- The paper introduces LRAS, a dual-mechanism framework that combines introspective imitation learning with difficulty-aware reinforcement learning to enhance legal reasoning.
- The paper demonstrates significant performance gains, with up to 32.0% relative accuracy improvements and 22% higher multi-search engagement on challenging legal tasks.
- The paper outlines a robust methodology and extensive experimental validation, highlighting the shift from static reasoning to dynamic, self-regulatory legal inquiry.
LRAS: Advanced Legal Reasoning with Agentic Search
Introduction
The paper "LRAS: Advanced Legal Reasoning with Agentic Search" (2601.07296) addresses critical deficiencies in the current generation of legal LLMs, which traditionally rely on static, parametric "closed-loop thinking." These models exhibit marked limitations in self-introspection and adaptability when confronted with knowledge boundaries in legal queries. The authors diagnose two fundamental failure modes: (1) a deep introspection deficit, resulting in unrecognized knowledge gaps and overconfident hallucinations; and (2) fragility in complex legal reasoning, where neither full retrieval nor static augmentation remedies the performance plateau in deep legal problem-solving. To transition from passive parametric inference to a dynamic, knowledge-seeking paradigm, the authors introduce LRAS: a dual-mechanism agentic search framework blending introspective imitation learning with difficulty-aware reinforcement learning, explicitly engineered for the legal domain.
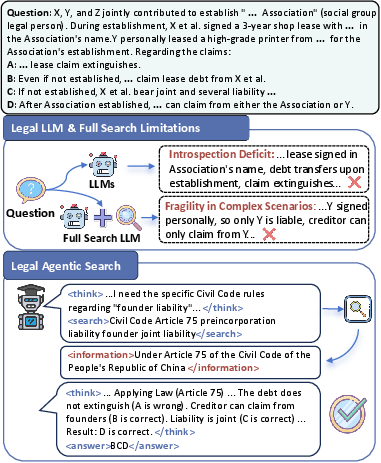
Figure 1: LRAS diverges from conventional legal LLMs by incorporating dynamic search decisions, enabling accurate recognition of knowledge limits and well-grounded conclusion generation.
The formalization of legal agentic search as a sequential decision-making process augmented with external search tools is both precise and appropriate for the domain. The agent, parameterized by policy πθ, iteratively assesses introspective states, initiates information-seeking actions when necessary, and aborts the search trajectory upon sufficient evidence accrual. Analysis of 705 failed legal queries (JEC-QA) reveals that standard LLMs initiate external search in only 28.7% of failure modes, and even when tools are available, 71.3% of errors remain unrectified due to lack of introspection. More critically, information-agnostic strategies (e.g., "Full RAG") show only marginal improvement for shallow queries and are unable to close the deep reasoning gap on complex queries, whereas LRAS's agentic search mechanism achieves a significant jump in performance on such scenarios.
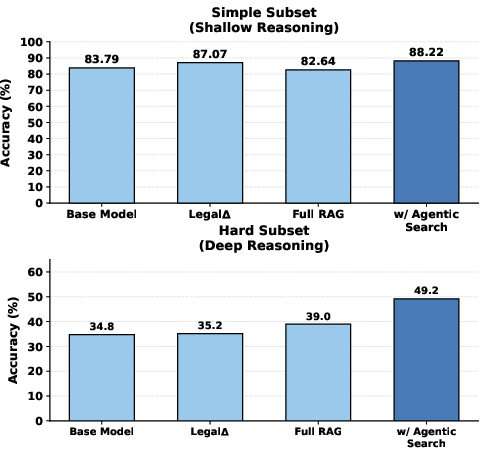
Figure 2: Agentic search confers substantial improvement on difficult (deep reasoning) legal tasks compared to static or passive search approaches.
Methodology
Dual-Mechanism Architecture
LRAS integrates two distinct learning regimes:
- Introspective Imitation Learning: Leveraging uncertainty-driven data curation and expert process emulation, this stage constructs a legal dataset emphasizing ambiguous and challenging questions. Each sample involves rich, step-labeled trajectories (> , <search>, <information>, <answer>), with rigorous annotation and relevance filtering. The agent is trained to first execute internal reasoning, and only invoke knowledge search when it systematically identifies knowledge insufficiency.
