Accelerating Scientific Research with Gemini: Case Studies and Common Techniques
Abstract: Recent advances in LLMs have opened new avenues for accelerating scientific research. While models are increasingly capable of assisting with routine tasks, their ability to contribute to novel, expert-level mathematical discovery is less understood. We present a collection of case studies demonstrating how researchers have successfully collaborated with advanced AI models, specifically Google's Gemini-based models (in particular Gemini Deep Think and its advanced variants), to solve open problems, refute conjectures, and generate new proofs across diverse areas in theoretical computer science, as well as other areas such as economics, optimization, and physics. Based on these experiences, we extract common techniques for effective human-AI collaboration in theoretical research, such as iterative refinement, problem decomposition, and cross-disciplinary knowledge transfer. While the majority of our results stem from this interactive, conversational methodology, we also highlight specific instances that push beyond standard chat interfaces. These include deploying the model as a rigorous adversarial reviewer to detect subtle flaws in existing proofs, and embedding it within a "neuro-symbolic" loop that autonomously writes and executes code to verify complex derivations. Together, these examples highlight the potential of AI not just as a tool for automation, but as a versatile, genuine partner in the creative process of scientific discovery.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper shows how advanced AI models (Google’s Gemini, especially a reasoning-focused version called “Deep Think”) can work with scientists to make real progress on hard research problems. Instead of just writing summaries or fixing grammar, the AI helped brainstorm ideas, spot mistakes in proofs, find counterexamples, suggest algorithms, and even connect ideas across different fields like computer science, economics, and physics.
What questions did the researchers ask?
The paper asks, in simple terms:
- Can AI be more than a helper and actually contribute to discovering new ideas in science and math?
- What kinds of research tasks is AI good at (for example, finding flaws, suggesting strategies, or proving smaller steps)?
- How should humans and AI work together to get the best results?
- Are there general techniques that other researchers can follow to use AI effectively?
How did they do it?
The authors collected many real case studies where scientists used Gemini to attack open problems. Then they looked for patterns—common methods that worked across different projects.
Here are the main approaches they used, explained simply:
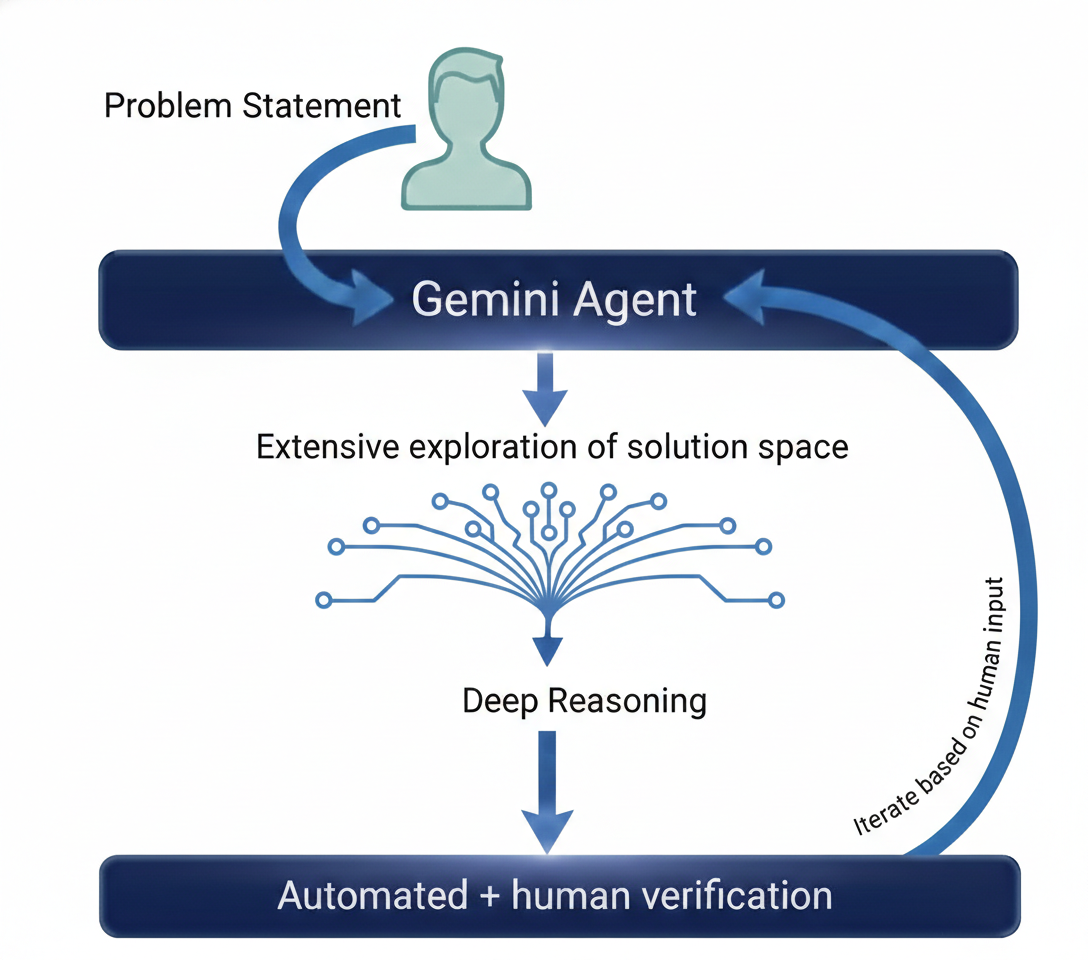
