Can Agentic AI Match the Performance of Human Data Scientists?
Abstract: Data science plays a critical role in transforming complex data into actionable insights across numerous domains. Recent developments in LLMs have significantly automated data science workflows, but a fundamental question persists: Can these agentic AI systems truly match the performance of human data scientists who routinely leverage domain-specific knowledge? We explore this question by designing a prediction task where a crucial latent variable is hidden in relevant image data instead of tabular features. As a result, agentic AI that generates generic codes for modeling tabular data cannot perform well, while human experts could identify the important hidden variable using domain knowledge. We demonstrate this idea with a synthetic dataset for property insurance. Our experiments show that agentic AI that relies on generic analytics workflow falls short of methods that use domain-specific insights. This highlights a key limitation of the current agentic AI for data science and underscores the need for future research to develop agentic AI systems that can better recognize and incorporate domain knowledge.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
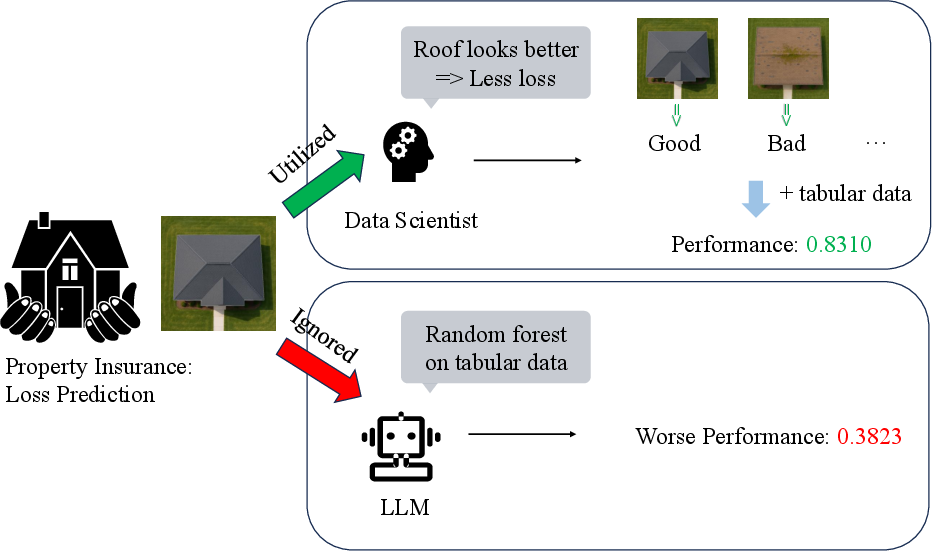
This paper asks a simple but important question: Can today’s AI “agents” that automatically write and run data science code do as well as human data scientists? The authors test this by creating a realistic challenge where a key clue is hidden in pictures, not in the spreadsheet of numbers. Humans can notice that clue using common sense and domain knowledge, but a generic AI pipeline that only looks at tables usually cannot.
What questions did the researchers ask?
They focused on two easy-to-understand questions:
- If important information is only visible in images (not in the table), do generic AI data science tools miss it?
- When humans add domain knowledge from the images, how much better can their predictions get?
How did they study it?
The team built a fake-but-realistic insurance dataset to carefully control the problem and make fair comparisons.
