Quantifying Memory Use in Reinforcement Learning with Temporal Range
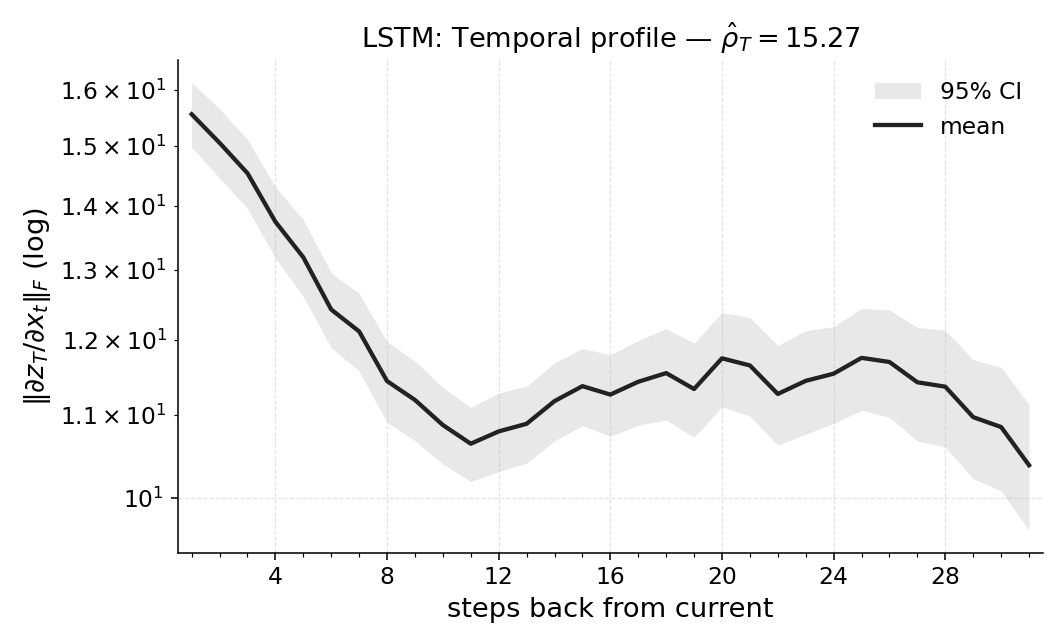
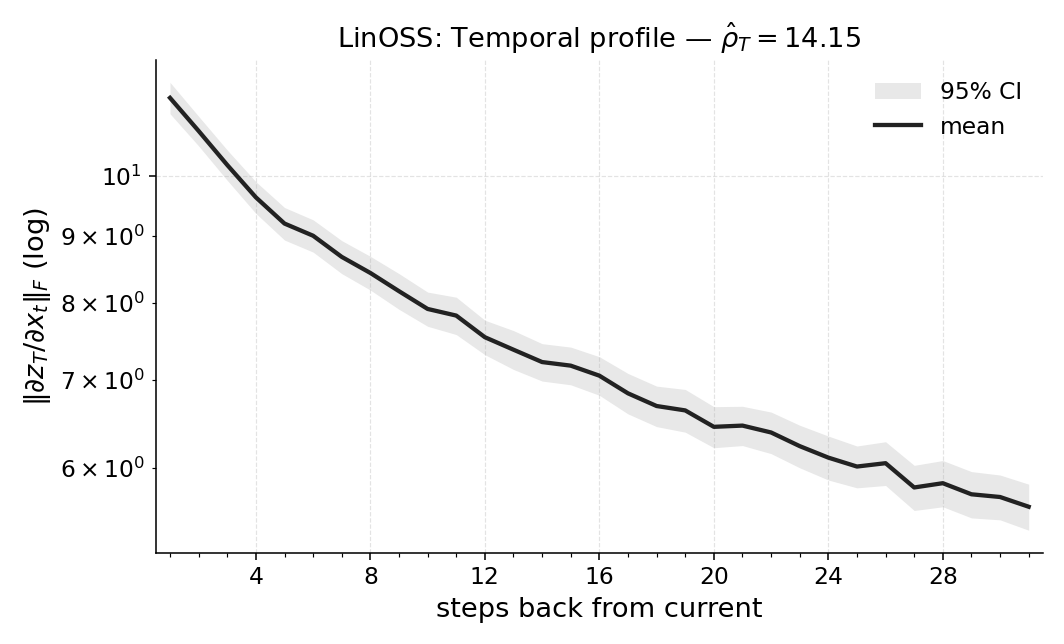
Abstract: How much does a trained RL policy actually use its past observations? We propose \emph{Temporal Range}, a model-agnostic metric that treats first-order sensitivities of multiple vector outputs across a temporal window to the input sequence as a temporal influence profile and summarizes it by the magnitude-weighted average lag. Temporal Range is computed via reverse-mode automatic differentiation from the Jacobian blocks $\partial y_s/\partial x_t\in\mathbb{R}{c\times d}$ averaged over final timesteps $s\in{t+1,\dots,T}$ and is well-characterized in the linear setting by a small set of natural axioms. Across diagnostic and control tasks (POPGym; flicker/occlusion; Copy-$k$) and architectures (MLPs, RNNs, SSMs), Temporal Range (i) remains small in fully observed control, (ii) scales with the task's ground-truth lag in Copy-$k$, and (iii) aligns with the minimum history window required for near-optimal return as confirmed by window ablations. We also report Temporal Range for a compact Long Expressive Memory (LEM) policy trained on the task, using it as a proxy readout of task-level memory. Our axiomatic treatment draws on recent work on range measures, specialized here to temporal lag and extended to vector-valued outputs in the RL setting. Temporal Range thus offers a practical per-sequence readout of memory dependence for comparing agents and environments and for selecting the shortest sufficient context.
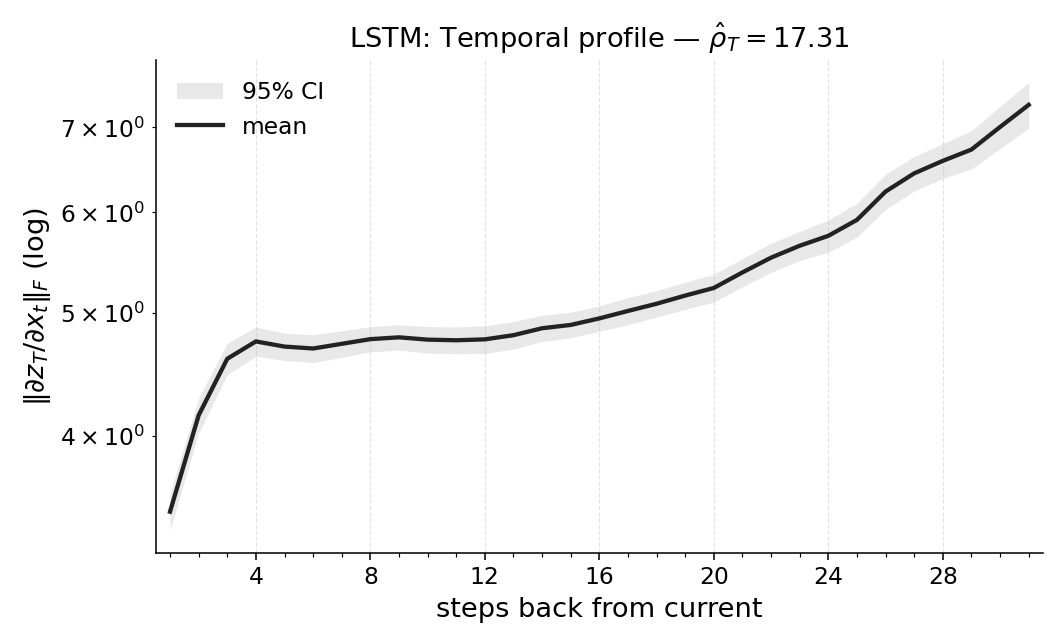
