BRAID: Bounded Reasoning for Autonomous Inference and Decisions
Abstract: LLMs exhibit nonlinear relationships between performance, cost, and token usage. This paper presents a quantitative study on structured prompting using BRAID (Bounded Reasoning for Au tonomous Inference and Decisions) across multiple GPT model tiers, eval uated on the AdvancedIF, GSM-Hard, and the SCALE MultiChallenge benchmark datasets. BRAID introduces a bounded reasoning framework using Mermaid-based instruction graphs that enable models to reason struc turally rather than through unbounded natural-language token expansion. We show that structured machine-readable prompts substantially increase reasoning accuracy and cost efficiency for agents in production systems. The findings establish BRAID as an effective and scalable technique for optimizing inference efficiency in autonomous agent systems. All datasets and detailed result logs are available at https://benchmark.openserv.ai.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces a new way to help AI models “think” clearly and cheaply. The method is called BRAID (Bounded Reasoning for Autonomous Inference and Decisions). Instead of letting an AI write long, free-form explanations while solving a problem, BRAID gives the AI a compact, step-by-step flowchart (made with a tool called Mermaid) that acts like a simple, high-density “map” of the reasoning. This keeps the AI focused, reduces wasted words, and can make small, cheaper models perform like bigger, expensive ones.
What questions does the paper try to answer?
The authors focus on a few straightforward questions:
- Can giving AI a structured, step-by-step diagram improve its accuracy compared to classic “think out loud” prompts?
- Can this structure reduce cost by using fewer tokens (words the AI reads/writes, which cost money)?
- Can smaller, cheaper models match or beat larger models if they use BRAID?
- Is there a smart way to split the work, using one model to plan the steps and another, cheaper model to carry out the plan?
How did they test their ideas?
Think of BRAID like handing the AI a recipe card instead of asking it to write a whole cooking essay. The paper set up a two-stage approach:
- A “Generator” model creates the recipe (a Mermaid flowchart that shows the logic steps).
- A “Solver” model follows that recipe to produce the final answer.
They tested this on three types of tasks:
- GSM-Hard: math word problems (like carefully doing multi-step arithmetic).
- SCALE MultiChallenge: complex questions that need multiple, connected steps of reasoning.
- AdvancedIF: instruction-following tasks (where the AI needs to understand and follow directions precisely).
To keep the results fair and practical:
- A separate judge AI checked whether answers were correct. This let solvers answer in their own natural style instead of being forced into rigid formats.
- For math, they used “numerical masking”: if the diagram included intermediate numbers, those numbers were removed and replaced with blanks, so the solver still had to do the math and couldn’t just copy an answer from the diagram.
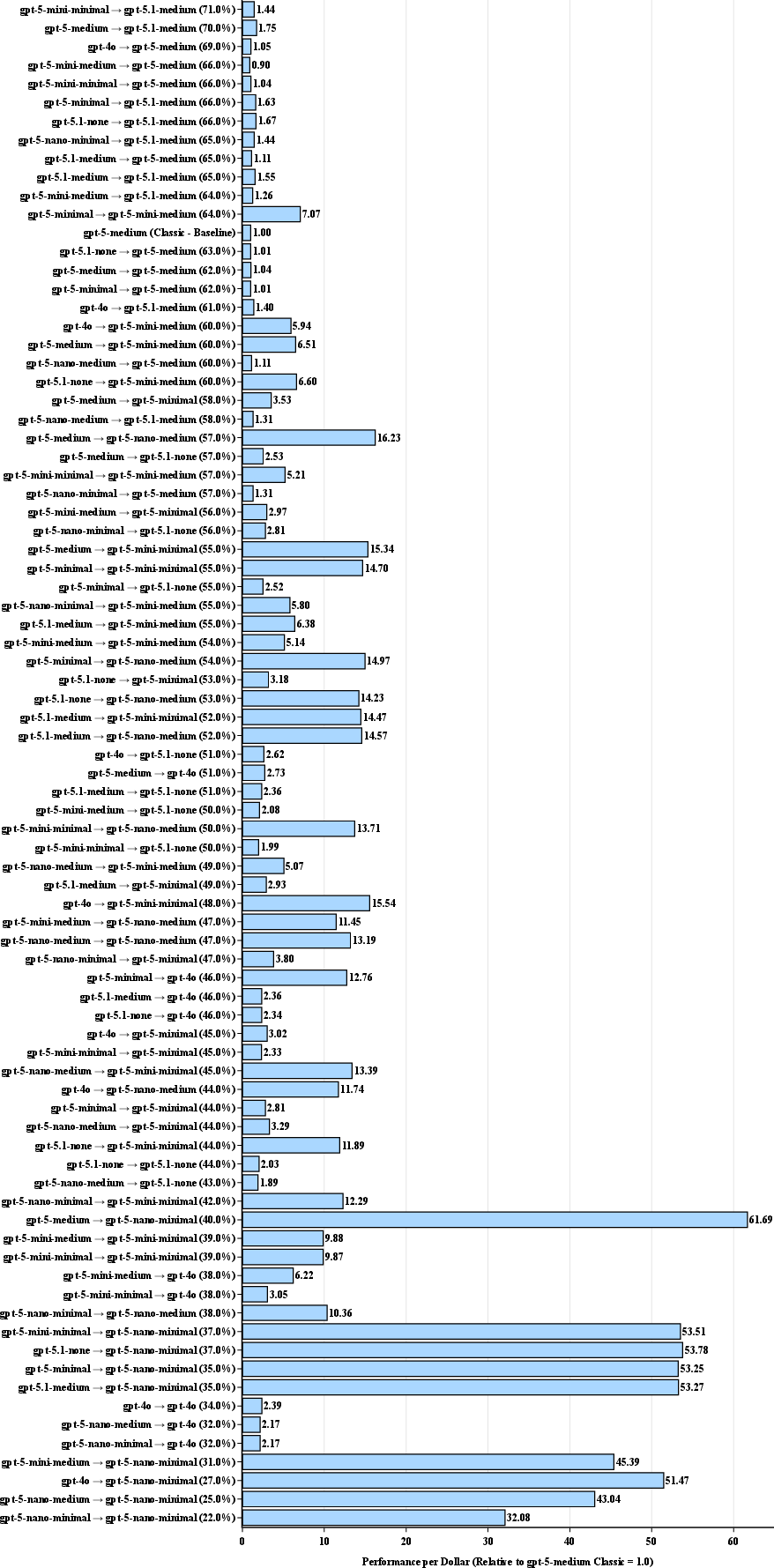
- They tracked cost by counting tokens and multiplying by each model’s price. Then they calculated “Performance-per-Dollar” (PPD), which is basically accuracy divided by cost, normalized to a standard model so 1.0 means “baseline efficiency.”