First, here’s the story behind the data:
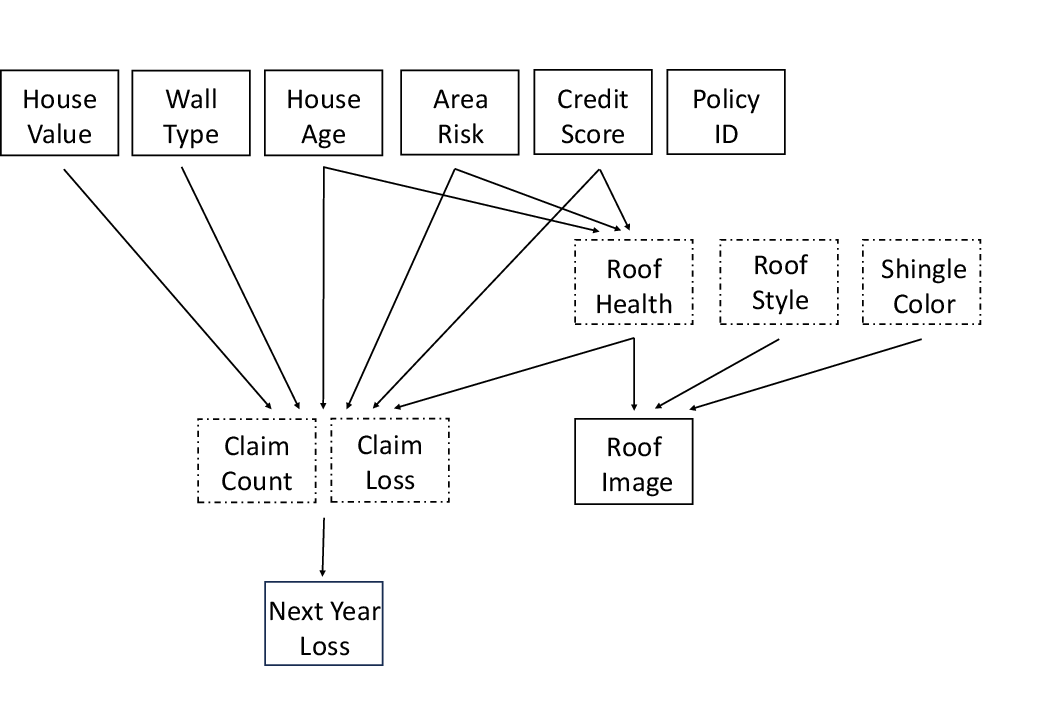
- Imagine an insurance company trying to predict how much money it will pay next year for house damage.
- For each house, you get normal spreadsheet columns (like house value, age, wall type, local storm risk, and credit score).
- You also get an overhead photo of the home’s roof.
- There is a hidden variable called RoofHealth (Good, Fair, or Bad). This matters a lot for future damage, but it is NOT written anywhere in the spreadsheet. It can only be guessed by looking at the roof photo (e.g., missing shingles, damaged ridge lines).
What they compared:
- Generic agentic AI approach: Use only the table (no images) with a standard model, like current AI agents often do.
- Human-like approaches: Use both the table and the images in sensible ways, such as:
- Turning images into features with a vision model (CLIP) and feeding those features into a prediction model.
- Asking a vision-LLM to label RoofHealth from the image, then using that label.
- Using perfect RoofHealth labels, as if an expert human had checked every image.
- Oracle (best possible): Use the exact formulas that generated the data plus the true RoofHealth. This sets the upper limit of how well anyone could do.
How they judged success:
- They used a ranking score called the normalized Gini coefficient (from 0 to 1).
- Think of it like grading how well your predictions order houses from most risky to least risky. A score near 1 means your ranking is almost perfect; 0 means you’re basically guessing.
What did they find and why is it important?
Key results show a clear pattern: using domain knowledge from images makes a big difference.
- Generic AI pipeline (tables only): normalized Gini ≈ 0.38
- This is not great because it ignores the roof photos where the crucial clue lives.
- Human-like use of images:
- Clustered image features into rough categories: ≈ 0.50 (some improvement)
- Full image features (CLIP) added to the model: ≈ 0.77 (big jump)
- RoofHealth auto-labeled by a vision-LLM: ≈ 0.73 (also strong)
- True RoofHealth labels (as if a careful human labeled every photo): ≈ 0.83 (near the best possible)
- Oracle (best achievable): ≈ 0.84
Why this matters:
- The jump from ≈ 0.38 (tables only) to ≈ 0.77–0.83 (when images/roof health are used) shows that domain knowledge and multimodal clues are critical. If the AI ignores the photos, it misses the most important signal.
Why this matters and what’s next?