- Iterative conversation: Like a back-and-forth with a smart study buddy. The researcher breaks a big problem into smaller steps. The AI tries something, the human checks it, and together they refine it.
- Problem decomposition: Splitting a big problem into bite-sized lemmas or calculations the AI can tackle one by one.
- Cross-pollination of ideas: The AI suggests connections between different fields. For example, a geometry theorem might help solve a graph problem.
- Counterexample search: To test a conjecture (a “maybe-true” idea), the AI tries to build a specific example that breaks it—like finding a glitch in a rule.
- Formalization and checking: Turning a sketchy idea into a clear, step-by-step proof, and checking definitions, assumptions, and notation for consistency.
- Tool-use “loops”: Think of a self-correcting lab assistant. The AI proposes a math idea, writes code to test it, runs it, reads the error messages, and fixes itself. This is called a “neuro‑symbolic” loop.
- Adversarial reviewing: The AI acts like a super picky journal reviewer, probing a proof for subtle errors, then double-checking its own critique.
- Human-in-the-loop guidance: The human steers the conversation, picks promising directions, and verifies final results—like a coach guiding a very fast, very eager player.
Behind the scenes, the Gemini model they used was trained to explore several solution routes in parallel (“parallel thinking”), practice multi-step reasoning, and apply extra checks at the end to catch mistakes.
What did they find, and why is it important?
The paper reports real successes where AI helped push research forward—not just toy examples:
- Finding counterexamples to refute a conjecture in online algorithms:
- In a problem about fairly assigning items that arrive in random order, earlier researchers suspected that “copying” an item to the end of a list wouldn’t help more than “moving” it there. Gemini built a small, clever example showing this guess was wrong. This saved people from following a dead-end path.
- Catching a subtle bug in a new cryptography paper:
- In a claimed breakthrough about short, checkable proofs (SNARGs) from a strong security assumption (LWE), Gemini—using a careful, self-correcting review process—found a mismatch between a definition and a construction. This kind of bug is easy to miss and important to catch, because cryptography must be airtight.
- Bridging ideas across fields to resolve open questions:
- For problems about graph embeddings and Steiner trees (ways to connect points efficiently), the AI noticed a link to a geometry theorem (Kirszbraun’s Extension Theorem). That connection helped settle a “simplex is best” conjecture in a particular setting.
- Turning physics math into runnable checks:
- In a study of cosmic strings (objects from theoretical physics), the AI proposed formulas, wrote code to test them, analyzed errors, and improved the math—acting like a scientist who constantly tests their own work.