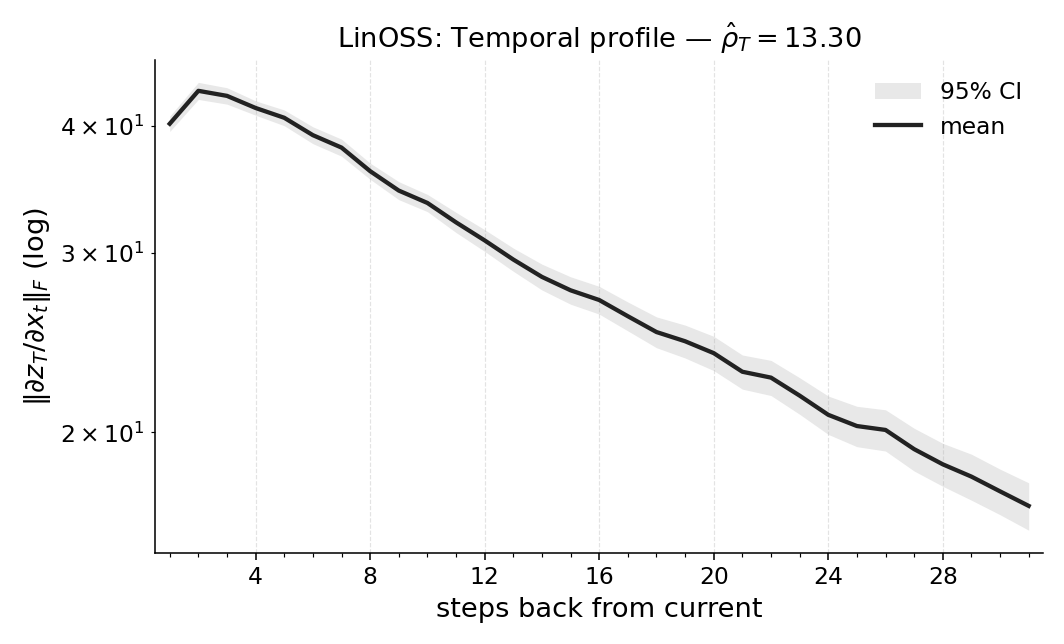
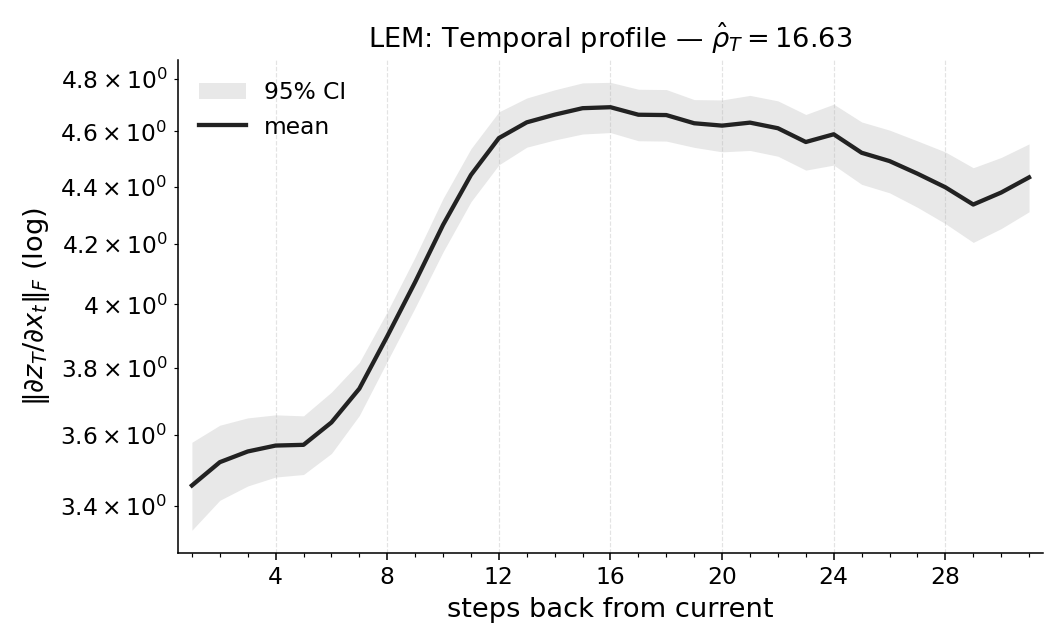
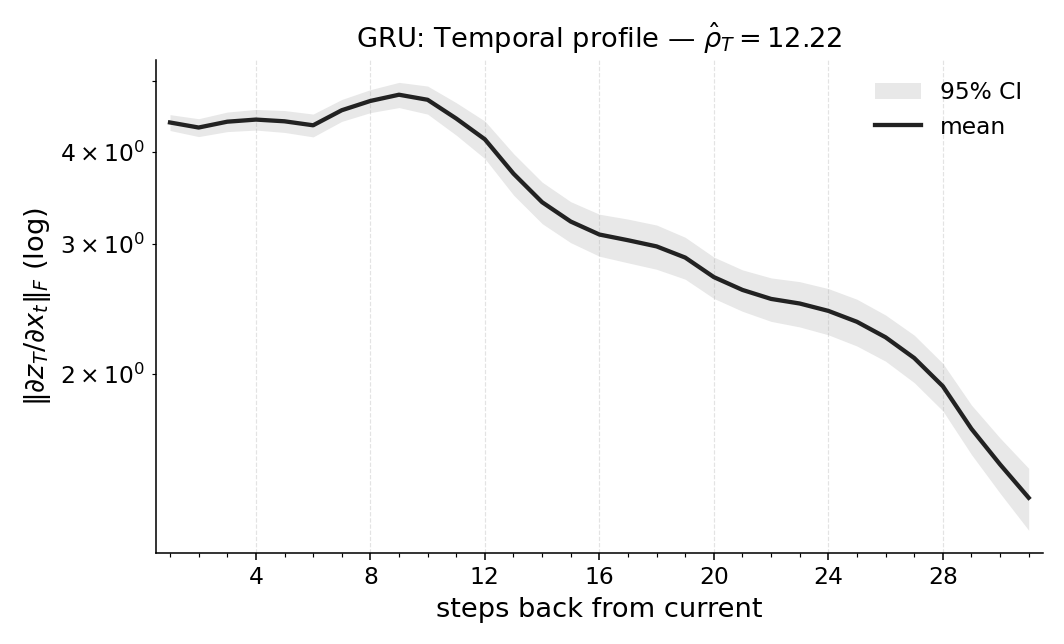
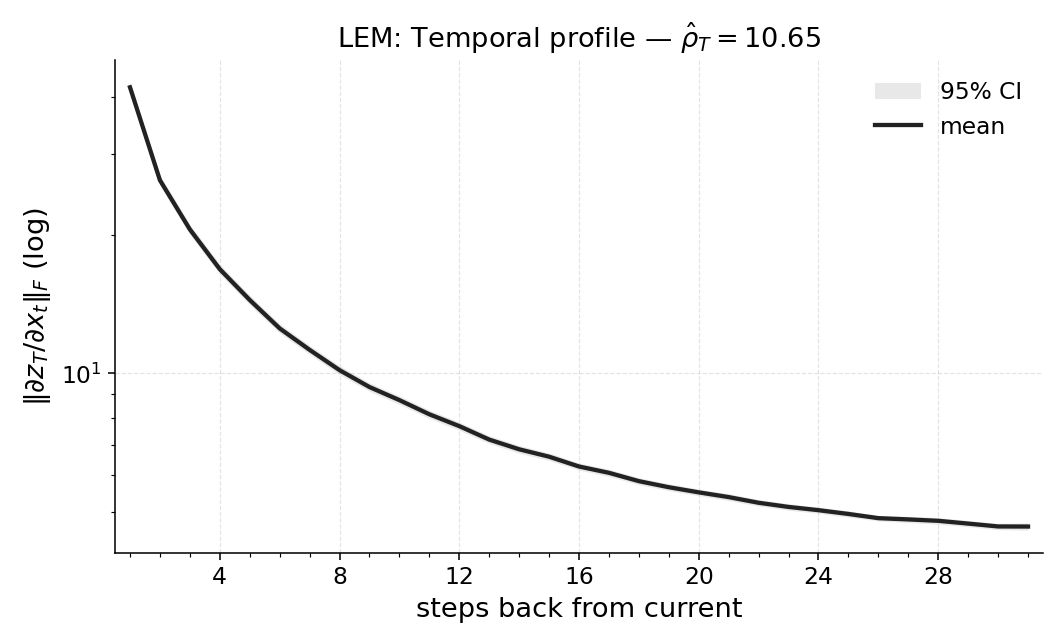
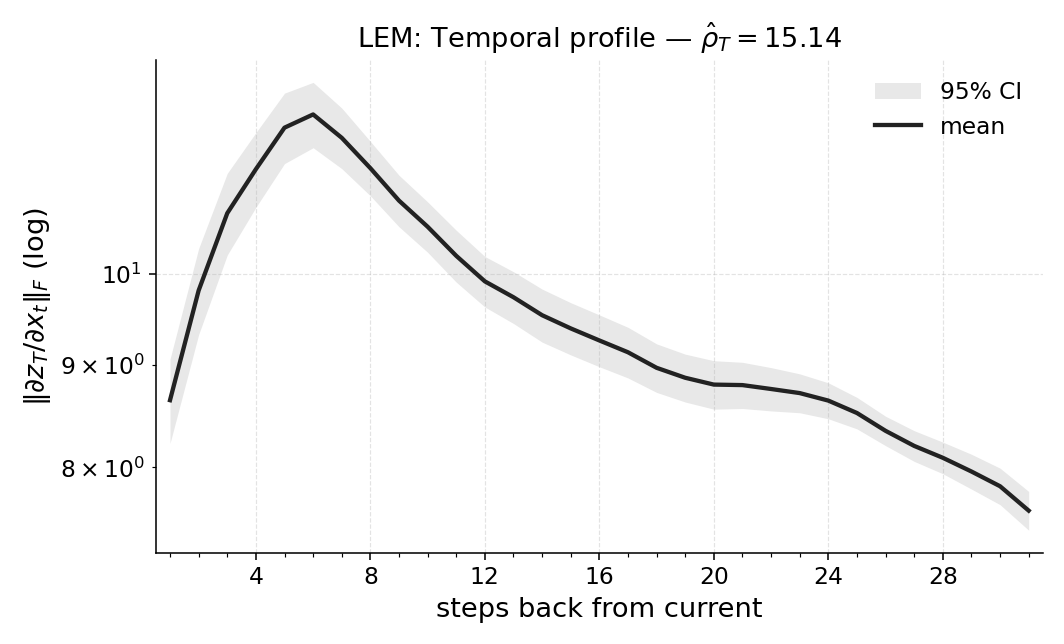
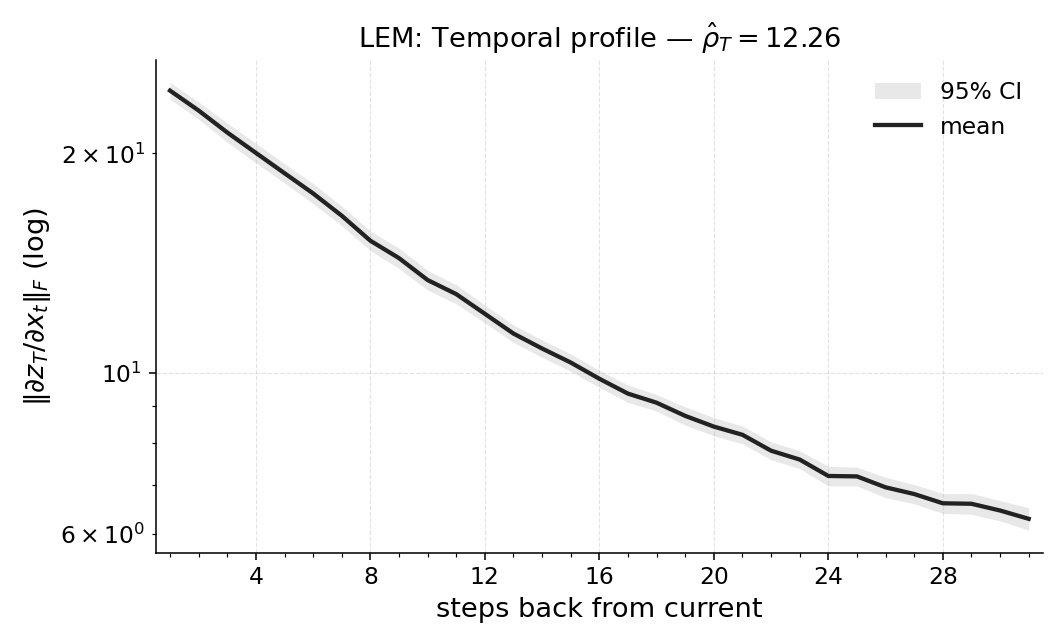
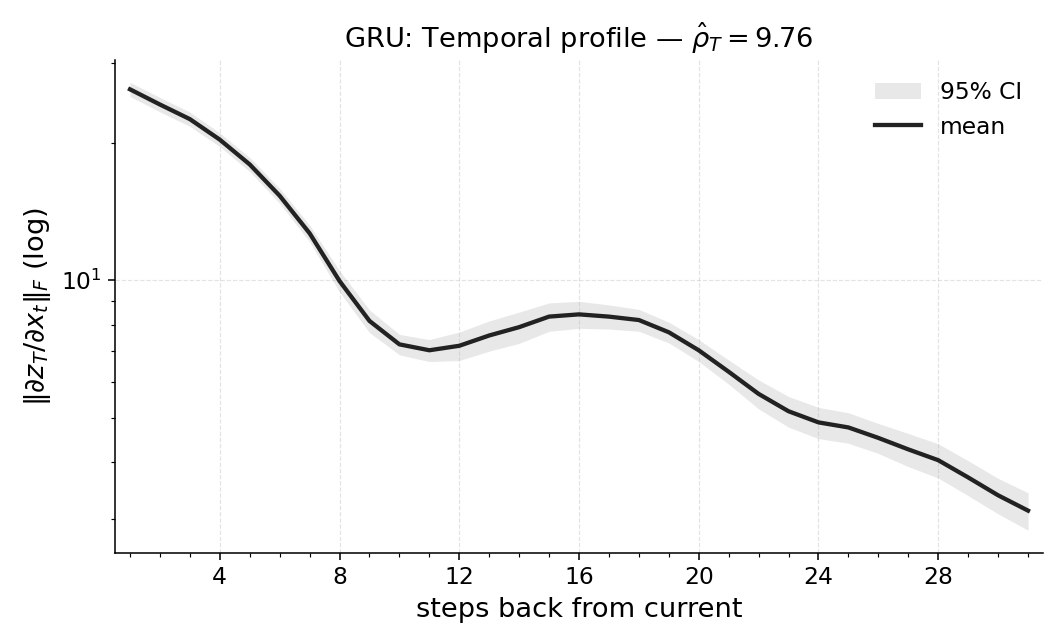
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Quantifying Memory Use in Reinforcement Learning with Temporal Range — A Simple Explanation
What is this paper about?
This paper asks a straightforward question: when a trained robot or game-playing AI makes a decision, how much does it actually use its memory of past observations? The authors introduce a simple number, called Temporal Range, that tells you “how far back in time” the AI is looking when it chooses an action.
What questions are they asking?
In kid-friendly terms, the paper explores:
- Can we measure how many steps back an AI “remembers” when making choices?
- Does this memory use match what the task truly needs (for example, remembering something from exactly 5 steps ago)?
- Can we compare different AI models fairly using one number?
- Can this number help us pick the shortest history window that still lets the AI play well?
How do they measure “how much a model remembers”?
Think of the AI watching a video of the world, frame by frame, and choosing what to do at each moment. To measure memory, they do something like this:
- Sensitivity as influence: For each earlier frame (past observation), they ask, “If we nudge this frame a tiny bit, how much would it change the AI’s future decision?” If a small change in an old frame causes a big change in a later action, that old frame is important.
- Turning sensitivities into a profile: They calculate these “nudges” for all earlier steps and all later decisions, then summarize how much each past step matters. This creates a temporal influence profile (like a chart showing which past steps matter most).
- A single number: They compress that profile into one number called Temporal Range by taking a magnitude-weighted average of “how many steps back” the important information is. If most influence comes from recent steps, the number is small; if influence comes from far back, the number is larger.
A helpful analogy:
- Imagine you’re answering a test question while flipping through your notes. Temporal Range measures how many pages back you actually look on average to answer correctly—recent pages or way back.
Some simple terms for the technical bits:
- “Sensitivity” (they use derivatives/Jacobians) = how much a small change in an input changes the output. You can think of it like how turning a volume knob a little raises or lowers the sound.
- “Matrix norm” = a way to measure the size of that change. Like saying “how big” the effect is.
- “Reverse-mode automatic differentiation” = a fast, built-in calculator that asks the model, “Which inputs made you decide this?” It works behind the scenes in many AI tools.
The authors also show this measure follows fair, common-sense rules:
- If you change the units (like meters to centimeters), the average look-back shouldn’t change.
- If two independent time chunks affect the decision, their influences should add up sensibly.
- The “average steps back” is uniquely determined by these fairness rules.