This study shows that current “agentic” AI for data science often follows a generic, table-only recipe. That works for many tasks, but it falls short when vital information is hidden in other formats (like images). Human data scientists, who know what to look for and how to combine different kinds of data, can do much better.
What this means going forward:
- AI tools need to get better at noticing when important clues might be in images, text, audio, or other sources—not just spreadsheets.
- They should learn to bring in domain knowledge (like “roof condition affects storm damage risk”) and to extract the right signals from the right data type.
- Future research should build AI agents that can ask for the missing pieces, read images intelligently, and reason like a domain expert, so they can close the gap with skilled humans.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper highlights an important performance gap but leaves several areas unresolved. Future research could address the following:
- External validity: Does the observed gap persist on real property insurance data with UAV/satellite roof imagery (variable angles, occlusions, weathering, resolution, and noise) rather than prompt-generated images?
- Human validation: To what extent can human experts reliably infer RoofHealth from real images (accuracy, inter-rater reliability), and at what time/cost? No user study or annotation experiment is reported.
- Agentic AI capability scope: The “agentic AI (generic pipeline)” baseline omits multimodal tool use. How well do state-of-the-art agent agents that can call vision models, perform end-to-end multimodal learning, or retrieve domain knowledge compare to human experts?
- Benchmark breadth: The study uses a single synthetic task/domain. Can a broader benchmark spanning multiple domains and modalities (text, audio, time series, geospatial) with hidden latent factors generalize the conclusions?
- Robustness to design choices: How sensitive are results to the strength of the latent factor, class prevalence thresholds (55%/80%), noise level in RoofHealth, and the parameters in the claim frequency/severity processes?
- Metric coverage: Normalized Gini is appropriate for ranking, but how do conclusions change under calibration metrics (e.g., calibration slope/ECE), tail-aware losses (quantile/Pinball), MAE/MAPE, or decision-centric metrics (profit/lift curves)?
- Model diversity: Only random forests are evaluated. How do gradient boosting (XGBoost/LightGBM/CatBoost), GLMs/GBMs tailored for insurance, zero-inflated and compound models, deep tabular networks, and modern multimodal architectures perform?
- End-to-end multimodal learning: Can joint image–tabular models trained end-to-end (e.g., CNN/ViT fusion with tabular MLP/GBM, late/early fusion) close the gap without explicit “domain knowledge” labeling?
- Detection of missing modalities: How can an agent autonomously diagnose when tabular features are insufficient and decide to query/use additional modalities (images/text) or domain expertise?
- Acquisition of domain knowledge: What strategies enable agents to recognize relevant domain concepts (e.g., RoofHealth) and operationalize them (RAG over actuarial literature, tool invocation for image analysis, structured reasoning/planning)?
- Image generation validity: Do prompt-engineered descriptors introduce spurious cues or shortcuts that CLIP/VLMs exploit? Is roof style/color distribution balanced to avoid unintended leakage?
- Cross-model variance: How consistent are results across different VLMs (e.g., CLIP variants, BLIP, SigLIP, GPT-4o, Gemini, Claude VLM) and across prompt formulations for label extraction?
- Statistical rigor: Results are reported as point estimates. Are differences statistically significant across multiple random seeds, bootstrapped confidence intervals, and repeated train/test splits?
- Sample size scaling: With only 2,000 policies, how does the performance gap evolve with larger datasets, different train/test ratios, and class imbalance variations?
- Reproducibility and release: Are the dataset, generation prompts, model versions, random seeds, and code publicly released with licenses to enable replication and extension?
- Oracle realism: The oracle assumes perfect knowledge of the generative process and RoofHealth. Can a learnable surrogate (e.g., correctly specified GLM for frequency/severity with latent inference) approximate this upper bound in practice?
- Fairness and bias: RoofHealth is a function of features including CreditScore. How do models (human or agentic) handle potential socio-economic bias, and what fairness/civil rights implications arise in real applications?
- Cost–benefit analysis: What is the economic impact of collecting, storing, and analyzing roof imagery versus gains in predictive performance (ROI, latency, compute cost)?
