- The paper introduces a novel KD approach using discrete and continuous Wasserstein Distance to evaluate logit and feature distributions.
- It demonstrates significant improvements in image classification on ImageNet and object detection on MS-COCO relative to traditional KL divergence methods.
- While the approach increases computational cost, it offers a more accurate geometric interpretation of data and addresses limitations of standard KD paradigms.
"Wasserstein Distance Rivals Kullback-Leibler Divergence for Knowledge Distillation"
Abstract
The paper proposes a novel approach to Knowledge Distillation (KD) using the Wasserstein Distance (WD) as an alternative to the Kullback-Leibler Divergence (KL-Div), addressing several limitations in the traditional KD paradigm. Through rigorous evaluations on image classification and object detection benchmarks, including ImageNet, CIFAR-100, and MS-COCO, the research demonstrates that WD can effectively account for cross-category relations in feature space, thus enhancing the distillation process.
Introduction
Knowledge Distillation is a technique for transferring knowledge from a high-performance teacher model to a smaller, more efficient student model. Conventionally, KL-Div has been the predominant method used for KD, focusing solely on the matching of category probabilities between teacher and student models. The paper highlights two major issues with KL-Div: its inability to compare probabilities across different categories and its ineffectiveness when applied to intermediate layers due to non-overlapping distributions and lack of geometric understanding of the data manifold.
Proposed Method
Discrete WD for Logit Distillation
Discrete WD is introduced for logit distillation, allowing for cross-category comparison of probabilities. This method leverages rich interrelations among categories by using concepts like Centered Kernel Alignment (CKA) to quantify similarities between features of different categories.

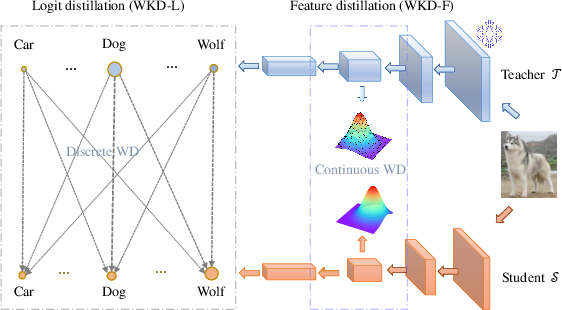
Figure 1: Real-world categories exhibit rich interrelations (IRs) in feature space.
Continuous WD for Feature Distillation
The paper also presents continuous WD for distilling intermediate layer information. Gaussian distributions are used to model the feature distributions within layers, allowing WD to measure dissimilarities across these distributions effectively using geometric properties inherent to the data's manifold.

Figure 2: Features are projected to 2D space using tSNE. Different categories are indicated by different colors.
Experimental Results
Extensive experiments validate the effectiveness of WD against KL-Div. Notably, the proposed discrete WD method outperformed existing KD techniques across various benchmarks. The continuous WD approach for feature distillation also showed significant improvements, particularly in capturing the geometric structure of data.