- Improving algorithms and proofs:
- The AI suggested new ways to adapt known data structures (like quadtrees) for different types of distances, and transformed sketchy ideas into rigorous proofs when the subproblems were well-posed.
Why this matters:
- It shows AI can be a true collaborator in creative, expert-level reasoning—not just an autocomplete tool.
- It speeds up the research cycle: faster idea generation, faster checking, and quicker discovery of dead ends.
- It helps researchers see surprising connections across fields, which is often how breakthroughs happen.
What could this change in the future?
If used well, AI can act like a tireless, well-read junior collaborator:
- It can explore many paths in parallel, suggest fresh angles, and handle tedious calculations.
- Humans remain essential to guide the exploration, choose the best ideas, and ensure everything is correct.
- The paper offers a practical “playbook” other researchers can use: break problems into steps, iterate with the AI, ask it to be an adversarial reviewer, let it write and run tests, and always verify.
In short, this research suggests a new normal for discovery: humans and AI working together—faster brainstorming, smarter checking, and more chances to find the next big idea.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what the paper leaves missing, uncertain, or unexplored, framed so future researchers can act on it.
- Replicability of results: The paper relies on an internal, non-public “advanced version of Gemini Deep Think.” There is no release of model weights, configuration, or exact training regimen, making the reported case studies non-reproducible for external researchers.
- Missing prompt protocols: Key interaction scaffolds (e.g., the “Math rigor prompt”) are referenced but not specified. Full prompt templates, conversation transcripts, and interaction guidelines are needed to enable replication and controlled comparison.
- Lack of controlled baselines: There are no controlled experiments comparing performance against (i) human-only workflows, (ii) other frontier models (e.g., GPT-5), or (iii) simpler Gemini variants, leaving the incremental value of the proposed techniques unquantified.
- Absence of quantitative metrics: The paper does not report standardized metrics (time-to-solution, number of iterations, token/compute cost, error rates, proof length/complexity) to measure speed-ups or rigor improvements attributable to AI assistance.
- Selection bias and negative results: Case studies appear curated without a systematic sampling strategy or documentation of failed attempts. A registry of tasks, success/failure counts, and reasons for failure would address publication bias.
- Data contamination assessment: There is no evidence that tasks or solutions were not present in the training corpus. Protocols to detect and rule out contamination (e.g., temporal data splits, provenance checks) are needed to validate novelty claims.
- Formal proof verification: Claims of “rigorous proofs” are not accompanied by formal verification with proof assistants (Lean/Isabelle/Coq) or independent expert audits. Integrations and audit logs should be provided to certify correctness.
- Adversarial review reliability: The “iterative self-correction protocol” for adversarial reviewing lacks evaluation (precision/recall of bug detection, false positive rates, types of errors caught/missed). A benchmark suite for proof review is needed.
- Generality beyond TCS: The paper focuses largely on theoretical computer science. It remains open whether the techniques generalize to other domains (e.g., wet-lab biology, empirical social science) with noisy data and fewer formal guarantees.
- Technique ablations: The relative contribution of techniques (iterative refinement, adversarial self-correction, cross-pollination, scaffolding) is not disentangled. Controlled ablations are needed to identify which practices drive success and when.
- Neuro-symbolic loop details: The agentic pipeline (symbolic proposal → code generation → automated feedback) lacks implementation specifics (APIs, sandboxing, error-handling policies). Code, configuration, and security guidelines should be released.
- Code execution safety: Running model-generated code introduces security risks. The paper does not specify sandboxing, dependency pinning, resource quotas, or mitigation for malicious or unstable code. A vetted, secure execution framework is required.
- Robustness to numerical instability: While the paper mentions handling tracebacks and instability (e.g., cancellation), there is no systematic evaluation of numerical robustness or fallback strategies. Standard stress tests and diagnostics should be defined.
- External theorem retrieval accuracy: The “identify dependencies → external verification → self-contained proof” flow is not benchmarked for retrieval accuracy or misapplication of theorems. A verification checklist for preconditions and scope is needed.