In everyday terms:
- Tokens are like phone minutes—more talking costs more money.
- BRAID is a compact plan that saves minutes and avoids rambling.
- PPD is “how much good work you get per dollar.”
What did they find?
The key results are clear and important:
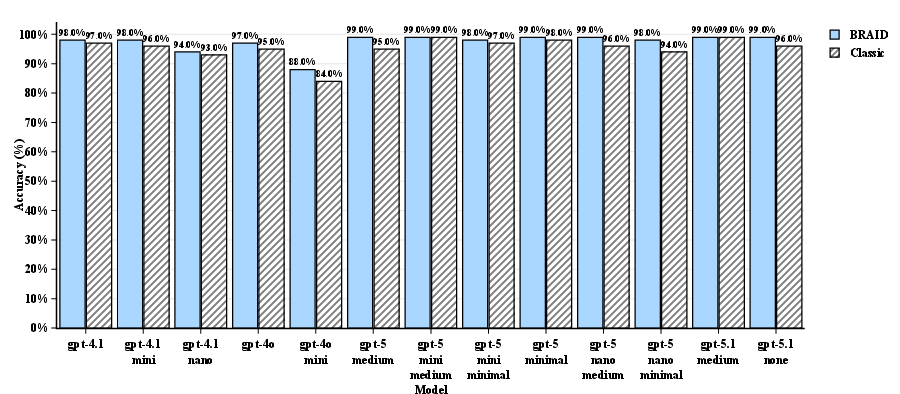
- Accuracy went up with BRAID across all model sizes and all datasets. Even models that were already good at math got slightly better, moving from “excellent” to “near-perfect.”
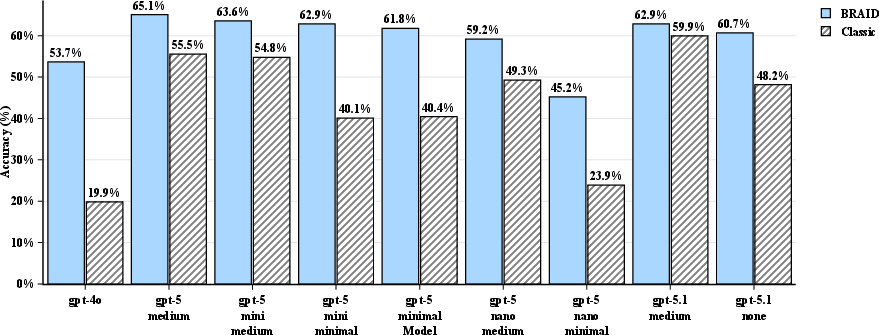
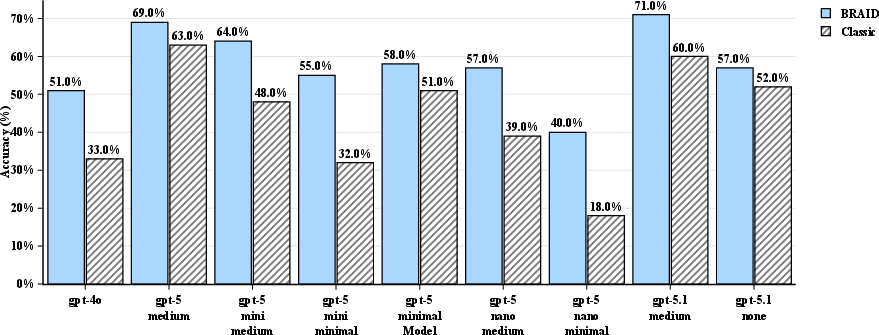
- The biggest jumps happened on complex, multi-step tasks (like SCALE MultiChallenge and AdvancedIF), where structure really helps. Some small models more than doubled their accuracy when using BRAID.
- Costs stayed the same or went down during solving. While it costs something to generate the reasoning diagrams, that cost becomes tiny if you reuse the same diagram across many questions (like caching a recipe and using it again and again).
- Performance-per-Dollar (PPD) soared for certain “split” setups. The most efficient approach was to use a stronger planner (Generator) to make a clear diagram, then a smaller, cheaper solver to follow it. In some cases, this was over 70 times more cost-effective than using a single, larger model—while still maintaining high accuracy.
In short, structure plus reuse leads to big savings and better results.
Why does this matter?
This research shows a practical path to making AI agents both smarter and cheaper:
- For companies and developers, BRAID can cut costs without sacrificing accuracy, especially when tasks are repeated and diagrams can be reused.
- For smaller models, BRAID acts like a GPS: it gives them a clear route so they don’t wander off or get verbose. That reduces “reasoning drift” (going off-topic) and the need for lots of tokens.
- It challenges the idea that you always need the biggest model for hard reasoning. With the right structure, smaller models can do great work.
- It encourages building libraries of reusable “reasoning maps” (Mermaid diagrams) for common tasks—like having reliable recipe cards for different problem types.
Overall, BRAID is a simple, scalable way to guide AI thinking: make a compact plan, then follow it. That means better answers, fewer wasted words, and much lower costs.
Knowledge Gaps
Unresolved gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, framed to enable actionable follow-on research.
- Statistical rigor and variance: No confidence intervals, significance testing, or variance analysis are reported; results are presented as “best for each solving model.” Quantify variability across seeds, runs, and prompt randomization to assess reliability.
- LLM-judge validity and bias: Accuracy is adjudicated by GPT-5.2 rather than exact-match or task-specific validators. Evaluate judge agreement with ground truth, inter-judge reliability, and bias across models and output styles; include human and programmatic validators where applicable.
- Baseline comparability: The “Classic” baseline excludes CoT triggers to avoid redundancy with “thinking models,” potentially disadvantaging baselines. Add matched baselines (e.g., CoT, self-consistency, least-to-most) under equal cost budgets to isolate BRAID’s unique contribution.