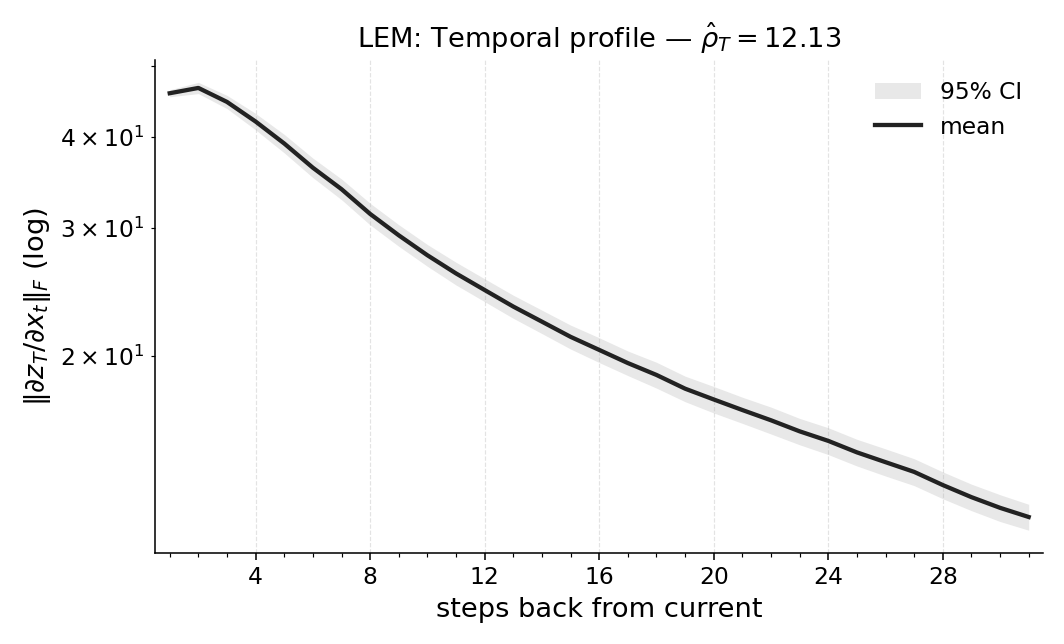
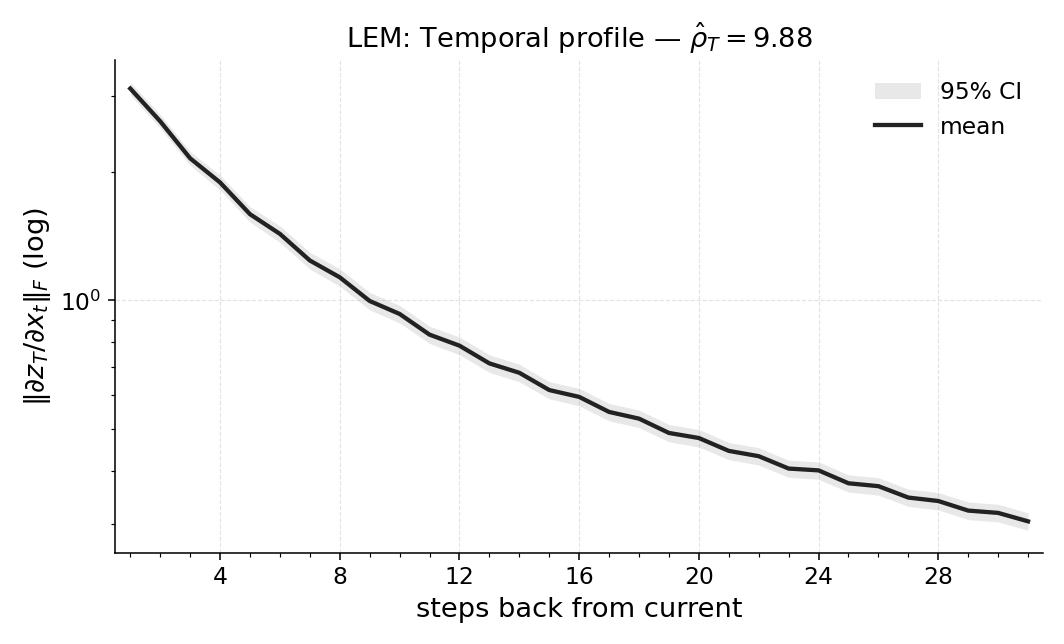
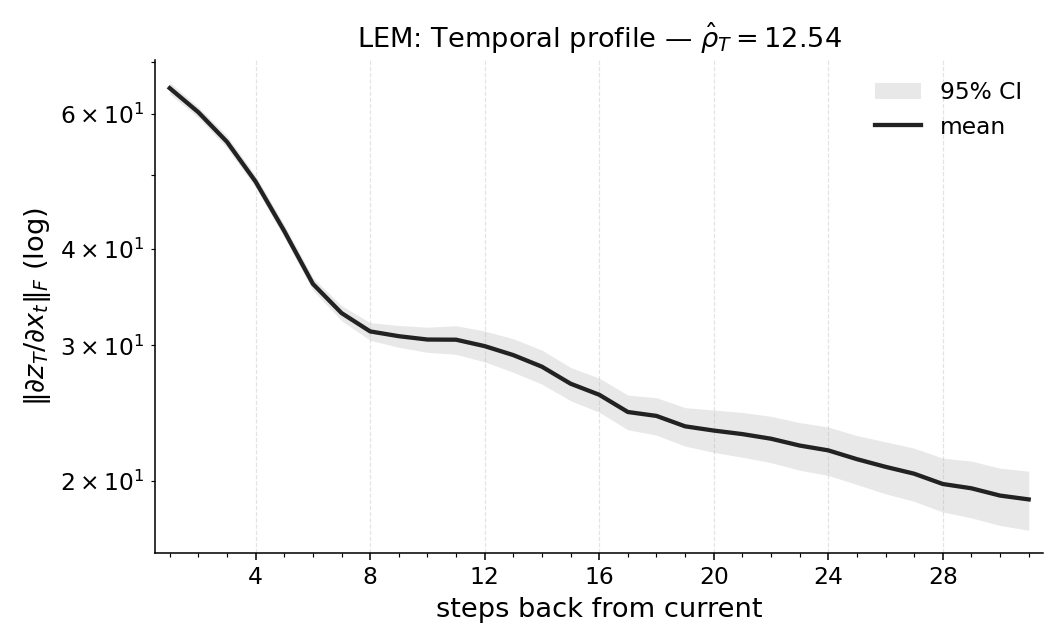
If the original model is hard to analyze (for example, it doesn’t allow gradients), they train a small, friendly model called LEM (Long Expressive Memory) on the same task and compute Temporal Range on that model as a proxy.
What did they test and find?
They tested different AI architectures (like GRUs, LSTMs, State-Space Models, and LEM) on several tasks, including:
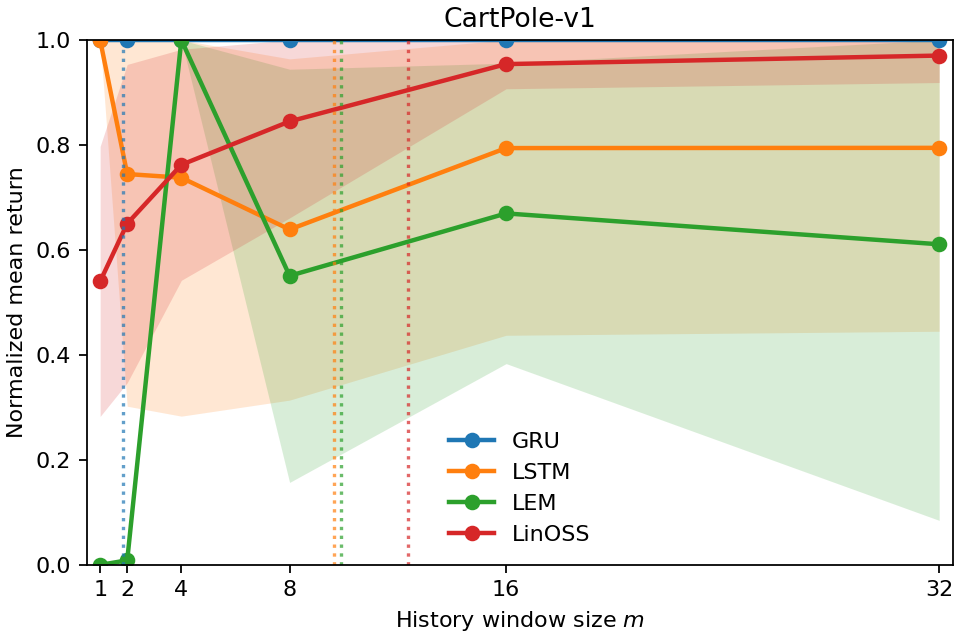
- Fully observed control (like CartPole), where you can mostly decide using the current observation (little memory needed).
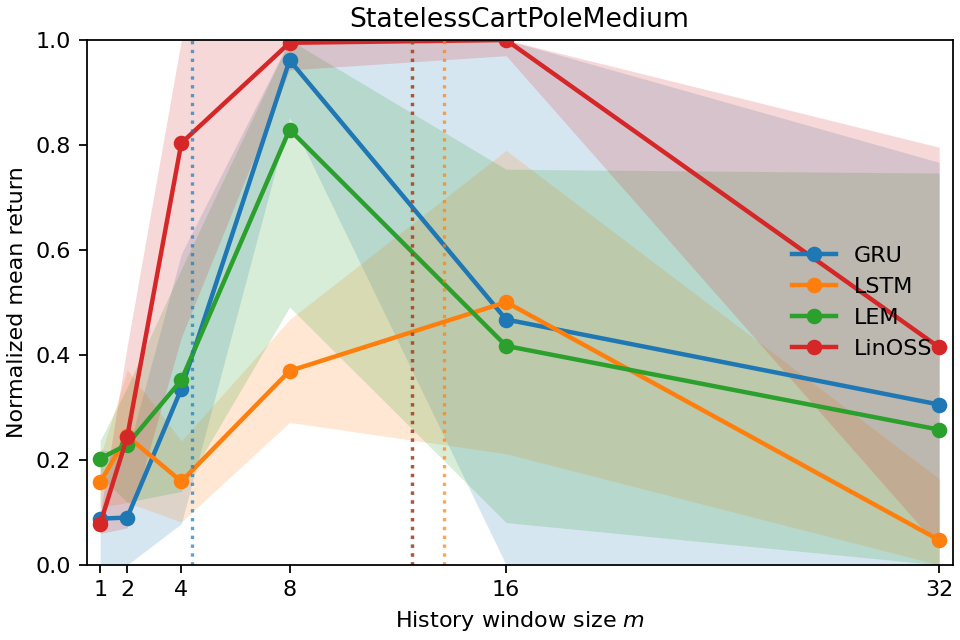
- Partially observed or noisy versions of those tasks, where you must remember the past to fill in missing information.
