Label-free Node Classification on Graphs with Large Language Models (LLMS)
Abstract: In recent years, there have been remarkable advancements in node classification achieved by Graph Neural Networks (GNNs). However, they necessitate abundant high-quality labels to ensure promising performance. In contrast, LLMs exhibit impressive zero-shot proficiency on text-attributed graphs. Yet, they face challenges in efficiently processing structural data and suffer from high inference costs. In light of these observations, this work introduces a label-free node classification on graphs with LLMs pipeline, LLM-GNN. It amalgamates the strengths of both GNNs and LLMs while mitigating their limitations. Specifically, LLMs are leveraged to annotate a small portion of nodes and then GNNs are trained on LLMs' annotations to make predictions for the remaining large portion of nodes. The implementation of LLM-GNN faces a unique challenge: how can we actively select nodes for LLMs to annotate and consequently enhance the GNN training? How can we leverage LLMs to obtain annotations of high quality, representativeness, and diversity, thereby enhancing GNN performance with less cost? To tackle this challenge, we develop an annotation quality heuristic and leverage the confidence scores derived from LLMs to advanced node selection. Comprehensive experimental results validate the effectiveness of LLM-GNN. In particular, LLM-GNN can achieve an accuracy of 74.9% on a vast-scale dataset \products with a cost less than 1 dollar.
- Understanding and improving early stopping for learning with noisy labels. Advances in Neural Information Processing Systems, 34:24392–24403, 2021.
- Large language models as annotators: Enhancing generalization of nlp models at minimal cost. arXiv preprint arXiv:2306.15766, 2023.
- Active learning for graph embedding. arXiv preprint arXiv:1705.05085, 2017.
- Exploring the potential of large language models (llms) in learning on graphs. arXiv preprint arXiv:2307.03393, 2023.
- Is gpt-3 a good data annotator? arXiv preprint arXiv:2212.10450, 2022.
- A survey for in-context learning. arXiv preprint arXiv:2301.00234, 2022.
- Active discriminative network representation learning. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence, IJCAI-18, pp. 2142–2148. International Joint Conferences on Artificial Intelligence Organization, 7 2018. doi: 10.24963/ijcai.2018/296. URL https://doi.org/10.24963/ijcai.2018/296.
- Chatgpt outperforms crowd-workers for text-annotation tasks. arXiv preprint arXiv:2303.15056, 2023.
- Citeseer: An automatic citation indexing system. In Proceedings of the Third ACM Conference on Digital Libraries, DL 9́8, pp. 89–98, New York, NY, USA, 1998. ACM. ISBN 0-89791-965-3. doi: 10.1145/276675.276685. URL http://doi.acm.org/10.1145/276675.276685.
- Gpt4graph: Can large language models understand graph structured data? an empirical evaluation and benchmarking. arXiv preprint arXiv:2305.15066, 2023.
- Inductive representation learning on large graphs. Advances in neural information processing systems, 30, 2017.
- Learning from imbalanced data. IEEE Transactions on Knowledge and Data Engineering, 21(9):1263–1284, 2009. doi: 10.1109/TKDE.2008.239.
- Explanations as features: Llm-based features for text-attributed graphs. arXiv preprint arXiv:2305.19523, 2023a.
- Annollm: Making large language models to be better crowdsourced annotators. arXiv preprint arXiv:2303.16854, 2023b.
- Graph policy network for transferable active learning on graphs. In H. Larochelle, M. Ranzato, R. Hadsell, M.F. Balcan, and H. Lin (eds.), Advances in Neural Information Processing Systems, volume 33, pp. 10174–10185. Curran Associates, Inc., 2020a. URL https://proceedings.neurips.cc/paper_files/paper/2020/file/73740ea85c4ec25f00f9acbd859f861d-Paper.pdf.
- Open graph benchmark: Datasets for machine learning on graphs. Advances in neural information processing systems, 33:22118–22133, 2020b.
- Active learning by querying informative and representative examples. In J. Lafferty, C. Williams, J. Shawe-Taylor, R. Zemel, and A. Culotta (eds.), Advances in Neural Information Processing Systems, volume 23. Curran Associates, Inc., 2010. URL https://proceedings.neurips.cc/paper_files/paper/2010/file/5487315b1286f907165907aa8fc96619-Paper.pdf.
- Semi-supervised classification with graph convolutional networks. arXiv preprint arXiv:1609.02907, 2016.
- BART: denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. CoRR, abs/1910.13461, 2019. URL http://arxiv.org/abs/1910.13461.
- Prompt-based zero-and few-shot node classification: A multimodal approach. arXiv preprint arXiv:2307.11572, 2023.
- Graphcleaner: Detecting mislabelled samples in popular graph learning benchmarks. arXiv preprint arXiv:2306.00015, 2023.
- Partition-based active learning for graph neural networks. arXiv preprint arXiv:2201.09391, 2022.
- Deep learning on graphs. Cambridge University Press, 2021.
- Automating the construction of internet portals with machine learning. Information Retrieval, 3:127–163, 2000.
- Wiki-cs: A wikipedia-based benchmark for graph neural networks. arXiv preprint arXiv:2007.02901, 2020.