- Token-level efficiency evidence: Claims of reduced “reasoning drift” and higher token density are not quantified. Measure input/output token counts, compression ratios, and token-per-correct-answer across conditions; analyze verbosity and off-topic generation rates.
- Latency and throughput: The study focuses on cost and accuracy but omits latency/throughput measurements critical for production agents. Report end-to-end time (generation + solving), solver-only latency, and concurrency scaling under realistic workloads.
- Graph quality and robustness: Automatically generated diagrams can be incomplete or wrong. Characterize failure modes, measure solver robustness to graph errors, and evaluate whether solvers can recover from or correct flawed structures.
- Amortization and break-even analysis: The cost model assumes reuse of cached graphs but lacks empirical curves for different reuse counts N. Provide break-even N and sensitivity analyses under varying task heterogeneity and graph reuse rates.
- Manual authoring costs: In production, graphs are “handcrafted,” yet authoring effort, maintenance burden, and lifecycle costs are not quantified. Estimate human hours per graph, update cadence, versioning overhead, and ROI vs. automated generation.
- Semantic formalization of diagrams: Mermaid is a markup language, not a formal reasoning DSL. Define a task-agnostic, formally specified grammar (with node types, edge semantics, constraints) and test whether stronger semantics improve correctness and interpretability.
- Executability vs. interpretability: BRAID graphs are advisory and not executable. Compare performance to Program-of-Thought or code-executing approaches, and evaluate hybrid designs where parts of the graph compile to executable checks or calculators.
- Alternative structured formats: Mermaid is one choice among many. Benchmark JSON schemas, pseudo-code, SAT-style constraints, flowcharts, or decision tables against Mermaid under matched budgets to see which structural representation yields the best efficiency/accuracy.
- Determinism claim: The paper asserts “deterministic logical flows,” but model-generated diagrams and free-form solver responses are not guaranteed to be deterministic. Provide empirical evidence (repeatability rates) and formal constraints that enforce determinism.
- Dataset coverage and difficulty stratification: Results span only three benchmarks and do not stratify by subtask types or difficulty. Extend to code generation, formal logic, commonsense, scientific QA, and multimodal tasks; analyze where BRAID helps or hurts.
- Numerical masking ablation: GSM-Hard uses masking to prevent leakage, but no ablation quantifies its effect on accuracy and cost. Test BRAID with/without masking, and ensure fairness by equalizing leakage prevention across baselines.
- Generalization across model families: Evaluations use closed OpenAI models. Replicate on open-weight (LLaMA, Mistral) and other closed-model families (Anthropic, Google) to assess portability and training-dependence on Mermaid syntax.
- Language and modality scope: The paper is English-centric and text-only. Assess multilingual performance (non-Latin scripts) and applicability to multimodal problems (vision, tables, diagrams) where graphs may encode cross-modal constraints.
- Security and robustness: No assessment of adversarial prompt injection via diagram content, poisoning of node semantics, or solver jailbreak risks. Develop and test defenses (schema validation, sanitization, restricted node vocabularies).
- Calibration vs. memorization: “Unseen” claims for SCALE/AdvancedIF are asserted but not verified. Perform training data overlap checks, control for memorization, and include out-of-distribution tests to confirm genuine reasoning gains.
- PPD metric stability: PPD depends on model pricing and the chosen baseline. Analyze sensitivity to price changes, regional pricing, and alternative normalizations (e.g., cost per correct, “regret per dollar” vs. best-known solver).
- End-to-end agentic evaluation: The paper assumes agents reuse graphs but does not evaluate persistent agents under realistic task mixes, interruptions, context resets, or long-horizon planning. Measure performance in full agent loops with caching policies.
- Error analysis: Provide qualitative and quantitative breakdowns of typical errors (missing steps, incorrect branching, wrong constraints) with and without BRAID to inform targeted improvements.
- Combining BRAID with sampling: Self-consistency or diverse-plan sampling may further boost robustness. Evaluate multi-graph generation (ensemble of BRAIDs), plan-selection heuristics, and vote/merge strategies under cost constraints.
- Interpretability for operators: Graph readability and maintainability by non-experts are not assessed. Conduct usability studies on graph clarity, debugging workflows, and training needed for ops teams to author/curate graphs.
- Governance and versioning: How are graph libraries curated, validated, versioned, and rolled back in production? Propose governance processes and CI/CD checks for reasoning artifacts.
- Theoretical grounding: The paper motivates bounded reasoning heuristically. Develop formal models of token economics vs. reasoning structure, and analyze conditions under which structure substitutes for parameter count (capacity × structure trade-off).
- Reproducibility artifacts: Exact prompts, graph-generation instructions, judge configurations, seeds, and code are not fully detailed in the paper. Release complete, versioned artifacts to enable independent replication and benchmarking.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that can leverage BRAID’s bounded reasoning with Mermaid-based instruction graphs today. Each item names sectors, a succinct value proposition, potential product/workflow ideas, and key dependencies or assumptions.
- Application: Agent cost-down via split-architecture prompting
- Sectors: Software, customer support, e-commerce, content ops
- What it does: Use a strong “Generator” model to produce reusable BRAID graphs and a cheaper “Solver” model to execute them; cut inference costs while improving or maintaining accuracy (the paper’s “Golden Quadrant”).
- Tools/Products/Workflows: Prompt orchestration layer that (1) caches BRAID graphs per task family, (2) routes to low-cost solvers, (3) logs accuracy and PPD.
- Assumptions/Dependencies: Solver must reliably interpret Mermaid; high-quality graphs exist or are easy to generate; caching provides high reuse.
- Application: Runbook-to-BRAID conversion for operations playbooks
- Sectors: IT operations, DevOps/SRE, customer support, BPO
- What it does: Convert standard operating procedures and runbooks into BRAID graphs so agents follow deterministic flows with fewer tokens and less “reasoning drift.”
- Tools/Products/Workflows: Internal “runbook compiler” that ingests SOPs and outputs Mermaid; library of reusable graphs for incident triage, escalation, and RCA checklists.
- Assumptions/Dependencies: Domain experts can validate/approve graphs; knowledge base alignment to procedures.
- Application: Customer service triage and resolution flows
- Sectors: Telecom, retail, SaaS, banking
- What it does: Encode decision trees (eligibility, refunds, troubleshooting) as Mermaid graphs; small solver models deliver accurate and consistent outcomes with reduced cost.