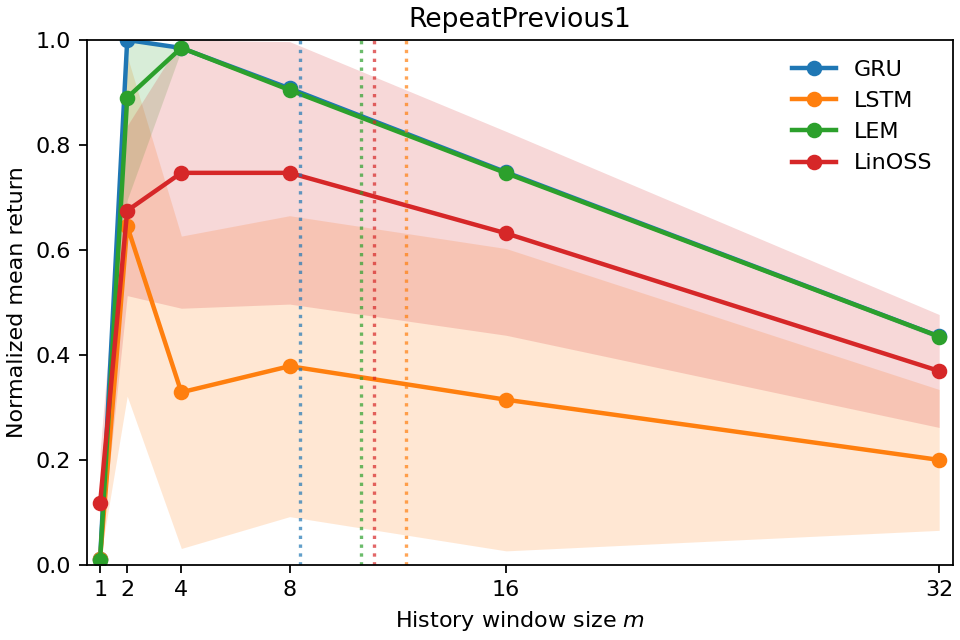
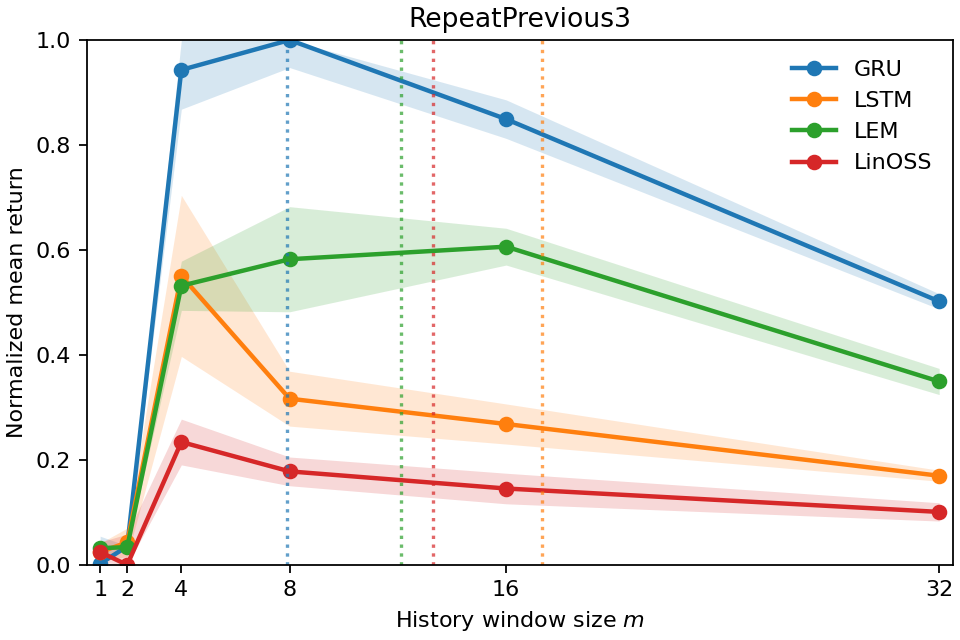
- Copy-k tasks, where the correct action is to repeat what happened exactly k steps ago (so the true memory need is known).
Here are the main takeaways:
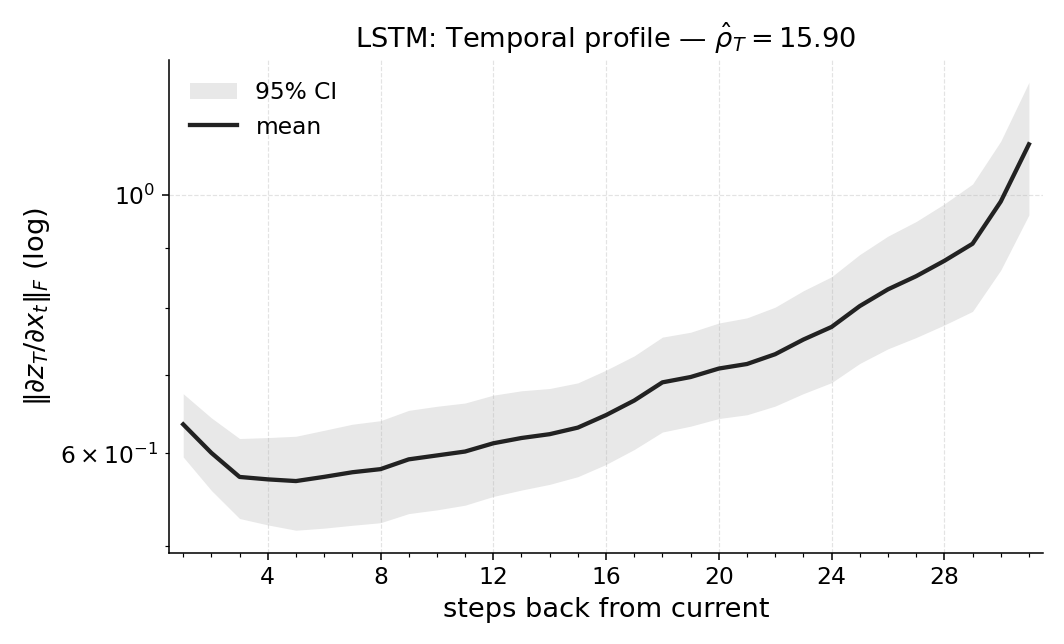
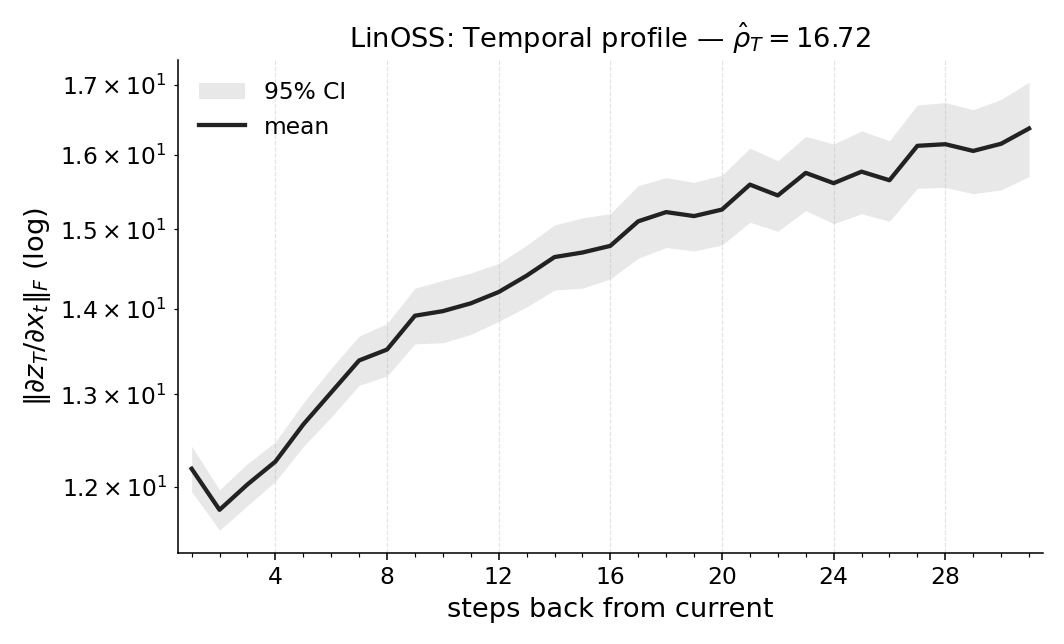
- In tasks that don’t really need memory (fully observed control), Temporal Range is small. That means the models mostly use recent information, as expected.
