LLM-ForcedAligner: A Non-Autoregressive and Accurate LLM-Based Forced Aligner for Multilingual and Long-Form Speech
Abstract: Forced alignment (FA) predicts start and end timestamps for words or characters in speech, but existing methods are language-specific and prone to cumulative temporal shifts. The multilingual speech understanding and long-sequence processing abilities of speech LLMs (SLLMs) make them promising for FA in multilingual, crosslingual, and long-form speech settings. However, directly applying the next-token prediction paradigm of SLLMs to FA results in hallucinations and slow inference. To bridge the gap, we propose LLM-ForcedAligner, reformulating FA as a slot-filling paradigm: timestamps are treated as discrete indices, and special timestamp tokens are inserted as slots into the transcript. Conditioned on the speech embeddings and the transcript with slots, the SLLM directly predicts the time indices at slots. During training, causal attention masking with non-shifted input and label sequences allows each slot to predict its own timestamp index based on itself and preceding context, with loss computed only at slot positions. Dynamic slot insertion enables FA at arbitrary positions. Moreover, non-autoregressive inference is supported, avoiding hallucinations and improving speed. Experiments across multilingual, crosslingual, and long-form speech scenarios show that LLM-ForcedAligner achieves a 69%~78% relative reduction in accumulated averaging shift compared with prior methods. The checkpoint and inference code will be released later.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
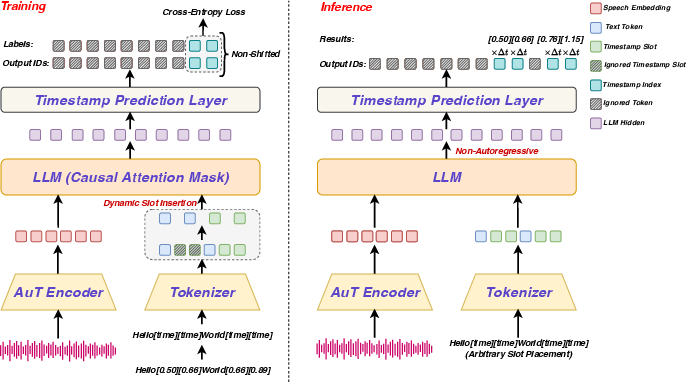
This paper introduces a new way to match spoken audio to the exact words in its transcript, a task called “forced alignment.” Think of karaoke: the song plays, and the lyrics light up at the right moment. Forced alignment figures out the start and end time for each word or character so the highlighting is accurate. The authors built a system called LLM-ForcedAligner that uses a LLM designed for speech to make this timing more accurate, work across many languages, and handle long recordings.
What questions are the researchers trying to answer?
They aim to solve three main problems:
- How can we get precise start and end times for each word without building separate, language-specific systems?
- How can we avoid small timing errors that add up and become big mistakes in long audio (like podcasts or lectures)?
- How can we make timing prediction fast and avoid “hallucinations” (fake or extra timestamps) that some LLMs produce when they guess one token at a time?
How does their method work?
Here’s the approach in everyday terms:
- The timeline as numbered ticks: They treat time as a series of small steps (like ticks on a ruler) — for example, every 80 milliseconds is one tick. Each word’s start and end time is just the tick number where it begins and ends.
- Slots in the transcript: They insert special tokens (like “[time]”) into the text where the start and end times should go. Imagine the transcript has blanks after each word for “start time” and “end time.” The model’s job is to fill in those blanks with the right tick numbers.
- Looking back, not ahead (causal attention): During training, the model learns to fill each blank using the audio plus what it has already seen in the transcript, not future words. This helps the model stay consistent and avoids messy, out-of-order predictions.
- Dynamic slot insertion: To make the system flexible, they don’t always insert time slots for every single word during training. Sometimes they skip slots randomly. This teaches the model to handle timestamps at any positions a user might request later.
- All-at-once predictions (non-autoregressive): Instead of predicting one timestamp at a time in a slow chain (which can cause hallucinations and delays), the model predicts all the needed timestamps in one go. This makes it faster and more reliable.
Under the hood, they combine:
- A speech encoder (Audio Transformer, or AuT) that turns audio into a sequence of features every 80 ms.
- A multilingual LLM (Qwen3-0.6B) that understands text across many languages.
- A simple output layer that picks the correct time tick for each “[time]” slot.
They trained the system on 56,000 hours of multilingual audio (10 languages), mostly using “pseudo-labels” — timestamps generated by an existing aligner (MFA). Even though those labels aren’t perfect, the new system learns to smooth out their errors.
What did they find, and why does it matter?
- Much lower timing drift: On many languages and very long audio (up to 5 minutes), their system reduced overall timing error by about 69–78% compared to previous methods. In simpler terms, their timestamps stay much closer to the true start and end times, even in long recordings where small errors usually pile up.
- Works across languages: Because it doesn’t rely on language-specific phoneme dictionaries, it can handle Chinese, English, French, German, Italian, Japanese, Korean, Portuguese, Russian, and Spanish without switching models.
- Faster and safer predictions: By predicting timestamps all at once, it avoids hallucinations (extra, wrong timestamps) and speeds up inference. There’s a small trade-off in speed (a slightly higher real-time factor), but the accuracy gains are significant.
- Better than the teacher: Even though it learned from MFA’s pseudo-labels, it didn’t simply copy MFA’s mistakes. On human-labeled test data, especially long-form speech, it corrected timing drift and performed better than MFA-based baselines.
Why is this important?
Accurate forced alignment helps with:
- Creating subtitles that appear exactly when words are spoken
- Editing audio and video (finding the exact moment a word occurs)
- Building and cleaning large speech datasets
- Improving text-to-speech timing and prosody (natural rhythm and emphasis)
- Language learning tools that highlight words as they’re spoken
Because this system works for many languages and long recordings, it can be used in global apps, podcasts, lectures, and movies without complicated language-specific setups.
Final thoughts: What’s the impact?
LLM-ForcedAligner shows that LLMs for speech can do more than recognize words — they can pinpoint when each word starts and ends with high accuracy. By turning forced alignment into a slot-filling task and predicting all timestamps at once, the system avoids common pitfalls (like drift and hallucinations), works across languages, and handles long audio smoothly.
In the future, this could make automatic subtitles more accurate, speed up audio/video editing, and improve speech research tools. The authors note some limits (human labels aren’t perfect, and more balanced data across languages could help), but the approach is a major step toward reliable, multilingual, long-form speech alignment.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of unresolved issues, missing analyses, and open questions that future work could address to strengthen and extend LLM-ForcedAligner.
- Dependence on MFA pseudo-labels and limited human annotations: model is trained primarily on MFA-generated timestamps; human-labeled evaluation is only in Chinese, leaving uncertainty about real-world performance in other languages and scripts. Collect and use multilingual human-annotated datasets to validate generalization and correct MFA biases.
- Ambiguity of “crosslingual” claims vs evaluation: “Mixed-Crosslingual” concatenations do not test true crosslingual alignment (audio in one language with transcript in another, or translation alignment). Design experiments with mismatched-language audio/transcript pairs and translation alignment tasks.
- Code-switching within utterances: robustness to intra-utterance language switching is not analyzed. Evaluate on code-switch corpora and quantify performance by switch frequency and switch positions.
- Transcript quality sensitivity: no quantitative study of how WER, punctuation errors, tokenization differences (e.g., segmentation in Chinese/Japanese), or partial transcript mismatches affect alignment. Benchmark AAS vs transcript WER and segmentation schemes (word-level vs character-level) across languages.
- Monotonicity and validity constraints: the model independently predicts start and end indices without explicit constraints that enforce start < end, non-overlap, and global monotonic increase across tokens. Explore constrained decoding (e.g., CRF/DP layers, differentiable monotonicity losses) and report rates of invalid or non-monotonic outputs.
- Hallucination avoidance claims: non-autoregressive decoding is claimed to “avoid hallucinations” but no metrics quantify timestamp hallucinations, extras, or omissions. Define and measure hallucination/error types (extra/missing timestamps, out-of-range indices) and compare NA vs AR.
- Timestamp resolution trade-offs: timestamps are discretized at 80 ms, with limited analysis beyond AAS. Investigate continuous/regression heads, adaptive or multi-resolution schemes, and effects on downstream tasks requiring finer boundary precision (e.g., phoneme-level TTS).
- Long-context scalability and context limits: experiments stop at 300 s and the classifier supports up to 500 s (3,750 classes). It is unclear how the method scales to longer audio given LLM context windows and class limits. Develop streaming/chunked inference and hierarchical context mechanisms with cross-chunk consistency.
- Silence and non-speech handling: behavior at leading/trailing silence, pauses, music, laughter, or overlapped background sounds is not characterized. Add silence-aware training, explicit non-speech tokens, and evaluate across noise types and SNRs for all languages.
- Multi-speaker and overlapped speech: no consideration of diarization or speaker-aware alignment in meetings or conversations where overlapping speech occurs. Integrate speaker embeddings/diarization and evaluate on multi-speaker corpora.
- Slot token design: a single
[time]token is used for both start and end slots, which could conflate roles. Compare distinct[start_time]/[end_time]tokens and study their impact on accuracy and monotonic validity. - Slot placement sensitivity: the method allows user-defined slot insertion but does not analyze performance vs slot density/placement (e.g., after punctuation, subwords). Quantify AAS as a function of slot location heuristics and recommend best practices.
- Boundary-level error analysis: AAS aggregates start and end errors together without reporting separate distributions or systematic biases (e.g., delayed ends for long vowels). Provide start vs end error histograms, duration-dependent analyses, and drift over time.
- Domain-generalization: while datasets span several scenarios, results are not broken out by domain (audiobooks, podcasts, meetings). Provide domain-wise evaluation and domain adaptation strategies (e.g., adapters, prompt conditioning).
- Language imbalance and low-resource performance: training is uneven across languages; higher AAS outside Chinese/English suggests disparity. Apply balanced sampling, language-specific adapters, or meta-learning and measure improvements in low-resource languages.
- Robustness to tokenization schemes and scripts: specifics of word vs character segmentation per language are not detailed, and impacts are not quantified. Systematically compare segmentation strategies for languages with/without spaces and scripts with complex morphology.
- Downstream utility validation: claims of improved FA for TTS corpus building, subtitling, or prosody analysis are not empirically validated. Demonstrate measurable gains in downstream tasks (e.g., TTS duration/prosody, subtitle timing quality).
- Metric diversity: only AAS is reported; other alignment metrics (boundary precision/recall/F1, mean signed error, coverage) and human perceptual evaluations are missing. Adopt richer metrics and user studies to assess practical alignment quality.
- Error calibration and confidence: the timestamp head outputs distributions, but uncertainty measures and calibration are unused. Provide confidence scores, calibrate probabilities, and explore thresholding for robust dataset curation.
- Alternative training objectives: only cross-entropy at slot positions is used. Evaluate structured losses (sequence-level constraints), contrastive alignment, multi-task objectives with ASR/CTC, and consistency regularization to reduce systematic shifts.
- Encoder/LLM component sensitivity: limited analysis of different speech encoders and LLM sizes beyond coarse parameter scaling. Compare encoders (frame rates, pretraining), LLM variants (context size, multilingual capacity), and their interaction with timestamp resolution.
- Streaming/online alignment: feasibility of real-time/low-latency forced alignment is not explored despite RTF reporting. Investigate incremental slot prediction with partial audio contexts and latency-accuracy trade-offs.
- Resource and deployment constraints: memory footprint, GPU/CPU requirements, and throughput under typical production settings are not characterized. Provide profiling, batching strategies, and deployment recipes.
- Reproducibility and data transparency: checkpoints and code are “to be released later,” and dataset composition is partly internal. Release models, training scripts, and detailed dataset manifests for reproducible evaluation across languages and domains.
- Post-processing and smoothing: no post-processing is described to correct local anomalies (e.g., brief non-monotonicities). Assess simple smoothing/constraint-enforcing post-processors and their impact on AAS and validity.
- Handling out-of-range predictions: the classifier supports up to 500 s; safeguards for mapping indices beyond audio length or padding scenarios are not described. Implement masking and report frequency of out-of-range outputs.
- Phoneme-level alignment: the approach targets word/character timestamps; phoneme-level FA (critical for TTS) is not addressed. Explore phoneme-slot prediction without lexicons or hybrid approaches that bridge phoneme semantics with multilingual LLMs.
- Hyperparameter robustness: dynamic slot insertion is tuned at ~50% but not exhaustively across languages/tasks. Conduct systematic sweeps (per language/domain) and provide guidelines for setting insertion rates and timestamp durations.
Practical Applications
Below are actionable applications that follow from the paper’s findings and method (LLM-ForcedAligner), organized by deployment horizon. Each item specifies likely sectors, potential tools/workflows, and key assumptions or dependencies that affect feasibility.
Immediate Applications
- Multilingual, long-form subtitling and captioning for video, broadcast, and OTT
- Sectors: media and entertainment, accessibility, public sector communications
- Tools/workflows: ASR → insert
"[time]"slots in transcripts → LLM-ForcedAligner for start/end times → SRT/VTT generation; integration as an API/CLI or NLE plug-in (e.g., Adobe Premiere, DaVinci Resolve) for post-production caption retiming at scale, including mixed-language content - Why now: Non-autoregressive inference, language-agnostic design (no phoneme lexicons), strong long-form performance up to 300s, and 66–78% lower AAS than prior methods
- Assumptions/dependencies: Availability of a reasonably accurate transcript (manual or ASR), model checkpoint/code availability, GPU for fast batch processing, timestamp resolution of 80 ms suffices for broadcast-grade captions
- Corpus building, cleaning, and segmentation for ASR/TTS datasets
- Sectors: AI/ML infrastructure, speech tech companies, academic labs
- Tools/workflows: Automated validation of audio–text pairs; pruning and segmenting long audio into sentence/utterance units using aligned word/character boundaries; quality gates based on alignment dispersion stats; improved dataset reliability across 10 supported languages
- Why now: Slot-filling alignment reduces cumulative shift in long audio, improving segmentation precision and downstream model training
- Assumptions/dependencies: Access to raw corpora and transcripts; adherence to data privacy/licensing; reliance on MFA-style pseudo-labels for initial bootstrapping is acceptable for large-scale operations
- Word-/character-level highlighting and navigation in meeting notes and recordings
- Sectors: enterprise productivity, developer tools, knowledge management
- Tools/workflows: Meeting transcription (ASR) → slot-based alignment to provide precise word-level playback; clickable transcripts; smart jump-to segments; alignment-aware summarization windows
- Why now: Near-real-time offline processing (low RTF ~0.016) and stable long-context alignment
- Assumptions/dependencies: Good ASR quality; mixed-speaker content may need separate diarization (not covered by this method)
- Prosody and duration analysis for TTS model development and QA
- Sectors: speech synthesis (TTS) R&D and product teams
- Tools/workflows: Extract per-word/character durations to train duration models; detect systematic timing errors; audit prosody drift across long utterances
- Why now: Direct, language-agnostic alignment without lexicon engineering; improved long-range temporal stability vs CTC/CIF-style aligners
- Assumptions/dependencies: 80 ms frame resolution is suitable for duration modeling at word/character level; phoneme-level supervision not required but may be desired for some pipelines
- Multilingual podcast/audiobook post-production and content search
- Sectors: publishing, podcast platforms, audiobooks, search/SEO
- Tools/workflows: Accurate timecodes for chapters/segments; text-based clip extraction; highlight reels; content compliance scans (e.g., brand mentions) tied to exact timestamps
- Why now: Alignment robustness in long-form content, cross-language robustness, reduced hallucinations
- Assumptions/dependencies: Transcript availability; performance may vary with heavy background music/noise; long recordings can be chunked ≤300s windows
- Subtitle translation workflows with precise source timings
- Sectors: localization, media/globalization services
- Tools/workflows: Align source-language transcript to source audio to obtain accurate timecodes → machine/human translation uses these timecodes for target-language captions
- Why now: Language-agnostic alignment means one system for many languages, simplifying production pipelines
- Assumptions/dependencies: Alignment is performed on the source-language transcript; target-language reflow still requires subtitle fitting tools
- Compliance, audit, and redaction with time-synchronized transcripts
- Sectors: broadcast compliance, legal tech, enterprise governance
- Tools/workflows: Locate sensitive terms and redact with accurate time boundaries; check ad length and content timing constraints; generate audit trails
- Why now: Lower timestamp shift improves trust in automated redaction and audit logs
- Assumptions/dependencies: Reliable transcripts; content with overlapping speakers may need diarization; policy teams must set acceptance thresholds (e.g., AAS limits)
- Education and language learning with word-level timing
- Sectors: edtech, accessibility
- Tools/workflows: Word-level karaoke-style highlighting for lectures; pronunciation pacing analysis; interactive replay at difficult segments
- Why now: Stable alignment for long lectures across multiple languages; minimal engineering per language
- Assumptions/dependencies: Accurate transcripts; 80 ms granularity usually sufficient for learner feedback at word/character level
- Enterprise search over spoken content with timestamped entities
- Sectors: finance (earnings calls), healthcare admin, customer support
- Tools/workflows: Timestamped entity/keyword indexing for call centers and earnings calls; link search results directly to precise audio spans
- Why now: Reduced long-range timestamp drift improves click-to-audio precision
- Assumptions/dependencies: Domain-specific ASR may be required for specialized terminology; privacy and compliance controls for sensitive speech data
- Developer-facing SDK/API for language-agnostic forced alignment
- Sectors: software/tooling
- Tools/workflows: Dockerized service or Python SDK that accepts audio + transcript with
"[time]"slots and returns aligned indices/timestamps; drop-in alternative to CTC/DTW aligners - Why now: Method is architecture-ready; integrates with popular ASR stacks (e.g., Whisper, NeMo) and media tooling
- Assumptions/dependencies: Release of checkpoints/inference code; licensing compatibility for Qwen/AuT components; GPU/CPU performance targets
Long-Term Applications
- Streaming, low-latency live captioning with stable word timings
- Sectors: live broadcast, conferencing, AR/VR events
- Tools/workflows: Incremental slot filling with streaming ASR; adaptive context windows to support very long sessions
- Why later: Current results demonstrated on up to 300 s windows and offline inference; streaming orchestration and state management require further research
- Assumptions/dependencies: Robust chunk stitching, latency-aware decoding, and memory-efficient long-context handling
- Fully crosslingual alignment between audio and translated transcripts
- Sectors: localization, media globalization, international policy communications
- Tools/workflows: Align target-language subtitles directly to source audio (beyond using source timings); automatic re-timing while respecting target-language segmentation
- Why later: The paper aligns same-language transcripts; direct alignment of translations to source audio needs modeling beyond the presented method (semantic/MT-aware alignment)
- Assumptions/dependencies: Multimodal semantic alignment across languages; confidence calibration to avoid drift
- Meeting analytics with robust diarization-aware alignment
- Sectors: enterprise collaboration, legal depositions, healthcare encounters
- Tools/workflows: Speaker-attributed word timings; analysis of talk time, interruptions, pauses, and turn-taking tied to exact timestamps
- Why later: Current method does not perform speaker diarization; integrating diarization and robust overlapping-speech handling is a separate module
- Assumptions/dependencies: High-quality diarization; noise/overlap robustness
- Feature-complete alignment for very long media (movies, TV series, multi-hour recordings)
- Sectors: film/TV post-production, archives/digital libraries
- Tools/workflows: Hierarchical alignment (scene → shot → sentence) with minimal drift over hours; automated spotting; large-context memory management
- Why later: Paper demonstrates up to 300 s; scaling to hour(s) requires hierarchical chunking, drift correction, and compute/memory optimizations
- Assumptions/dependencies: Efficient long-context scheduling; periodic anchor points and re-synchronization
- Music/lyrics alignment and prosody-aware lyric timing
- Sectors: music streaming, karaoke, creator tools
- Tools/workflows: Lyric-to-audio alignment with beat/prosody awareness; timecodes for syllables/words; content moderation in music
- Why later: Authors note future work on music; music differs from speech (sustained vowels, rhythm, instrumentation) and may require specialized encoders/training data
- Assumptions/dependencies: Music-domain pretraining; beat/tempo features; possibly finer than 80 ms resolution
- Phoneme-level and subword alignment without language-specific lexicons
- Sectors: TTS, phonetics research, speech therapy
- Tools/workflows: Extend slot-filling to phoneme/subword slots for higher temporal precision; better control over duration models
- Why later: Current approach operates at word/character with 80 ms frames; phoneme-level accuracy and consistency across languages need additional modeling/data
- Assumptions/dependencies: Phoneme inventories or learned subword acoustics; finer time resolution (e.g., 20–40 ms)
- On-device, privacy-preserving alignment for mobile and edge
- Sectors: consumer productivity, regulated industries (healthcare, finance)
- Tools/workflows: Quantized/distilled models running locally to avoid cloud data transfer; offline captioning and alignment
- Why later: Model size (~0.9B with AuT encoder) and compute needs suggest further compression/distillation
- Assumptions/dependencies: Model compression (quantization, pruning), efficient audio encoders, hardware acceleration
- Policy and standards for caption accuracy and timing quality
- Sectors: regulators, public broadcasters, accessibility standards bodies
- Tools/workflows: Benchmarks and acceptance criteria (e.g., AAS thresholds per content type/language); procurement guidelines for language-agnostic aligners; audit tooling
- Why later: Requires consensus on metrics and thresholds, broad multilingual validation, and integration with regulatory frameworks
- Assumptions/dependencies: Open evaluation datasets beyond Chinese; stakeholder alignment on measurable caption quality targets
Common assumptions and dependencies across applications
- Transcript quality: The method assumes a transcript exists; alignment quality degrades with heavily erroneous transcripts.
- Model availability: Public release of checkpoints/inference code and compatible licenses for Qwen/AuT components.
- Compute: GPU recommended for low RTF; CPU-only feasibility depends on future optimization.
- Language coverage: Trained on 10 languages; performance on other languages may require additional data or fine-tuning.
- Granularity: 80 ms frame resolution is sufficient for many applications; sub-50 ms needs may require retraining with finer discretization and/or encoder changes.
- Domain robustness: No explicit diarization/overlap handling; noisy or music-heavy content may need complementary modules (VAD, denoising, diarization).
- Privacy/compliance: Audio data handling must follow applicable laws/regulations (e.g., HIPAA/GDPR) in enterprise/healthcare/legal use cases.
Glossary
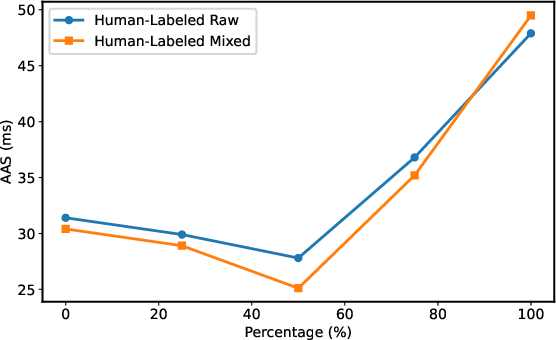
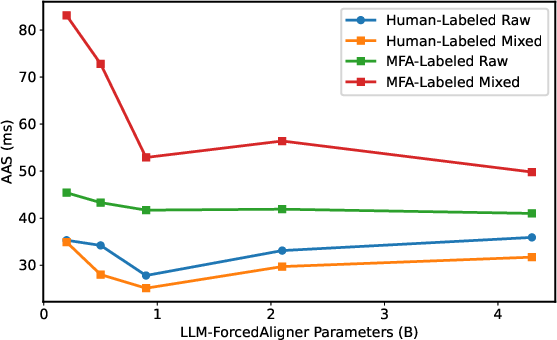
- Accumulated averaging shift (AAS): Metric for average timestamp deviation across slots; lower is better. "We use accumulated averaging shift (AAS) to measure the performance of timestamp prediction"
- Adam optimizer: Adaptive gradient-based optimization algorithm commonly used to train neural networks. "jointly optimized using the Adam optimizer with a warm-up scheduler"
- Audio Transformer (AuT): A transformer-based speech encoder producing frame-level speech embeddings. "The speech encoder in LLM-ForcedAligner is from the Audio Transformer (AuT)"
- Autoregressive decoding: Sequential generation where each output depends on previous outputs. "avoiding hallucinations compared with autoregressive decoding"
- Causal attention masking: Attention constraint allowing tokens to attend only to past (and current) positions. "During training, causal attention masking with non-shifted input and label sequences allows each slot to predict its own timestamp index"
- Causal training: Training setup where outputs are predicted with access only to current and prior context. "we adopt causal training with the output ID and label sequences non-shifted"
- Connectionist temporal classification (CTC): Loss and alignment method for sequence labeling without frame-level alignment supervision. "Connectionist temporal classification (CTC) is a common end-to-end FA method"
- Continuous integrate-and-fire (CIF): Alignment mechanism integrating frame weights and emitting when a threshold is reached. "Continuous integrate-and-fire (CIF) predicts a weight for each encoder output frame"
- Crosslingual: Involving multiple languages within the same sample or model usage. "multilingual, crosslingual, and long-form speech scenarios"
- Dynamic programming: Optimization technique solving complex problems via subproblems with overlapping structure. "employing dynamic programming to identify the optimal path that aligns with the text sequence within constrained search paths"
- Dynamic slot insertion: Training strategy that randomly inserts timestamp slots to improve generalization and arbitrary-position prediction. "Dynamic slot insertion enables FA at arbitrary positions."