- Distribution shift: How robust are methods to covariate/label shift (e.g., region-specific roofing materials, climate changes, new building codes) and to real-world image artifacts?
- Generality of latent placement: Beyond images, how do results change when the crucial latent variable is embedded in other modalities (adjuster notes, sensor streams, text reports), or when multiple interacting latent variables exist?
Practical Applications
Immediate Applications
Below is a concise list of applications that can be deployed now, mapped to relevant sectors and accompanied by key dependencies and assumptions.
- Insurance (Property): Roof imagery–augmented underwriting and pricing
- Description: Add a derived “RoofHealth” feature to existing tabular models by extracting signals from aerial or street-view images (e.g., CLIP embeddings, VLM labels). Integrate into GLM/GBM/RF workflows to uplift ranking performance for loss prediction (e.g., normalized Gini).
- Tools/Workflows: Pretrained image encoders (CLIP), lightweight VLMs (e.g., gpt-4o-mini), feature fusion with tabular pipelines, model monitoring with normalized Gini.
- Dependencies/Assumptions: Access to recent high-resolution roof imagery; basic MLOps; legal permissions for image use; image quality variability and geographic coverage.
- Insurance (Claims Operations): Event-driven claims triage using pre/post-event roof imagery
- Description: Prioritize inspections and reserves by scoring roof damage likelihood after storms, combining historical policy features with image-derived condition.
- Tools/Workflows: Batch scoring pipelines; damage-change detection; rules plus ML prioritization.
- Dependencies/Assumptions: Timely imagery acquisition; storm footprint maps; operational SLAs; threshold tuning for heavy-tailed losses.
- Software/Data Science Enablement: Multimodal feature engineering library for tabular + image fusion
- Description: Package the paper’s approach as a reusable Python library/notebook templates to help DS teams incorporate image features into tabular models.
- Tools/Workflows: CLIP feature extraction, clustering/labeling, RF/GBM integration, normalized Gini evaluator.
- Dependencies/Assumptions: Maintained model weights; governance around image preprocessing; reproducible pipelines.
- Human–AI Teaming: Domain-knowledge checklists and agent guardrails
- Description: Introduce prompt/system-level guardrails so DS agents must consider non-tabular modalities and domain latent variables before finalizing models.
- Tools/Workflows: Agent task templates (e.g., “search for latent variables outside tabular data”); review steps; escalation to human experts.
- Dependencies/Assumptions: Organizational buy-in; minimal agent customization; clear escalation paths.
- Academia (Teaching/Training): Coursework and labs on multimodal domain-aware data science
- Description: Use the synthetic dataset to teach students how to identify latent variables and fuse image signals with tabular features.
- Tools/Workflows: Course modules; Kaggle-style labs; grading via normalized Gini; ablation exercises.
- Dependencies/Assumptions: Access to teaching compute; permissive licenses for pretrained models; student familiarity with ML basics.
- Benchmarking & Evaluation (ML Platforms): Synthetic, controllable tasks to probe agent limitations
- Description: Extend DS-bench/MLE-bench with multimodal tasks where key signals reside outside tabular features, benchmarking agents against human baselines.
- Tools/Workflows: Synthetic data generators; challenge suites; leaderboards using normalized Gini.
- Dependencies/Assumptions: Benchmark governance; reproducible seeds; consistent scoring and disclosure policies.
- Procurement/Model Governance (Policy & Compliance within firms): Vendor requirements for multimodal capability
- Description: Update RFPs and model risk standards to require evidence of multimodal ingestion and domain-knowledge incorporation for high-stakes predictions.
- Tools/Workflows: Checklists; validation protocols; documentation of feature provenance.
- Dependencies/Assumptions: Internal policy updates; model risk functions; audit trails.
- UAV/Imagery Vendors (Energy, Construction, Real Estate): “RoofHealth-as-a-Service” API
- Description: Offer an API that returns standardized roof condition scores from aerial imagery for insurers, property managers, and assessors.
- Tools/Workflows: Inference services; SLAs on latency/accuracy; calibration per geography.