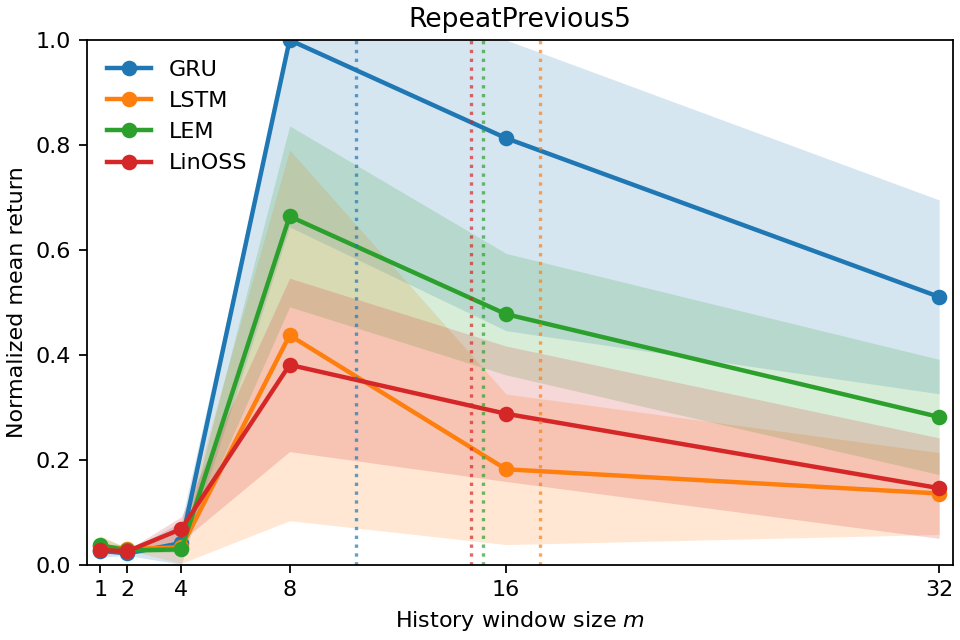
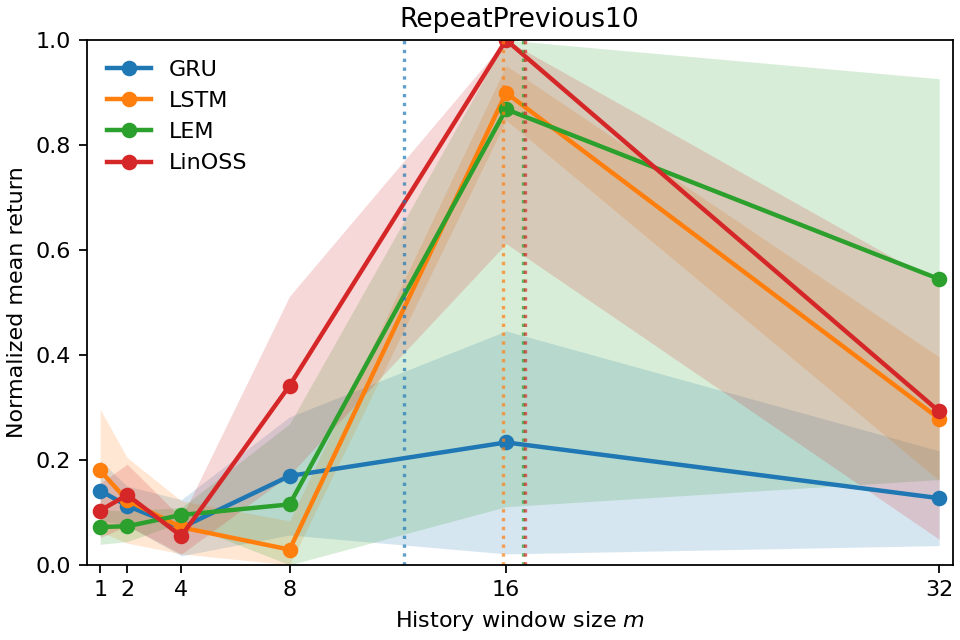
- In Copy-k tasks, the measured Temporal Range grows with k. If you must remember something from 10 steps ago, the number lands near 10. That shows the metric is accurate and meaningful.
- The number also matches how much history you actually need to keep to perform well. When they limited the models to only the last m steps (a “window ablation”), performance bounced back around when m was about the Temporal Range. In other words, the metric correctly predicts the shortest history window that’s enough.
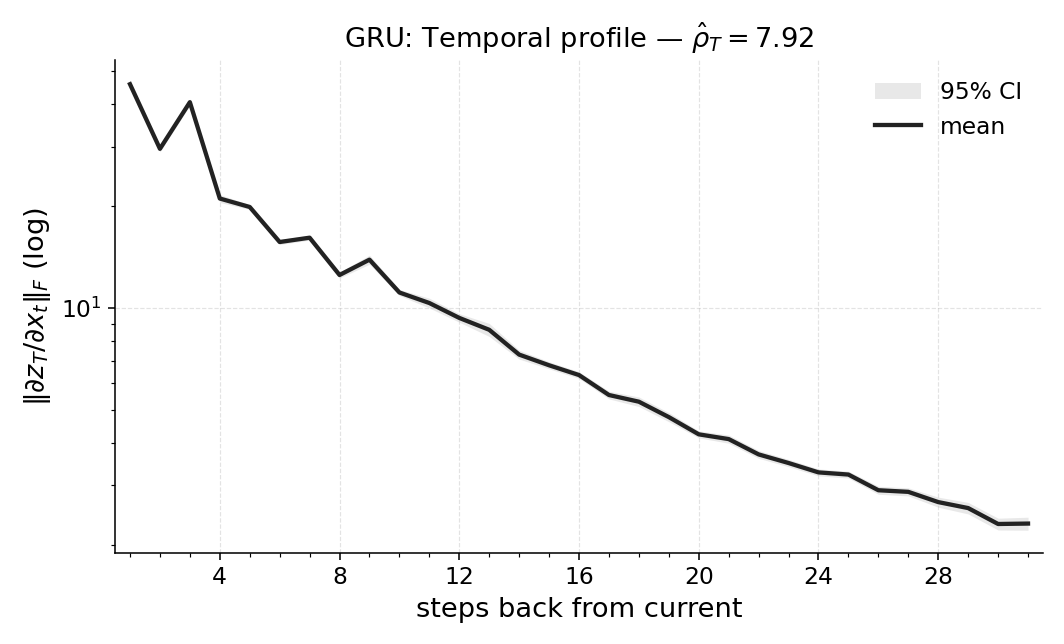
- Different models use memory differently. For example, some models keep longer “tails” of memory even when they don’t need to. Temporal Range reveals these differences in a clean, comparable way.
To make these points concrete, here’s a short list of why the results matter:
- The metric is small when it should be small (easy tasks with full information).
- It scales exactly with real memory needs (Copy-k).
- It predicts the minimum history window you need to keep performance high (confirmed by experiments).
- It works across many model types and tasks, giving a fair, apples-to-apples comparison.
Why does this matter?
- Designing simpler systems: If the model’s Temporal Range is short, you can safely use smaller memory windows or simpler architectures. That saves compute and memory.
- Diagnosing problems: If a task needs memory but the measured range is small, your model might be underusing memory. You might need a better architecture or training setup.
- Avoiding waste: If a task is simple but the model uses long-range memory, you might be able to simplify the model for faster, more efficient deployment.
- Planning deployment: Temporal Range gives a practical way to choose the shortest “context window” to store and update during inference, which is useful in real-world, memory-limited settings.
In short
The paper introduces Temporal Range, a simple, trustworthy number that tells you how far back an AI policy looks when it acts. It’s easy to compute, fair to compare across models and tasks, and it lines up with what tasks truly require. This helps researchers and engineers build models that are just the right size, use memory wisely, and perform efficiently.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues and concrete open questions that future work could address.
- Empirical scope: Validate Temporal Range (TR) on high-dimensional, long-horizon, and vision-based RL (e.g., Atari, DMControl, MuJoCo) where c×d Jacobians are large and computing all J_{s,t} may be expensive; report runtime/memory profiles and scalability limits.
- Computational scaling: Provide algorithms for efficient TR estimation at large T (e.g., exploiting Jacobian–vector products, low-rank approximations, or sampling of s,t pairs), and quantify accuracy–efficiency trade-offs.
- Window length selection: Develop procedures to choose window length T adaptively; analyze bias when true memory exceeds T and establish diagnostics for underestimation.
- Aggregation design: Systematically study how the choice of matrix norm (Frobenius vs. operator norms) and aggregation operator (mean vs. max vs. weighted schemes) affects TR values and task-level conclusions; provide guidance or principled defaults.
- Local linearization limitations: Quantify how nonlinearity (activation saturation, gating, attention) and gradient pathologies (dead ReLUs, exploding/vanishing gradients) bias first-order TR; evaluate second-order or path-integrated variants as robustness checks.
- Causal validity: Distinguish correlation from necessity—do large TR values reflect required memory? Compare evaluation-only window ablations with retraining under constrained contexts to avoid distribution-shift confounds and provide causal evidence.
- Proxy fidelity: When using LEM as a proxy for non-differentiable policies, measure the approximation error between proxy TR and the true policy’s TR; characterize when proxy estimates are reliable and provide quantitative bounds or diagnostics.
- Time-resolved analysis: Extend TR from a single scalar per window to per-step TR(·, s), analyzing temporal variability across decisions; propose summaries (e.g., distributions or percentiles) and assess stability.
- Policy vs. value heads: Systematically measure TR for both action and value outputs across tasks; quantify relationships to credit-assignment hyperparameters (e.g., GAE λ, TD horizons) and derive tuning recommendations.
- Stochastic policies: Investigate whether TR computed on logits reflects actual memory use under sampling; study sensitivity to exploration noise (temperature, entropy regularization) and discrete-action selection effects.
- Input preprocessing: Beyond uniform scaling invariance, analyze TR sensitivity to feature-wise normalization, whitening, and channel-wise rescaling; establish invariance or correction schemes for non-uniform input transformations.
- Invariance properties: Evaluate whether TR is invariant (or how it changes) under orthogonal reparameterizations, input-channel permutations, or output-head remappings; formalize desired invariances and test them empirically.
- Noise and observability: Map TR as a function of noise level and partial observability parameters (SNR curves); determine whether TR growth tracks information-theoretic demands versus model-induced smoothing.
- Slow modes vs. useful memory: Develop criteria or regularizers to separate task-relevant long-range dependence from architecture-induced slow modes that inflate TR without return gains; validate on controlled benchmarks.
- Confidence estimates: Provide statistical uncertainty for TR (e.g., confidence intervals over episodes/rollouts), sample-size guidelines for calibration sets, and tests for episode-dependent variability.
- Benchmark breadth: Extend evaluation to multi-agent and decentralized POMDPs; measure per-agent TR and study effects of communication, belief sharing, and coordination on effective memory.
