- The paper introduces a multimodal chain-of-thought (MCoT) framework that transforms egocentric spatial descriptions into allocentric directions.
- The methodology integrates ASR-transcribed speech with spatial coordinates through structured reasoning, reaching 100% accuracy on clean text and 98.1% on noisy inputs.
- Ablation studies confirm the critical role of spatial data and structured CoT reasoning in mitigating ASR errors and enhancing orientation accuracy.
Summary of "Conversational Orientation Reasoning: Egocentric-to-Allocentric Navigation with Multimodal Chain-of-Thought"
Introduction
The paper "Conversational Orientation Reasoning: Egocentric-to-Allocentric Navigation with Multimodal Chain-of-Thought" introduces a novel benchmark and framework aimed at enhancing the reasoning capabilities of conversational agents. The problem addressed is the conversion of egocentric spatial descriptions, such as "on my right," into allocentric orientations like North, East, South, and West, particularly in environments lacking GPS signal or detailed maps. Utilizing a multimodal chain-of-thought (MCoT) framework, the study integrates automatic speech recognition (ASR) processed speech with spatial coordinates to guide an agent through this complex transformation.
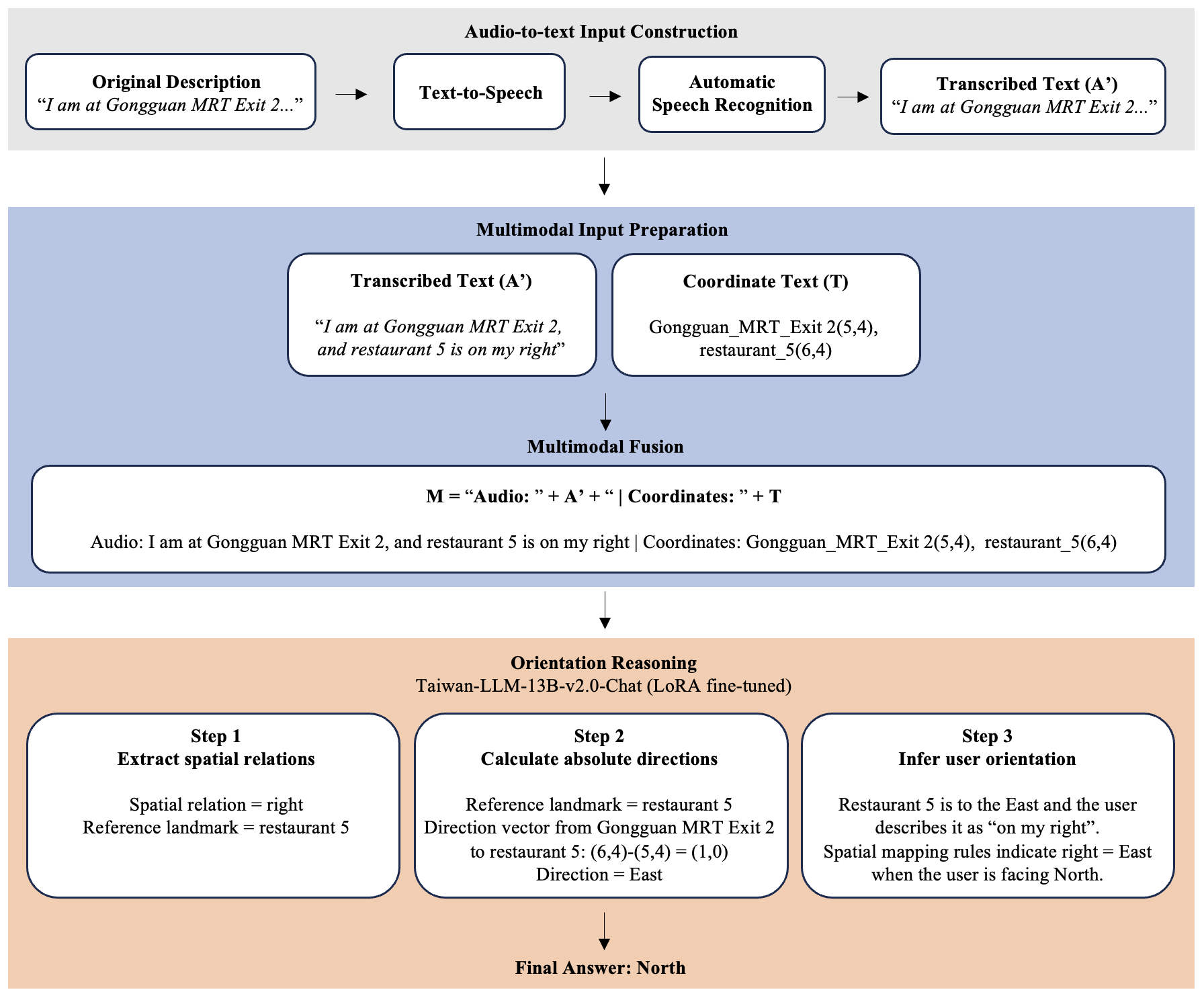
Figure 1: Pipeline of our MCoT framework. It consists of three modules: (1) speech synthesis and transcription, (2) multimodal input preparation and fusion, and (3) orientation reasoning.