- Use of advanced machinery vs. hallucination risk: The model’s tendency to avoid (or selectively use) non-elementary results is noted, but there is no strategy to calibrate this trade-off. Methods to encourage justified use of deep results without hallucination should be studied.
- Credit attribution and authorship: The paper does not define how to attribute intellectual contribution between AI and humans. Clear authorship, citation, and contribution policies are needed, especially for novel proofs or counterexamples.
- Ethics and responsible disclosure: The cryptography bug detection case raises responsible disclosure and dual-use concerns. A formal process for reporting, validating, and timing disclosures is needed to avoid harm.
- Benchmarking counterexample generation: While specific counterexamples are presented, there is no standardized protocol to test breadth, minimality, and correctness across domains. A public benchmark and validator suite for counterexample search would help.
- Open bounds in submodular welfare: After refuting Conjecture 15, the tight competitive ratio in the random-order model remains unresolved. Alternative proof strategies and algorithms (beyond Greedy) should be systematically explored and benchmarked.
- SNARGs bug-fixing capability: The paper shows bug detection but does not assess whether the model can propose correct replacements or complete constructions (e.g., SNARGs from LWE). A targeted study on repair-by-design in cryptographic proofs is warranted.
- Versioning and drift: There is no discussion of model/version drift and its impact on reproducibility. A protocol for logging model versions, capabilities, and changes across experiments should be established.
- Tree-based reasoning parameters: The “parallel thinking” setup (branching factor, depth, pruning criteria) is not specified or evaluated. Exposing these parameters and their impacts would guide optimal configuration.
- Cost–benefit analysis: The paper lacks a transparent accounting of compute costs (tokens, wall-clock time, hardware) relative to research gains. A cost framework is needed for practical adoption decisions.
- Open-sourcing artifacts: No code, datasets, or harnesses (for the agentic loop, verification, literature retrieval) are released. Publishing artifacts is essential for community validation and extension.
- Legal and licensing of training data: The curated corpus and reinforcement learning data sources are not described or licensed. Clarifying data provenance, licenses, and compliance (especially for proprietary texts) is necessary.
- Taxonomy of problem suitability: The paper does not systematize which problem types (e.g., combinatorial optimization vs. measure-theoretic proofs) benefit most from AI assistance. A taxonomy and predictive task suitability model should be developed.
- Human oversight guidelines: While “human orchestration” is emphasized, concrete guidance (when to intervene, how to verify, escalation paths) is absent. Standard operating procedures for safe, effective collaboration should be codified.
- Evaluation of writing quality: Improvements in mathematical exposition are claimed but not measured. Metrics for clarity, structure, and correctness (with blinded expert ratings) should be introduced.
- Community benchmarks: There is no shared benchmark of open problems with ground-truth status (open/solved), difficulty tiers, and validation protocols for AI-assisted attempts. Establishing such a benchmark would enable fair, longitudinal evaluation.
Practical Applications
Immediate Applications
Below are deployable use cases that leverage the paper’s demonstrated techniques (adversarial reviewing, neuro‑symbolic loops, counterexample search, cross‑domain synthesis, iterative refinement, and automated proof drafting).
- AI adversarial reviewer for technical proofs and specs (academia; software; security/cryptography)
- Potential tool/workflow: ProofGuard (LaTeX plugin), CryptAudit AI (protocol auditor) integrated into journal submission systems, arXiv screening, and internal R&D reviews.
- Assumptions/Dependencies: Access to reasoning‑enhanced models (e.g., Gemini Deep Think variants), domain‑specific prompts/corpora, human‑in‑the‑loop validation, confidentiality controls, reproducibility policies.
- Neuro‑symbolic verification loop for math/physics derivations (physics; engineering; quant finance; software)
- Potential tool/workflow: AutoVerify Jupyter/VS Code extension that lets the model propose derivations, generate code, execute in a sandbox, and self‑correct from tracebacks.
- Assumptions/Dependencies: Instrumented runtime, secure sandboxing, benchmark datasets for numerical grounding, compute budget.