- Attention and external memory: Adapt TR to Transformer-style policies and external memory mechanisms (buffers, differentiable memory); define appropriate Jacobian blocks and aggregation for attention weights and memory reads/writes.
- Comparison to alternatives: Conduct head-to-head comparisons with effective context length, predictive-state representations, mutual-information–based measures, influence functions, and integrated gradients; identify regimes where TR is preferable or complementary.
- Training dynamics: Track TR over training to study how memory use evolves; test whether changes in TR predict performance improvements or overfitting, and whether TR can guide early stopping or curriculum design.
- Hyperparameter sensitivity: Quantify how PPO/GAE settings, truncation length in BPTT, recurrent/SSM cell sizes, and regularization affect TR independently of environment; provide tuning heuristics to align TR with task demands.
- Theory for nonlinear case: Extend axiomatic guarantees (uniqueness, stability) beyond linear maps; derive bounds linking TR to minimal sufficient context under smoothness assumptions and curvature constraints.
- Deployment policies: Explore adaptive, TR-guided context selection at inference (online window sizing) and architecture search; test whether TR can reduce memory/compute while maintaining performance in real-time systems.
- Real-world validation: Apply TR to robotics tasks with delays, occlusions, and non-stationarity; assess robustness under domain shifts and drifting environments, and test dynamic TR tracking to handle non-stationary memory demands.
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed with the paper’s current method and code. Each item lists sector(s), potential tools/workflows, and key assumptions/dependencies.
- Memory auditing of trained RL policies
- Sectors: robotics, autonomous driving, industrial automation, games/simulation, software infrastructure for RL.
- What: Use Temporal Range (TR) to quantify how far back policies actually rely on history on a per-sequence basis; compare across agents/environments to detect unnecessary long memory (slow modes) or insufficient memory on POMDPs.
- Tools/workflows: “TR Analyzer” (JAX/PyTorch autograd), per-episode TR dashboards with temporal influence profiles; cross-run comparisons for architecture audits.
- Assumptions/dependencies: Access to policy gradients or a differentiable proxy; first-order local linearization captures salient dependencies; choice of matrix norm and aggregation operator.
- Context-window selection for memory-efficient deployment
- Sectors: edge robotics/drones, mobile on-device RL, cloud RL serving, games/ad-tech.
- What: Set the shortest sufficient observation buffer length as ceil(TR+1) to rebuild hidden state periodically (windowed evaluation) with high performance retention; reduce memory and compute.
- Tools/workflows: “ContextSizer” that sets deployment buffers from TR; CI step to re-benchmark retention when models update; ring-buffer allocation tuned to TR.
- Assumptions/dependencies: TR estimated on representative evaluation rollouts; validated with window ablations; distribution shift minimal when moving to windowed regime.
- Black-box policy auditing via a proxy (LEM)
- Sectors: defense/aerospace, vendors with proprietary controllers, regulated industries.
- What: Train a compact Long Expressive Memory (LEM) agent on the same task to approximate TR when the production policy blocks gradients; use as a proxy readout of task-level memory.
- Tools/workflows: “TR Proxy” (train LEM → compute TR); reporting pipelines where direct autograd is unavailable.
- Assumptions/dependencies: Proxy achieves competent task performance; proxy Jacobians correlate with task memory needs; calibration on multiple rollouts.
- Architecture selection and capacity sizing
- Sectors: software/ML platforms, robotics, autonomy stacks.
- What: Use TR to choose between RNN/SSM/Transformer and hidden sizes; prune models that exhibit long ranges on near-Markov tasks; select architectures that achieve necessary TR on POMDPs.
- Tools/workflows: “TR Compare” (model-family sweeps + TR summaries); early training checkpoints with TR to stop unpromising runs.
- Assumptions/dependencies: Comparable training/performance across candidates; normalized TR invariance supports cross-model comparisons.
- Training diagnostics for temporal credit assignment
- Sectors: all RL training pipelines.
- What: Compare TR of policy vs value heads; adjust GAE λ, n-step horizon, or bootstrapping schedule when critic range outpaces policy range (unstable advantages).
- Tools/workflows: TR-driven hyperparameter tuner for λ and n-step; training dashboard that plots TR gaps over time.
- Assumptions/dependencies: Reliable per-head Jacobians; metric stability across seeds.
- BPTT truncation, sequence-length, and replay-buffer sizing
- Sectors: software/ML platforms, offline/online RL systems.
- What: Set BPTT truncation length, sequence chunks, and replay buffer context to match TR; reduce waste and improve optimization stability.
- Tools/workflows: “TR-to-Train” scheduler that adapts BPTT length as TR evolves.
- Assumptions/dependencies: TR trends during training reflect emergent memory use; truncation does not materially harm convergence when ≥ TR.
- Environment/task benchmarking and dataset curation
- Sectors: academia/benchmarking, simulation vendors, curriculum learning platforms.
- What: Quantify task memory demand (e.g., POPGym, Copy-k) and align with intended difficulty; detect unintended long-range shortcuts or spurious dependencies.
- Tools/workflows: TR benchmark cards; task design loops where TR is a target property.
- Assumptions/dependencies: Evaluation rollouts cover diverse regimes; TR’s locality acknowledged when summarizing across episodes.
- Drift and robustness monitoring in production
- Sectors: finance (trading RL), recommender systems/ads, ops platforms.
- What: Monitor TR over time; increases signal rising partial observability, noisier sensors, or changing dynamics; trigger retraining or sensor fusion updates.
- Tools/workflows: “TR Monitor” with alerts on TR shifts; SLOs on memory footprint.
- Assumptions/dependencies: Stable estimation procedure; unit/temperature rescaling handled (normalized TR invariances).
- Privacy and data minimization in deployment
- Sectors: healthcare (clinical support RL), fintech, consumer personalization.
- What: Use TR to justify minimum rolling window retention for inference, satisfying data minimization principles (e.g., GDPR) while preserving performance.
- Tools/workflows: Compliance reports attaching TR evidence to data retention policies; window-ablation validation artifacts.
- Assumptions/dependencies: TR aligns with minimal sufficient context; repeated audits across cohorts.
- Multi-agent memory budgeting and comms policies
- Sectors: multi-robot systems, logistics, swarm coordination.
- What: Size local buffers and communication windows to match per-agent TR; avoid unnecessary latency/bandwidth for near-Markov roles.
- Tools/workflows: Per-agent TR profiling; communication policy rules tied to TR estimates.
- Assumptions/dependencies: Agent policies individually differentiable or proxied; TR jointly considered with comms constraints.
Long-Term Applications
These scenarios require additional research, scaling, or development (e.g., integrating TR into training objectives, standardization, new tooling).
- TR-regularized training objectives
- Sectors: robotics, industrial control, safety-critical autonomy.
- What: Add penalties that discourage unnecessary temporal range, biasing toward simpler, short-context controllers without reward loss.
- Tools/workflows: Differentiable TR surrogates or proxies included in loss; curriculum with gradually tightened TR constraints.
- Assumptions/dependencies: Smooth, stable surrogate for TR; avoiding performance regressions on truly long-memory tasks.
- Dynamic, TR-aware runtime memory controllers
- Sectors: embedded/on-device RL, autonomous driving, energy grid control.
- What: Adapt context windows online based on live TR estimates; allocate memory/compute elastically under resource limits.
- Tools/workflows: Firmware/runtime that queries TR periodically to resize buffers; admission control for memory bursts.
- Assumptions/dependencies: Low-overhead TR approximation at inference (e.g., periodic/proxy-based); stability under adaptation.
- TR-guided attention masking for sequence models
- Sectors: software/ML platforms, language-model–style RL (DT, ICL-RL).
- What: Use TR to prune attention to temporally distant tokens; reduce quadratic attention costs while preserving performance.
- Tools/workflows: Dynamic attention masks or sparse kernels parameterized by TR; hybrid learned-and-TR masks.
- Assumptions/dependencies: Mapping from TR (Jacobian-based) to attention sparsity robustly preserves behavior.
- Safety and standards: “Memory footprint” governance
- Sectors: regulators, aviation/medical devices, automotive.
- What: Include TR-based disclosures in safety cases; certify that controllers do not rely on long-lag information beyond validated ranges.
- Tools/workflows: TR compliance dashboards; third-party audits using LEM proxies for black-box systems.
- Assumptions/dependencies: Accepted methodology for TR estimation and variance reporting; agreement on thresholds per domain.
- TR-informed robust RL against temporal perturbations
- Sectors: cyber-physical systems, finance.
- What: Stress-test controllers at their estimated horizon (e.g., delayed/noisy past frames); design defenses targeted at vulnerable lags.
- Tools/workflows: Temporal attack simulators around TR; robust training pipelines that target lag-specific vulnerabilities.
- Assumptions/dependencies: Validity of TR as a proxy for vulnerability surface; integration with adversarial RL frameworks.
- Dataset and curriculum design with targeted memory demand
- Sectors: education/research, simulation providers.
- What: Build curricula where task TR increases over time; diagnose spurious long-range correlations in datasets.
- Tools/workflows: TR-driven task generators; automated “TR progression” curricula.
- Assumptions/dependencies: Reliable aggregation of local TR into task labels; transfer of curriculum gains to deployment tasks.