Methodology
The MCoT framework proposed in the paper comprises three key modules: speech synthesis and transcription, multimodal input preparation, and orientation reasoning. The approach involves synthesizing speech from clean egocentric descriptions, transcribing them with ASR, and combining them with spatial coordinates to infer absolute directions. The orientation reasoning is structured into three stages: extracting spatial relations, mapping coordinates to absolute directions, and inferring user orientation. This framework is implemented on a mid-sized LLM, Taiwan-LLM-13B-v2.0-Chat, optimized for orientation reasoning in Traditional Chinese, under noisy ASR conditions.
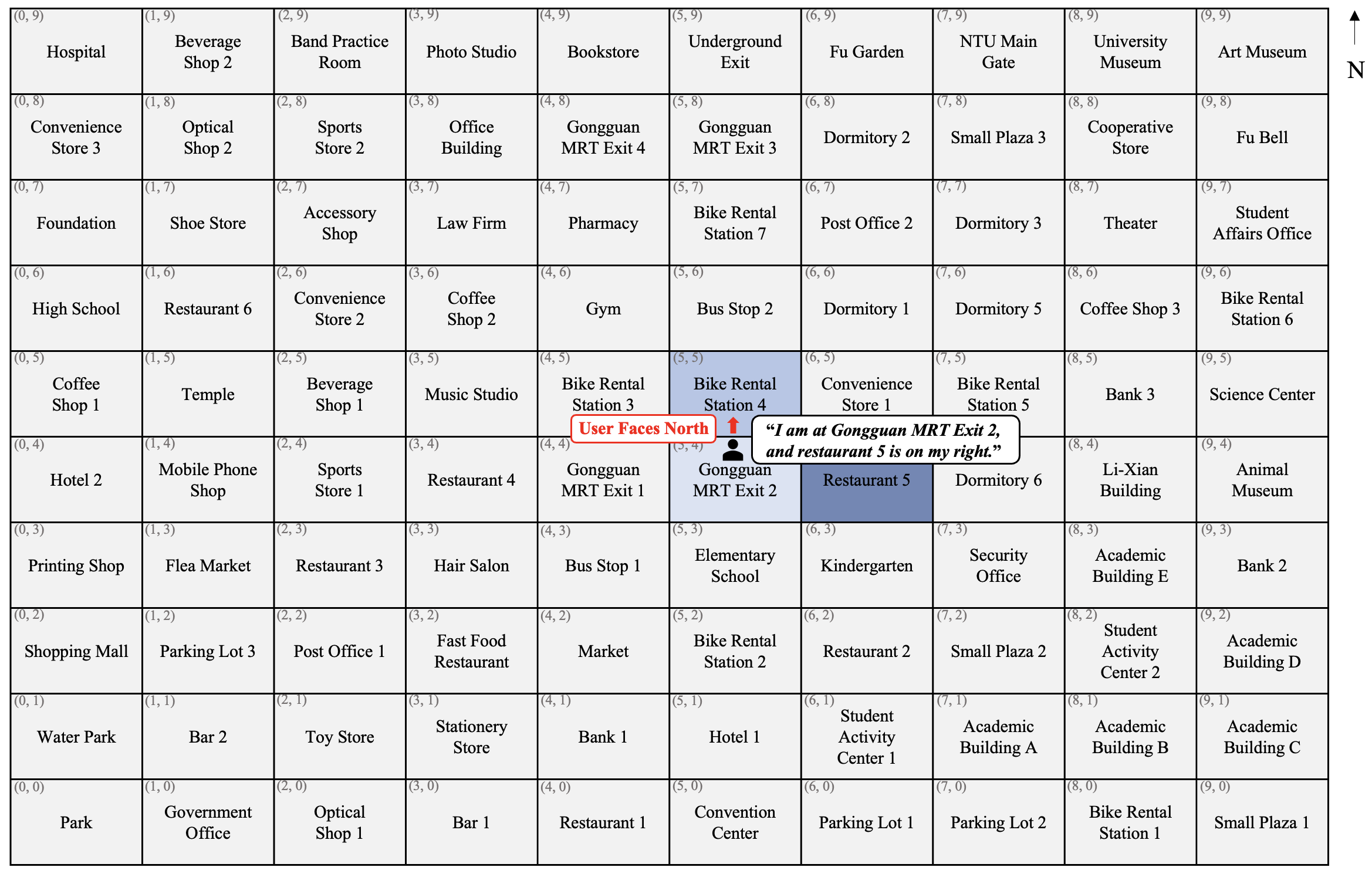
Figure 2: Task environment. Gongguan MRT area projected into a 10 × 10 grid map for testing.
