- The paper introduces a reinforcement learning framework for MEV extraction on Polygon, proving its superiority over static bidding strategies.
- It employs a PPO-based bidding agent and continuous action space to adaptively simulate market and auction dynamics in the Polygon Atlas system.
- Empirical validation shows history-conditioned agents capturing up to 81% of potential profits, highlighting the framework's practical industrial benefits.
This paper addresses the strategic intricacies of Maximal Extractable Value (MEV) in Polygon blockchain networks, shifting focus from traditional gas bidding wars to structured sealed-bid auctions enabled by the Polygon Atlas system. It articulately advances the potential of Reinforcement Learning (RL) in enhancing competitive bidding strategies under extreme transactional constraints.
Blockchain transactions have evolved into complex, competitive financial activities where the order and timing of transaction executions lead to significant profit opportunities, known as MEV. Polygon, as a prominent Layer-2 solution, accommodates decentralized finance ecosystems that catalyze fleeting arbitrage opportunities across decentralized exchanges (DEXs). The Polygon Atlas upgrade further streamlined MEV extraction into efficient sealed-bid auction mechanisms, challenging traditional game-theoretic approaches and highlighting inadequacies in static optimization methods.
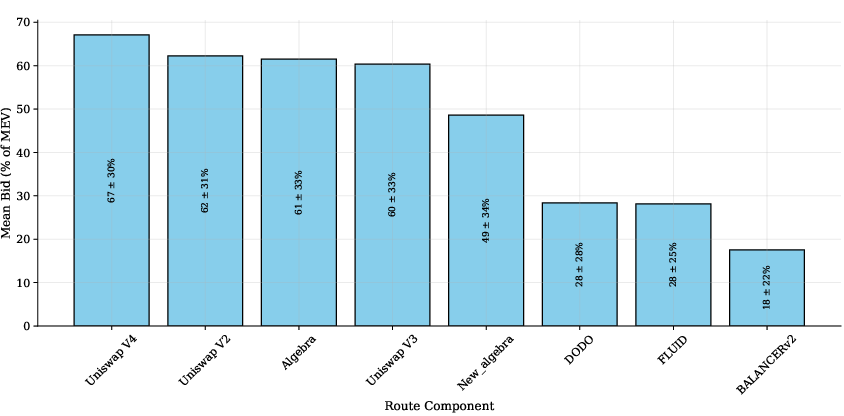
MEV Dynamics: MEV comprises the economic gains from strategic transaction ordering, predominantly through atomic arbitrage (AA), where price discrepancies across DEXs are exploited for risk-free profits. However, AA depends heavily on timely transaction placement within blocks, creating intense competition among searchers.
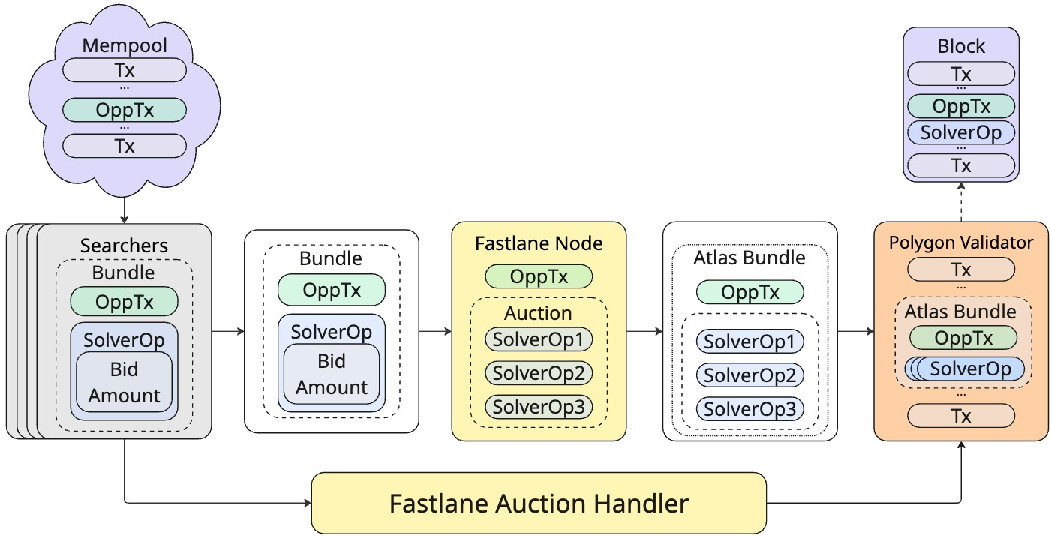
Figure 1: Empirical transaction execution flow observed in the Polygon Atlas network.
Reinforcement Learning Framework
Addressing the complex bidding environment of Polygon Atlas, the paper introduces a robust RL framework tailored to Polygon's FastLane auction mechanism. It leverages a Proximal Policy Optimization (PPO) approach within partially observable environments, simulating stochastic arbitrage arrival and opponent behaviors.
Framework Components:
- Simulation Framework: Details stochastic arrival and probabilistic competition modeling within Atlas auctions.
- PPO-based Bidding Agent: Employing adaptive strategy formulation under production constraints, aimed at efficient real-time bidding in continuous action spaces.