- Tools/Products/Workflows: CRM plugin to fetch the right BRAID graph by intent; A/B tests vs classic prompting on CSAT, AHT, and PPD.
- Assumptions/Dependencies: Up-to-date policy/knowledge integration; guardrails for compliance.
- Application: Document drafting with structured issue trees
- Sectors: Legal, compliance, consulting
- What it does: Use BRAID graphs to structure argumentation, risk analysis, or contract clause selection, reducing meandering CoT and improving consistency.
- Tools/Products/Workflows: “Issue tree to draft” assistant with graph templates for NDAs, MSAs, DPIAs; document assembly guided by nodes.
- Assumptions/Dependencies: Human-in-the-loop review; curated clause libraries; jurisdiction-specific rules.
- Application: Instruction-following in content workflows
- Sectors: Marketing, localization, technical writing
- What it does: Encode style guides, tone constraints, and review criteria in BRAID to enforce deterministic editorial pipelines with smaller models.
- Tools/Products/Workflows: CMS plugin that applies task-specific Mermaid graphs (e.g., outline → draft → compliance check → finalize) for repeatable outputs.
- Assumptions/Dependencies: Good mapping from style guides to decision logic; measurement of quality vs cost.
- Application: STEM problem solving with leakage-safe patterns
- Sectors: Education, test prep, tutoring platforms
- What it does: Apply the paper’s numerical masking protocol to math graphs; students get accurate solutions from small models without “answer leakage.”
- Tools/Products/Workflows: Tutor mode that shows graph-based reasoning templates while keeping numbers masked until solution time; per-problem BRAID library.
- Assumptions/Dependencies: Solver’s arithmetic reliability; content moderation; alignment with pedagogy.
- Application: Compliance and policy adherence checkers
- Sectors: Finance, healthcare, HR, procurement
- What it does: Operationalize policies/procedures as BRAID graphs (eligibility, documentation checks, KYC steps); ensure consistent, auditable decisions with low-cost solvers.
- Tools/Products/Workflows: Policy-to-graph converter; “Why” trace mapped to graph edges for audit.
- Assumptions/Dependencies: Current policy corpus; trace logging and access controls.
- Application: Product support troubleshooting assistants
- Sectors: Consumer electronics, software/hardware OEMs
- What it does: Encode troubleshooting trees into Mermaid for consistent diagnosis and resolution suggestions, minimizing verbose CoT and token waste.
- Tools/Products/Workflows: Self-serve portal/IVR-to-chat that maps intents to device-specific BRAID graphs; dynamic parts/RMA handoff nodes.
- Assumptions/Dependencies: Coverage of device variants; integration with backend systems.
- Application: Job routing and workflow orchestration for LLM agents
- Sectors: Software engineering, back-office automation
- What it does: Use BRAID to define task decomposition, tool-calling order, and guardrails, preventing off-topic exploration.
- Tools/Products/Workflows: LangChain/LLM framework component to parse Mermaid into execution plans; cost/latency dashboards using PPD.
- Assumptions/Dependencies: Stable tool APIs; deterministic plan execution; telemetry.
- Application: Procurement and model selection driven by PPD metric
- Sectors: Enterprise IT, AI platform teams
- What it does: Use the paper’s PPD to pick cost-optimal Generator→Solver pairs for each task family; continuously benchmark and re-route.
- Tools/Products/Workflows: Model router with PPD leaderboards; policy to prefer BRAID+small solver when accuracy thresholds met.
- Assumptions/Dependencies: Accurate price/usage metering; ongoing evaluation set; change management.
- Application: Data labeling and review with bounded checklists
- Sectors: ML ops, annotation vendors, research labs
- What it does: Encode labeling guidelines as graphs, enforcing decision criteria (e.g., toxic vs non-toxic, multi-label steps), lowering costs with small solvers.
- Tools/Products/Workflows: Annotation UI that runs Solver with a BRAID graph per taxonomy; inter-annotator agreement measured at lower cost.
- Assumptions/Dependencies: High-quality labeling policies; human adjudication for edge cases.
- Application: Agent safety guardrails with explicit branches
- Sectors: Healthcare, fintech, education
- What it does: Replace free-form reasoning with explicit “red line” branches (e.g., escalate, refuse, warn) to reduce unsafe outputs and hallucinations.
- Tools/Products/Workflows: Safety graphs embedded as system prompts; post-hoc audits by comparing outputs to traversed nodes.
- Assumptions/Dependencies: Policy coverage; robust refusal patterns; logging of graph traversal.
- Application: Cost-aware content moderation and triage
- Sectors: Social media, UGC platforms, marketplaces
- What it does: Encode violation categories and escalation logic; small solvers triage most traffic, escalate only necessary cases to larger models/humans.
- Tools/Products/Workflows: Tiered moderation pipeline; BRAID cache keyed by topic/policy version; PPD-based escalations.
- Assumptions/Dependencies: Up-to-date policy mapping; fairness/false-positive monitoring.
- Application: Academic evaluations and auto-graders with structured rubrics
- Sectors: Education, MOOC platforms
- What it does: Encode rubrics (criteria, weighting, common errors) as BRAID; small solvers apply deterministic checks, reducing grading drift and cost.
- Tools/Products/Workflows: LMS plug-in that translates rubrics to graphs; numeric masking for calculation questions; sampling for human QA.
- Assumptions/Dependencies: Well-defined rubrics; institutional acceptance; bias checks.
Long-Term Applications
These opportunities are promising but may require further research, scaling, productization, or standards.
- Application: “Instruction graph” marketplaces and catalogs
- Sectors: Cross-sector
- What it could be: Marketplaces for reusable BRAID graphs (e.g., KYC flows, SOC2 checks, onboarding), versioned and audited.
- Dependencies: Licensing/IP frameworks; quality ratings; interoperability standards for graph schemas.
- Application: Formal verification and certification of reasoning graphs
- Sectors: Healthcare, aviation, automotive, finance
- What it could be: Verified BRAID graphs with proofs of coverage/completeness and compliance; certifiable AI workflows.
- Dependencies: Tooling for static analysis of Mermaid/graph DSLs; regulatory buy-in; safety cases.