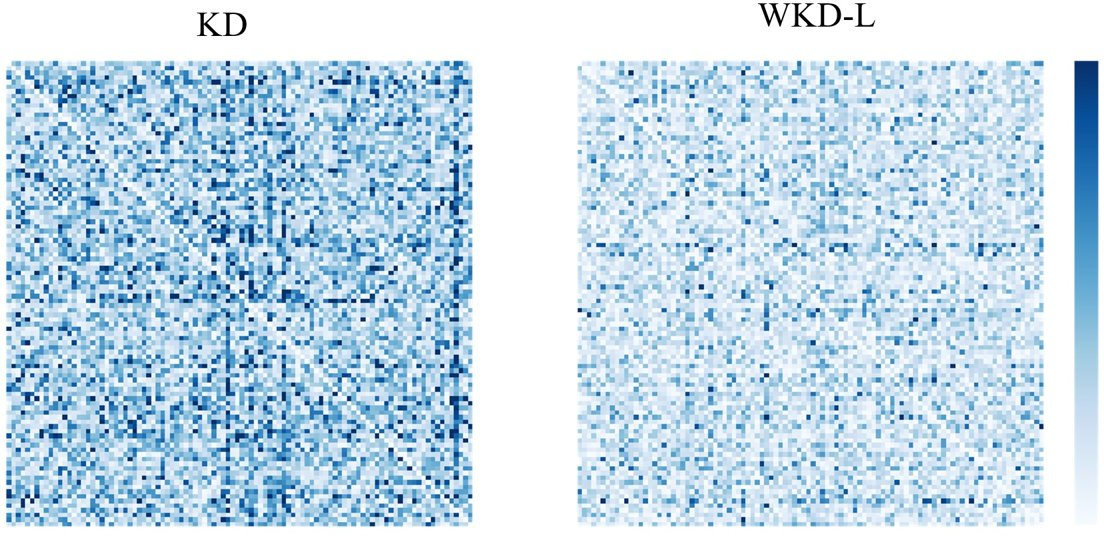


Figure 3: Visualization for WKD-L.
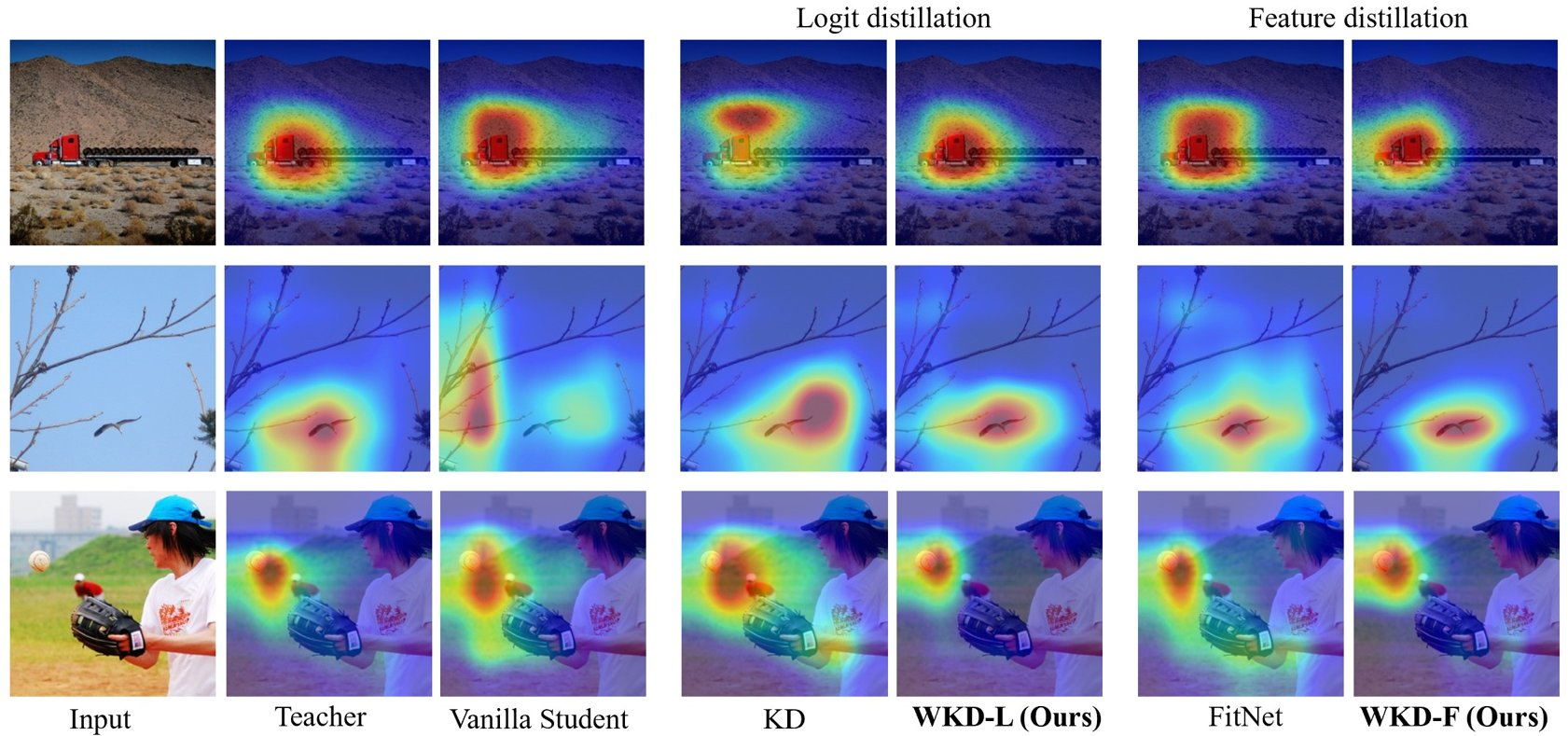
Figure 4: Visualization of CAM.
- Image Classification: On ImageNet, the proposed methods showed substantial gains, outperforming KL-Div-based methods like DKD, NKD, and OFA.
- Object Detection: WD techniques improved upon standard KD methods when applied to detection tasks on MS-COCO, showcasing better utilization of spatial feature maps for object localization.
- Computational Efficiency: Despite a higher computational cost, WD's performance gains justify the trade-off, and its application is highly beneficial in resource-limited settings.
Challenges and Trade-offs
While WD provides numerous advantages over KL-Div, it comes with increased computational demands, especially when computing discrete WD. However, these costs are mitigated by the potential improvements in model accuracy and reliability. The Gaussian assumption for feature distribution may limit applicability in scenarios where feature manifolds deviate significantly from this model.
Conclusion
The introduction of Wasserstein Distance as a rival to KL-Div in knowledge distillation paradigms is a promising advancement. It not only addresses previous limitations by leveraging cross-category interrelations but also provides enhanced performance metrics across varying benchmarks. Future research may focus on optimizing computational efficiency and exploring alternative statistical models beyond Gaussian assumptions for richer feature representation across neural networks.
In summary, the paper paves the way for more robust and theoretically sound approaches to KD, opening avenues for further exploration into advanced metrics like WD in model training and deployment in real-world applications.