- Empirical Validation: History-conditioned agents significantly outperform traditional bidding approaches by achieving up to 81% of available profits, a testament to the advantage RL provides in such intricate environments.
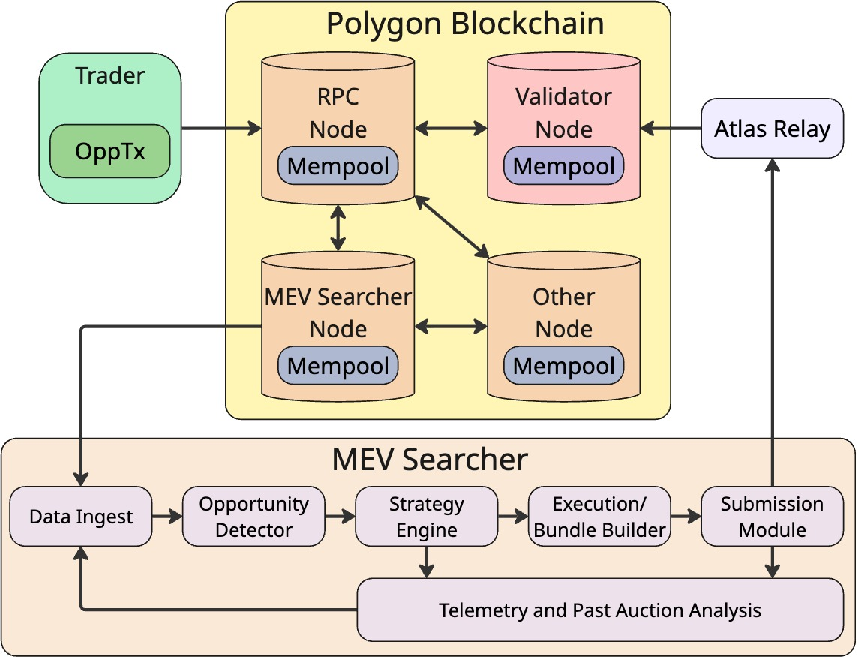
Figure 2: End-to-end architecture of a professional Polygon MEV searcher system, illustrating data ingestion, opportunity detection, strategy formulation, execution pipeline, and sealed-bid submission mechanics.
Methodological Contributions
The RL framework encapsulates essential components for simulating and deploying MEV strategies:
- State Representation: Combining immediate transaction characteristics and evolving market context into structured feature vectors.
- Action Space: Continuous bribe fractions enable finer strategic adaptation.
- Reward Function: Incorporates factors like overbidding penalties to maintain balance between risk and competitive engagement.
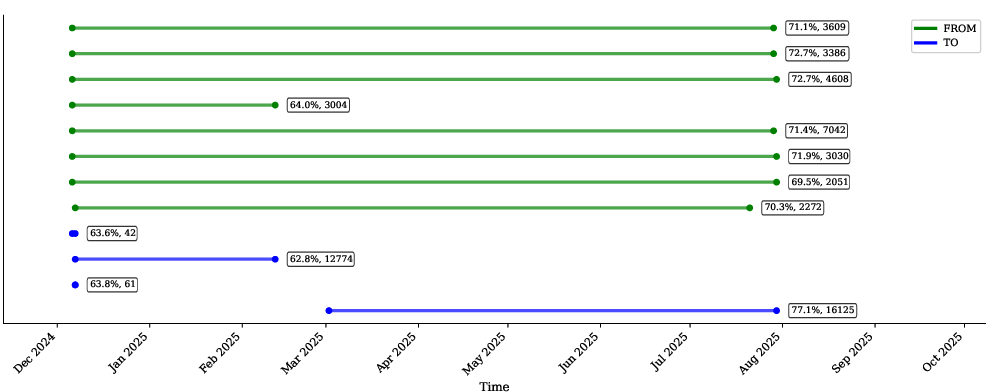
Figure 3: Temporal activity patterns of a professional searcher's addresses, showing parallel bot deployment, operational timeline, and bid escalation patterns. Address annotations indicate mean bribe percentage and participation count.
Industrial Implications
The framework’s deployment reflects on various industrial realities:
Experiments and Results
The paper rigorously evaluates this RL approach against traditional methods, employing both historical participation and replacement scenarios to measure effectiveness. The RL agent consistently demonstrates higher profit captures and strategic bidding efficiencies across both experimental setups.
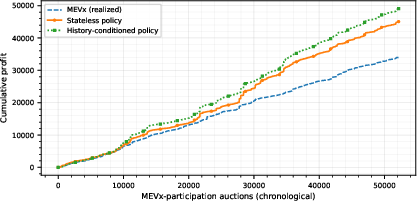
Figure 5: Cumulative profit comparison on test set, demonstrating the consistent superiority of history-conditioned bidding strategies across the evaluation period.
Conclusion and Future Directions
This research underscores RL’s applicability in optimizing MEV extraction under Polygon's complex auction structure, forecasted to spur future studies into mechanism refinements and cross-chain arbitrage strategy development. The findings offer substantial value implications for protocol designers and industrial blockchain participants, emphasizing adaptive strategic models in dynamic, high-frequency transaction environments.