- Application: Native BRAID interpreters and compilers
- Sectors: Software tooling, AI platforms
- What it could be: Engines that compile Mermaid/graph DSL to executable plans with tool-calls, retrieval steps, and control flow, independent of vendor prompts.
- Dependencies: Standardized graph semantics; robust execution runtimes; error recovery semantics.
- Application: Training or fine-tuning LLMs on bounded reasoning corpora
- Sectors: Foundation model providers, academia
- What it could be: Models that internalize BRAID-like structures, reducing need to parse Mermaid and improving solver robustness.
- Dependencies: Large curated datasets of graph-reasoning pairs; training infrastructure; evaluation protocols.
- Application: Adaptive graph learning and personalization
- Sectors: Education, customer experience, enterprise automation
- What it could be: Systems that learn to refine graphs from user feedback and outcomes (e.g., shorter paths, fewer escalations).
- Dependencies: Safe online learning loops; governance for changes; drift detection.
- Application: Hybrid PoT/BRAID with executable nodes
- Sectors: Finance (valuation), engineering (simulation), data analysis
- What it could be: Nodes that call code, SQL, or tools; combine symbolic plan with deterministic computation for reliability and auditability.
- Dependencies: Secure sandboxes; tool-use policies; robust tool-calling APIs.
- Application: Carbon-aware and budget-aware routing via PPD
- Sectors: Cloud/AI ops, sustainability
- What it could be: Dynamically route workloads to Generator→Solver pairs that optimize for carbon intensity, latency, and budget constraints.
- Dependencies: Real-time pricing/carbon feeds; SLAs; multi-provider orchestration.
- Application: Regulatory metrics and disclosures for AI efficiency
- Sectors: Policy, regulators, standards bodies
- What it could be: Standardized disclosures (e.g., PPD, tokens per decision, accuracy@budget) for AI systems used in public services or finance.
- Dependencies: Consensus on metrics; audit tooling; adoption by vendors.
- Application: Safety envelopes and “reasoning sandboxes”
- Sectors: Healthcare, public sector, critical infrastructure
- What it could be: Strictly bounded graphs with whitelisted actions for safety-critical decisions; runtime monitors that enforce path constraints.
- Dependencies: Hazard analyses; formal safety cases; incident response integration.
- Application: Multi-agent systems coordinated by shared BRAID plans
- Sectors: Robotics, logistics, manufacturing
- What it could be: Teams of agents (planning, perception, actuation) executing shared graphs with synchronization points to reduce coordination errors and token overhead.
- Dependencies: Real-time comms; alignment across agents; failover strategies.
- Application: End-user tooling for “visual reasoning programming”
- Sectors: SMBs, education, citizen developers
- What it could be: No-code editors for authoring and testing BRAID flows; test harnesses; one-click deployment to chatbots/agents.
- Dependencies: Usable UX; templates; guardrails to prevent unsafe flows.
- Application: Auditable decision trails for algorithmic accountability
- Sectors: Public sector, HR, lending
- What it could be: Store the exact graph path traversed per decision, enabling explainability and appeals.
- Dependencies: Privacy-preserving logs; governance; legal acceptance of graph-based explanations.
- Application: Hardware/inference optimizations for graph-bounded LLMs
- Sectors: Semiconductors, AI infra
- What it could be: KV cache and decoding strategies optimized for short, structured prompts and low-output verbosity; accelerator kernels for graph execution.
- Dependencies: Vendor support; workload profiling; ecosystem adoption.
Cross-cutting assumptions and risks
- Mermaid/graph comprehension: Some models may need prompt-tuning or adapters to reliably parse and follow Mermaid syntax.
- Graph quality: Handcrafted or generated graphs must be accurate and updated; poor graphs impede performance regardless of solver cost.
- Caching economics: High reuse of graphs is key to amortize generation cost; low-reuse tasks may see less benefit.
- Model/vendor drift: Token pricing, API behaviors, and “thinking” capabilities may change; continuous PPD monitoring is required.
- Evaluation reliability: The paper used an LLM judge; in production, human evaluation or robust automatic metrics may be necessary for high-stakes tasks.
- Security and privacy: Stored graphs may encode sensitive policy logic; access controls and versioning are required.
- Domain constraints: Safety-critical deployments require formal verification and regulatory approval beyond today’s capabilities.
Glossary
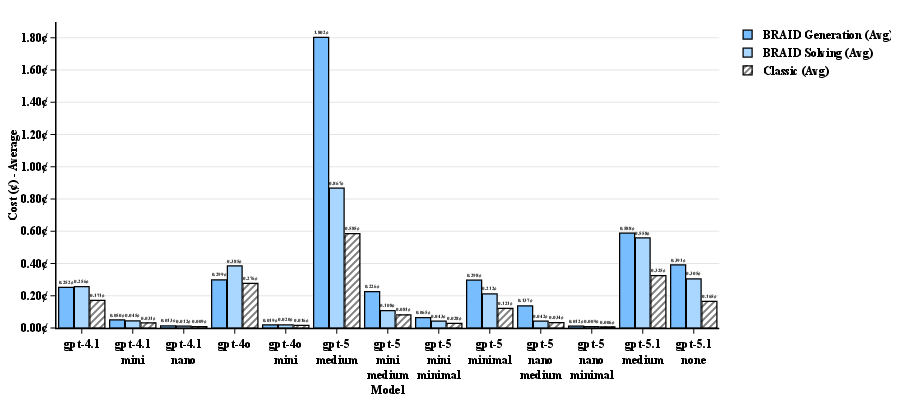
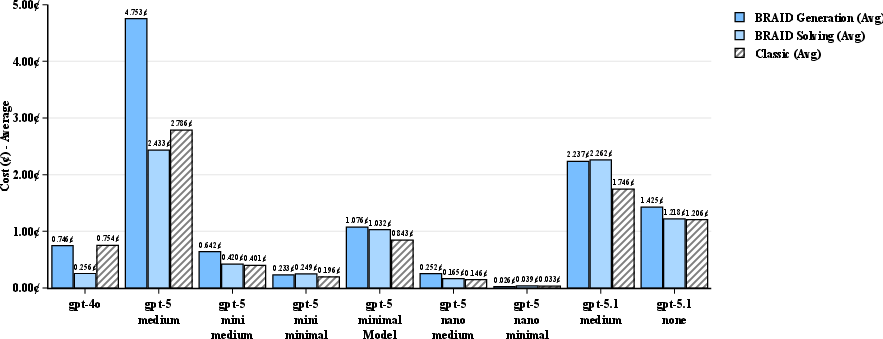
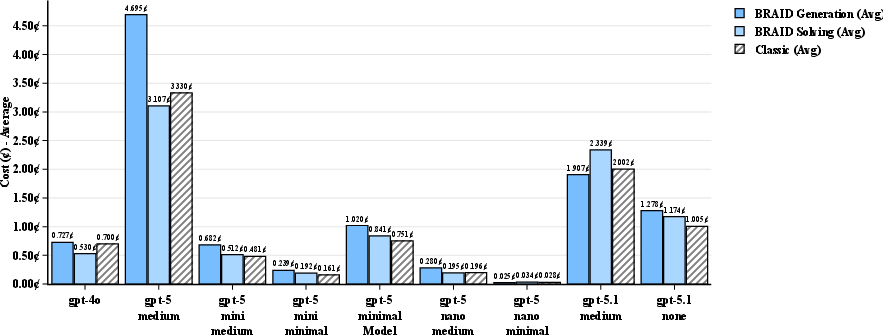
- AdvancedIF: A benchmark dataset used to evaluate instruction-following and reasoning performance of LLMs. "We evaluated 272 SCALE MultiChallenge reasoning questions, 100 GSM-Hard and 100 AdvancedIF questions across combinations of GPT models acting as prompt generators and solvers."
