval.
Long-Term Applications
These applications are feasible with additional research, domain-specific reward models/verifiers, scaling, or regulatory clearance. They extend the paper’s methods (proof-level RL, self-refinement, test-time scaling) into higher-stakes and broader domains.
- Bold: Formal-proof synthesis integrated with proof assistants
- Sectors: Academia, Software (formal methods)
- Tools/workflows: Translate natural-language proofs into Lean/Coq/Isabelle; round-trip verification with symbolic kernels; iterative repair guided by formal counterexamples.
- Dependencies/assumptions: Large paired datasets (natural language ↔ formal proofs); robust tactic synthesis; performance on deep dependencies.
- Bold: Scientific discovery copilot
- Sectors: Research (physics, chemistry, biology), Materials/Drug discovery
- Tools/workflows: Hypothesis generation, derivation of governing equations, sanity checks, and literature-grounded verification; integration with simulation for counterexample search.
- Dependencies/assumptions: High-quality domain reward models; simulators and curated corpora; strong human-in-the-loop scientific judgment.
- Bold: Safety-critical engineering verification
- Sectors: Aerospace, Automotive, Energy (power systems, nuclear)
- Tools/workflows: Verify stability proofs, constraints, and failure-mode analyses; formalize assumptions; generate adversarial scenarios.
- Dependencies/assumptions: Certification frameworks; coupling with formal verification tools; stringent reliability audits and liability regimes.
- Bold: Clinical reasoning and protocol verification
- Sectors: Healthcare, Clinical research
- Tools/workflows: Quantitative verification of dosing rules, trial power analyses, and decision trees; generate structured evidence maps for each step.
- Dependencies/assumptions: Medical-grade datasets; regulatory requirements (FDA/EMA); bias and safety audits; human clinician oversight.
- Bold: Financial model risk management autopilot
- Sectors: Finance, Insurance
- Tools/workflows: Continuous verify–refine across pricing, VaR, stress tests; counterfactual and edge-case analysis with auditable trails.
- Dependencies/assumptions: Real-time data access; model governance and SOX/MiFID compliance; stringent change management.
- Bold: Legal argument drafting and consistency checking
- Sectors: Legal services, Public policy
- Tools/workflows: Structure arguments, check internal consistency, verify citations; iterative refinement of briefs with explicit premises–conclusions chains.
- Dependencies/assumptions: Domain reward models tuned to legal standards; authoritative citation databases; confidentiality and privilege safeguards.
- Bold: Multi-agent self-verification knowledge systems
- Sectors: Enterprise AI, Knowledge management
- Tools/workflows: Teams of agents proposing, verifying, and refining models/policies; persistent experience replay of rare successful “proofs” (analyses) for institutional memory.
- Dependencies/assumptions: Orchestration infrastructure; cost-effective long-horizon inference; governance to prevent consensus failures.
- Bold: Robotics and autonomous planning with verify–refine loops
- Sectors: Robotics, Logistics, Autonomous vehicles
- Tools/workflows: Generate task plans, verify constraints in simulators, and refine plans; explicit bug reports on violated safety invariants.
- Dependencies/assumptions: High-fidelity simulators; safety monitors; real-to-sim gap handling; certification.
- Bold: Domain-general verifiable RL framework
- Sectors: ML/AI platforms
- Tools/workflows: Generalize GSPO + reward stacking + replay to coding, data analysis, and multimodal tasks; unify rule-based and generative verifiers to reduce reward hacking.
- Dependencies/assumptions: Scalable verifier development; anti-hack defenses; open benchmarks for process-level rewards.
- Bold: Adaptive curricula guided by reverse-perplexity
- Sectors: Education (K–12, higher ed, corporate training)
- Tools/workflows: Personalize lesson ordering by student-specific “reverse-PPL” with periodic recalibration; structured self-check and repair tasks.
- Dependencies/assumptions: Accurate assessment signals; fairness and accessibility considerations; privacy and telemetry controls.