- Counterexample generation and small‑instance simulation (academia; software QA; optimization; policy analysis; education)
- Potential tool/workflow: CounterExGen library for producing adversarial instances to test conjectures, policies, or system constraints.
- Assumptions/Dependencies: Well‑specified constraints/objectives, representative distributions, automated verification harnesses.
- Deep literature synthesis and conceptual bridging (academia; corporate R&D; IP landscaping)
- Potential tool/workflow: Research Co‑Pilot that retrieves obscure theorems and maps cross‑domain analogies (e.g., Lipschitz extensions ↔ Steiner trees).
- Assumptions/Dependencies: Licensed access to high‑quality literature, citation grounding, deduplication and de‑biasing of sources.
- Automated proof drafting and rigor checks for subproblems (academia; formal methods)
- Potential tool/workflow: ProofLint for LaTeX that expands sketches, checks notation/assumptions, and produces structured proofs for human review.
- Assumptions/Dependencies: Human verification, consistent definitions, integration with proof assistants for optional formalization.
- Algorithmic insight and optimization assistant (software; data infrastructure; robotics planning)
- Potential tool/workflow: AlgOpt Coach that proposes data structure adaptations, norm changes, and analysis tricks (e.g., quadtree variants) to improve complexity.
- Assumptions/Dependencies: Clear performance benchmarks, test suites, domain expertise to validate and deploy changes.
- Theoretical justification of ML heuristics and architectures (software/ML engineering; product teams)
- Potential tool/workflow: Architecture Probe sessions where the model characterizes implicit regularization or bias of components (e.g., Self‑regularized Gumbel Sigmoid).
- Assumptions/Dependencies: Access to training logs/ablation results, privacy‑preserving data pipelines, willingness to update design choices.
- Prompting playbook and context de‑identification for effective AI collaboration (academia; industry)
- Potential tool/workflow: Team training and checklists (iterative scaffolding, adversarial self‑correction, context de‑identification to avoid refusal/hallucination).
- Assumptions/Dependencies: Staff adoption, prompt libraries aligned with domain norms, ongoing measurement of impact.
- Agentic tool‑use in CI/CD for code correctness and numerical stability (software)
- Potential tool/workflow: LLM‑in‑the‑loop runner that generates tests, catches numerical issues (e.g., catastrophic cancellation), and proposes fixes from tracebacks.
- Assumptions/Dependencies: Safe execution, guardrails to prevent harmful actions, audit trails.
- Blockchain and protocol pre‑deployment audits (security/cryptography; finance)
- Potential tool/workflow: ZK‑Proof Auditor for SNARK/SNARG constructions and protocol specs, catching consistency mismatches and assumption gaps.
- Assumptions/Dependencies: Formalized specifications, clear threat models, disclosure and remediation workflows.
Long‑Term Applications
These applications are plausible but require further research, scaling, formal integration, or regulatory acceptance.
- Autonomous formal theorem proving integrated with proof assistants (academia; software verification)
- Potential tool/workflow: AI Theorem Prover that produces Lean/Coq‑checked proofs and certified complexity bounds.
- Assumptions/Dependencies: Rich formal libraries, proof soundness guarantees, robust benchmarks, community standards for trust and attribution.
- End‑to‑end “Research OS” for AI‑accelerated discovery (industry; academia)
- Potential tool/workflow: Integrated environment combining literature ingestion, reasoning tree search, code generation, numerical verification, and provenance tracking.
- Assumptions/Dependencies: Strong safety/auditability, IP/licensing management, reproducibility infrastructure, user training.
- Physics and materials discovery pipelines using neuro‑symbolic agents (energy; advanced manufacturing; aerospace)
- Potential tool/workflow: AI Scientist that proposes analytical spectra/models, validates numerically, and guides experiments.
- Assumptions/Dependencies: High‑fidelity simulators, experimental validation loops, HPC resources, uncertainty quantification.
- Healthcare evidence synthesis and guideline drafting (healthcare; public health policy)
- Potential tool/workflow: ClinEvidence AI that cross‑links trial outcomes, proposes mechanistic hypotheses, and drafts guideline updates for expert review.