>
> 2. Difficulty-aware Reinforcement Learning: Here, the RL agent is trained on a hard-sample-mined dataset, focusing on cases where the SFT baseline fails. Using Group Relative Policy Optimization (GRPO), the agent explores multi-step search strategies with composite rewards balancing accuracy and structural conformance, advancing from reactive correction to directed, multi-hop legal inquiry.
>
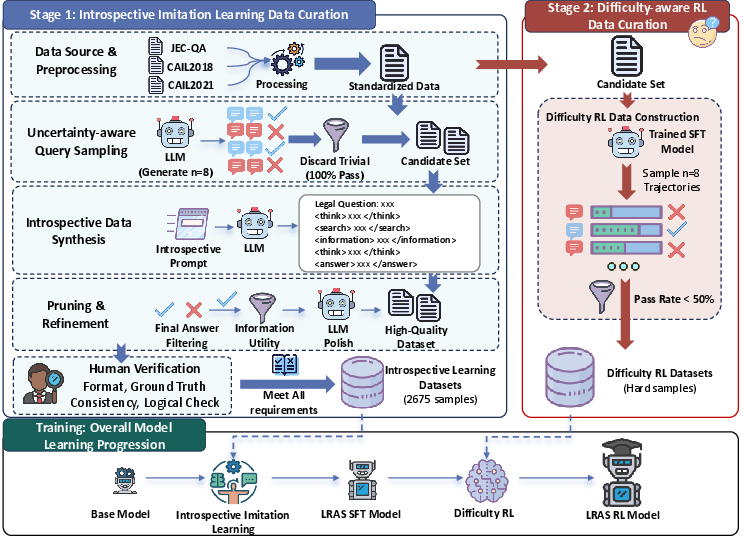 >
> Figure 3: The LRAS framework comprises successive stages of introspective imitation learning data curation and reinforcement learning with hard-case mining, culminating in an autonomous, search-augmented legal agent.
>
> ## Experimental Results
>
> LRAS is comprehensively evaluated on in-distribution (LexEval, LawBench, UniLaw-R1-Eval) and OOD (DiscLaw) legal benchmarks. Across all tested infrastructures (Qwen3 4B, 8B, 14B), LRAS substantially outperforms both base models and current legal LLMs:
>
> - Relative accuracy boosts range from 8.2% to 32.0%.
>
> - On the hardest benchmark (DiscLaw OOD), LRAS-RL reaches 75.66% accuracy (14B), outperforming LegalΔ-14B by 13.6% relative margin.
>
> - Even the smallest configuration (4B) surpasses larger competitive baselines, demonstrating the criticality of active inquiry over scale alone.
>
> Notably, RL-stimulated agentic search behaviors manifest in elevated multi-search engagement rates (49.7% for 4B RL), directly translating to 22% higher accuracy on tasks necessitating active multi-step search compared to SFT variants.
> 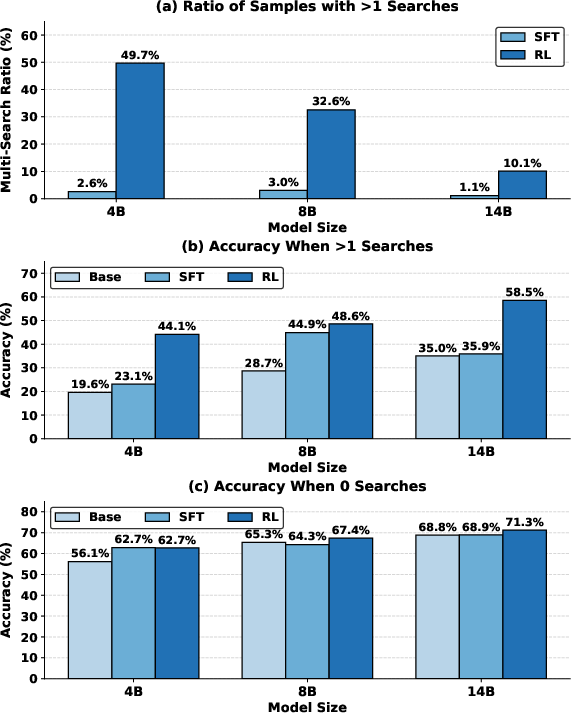 >
> Figure 4: RL-based agentic models perform more multi-search steps and deliver higher accuracy on complex queries requiring iterative information retrieval.