- Dependencies/Assumptions: Reliable data pipelines; client integration; legal compliance (privacy, airspace).
- Metrics & Monitoring (Cross-sector DS): Adopt normalized Gini for ranking heavy-tailed targets
- Description: Use normalized Gini alongside AUC and RMSE to monitor rank-quality in claims, fraud, energy outages, and other heavy-tailed tasks.
- Tools/Workflows: Metric modules; dashboards; sensitivity analyses.
- Dependencies/Assumptions: Stakeholder education on metric interpretation; baseline establishment.
Long-Term Applications
These applications require further research, scaling, or development before broad deployment.
- Agentic AI (Software): Domain-aware, multimodal DS agents that discover and acquire missing signals
- Description: Agents that autonomously hypothesize latent variables (e.g., RoofHealth), request/collect appropriate modalities (images, text, sensors), and integrate them into models with explainable fusion.
- Potential Products: “Active sensing” DS agents; multimodal AutoML with ontology-guided retrieval.
- Dependencies/Assumptions: Robust multimodal reasoning; data acquisition orchestration; explainability and safety checks; integration with enterprise data lakes.
- Cross-Sector Expansion (Healthcare, Agriculture, Energy, Finance): Latent-variable inference from non-tabular streams
- Description: Generalize the paper’s mechanism to radiology + EHR (health risk), crop imagery + weather (yield/loss), asset imagery + telemetry (outage risk), satellite photos + POS (retail footfall).
- Potential Products: Sector-specific condition scoring APIs (e.g., “Transformer Health Score”), multimodal risk platforms.
- Dependencies/Assumptions: Domain-specific ontologies; regulatory approvals (HIPAA, GDPR); high-quality multimodal data; bias mitigation.
- Synthetic Data Frameworks (Academia/Industry Consortia): Realistic multimodal benchmarks with controllable latent factors
- Description: Build large, open synthetic suites that mirror hidden-variable challenges across sectors; standardize evaluation protocols.
- Potential Products: Public benchmark hubs; curriculum datasets; testbeds for agents.
- Dependencies/Assumptions: Community governance; dataset documentation; licensing; compute for generation.
- Learning at Scale (Vision/ML): Self-supervised and weakly supervised roof-health models trained on real imagery
- Description: Train robust models that infer RoofHealth across geographies, materials, and conditions, reducing dependence on manual labels or synthetic prompts.
- Potential Products: Foundation models for built-environment assessment; fine-tuned VLMs for structural integrity.
- Dependencies/Assumptions: Large diverse datasets; annotation strategies; domain drift handling; continual learning.
- Explainability & Auditability (Policy/RegTech): Multimodal explanations for underwriting and claims models
- Description: Develop methods that attribute predictions to image regions/features and tabular variables, meeting regulatory scrutiny for fairness and transparency.
- Potential Products: XAI toolkits for multimodal ranking models; audit dashboards.
- Dependencies/Assumptions: Accepted XAI standards; regulator guidance; human factors research on explanation usability.
- Federated & Privacy-Preserving Learning (Insurance, Healthcare): Multimodal modeling without centralized data sharing
- Description: Train across institutions using federated/secure aggregation to protect imagery and PII while improving model robustness.
- Potential Products: Federated multimodal platforms; privacy-enhancing technologies (DP, secure enclaves).
- Dependencies/Assumptions: Partner alignment; network reliability; legal agreements; performance trade-offs.
- Edge AI on Drones/IoT (Energy, Construction): Real-time structural condition scoring
- Description: Run compressed VLMs on drones to assess roof/asset health on-site, feeding scores directly into maintenance/underwriting systems.
- Potential Products: Drone-integrated inference kits; onsite triage workflows.
- Dependencies/Assumptions: Hardware acceleration; battery/compute constraints; safety protocols; model robustness in the wild.
- Fairness & Policy Frameworks (Public Policy): Standards for multimodal risk scoring
- Description: Establish guidelines on equitable use of imagery in pricing and claims (e.g., avoiding socioeconomic proxies), disclosure, and contestability.