Empirical Evaluation
Extensive experiments demonstrate the efficacy of the MCoT framework. The structured reasoning process achieves 100% accuracy on clean text and 98.1% on ASR transcripts, showing significant improvement over unimodal and non-structured baselines. The curriculum learning strategy progressively enhances orientation reasoning capabilities, contributing to robustness against linguistic variation, domain shift, and referential ambiguity.
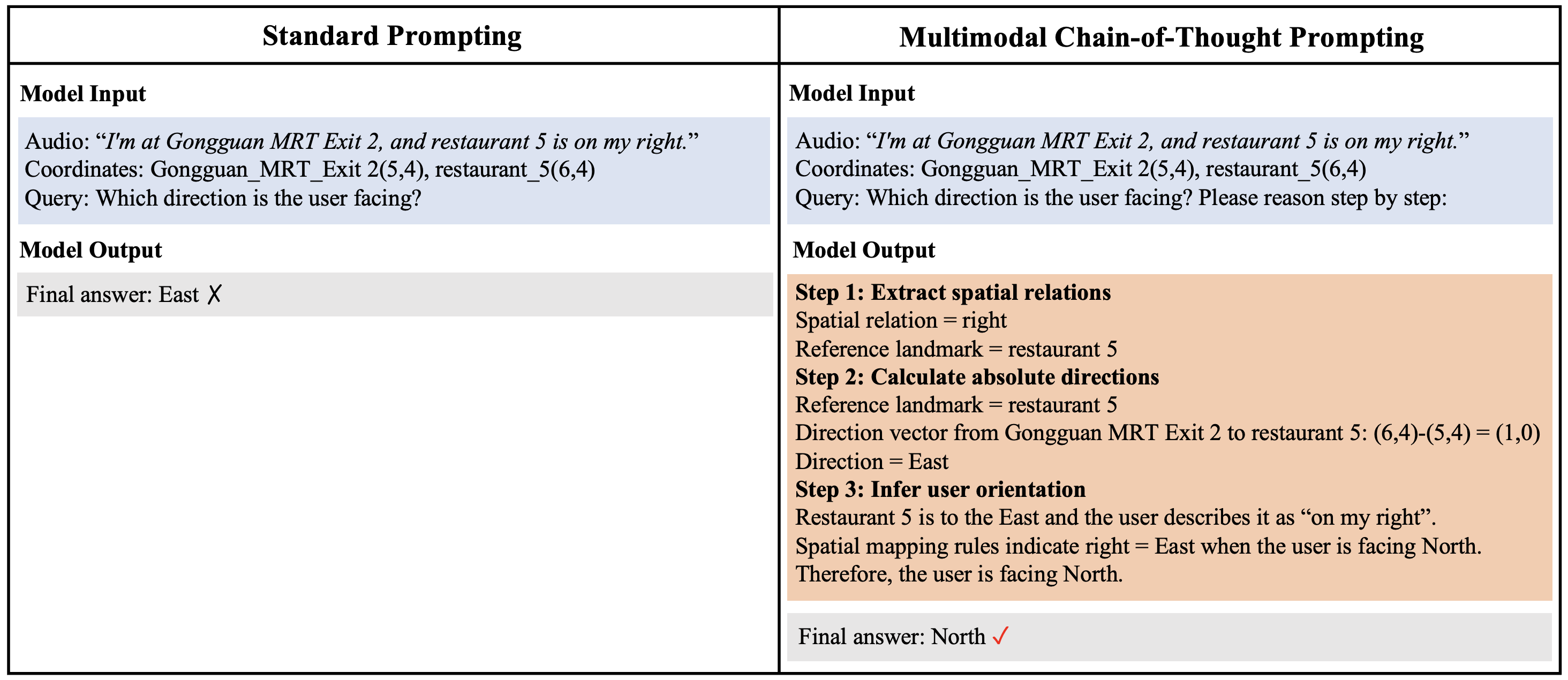
Figure 3: Comparison of standard prompting and MCoT. Standard prompting fails under ambiguous egocentric descriptions, whereas MCoT uses structured steps for better accuracy and interpretability.