>
> ## Introspection and Agentic Search: Qualitative Analysis
>
> Systematic ablations on introspection design show that deeper self-reflection stages ("Level-3") yield consistent, significant improvements (+4.16% on average, +7.88% on UniLaw deep tasks), supporting the hypothesis that explicit introspection is crucial for non-trivial legal reasoning.
>
> The provided case study highlights the qualitative leap induced by agentic search. While baseline models hallucinate deadlines or fail to verify statutory details, LRAS-RL correctly identifies its knowledge boundaries, retrieves the precise legal provision, and outputs the correct answer with explicit evidence grounding.
> 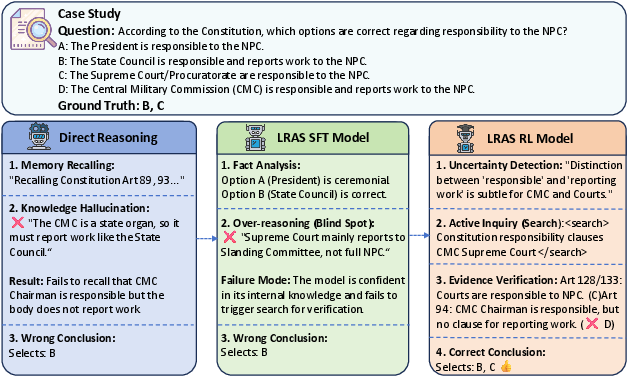 >
> Figure 5: Detailed comparative reasoning trajectories, illustrating successful knowledge boundary detection and search invocation by LRAS-RL.
>
> ## Dataset Construction and Behavioral Dynamics
>
> The dataset supports a diverse distribution of multi-turn, search-intensive trajectories, with search calls, conversation turns, and response lengths reflecting the complexity needed for high-fidelity legal reasoning.
> 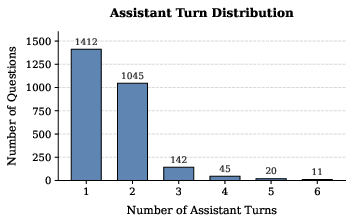 >
> Figure 6: Distribution of assistant turns in SFT data, supporting complex, multi-stage reasoning trajectories.
>
> ## Implications and Future Directions
>
> LRAS's explicit coupling of introspection and agentic search signifies a paradigm shift for legal AI. The robust generalization to OOD legal scenarios, and the observed improvements across all model scales, demonstrate that the principal limitation for legal LLMs is not parametric scale but the absence of dynamic, self-regulatory inquiry mechanisms. This approach sets the groundwork for trustworthy, verifiable AI agents in domains demanding explicit evidence chains and procedural precision.
>
> Pragmatically, robust agentic search mechanisms increase reliability, reduce hallucination rates, and enable deployment in high-stakes environments such as legal advice, regulatory compliance, and evidence-based judicial support. Theoretically, these findings reinforce the importance of integrating external tool usage, meta-reasoning, and adaptive search into LLMs for any domain with knowledge volatility or high epistemic demands.
>
> Areas for future refinement include augmenting the interaction horizon for extremely complex legal scenarios, developing mechanisms for robust handling of tool-induced errors (e.g., retrieval noise, statute incompleteness), and exploring more granular reward engineering for precise procedural alignment.
>
> ## Conclusion
>
> LRAS demonstrates that a dual-mechanism, agentic search framework centered on introspective reasoning and difficulty-aware RL yields superior legal reasoning models able to dynamically engage with knowledge boundaries and orchestrate complex search strategies. These findings underscore that the future of domain-specialized AI lies in adaptive, meta-cognitive reasoning integrated with external information-seeking competencies.