- Potential Products: Industry codes of practice; compliance templates; audit programs.
- Dependencies/Assumptions: Multi-stakeholder input; empirical bias assessments; regulator adoption.
- Economic Impact Studies (Industry/Academia): Cost–benefit analysis of multimodal uplift
- Description: Quantify ROI of integrating image-derived features vs. data acquisition/storage costs and operational complexity.
- Potential Products: Decision-support models; procurement playbooks.
- Dependencies/Assumptions: Access to historical outcomes; robust causal analysis; scenario modeling.
- Generalized Multimodal Benchmarks for Agentic AI (ML Ecosystem): Standard tasks testing “beyond-tabular” competence
- Description: Expand DSBench/MLE-bench with multimodal, hidden-variable tasks to drive research on agents that reason over domain cues.
- Potential Products: Annual challenges; leaderboard ecosystems; shared baselines.
- Dependencies/Assumptions: Community engagement; reproducibility; funding for hosting and maintenance.
Glossary
- Actuarial practice: Professional methods and standards used to model insurance risk and losses. "The construction of our synthetic property insurance dataset is grounded in established actuarial practice and empirical research."
- Agentic AI: Autonomous AI systems that plan and execute multi-step workflows, such as automated data science pipelines. "agentic AI that relies on generic analytics workflow falls short of methods that use domain-specific insights."
- Bayes-optimal expected loss: The expected loss under the true generative model that minimizes expected error. "This gives the Bayesâoptimal expected loss and any remaining error reflects only inherent randomness in claims."
- Beta distribution: A continuous probability distribution on [0,1] often used to model proportions or probabilities. "AreaRisk: "
- Bernoulli distribution: A discrete distribution for a single binary outcome, typically parameterized by a success probability. "WallType: "
- CLIP: A pretrained model (Contrastive Language–Image Pretraining) that learns joint representations of images and text. "pretrained CLIP model"
- CLIP embeddings: Vector representations produced by CLIP’s encoders that capture semantic information from images or text. "Using naive clustering of CLIP embeddings as categorical features provides some improvement"
- Compound frequency–severity model: An insurance modeling framework that combines a distribution for claim counts (frequency) with a distribution for claim sizes (severity). "The target outcome, next-year loss, is generated using a compound frequency-severity model."
- FICO distribution: The empirical distribution of US credit scores used as a proxy for financial risk. "CreditScore: drawn from the US FICO distribution (300â850)."
- Gamma distribution: A continuous distribution for positive-valued data, commonly used to model claim severities. "Z_{p,j} \sim \Gamma!\bigl(k=2,\;\theta=\exp(\mu_p)/2\bigr)\,."
- Latent variable: An unobserved variable that influences the data-generating process and outcomes. "The key latent variable is RoofHealth"
- Lognormal distribution: A distribution where the logarithm of the variable is normally distributed, often used for skewed monetary values. "HouseValue: "
- Multimodal data: Data that combines multiple modalities such as images and tabular features. "improve agentic AI's ability to identify and use domain-specific knowledge from multimodal data sources."
- Negative binomial distribution: A discrete distribution for count data that handles overdispersion relative to the Poisson. "N_p \sim \mathrm{NegBinom}\bigl(r=10,\;\text{mean}=\lambda_p\bigr)\,."
- Normalized Gini coefficient: A rank-based performance metric (scaled to [-1,1]) widely used in insurance to evaluate predictive models. "We measure predictive performance using normalized Gini coefficient"
- Oracle model: A benchmark model that has access to the true generative process and latent variables, representing best achievable performance. "Oracle (Best achievable)"
- RoofHealth: A domain-specific categorical variable indicating roof condition (Good, Fair, Bad) that impacts insurance losses. "RoofHealth (latent): compute"
- Text-to-image model: A generative model that synthesizes images from natural language prompts. "we use a text-to-image model with engineered prompts"
- Vision-LLM: A model that jointly processes visual and textual inputs to perform tasks like classification or labeling from images. "vision-LLM gpt-4o-mini"
Collections
Sign up for free to add this paper to one or more collections.