Ablation Studies and Robustness
Ablation studies reveal the importance of spatial coordinates and structured CoT reasoning, each contributing to improved accuracy and reduced format errors when ASR noise is introduced. Moreover, the model generalizes well across linguistic variations and new spatial domains while maintaining high accuracy in referentially ambiguous contexts.
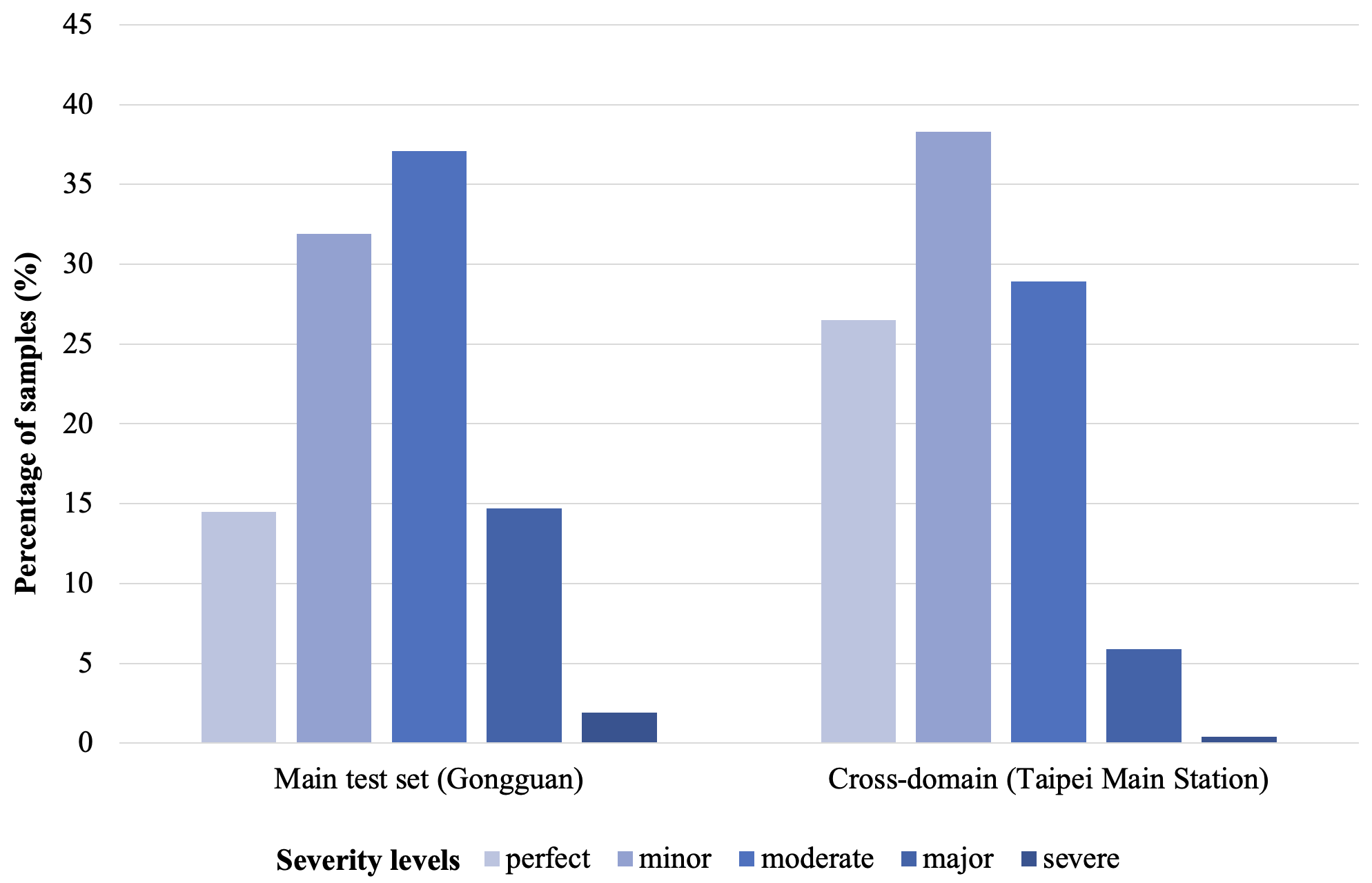
Figure 4: ASR error severity distribution in the two evaluation sets.