- agentic workflows: Continuous, autonomous agent processes that execute tasks and can reuse structured prompts for efficiency. "demonstrating a major economic advantage for agentic workflows that leverage cached Mermaid reasoning graphs."
- amortized total cost per query: The per-query cost obtained by spreading a one-time prompt generation expense across many future uses. "In cases where BRAID generation is performed once but reused across queries, the amortized total cost per query can be expressed as:"
- answer leakage: Unintended exposure of intermediate or final answers in artifacts that could let a solver copy rather than compute. "we implemented a Numerical Masking Protocol to address ``answer leakage.''"
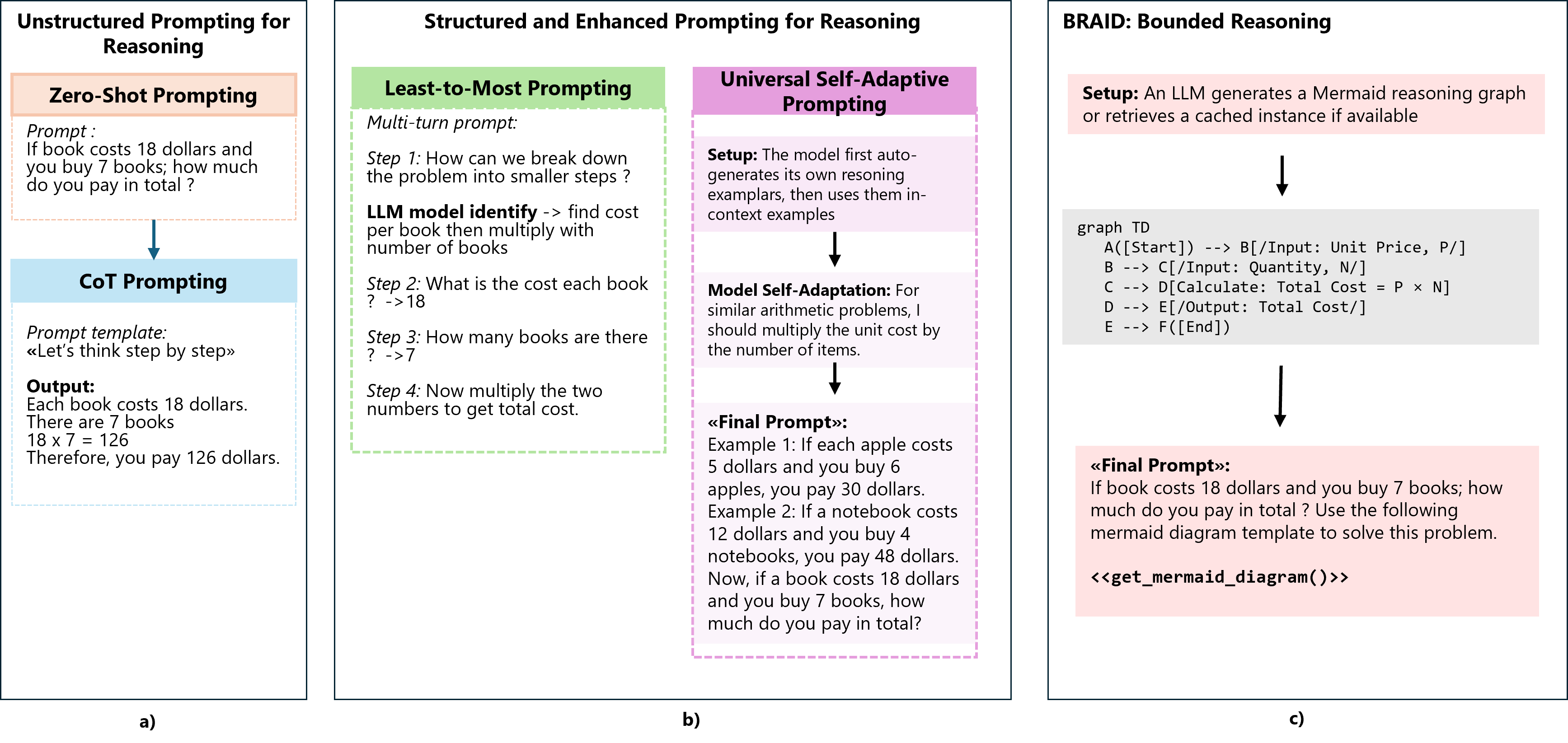
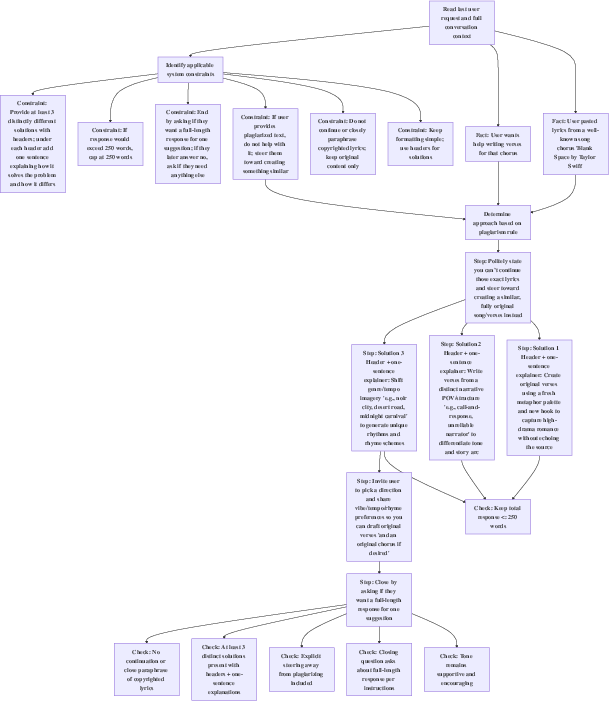
- bounded reasoning: Constraining a model’s reasoning steps to a predefined, symbolic structure to control token usage and path variability. "BRAID introduces a bounded reasoning framework using Mermaid-based instruction graphs that enable models to reason structurally rather than through unbounded natural-language token expansion."