- Bold: Regulatory impact simulators with auditable reasoning chains
- Sectors: Government, Climate/Energy policy
- Tools/workflows: Transparent solve–verify–refine analyses for policy options; versioned reasoning chains and error logs for public scrutiny.
- Dependencies/assumptions: Trusted datasets; institutional acceptance of AI-generated analyses; independent audits.
- Bold: CAS–LLM hybrid “Proof Engine”
- Sectors: Software tools for scientists/engineers
- Tools/workflows: Combine symbolic CAS (e.g., Mathematica/SymPy) with SU-01-style proof search and self-verification; two-way handoff of lemmas and counterexamples.
- Dependencies/assumptions: Tight API integration; licensing; latency optimizations for interactive use.
Notes on cross-cutting feasibility
- Test-time scaling is compute-intensive; budgeted orchestration and acceptance criteria are necessary to control costs.
- Verifier quality governs reliability. Many long-term applications require domain-calibrated reward models and/or coupling with formal/symbolic tools.
- Experience replay and router freezing stabilize RL for MoE models; reusing these design choices can reduce training instability in other domains.
- Anti-hack preprocessing for reward models should be considered a required component in any reward-driven training or evaluation loop.
- Human oversight remains necessary in high-stakes contexts; immediate applications are best confined to low- or medium-stakes settings with clear escalation paths.
Glossary
- Anti-hack preprocessing: A safeguard that sanitizes generations to prevent exploiting the reward model via formatting or repetition artifacts. "We therefore apply anti-hack preprocessing before sending a response to the reward model"
- Answer-verifiable: Describes tasks where correctness can be reliably checked by a final answer or automatic verifier. "The first family contains answer-verifiable reasoning tasks"
- Binary outcome reward: A reward signal that assigns 1 for a verified-correct solution and 0 otherwise. "a binary outcome reward"
- Canonicalized text matching: Normalizing textual answers to a standard form for reliable equality checking. "apply canonicalized text matching."
- Chain-of-thought prompting: A prompting technique that elicits step-by-step reasoning traces from models. "chain-of-thought prompting, math-specialized post-training, and reinforcement learning with verifiable rewards"
- Clipped sequence-level surrogate: The GSPO training objective that clips sequence-level importance ratios to stabilize policy updates. "updated with the clipped sequence-level surrogate"
- Coarse RL: The first RL stage that optimizes for correct outcomes using verifiable rewards to scale search and solving behavior. "Coarse RL uses verifiable prompts and efficient outcome checking"
- Deduplicate and decontaminate: Dataset cleaning steps removing duplicates and leakage from evaluation sets. "we first deduplicate and decontaminate the prompt pool."
- DeepSeekMath-V2 (generative reward model): A model used to judge full proofs and provide process-level rewards. "We use DeepSeekMath-V2 as a generative reward model for refined RL"
- Experience replay: Reusing high-value past trajectories during RL to reinforce rare successful behaviors. "experience replay for preserving rare successful trajectories on hard problems."
- Generative reward model: A model that reads a problem and full solution and outputs a judgment score, focusing on proof validity. "a proof-level generative reward model for scoring complete proofs"
- Generative verification: Using a large model to judge correctness when rule-based checks are inconclusive. "for generative verification."
- GRPO: A token-level policy-optimization baseline contrasted with GSPO in outcome-reward training. "than token-level GRPO because both reward assignment and policy clipping operate at the complete-response level."
- GSPO (Group Sequence Policy Optimization): A sequence-level RL algorithm that optimizes complete responses with group-based advantages. "Group Sequence Policy Optimization (GSPO; \citealt{zheng2025gspo})."
- Group-relative advantage: An advantage computed within a sampled group of responses for the same prompt. "The group-relative advantage is computed from the within-prompt reward baseline."
- Length-normalized perplexity: Perplexity averaged per token to compare trajectories of different lengths in curriculum ordering. "we score each example by its length-normalized perplexity"
- Long-CoT: Long chain-of-thought supervision emphasizing extended reasoning traces. "Long-CoT SFT on a post-trained reasoning model is a delicate optimization problem."