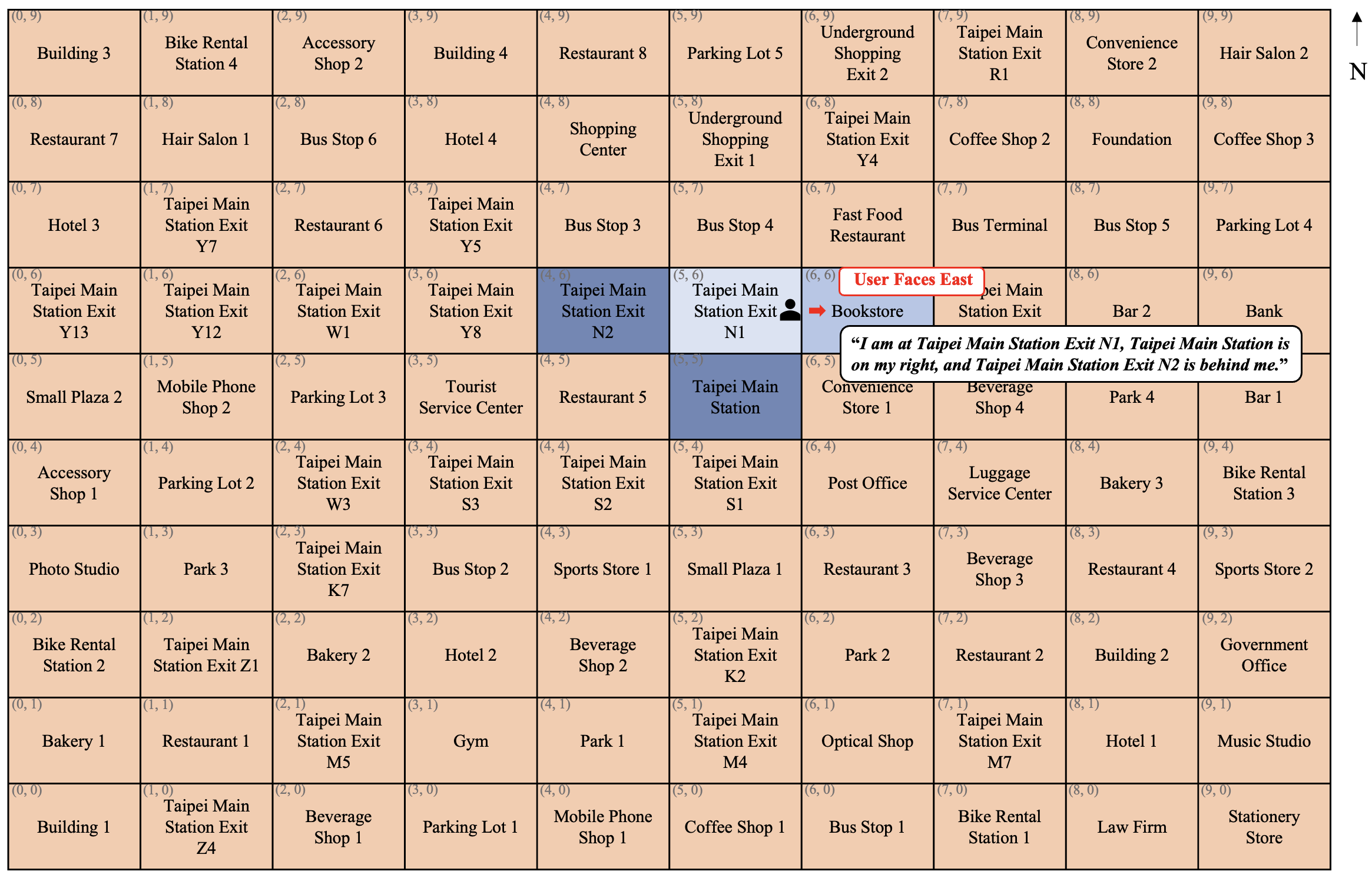
Figure 5: Cross-domain evaluation environment. Taipei Station area projected into a 10 × 10 grid.
Error Analysis
Error analysis identifies residual errors primarily in direction understanding and ASR misrecognition. Representative error cases illustrate challenges in correctly applying spatial mapping rules and extracting spatial relations from noisy ASR inputs.

Figure 6: Representative error cases falling into three categories: direction understanding errors, relation extraction errors, and ASR misrecognition errors.
Conclusion
The paper presents a comprehensive framework that enhances conversational navigation through structured reasoning, achieving high accuracy and robustness across diverse scenarios. Despite the promising results, limitations exist, including the grid-based environment and reliance on synthesized speech data. Future work may explore larger continuous spaces, multilingual contexts, and integration of additional sensory data, such as visual cues, for further advancements in embodied navigation systems.