- Assumptions/Dependencies: Comprehensive medical corpora, bias mitigation, regulatory approval, clinical validation and post‑deployment monitoring.
- Automated model risk and compliance assurance (finance)
- Potential tool/workflow: ModelRisk AI that stress‑tests models, generates adversarial scenarios/counterexamples, and drafts compliance evidence.
- Assumptions/Dependencies: Explainability standards, regulator acceptance, comprehensive audit trails, high‑quality market data.
- Policy design stress‑testing via counterexample search and simulation (government; NGOs)
- Potential tool/workflow: PolicyLab that finds edge cases violating fairness/safety constraints and suggests corrective mechanisms.
- Assumptions/Dependencies: Formal policy models, stakeholder governance, transparent evaluation criteria.
- Continuous cryptanalytic agents for protocol hardening (security/cryptography)
- Potential tool/workflow: CryptoSentinel that scans emerging constructions for subtle inconsistencies and attacks under realistic adversary models.
- Assumptions/Dependencies: Access to evolving literature/specs, responsible disclosure frameworks, coordination with standards bodies.
- Compiler/optimizer that auto‑discovers algorithmic improvements with proofs (software; robotics; embedded systems)
- Potential tool/workflow: Proof‑backed Optimizing Compiler suggesting asymptotic improvements or parameter regimes with provable guarantees.
- Assumptions/Dependencies: Formal verification integration, performance monitoring in production, safe fallback mechanisms.
- Personalized proof‑centric education platforms (education)
- Potential tool/workflow: Vibe‑Proving Tutor for individualized theorem‑proving pathways, scaffolding, and formative feedback at scale.
- Assumptions/Dependencies: Pedagogical validation, fairness/accessibility, privacy protections, alignment with curricula.
- Grid optimization and logistics scheduling via AI‑suggested algorithms (energy; logistics)
- Potential tool/workflow: GridOpt AI that proposes improved Steiner/flow/dispatch algorithms with proofs of performance bounds.
- Assumptions/Dependencies: Integration with SCADA/EMS, certification and safety cases, robust simulators and field pilots.
Glossary
- 1-Lipschitz: A distance-nonexpanding map whose Lipschitz constant is 1, meaning it never increases distances between points. "a distance-compressing (1-Lipschitz) map"
- Adversarial reviewer: A reviewer role or mode that actively seeks subtle flaws or inconsistencies in arguments to improve rigor. "act as adversarial reviewers."
- Adversarial setting: An online algorithms model where inputs may be chosen by an adversary to minimize an algorithm’s performance. "adversarial setting"
- Agentic Execution Loops: Automated, model-driven workflows where the AI proposes ideas, writes code, runs it, and self-corrects using feedback from execution. "Agentic Execution Loops: Moving beyond manual chat interfaces, models can be embedded in automated ``neuro-symbolic" pipelines."
- Catastrophic cancellation: A numerical instability where subtracting nearly equal numbers causes large relative errors due to loss of significant digits. "such as catastrophic cancellation"
- Competitive ratio: A worst-case performance measure for online algorithms comparing the algorithm’s outcome to the optimal offline solution. "competitive ratio of $1/2$"
- Erdős Problem database: A curated collection of mathematical problems attributed to Paul Erdős and collaborators, used to track progress and solutions. "Erd\H{o}s Problem database"
- Fully homomorphic encryption: Encryption that allows arbitrary computation on ciphertexts, producing encrypted results that decrypt to the correct output. "fully homomorphic encryptions"
- Gadget: A small, purpose-built combinatorial component used in reductions or constructions to enforce specific constraints. "combinatorial structures (gadgets)"
- Geometric functional analysis: A field blending geometry and functional analysis to study normed spaces and mappings between them. "from geometric functional analysis"
- Hardness of approximation: The study of limits on how well optimization problems can be approximated under complexity-theoretic assumptions. "hardness of approximation"
- Hilbert space: A complete inner-product space generalizing Euclidean geometry to possibly infinite dimensions. "Hilbert Space Geometry"
- