- The paper introduces FuseSearch, a reinforcement learning-based framework for adaptive parallel tool execution that improves code localization accuracy while reducing redundant tool usage.
- The paper demonstrates that dynamic parallel execution with dual-metric optimization boosts file-level and function-level F1 scores and achieves significant speedups.
- The paper shows that efficiency-driven training and adaptive tool invocation reduce inference turns and token usage, enhancing automated software engineering pipelines.
Learning Adaptive Parallel Execution for Efficient Code Localization
Introduction
Code localization remains a primary bottleneck in automated software engineering pipelines due to the need for agents to identify relevant source code entities for subsequent issue resolution. Existing LLM-based localization agents predominantly rely on sequential tool execution, which, under constrained interaction budgets, leads to either incomplete contextual acquisition (information starvation) or significant computational redundancy. The study introduces FuseSearch, a code localization framework that fundamentally shifts the quality-efficiency trade-off by learning adaptive parallel execution via reinforcement learning (RL), explicitly balancing localization accuracy and tool usage efficiency. Unlike prior approaches that enforce fixed parallelism or sequential search strategies, FuseSearch dynamically modulates the degree of parallel tool invocation per turn based on evolving context.
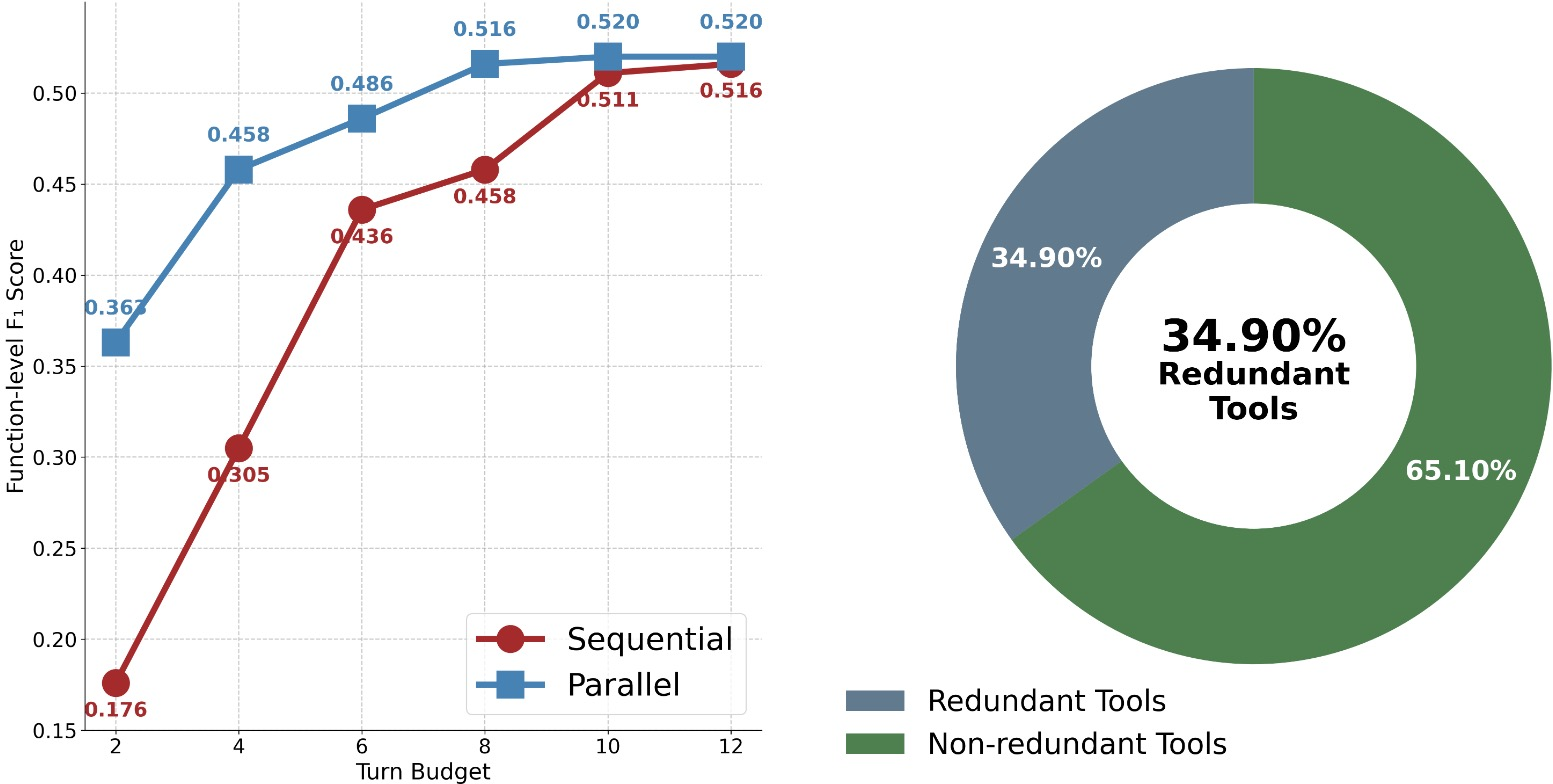
Figure 1: Parallel execution mitigates information starvation, but naive parallelization yields a 34.9% redundancy rate across tools.
FuseSearch Framework
FuseSearch adopts three language-agnostic, read-only tools (grep, glob, read_file), eschewing code graph construction or language-dependent parsing. This minimalism ensures immediate applicability across diverse codebases and focuses the agent policy on execution strategy rather than machinery.
Parallel execution is enabled by allowing multiple tool invocations per turn, all executed concurrently and aggregated before the next action. In prevailing sequential paradigms, excessive turn limits lead to poor context gathering, while fixed parallel tool enforcement yields redundant, uninformative tool calls (as high as 34.9% redundancy).
Dual-Metric Optimization: Quality and Efficiency
A central innovation is the tool efficiency metric (e), defined as the mean ratio of novel information gain per tool call. Agents are jointly optimized for file-level and function-level F1 (reflecting localization quality) and e, which quantifies information novelty. The dual-objective RL reward function is:
R(τ)=α⋅F1(τ)+γ⋅(F1(τ)⋅e(τ))
This objective captures both the necessity for high accuracy and the reduction of redundant exploration, penalizing empty or duplicate tool invocations.
Training Pipeline
FuseSearch is trained through a two-stage approach:
- Supervised Fine-Tuning (SFT): Trajectories for SFT are generated with explicit parallel tool usage (2-8 tools/turn) and filtered to ensure both high F1 and high e (joint metric filtering).
- Reinforcement Learning (RL): Group Relative Policy Optimization (GRPO) further refines the policy, using the dual-objective reward to encourage strategic adaptive parallelism.
This pipeline yields compact Qwen3 models (4B and 30B), which, after RL, demonstrate both strong localization and efficiency.
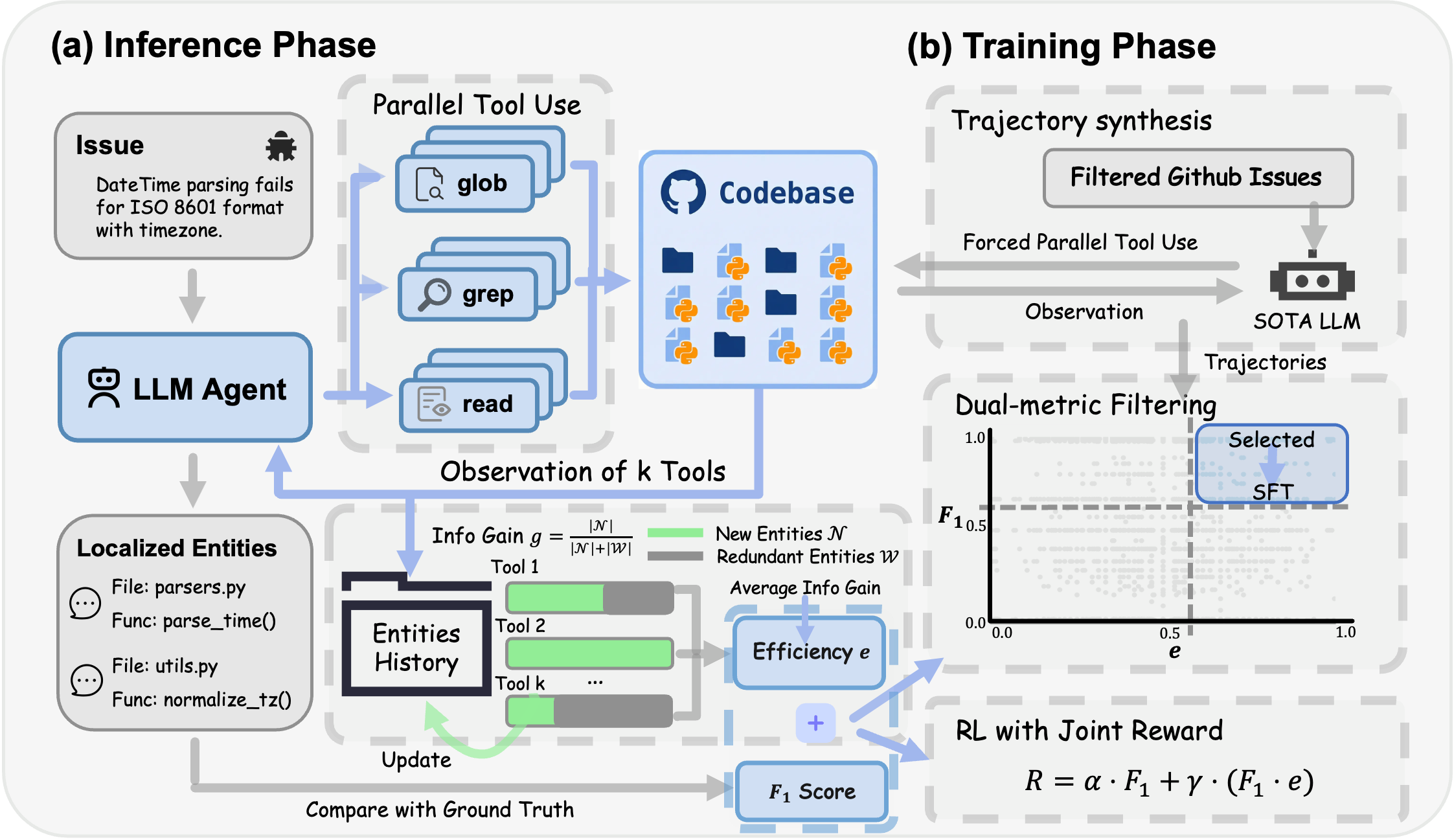
Figure 2: FuseSearch system: parallel tool execution at inference, dual-metric trajectory filtering for SFT, and RL optimization with the joint reward.
Experimental Results
Benchmark and Baseline Comparison
Evaluation on SWE-bench Verified demonstrates that FuseSearch-4B achieves 84.7% file-level F1 and 56.4% function-level F1, on par with much larger proprietary models and specialized agent systems. Notably, it realizes a 93.6% speedup, requiring 67.7% fewer turns and 68.9% fewer tokens than sequential LLM agents. Minimalist sequential agents are sound, but the addition of adaptive parallelism realized by efficiency-aware RL is necessary for optimal cost-accuracy balance.
Strong claims validated by the results include:
Training Analysis
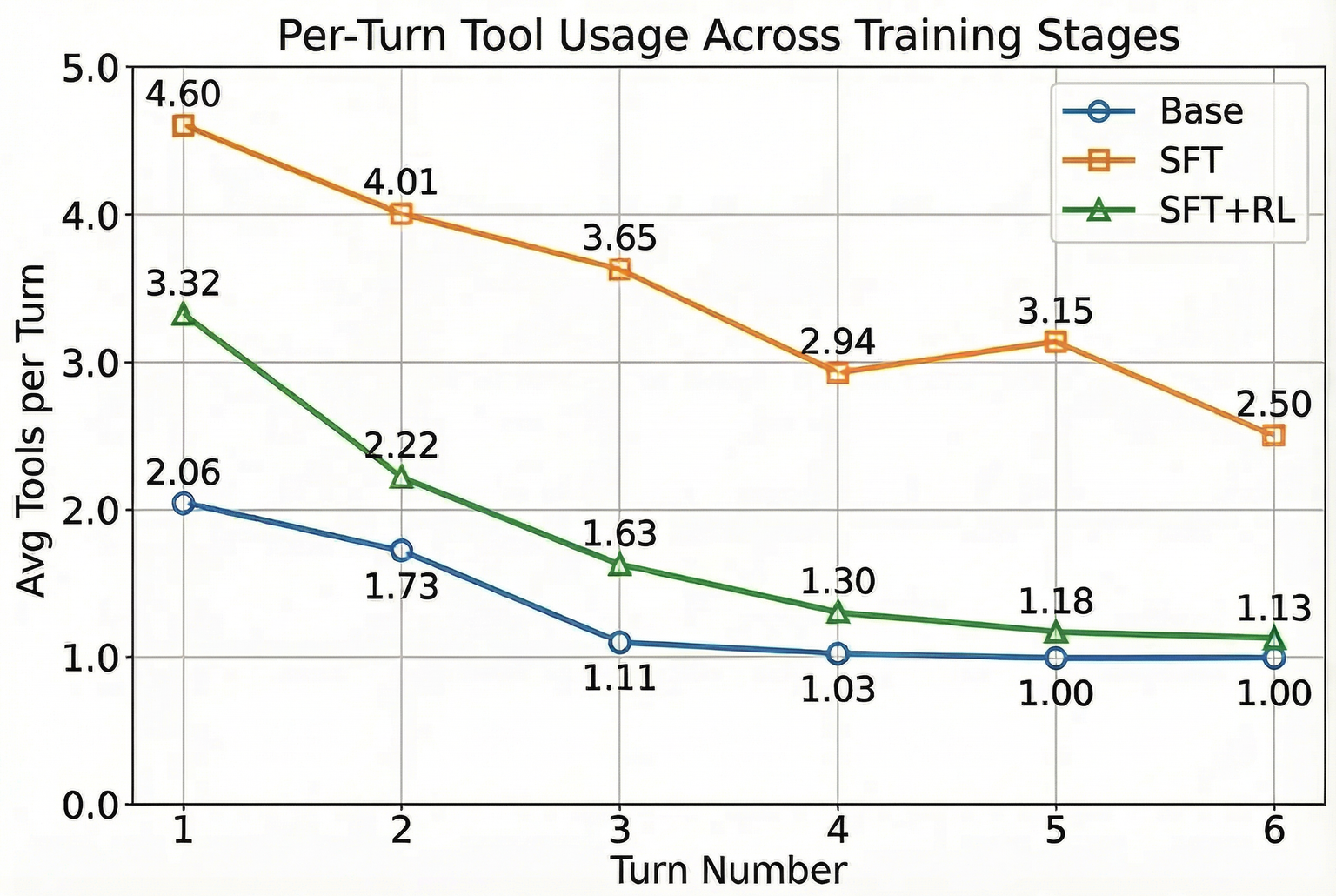
SFT bootstraps effective parallel tool usage, enhancing recall but with increased redundant accesses. RL using the joint reward transitions the agent from overly aggressive parallelism toward context-sensitive, adaptive parallelism: broad initial exploration yielding to single-stream, high-precision refinement in later turns. Only the joint objective reliably optimizes both F1 and e; single-metric optimization degrades one for the other. The effect generalizes across models (4B and 30B) and benchmarks (LocBench).
Downstream and Practical Implications
Incorporating FuseSearch as a preprocessing or sub-agent in end-to-end code repair pipelines further reduces inference time and token usage for downstream agents (e.g., Kimi-K2-Instruct), cutting task completion time by up to 28.5% without harming final pass rates. The framework thus functions as a turn/key-token accelerator for production systems, with high utility for agent orchestration in automated software engineering.