- Automated annotation with generative ai requires validation. arXiv preprint arXiv:2306.00176, 2023.
- Gpt self-supervision for a better data annotator. arXiv preprint arXiv:2306.04349, 2023.
- Sentence-bert: Sentence embeddings using siamese bert-networks. In Conference on Empirical Methods in Natural Language Processing, 2019. URL https://api.semanticscholar.org/CorpusID:201646309.
- Dissimilar nodes improve graph active learning. arXiv preprint arXiv:2212.01968, 2022.
- Collective classification in network data. AI Magazine, 29(3):93, Sep. 2008. doi: 10.1609/aimag.v29i3.2157. URL https://ojs.aaai.org/aimagazine/index.php/aimagazine/article/view/2157.
- C. E. Shannon. A mathematical theory of communication. The Bell System Technical Journal, 27(3):379–423, 1948. doi: 10.1002/j.1538-7305.1948.tb01338.x.
- Learning from noisy labels with deep neural networks: A survey. IEEE Transactions on Neural Networks and Learning Systems, 2022.
- Just ask for calibration: Strategies for eliciting calibrated confidence scores from language models fine-tuned with human feedback. arXiv preprint arXiv:2305.14975, 2023.
- Graph attention networks. arXiv preprint arXiv:1710.10903, 2017.
- Can language models solve graph problems in natural language? arXiv preprint arXiv:2305.10037, 2023.
- Self-consistency improves chain of thought reasoning in language models. arXiv preprint arXiv:2203.11171, 2022.
- Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems, 35:24824–24837, 2022.
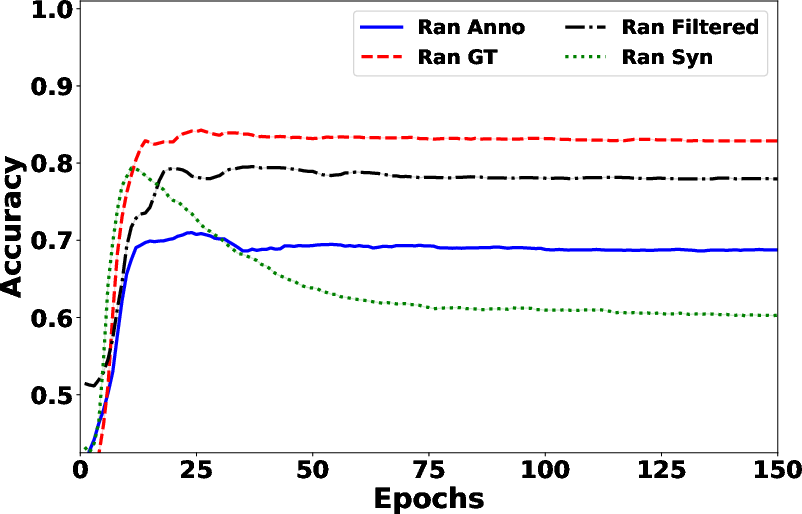
- Learning with noisy labels revisited: A study using real-world human annotations. arXiv preprint arXiv:2110.12088, 2021.
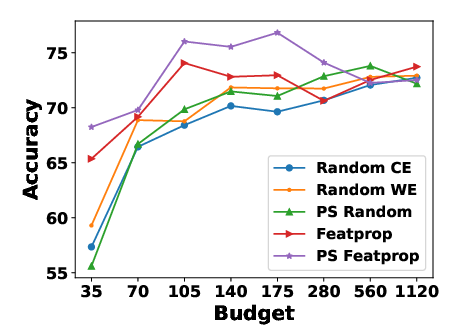
- Active learning for graph neural networks via node feature propagation. arXiv preprint arXiv:1910.07567, 2019.
- Can llms express their uncertainty? an empirical evaluation of confidence elicitation in llms. arXiv preprint arXiv:2306.13063, 2023.
- Revisiting semi-supervised learning with graph embeddings. ArXiv, abs/1603.08861, 2016. URL https://api.semanticscholar.org/CorpusID:7008752.
- Natural language is all a graph needs. arXiv preprint arXiv:2308.07134, 2023.
- Alg: Fast and accurate active learning framework for graph convolutional networks. In Proceedings of the 2021 International Conference on Management of Data, SIGMOD ’21, pp. 2366–2374, New York, NY, USA, 2021a. Association for Computing Machinery. ISBN 9781450383431. doi: 10.1145/3448016.3457325. URL https://doi.org/10.1145/3448016.3457325.
- Rim: Reliable influence-based active learning on graphs. Advances in Neural Information Processing Systems, 34:27978–27990, 2021b.
- Grain: Improving data efficiency of graph neural networks via diversified influence maximization. arXiv preprint arXiv:2108.00219, 2021c.
- Batch active learning with graph neural networks via multi-agent deep reinforcement learning. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 36, pp. 9118–9126, 2022.
- Shift-robust gnns: Overcoming the limitations of localized graph training data. Advances in Neural Information Processing Systems, 34:27965–27977, 2021a.
- Clusterability as an alternative to anchor points when learning with noisy labels. In International Conference on Machine Learning, pp. 12912–12923. PMLR, 2021b.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.