- BRAID (Bounded Reasoning for Autonomous Inference and Decisions): A prompting framework that replaces natural-language chains of thought with compact, structured symbolic diagrams. "The Bounded Reasoning for Autonomous Inference and Decisions (BRAID) framework is proposed as a structural improvement to classical prompting techniques."
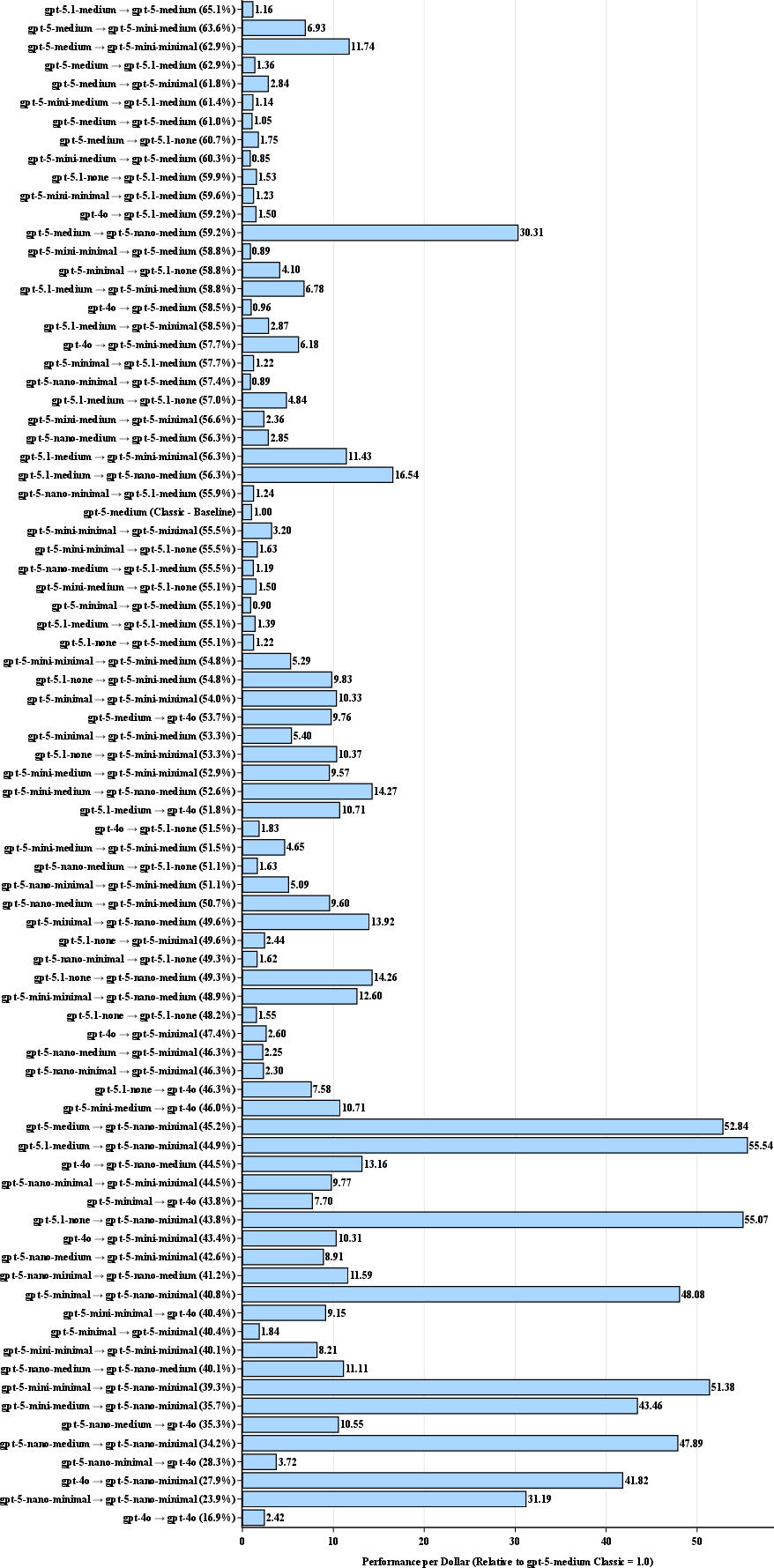
- BRAID Parity Effect: The observed phenomenon that a smaller model using BRAID can match or exceed larger models’ performance under unstructured prompting. "The most significant finding of this study as we call the BRAID Parity Effect: the observation that a smaller model equipped with bounded reasoning (BRAID) often matches or exceeds the performance of a model one or two tiers larger using unstructured prompting."
- Chain-of-Thought (CoT) prompting: A strategy that elicits intermediate reasoning steps before producing the final answer. "Chain-of-Thought (CoT) prompting is a landmark prompting strategy that elicits intermediate reasoning steps before the final answer."
- decompositional prompting: A method that breaks a complex problem into a sequence of simpler sub-problems solved step by step. "Decompositional prompting is one of them proposed by \cite{zhou2022least} as ``least-to-most prompting'' technique."