- TR-driven architecture search (NAS) for memory efficiency
- Sectors: ML platforms, OEMs for autonomy stacks.
- What: Incorporate TR constraints into search objectives to find minimal-memory models that meet performance targets.
- Tools/workflows: NAS with multi-objective (reward, latency, TR); SSM vs RNN vs Transformer search conditioned on target TR.
- Assumptions/dependencies: Fast TR proxies compatible with NAS loops; meaningful Pareto fronts.
- Policy/value head co-design
- Sectors: all RL pipelines.
- What: Jointly constrain policy and value ranges to stabilize advantage estimation; redesign critic architectures that match policy TR.
- Tools/workflows: TR-aware critic architectures; adaptive λ/n-step schedules governed by TR-gap.
- Assumptions/dependencies: Empirical link between TR-gap and instability; robust schedules for varied tasks.
- On-chip accelerators and compilers with TR hints
- Sectors: hardware for robotics/mobile AI.
- What: Compile-time allocation of temporal buffers and compute pipelines sized by TR; DMA schedules that favor short-context access.
- Tools/workflows: RL compiler extensions that ingest TR metadata; memory partitioners tuned to TR.
- Assumptions/dependencies: Stable TR across operating conditions; hardware-software co-design.
- Privacy/fairness governance guided by TR
- Sectors: healthcare, HR-tech, finance.
- What: Use TR to design data retention and forgetting policies; reduce reliance on stale or potentially biased long-range signals.
- Tools/workflows: TR-based retention policies; fairness audits that test outcome sensitivity to older windows beyond TR.
- Assumptions/dependencies: Verified relationship between shorter memory and reduced bias for target domain; domain-specific thresholds.
- Advanced methodology: time-resolved and per-output TR, causal checks
- Sectors: academia and applied research.
- What: Extend TR to per-output components (e.g., action dimensions), time-resolved profiles across episodes, and combine with causal interventions to strengthen attribution.
- Tools/workflows: TR+causal perturbation toolkits; integration with influence functions/Integrated Gradients.
- Assumptions/dependencies: Efficient estimators; standardized reporting for uncertainty and sensitivity to norm/aggregation choices.
Cross-cutting assumptions and dependencies
- Differentiability or access to a reliable proxy (LEM) to compute Jacobians.
- Locality: TR is a first-order, per-sequence measure; aggregate over representative episodes to generalize.
- Norm and aggregation choices (e.g., Frobenius, mean vs max) can shift estimates; fix and report them for comparability.
- Slow modes may inflate TR without improving return; pair TR with window ablations for validation.
- Evaluation conditions (noise, preprocessing, scaling) affect TR; use normalized TR to compare across rescalings.
Glossary
- Absolute homogeneity: A property of a functional where scaling inputs scales the output proportionally, used to help uniquely determine the metric’s form. "absolute homogeneity identify the unique matrix-normâweighted lag sums/averages."
- Actor–critic: A reinforcement learning architecture that jointly trains a policy (actor) and a value function (critic). "the actor--critic uses a single LEM cell (size 128)"
- Additivity over disjoint time indices: An axiom requiring that influences from non-overlapping time sets add up, guiding the metric’s uniqueness. "additivity over disjoint time indices (or magnitude-weighted averaging)"
- Active Inference: A Bayesian decision-making framework modeling agents that infer and act to minimize uncertainty, related to memory use in partial observability. "Bayesian/active inference perspectives \citep{malekzadeh_active_2024}"
- Aggregation operator (⊕): A configurable operator for combining Jacobian norms across timesteps (e.g., mean or max). "The operator is configurable: we use "
- Backpropagation Through Time (BPTT): The method of computing gradients in recurrent networks by unrolling across timesteps. "backpropagation through time \citep{werbos_backpropagation_1990}"
- Copy-: A diagnostic task where an agent must output the observation from exactly steps ago, providing known ground-truth lag. "scales with the task's ground-truth lag in Copy-"
- Effective context length: The length of prior context a model effectively uses to make predictions. "âeffective context lengthâ observations in language modeling \citep{khandelwal_sharp_2018}"
- Exploding/vanishing gradients: Training pathologies in deep/recurrent models where gradients grow without bound or shrink to zero. "exploding/vanishing gradients and bias from truncated BPTT"
- Frobenius norm: A matrix norm equal to the square root of the sum of squared entries, used to measure Jacobian block magnitudes. "Unless otherwise noted, we use the Frobenius norm."
- Gated Recurrent Units (GRUs): A type of recurrent neural network with gating mechanisms to control information flow. "Gated Recurrent Units (GRUs) \citep{chung2014empirical}"
- Generalized Advantage Estimation (GAE): A technique for variance-reduced policy gradient estimation using a decay parameter λ. "the in Generalized Advantage Estimation (GAE)"
- Induced operator norm: A norm on matrices defined by the maximum amplification of vector norms under the linear map. "Frobenius, or an induced operator norm"
- Inductive bias: Assumptions built into a learning algorithm or model that shape the hypotheses it prefers. "These conflate optimization, inductive bias, and true memory demand"
- Influence functions: Tools to estimate the effect of training points on model predictions, adapted for interpretability. "influence-functionâstyle analyses"
- Integrated Gradients: An attribution method that integrates gradients along a path from a baseline to the input. "Integrated Gradients, SmoothGrad, and influence-functionâstyle analyses"
- JAX: A numerical computing and autodiff framework used for differentiable programming in Python. "We use the JAX auto-differentiation framework \citep{jax2018github}"
- Jacobian: The matrix of first-order partial derivatives of outputs with respect to inputs. "Jacobian blocks "
- Latent states: Hidden variables underlying observations, which may be recoverable from histories in POMDPs. "latent states can be decoded from histories of length "
- Linear Oscillatory State-Space models (LinOSS): State-space models with oscillatory dynamics used for sequence modeling. "Linear Oscillatory State-Space models (LinOSS) \citep{rusch2025linoss}"
- Local linearization: Approximating a nonlinear policy by its first-order (linear) behavior around a point. "The same formulas applied to the local linearization yield our nonlinear policy metric."
- Long Expressive Memory (LEM): A sequence model designed to maintain stable gradients over long horizons via ODE-based dynamics. "Long Expressive Memory (LEM)"
- Long-horizon gradients: Gradient signals that remain stable over long temporal contexts, crucial for memory tasks. "stable long-horizon gradients."
- Magnitude-weighted average lag: The scalar summary of temporal influence, weighting lags by Jacobian magnitudes. "magnitude-weighted average lag."
- Markov decision processes (MDPs): RL models where the next state depends only on the current state and action. "Markov decision processes (MDPs)"
- Matrix norm: A function measuring the size of a matrix, used here to quantify Jacobian magnitudes. "Fix a matrix norm $\|\!\cdot\!\|_{\text{mat}$"
- Multiscale ordinary differential equation (ODE) formulation: A modeling approach using ODEs across scales to maintain expressive, stable memory. "via a multiscale ordinary differential equation (ODE) formulation."
- Partially observed Markov decision processes (POMDPs): RL settings where the agent observes incomplete information about the true state. "Partially observed Markov decision processes (POMDPs)"
- Policy head: The network output that parameterizes the action distribution. "Policy and value heads can differ materially."
- Policy logits: Unnormalized log-probabilities output by a policy network before softmax. "temperature scaling of logits."
- Proximal Policy Optimization (PPO): A policy gradient algorithm that constrains updates via a clipped objective. "Proximal Policy Optimization (PPO)"
- Range functionals: Functionals that measure extent or span (here, temporal range), used to axiomatize the metric. "prior ârangeâ functionals"
- Reverse-mode automatic differentiation: Autodiff mode that efficiently computes gradients of scalar outputs w.r.t. many inputs. "reverse-mode automatic differentiation"
- Saliency maps: Gradient-based visualizations of input importance for model outputs. "saliency maps \citep{adebayo_sanity_2018}"
- Sample-complexity bounds: Theoretical limits on the number of samples needed to learn with guarantees. "sample-complexity bounds \citep{williams_reinforcement_2009, efroni_provable_2022, morad_popgym_2023}"
- SmoothGrad: An attribution method that averages noisy gradient maps to reduce visual noise. "Integrated Gradients, SmoothGrad, and influence-functionâstyle analyses"
- State-Space Models (SSMs): Sequence models that evolve latent states over time with structured dynamics. "State-Space Models (SSMs) \citep{gu2021efficiently,gu2023mamba}"
- Temperature scaling: Rescaling logits by a constant to adjust output confidence or exploration. "temperature scaling of logits."
- Temporal credit assignment: The challenge of attributing outcomes to earlier actions or observations over time. "temporal credit-assignment foundations in RL"
- Temporal influence profile: The per-timestep weight distribution indicating how past inputs affect future outputs. "as a temporal influence profile"
- Temporal Range: The proposed metric measuring how far back a policy effectively looks in its input history. "Temporal Range thus offers a practical per-sequence readout of memory dependence"
- Truncated BPTT: Limiting backpropagation to a fixed window in time, introducing bias in recurrent training. "bias from truncated BPTT"
- Value head: The network output estimating expected return from a state. "the value head often yields a larger effective range"
- Window ablations: Experimental procedure that truncates history windows to test minimal required context. "window ablations that rebuild hidden state from truncated histories."
Collections
Sign up for free to add this paper to one or more collections.