Figure 4: System prompt structure guiding the agent’s two-part output, separating must-modify locations from auxiliary context.
Ablation and Analysis
- Parallel vs. Sequential: Parallel agents with adaptive breadth outperform sequential ones in both cost and F1, even controlling for total tool use.
- Joint SFT Filtering: Demonstration filtering on both F1 and e produces data distributions essential for robust parallel policy learning.
- Reward Design: Only a multiplicative F1⋅e term reliably produces models displaying both high quality and high efficiency.
Limitations
Current evaluations rely on gold patch ground truths, limiting the assessment of alternative correct localizations. The experiments focus on Python-centric benchmarks; future benchmarks covering statically typed or non-Python repositories are needed. Generalization to non-issue-driven code search (e.g., QA, comprehension, documentation generation) is not explored.
Conclusion
FuseSearch establishes a minimalist yet robust paradigm for code localization via RL-driven adaptive parallel execution, achieving SOTA-level quality with substantial search acceleration and computational savings. The explicit integration of tool efficiency into the reward function enables strong localization performance, minimal redundancy, and practical deployment on modest model scales. This approach provides theoretical and pragmatic foundations for multi-tool agent orchestration in automated software engineering, and opens avenues for efficiency-aware RL in other large search-space reasoning tasks.
Reference: "Learning Adaptive Parallel Execution for Efficient Code Localization" (2601.19568)