- few-shot prompting: Providing a small number of input–output examples in the prompt so the model can infer patterns without fine-tuning. "in-context learning via few-shot prompting can achieve strong performance on diverse NLP tasks using only text demonstrations instead of fine-tuning"
- Golden Quadrant: The efficiency regime achieved by pairing a high-intelligence generator with a low-cost solver to maximize PPD. "By decoupling reasoning (generation) from execution (solving), we identified a \"Golden Quadrant\" of efficiency: using high-intelligence models for generation and low-cost models for solving."
- GSM-Hard: A math word problem benchmark used to test multi-step reasoning accuracy of LLMs. "We evaluated 272 SCALE MultiChallenge reasoning questions, 100 GSM-Hard and 100 AdvancedIF questions across combinations of GPT models acting as prompt generators and solvers."
- in-context learning: The ability of LLMs to learn task behavior from examples or instructions in the prompt without updating parameters. "in-context learning via few-shot prompting can achieve strong performance on diverse NLP tasks using only text demonstrations instead of fine-tuning"
- LLM adjudicator: A LLM used to judge or grade the correctness of outputs in evaluations. "Across all three datasets, accuracy was evaluated using an external LLM, with GPT-5.2 (medium reasoning effort) serving as the adjudicator."
- LLM judge: An LLM employed to evaluate responses, allowing flexible output formats without strict schemas. "By utilizing an LLM judge, we permitted the solver models to produce responses in their native, unconstrained free-form style."
- Mermaid-based instruction graphs: Machine-readable procedural diagrams written in Mermaid syntax to guide structured reasoning. "Mermaid-based instruction graphs that enable models to reason structurally rather than through unbounded natural-language token expansion."
- Mermaid diagrams: Textual graph notations (flowcharts) used in prompts to encode deterministic logical flows. "BRAID replaces the natural-language CoT trace with a bounded, symbolic reasoning structure expressed in Mermaid diagrams."
- Numerical Masking Protocol: A post-processing step that replaces numbers in reasoning graphs with placeholders to prevent leaking intermediate computations. "we implemented a Numerical Masking Protocol to address ``answer leakage.''"
- Performance-per-Dollar (PPD): A normalized metric comparing accuracy per unit cost relative to a baseline model, used to assess efficiency. "Introducing performance-per-dollar (PPD) metric for quantifying LLM efficiency gains, achieving major leap in optimal configurations"
- Plan-and-Solve prompting: A two-stage approach where the model first devises a plan, then executes sub-tasks according to that plan. "Plan-and-Solve prompting \cite{wang2023plan} uses a two-phase prompt to avoid missing steps in zero-shot reasoning."
- pretraining prior: The bias induced by training data that influences earlier transformer layers to retrieve world knowledge. "earlier layers remain biased toward retrieving world knowledge (the pretraining prior), while later layers shift focus on the in-context reasoning provided by the CoT prompt."
- Program-of-Thought (PoT): A prompting technique that uses executable code or formal symbols as intermediate reasoning steps. "Program-of-Thought (PoT) or Chain-of-Symbol approaches by \cite{chen2023programthoughtspromptingdisentangling} replace or supplement natural language steps with executable code or symbolic representations."
- reasoning drift: The tendency of free-form chains of thought to become verbose, off-topic, or inconsistent over time. "This structural shift not only mitigates the token-cost problem but also reduces “reasoning drift” where the model’s internal monologue becomes verbose or off-topic."
- SCALE MultiChallenge: A benchmark involving complex multi-step reasoning across diverse tasks. "We evaluated 272 SCALE MultiChallenge reasoning questions, 100 GSM-Hard and 100 AdvancedIF questions across combinations of GPT models acting as prompt generators and solvers."
- Self Consistency decoding strategy: A method that samples multiple reasoning paths and aggregates their final answers for improved reliability. "One mitigation is to sample multiple distinct chains of thought and aggregate their answers – the Self Consistency decoding strategy \cite{wang2022self}."
- signal-to-noise ratio: The proportion of meaningful information relative to extraneous text in generated reasoning. "This can potentially degrade the signal-to-noise ratio, particularly for high-end reasoning models like GPT-5 with high reasoning effort, which often generate verbose reasoning traces without proportional accuracy improvement"
- split-architecture approach: Decoupling prompt generation and solving into separate models to optimize cost-efficiency and performance. "The efficiency gains for GSM-Hard confirm the viability of this split-architecture approach."
- Structured Chain-of-Thought (SCoT) prompting: A variant of CoT that uses pseudo-code structures (loops, branches) as the “thoughts.” "Structured Chain-of-Thought (SCoT) prompting by \cite{li2023structuredchainofthoughtpromptingcode} uses pseudo-code structures (like loops, branches) as the “thoughts” to guide code writing."
- structured prompting: Prompting that imposes explicit structure or intermediate steps to improve reliability on complex tasks. "This paper presents a quantitative study on structured prompting using BRAID (Bounded Reasoning for Autonomous Inference and Decisions)"
- Thinking models: LLM variants with intrinsic latent reasoning capabilities that automatically engage during inference. "the models evaluated in this study possess intrinsic latent reasoning capabilities (`thinking models') that automatically engage during inference."
- Tree of Thoughts: A reasoning framework that organizes multi-step problem solving as exploration in a tree of intermediate states. "Explicit stepwise instructions e.g. Tree of Thoughts by \cite{yao2023_ToT} scaffold the model’s internal generation toward intermediate reasoning tokens"
- Universal Self-Adaptive Prompting (USP): An automated zero-shot prompting method where the model constructs its own pseudo-demonstrations. "Universal Self-Adaptive Prompting (USP) \cite{wan2023universal} is an approach that learns to construct effective prompts for arbitrary tasks in a zero-shot way."
- Zero-Shot CoT: Eliciting chain-of-thought reasoning without providing example demonstrations. "This Zero-Shot CoT approach revealed that LLMs are “decent zero-shot reasoners” when encouraged to articulate multi-step solutions"
- zero-shot prompting: Prompting with no labeled examples, often relying solely on task instructions. "for the control conditions, we employed a strict zero-shot prompting protocol, deliberately omitting explicit Chain-of-Thought triggers (e.g., `Let's think step by step')."
Collections
Sign up for free to add this paper to one or more collections.