- Math-Verify: A rule-based pipeline that evaluates mathematical expressions in LLM outputs. "Unresolved cases are then checked by Math-Verify, a rule-based mathematical-expression evaluation pipeline for LLM outputs."
- Mixture-of-Experts (MoE) router: The component that routes tokens to experts in MoE models; frozen here to stabilize replay. "we freeze the MoE router during RL"
- Non-verifiable: Prompts or tasks whose correctness cannot be reliably auto-checked and require softer judgment. "non-verifiable or proof-oriented tasks."
- Proof-level RL: Reinforcement learning that optimizes for complete, rigorous proofs rather than only final-answer correctness. "more delicate proof-level RL"
- Proof-oriented: Evaluation focused on the validity and completeness of reasoning, not just final answers. "On proof-oriented evaluation, SU-01 reaches 57.6%"
- Proof rigor: The standard of complete, justified, and logically sound proofs. "a solver prompt that prioritizes proof rigor rather than merely reaching a final answer."
- Proof search: Exploring and constructing candidate proof paths systematically. "rigorous proof-search patterns."
- Refined RL: The second RL stage focusing on proof quality with process-level rewards, self-refinement, and replay. "Refined RL then shifts the target from answer correctness to proof quality."
- Refinement prompts: Prompts created from failed attempts that instruct the model to critique and repair its solution. "converted into refinement prompts."
- Rejection sampling: Filtering out too-easy or too-hard examples relative to the current policy before training. "We then apply rejection sampling to remove examples that are already too easy or too hard for the current policy"
- Replay buffer: A storage of successful trajectories keyed by query for targeted re-use during training. "we keep a replay buffer keyed by query"
- Reverse-perplexity curriculum: Training order that starts each epoch with examples the current policy finds hardest (highest perplexity). "a reverse-perplexity curriculum for SFT"
- RLVR (Reinforcement Learning with Verifiable Rewards): RL framework that uses automatic verifiers to provide reliable reward signals. "reinforcement learning with verifiable rewards (RLVR; \citealt{lambert2024tulu,r1})"
- Routing-replay motivation: A GSPO rationale to freeze routing so replayed trajectories see stable expert assignments. "Following the routing-replay motivation in GSPO"
- Self-refinement: The behavior of critiquing a draft solution and producing a repaired version. "self-verification and self-refinement behaviors."
- Self-refinement buffer: A queue of refinement tasks mixed into training to teach critique-and-repair. "These prompts are stored in a self-refinement buffer"
- Self-verification: The model’s process of checking its own solutions for errors or gaps. "self-verification and self-refinement behaviors."
- Sequence-level importance ratio: The GSPO ratio comparing new vs. old policy likelihoods over the entire generated sequence. "The key GSPO quantity is the length-normalized sequence-level importance ratio"
- SFT (Supervised fine-tuning): Supervision that reshapes the model’s reasoning behavior by imitating curated trajectories. "SFT on this rigorous proof data instills reasoning behaviors centered on proof search, self-checking, and repair."
- Self-verification and refinement loop: An inference procedure that iterates solve, verify, and repair until a stable proof is reached. "as a self-verification and refinement loop."
- Test-time scaling (TTS): Allocating extra inference-time compute through multi-round verification and refinement to solve harder problems. "and finally boosts solving performance with test-time scaling."
- Truncation rate: The fraction of generations that hit the length limit; used as an indicator of stable long-form reasoning. "a truncation rate below 5\% is a useful sign"
- Verification prompt: A prompt asking the model to inspect a solution and produce a structured bug report. "a verification prompt: the model inspects the full solution and writes a structured bug report"
- Verdict step: The component that interprets the verification report to accept, reject, or refine a candidate solution. "A verdict step interprets this report and decides whether the candidate should be accepted, rejected, or sent back for another refinement round."
- Verifiable prompts: Prompts whose outputs allow reliable automatic checking to produce rewards. "Coarse RL uses verifiable prompts and efficient outcome checking"
- Within-prompt reward baseline: The average reward over a sampled group for the same prompt used to compute advantages. "within-prompt reward baseline."
Collections
Sign up for free to add this paper to one or more collections.