- Dynamic time warping (DTW): Algorithm aligning time series by non-linearly stretching/compressing sequences. "using dynamic time warping (DTW), thereby obtaining word-level timestamps by aggregating phoneme-level timestamps"
- End-to-end models: Systems trained to map input to output directly without handcrafted intermediate stages. "Existing FA methods can be broadly categorized into two main groups: traditional hybrid systems and end-to-end models"
- Emission probabilities: Probabilities of output tokens/labels given acoustic frames used for alignment. "achieving alignment by computing emission probabilities."
- Fire event: The CIF trigger when accumulated weight exceeds a threshold, producing an aligned embedding. "When the accumulated weight exceeds a threshold, a fire event is triggered"
- Forced alignment (FA): Estimating word/character start and end timestamps given speech and transcript. "Forced alignment (FA) predicts start and end timestamps for words or characters in speech"
- Gaussian Mixture Model–Hidden Markov Model (GMM–HMM): Hybrid acoustic modeling framework combining GMM emissions with HMM state dynamics. "a hybrid Gaussian Mixture Model–Hidden Markov Model (GMM–HMM) framework"
- Kaldi: Open-source speech recognition toolkit used for building acoustic models and aligners. "build GMM–HMM acoustic models based on Kaldi"
- Monotonic path search: Constrained alignment search that enforces time-ordered progression. "a process of calculating local acoustic similarities followed by a monotonic path search"
- Montreal Forced Aligner (MFA): Open-source, trainable tool for aligning speech to transcripts. "we adopt pseudo-timestamp labels generated by MFA"
- NeMo Forced Aligner (NFA): NVIDIA’s CTC-based aligner for word/phoneme alignment. "CTC-based NeMo forced aligner (NFA) requires language-specific lexicons"
- Next-token prediction paradigm: Standard LLM objective of predicting the following token given context. "directly applying the next-token prediction paradigm of SLLMs to FA results in hallucinations and slow inference"
- Non-autoregressive decoding: Parallel prediction for all outputs without depending on previously generated outputs. "enables non-autoregressive decoding, completely avoiding hallucinations compared with autoregressive decoding and achieving faster speed."
- Non-monotonic hallucinations: Out-of-order or spurious timestamp generations violating temporal order. "Such a paradigm is susceptible to temporal non-monotonic hallucinations and incurs substantial inference latency."
- Real-time factor (RTF): Ratio of inference time to audio duration; lower is faster. "while incurring only a slight increase in real-time factor (RTF)."
- Scaled-CIF: Post-processing variant of CIF adjusting timings to mitigate systematic delays. "Although post-processing such as scaled-CIF and fire-delay can partially alleviate this issue"
- Semantic-boundary-aware alignment: Alignment that respects meaningful linguistic units rather than purely acoustic boundaries. "extends conventional purely acoustic, phoneme-level alignment to semantic-boundary-aware, character-level or word-level alignment."
- Slot-filling paradigm: Casting alignment as filling special timestamp slots within the transcript. "we propose LLM-ForcedAligner, reformulating FA as a slot-filling paradigm"
- Speech embeddings: Vector representations of speech frames produced by an encoder. "Conditioned on the speech embeddings and the transcript with slots, the SLLM directly predicts the time indices at slots."
- Speech LLMs (SLLMs): LLMs augmented to process speech and text jointly. "The multilingual speech understanding and long-sequence processing abilities of speech LLMs (SLLMs) make them promising for FA"
- Timestamp indices: Discrete time-step labels representing quantized timestamps. "timestamps are treated as discrete indices"
- Timestamp prediction layer: Output layer that classifies each slot into a discrete time index. "and the timestamp prediction layer is a single linear layer with 3,750 output timestamp classes"
- Viterbi decoding: Dynamic programming algorithm to find the most likely state sequence in HMMs. "computing the timestamps via Viterbi decoding for frame-level phoneme-to-text alignment paths"
- Warm-up scheduler: Learning-rate schedule that ramps up the rate before standard training decay. "using the Adam optimizer with a warm-up scheduler"
- WhisperX: Alignment toolkit combining phoneme recognition with DTW for time-accurate transcription. "WhisperX employs a lightweight end-to-end phoneme recognition model to perform frame-level phoneme classification on speech"
Collections
Sign up for free to add this paper to one or more collections.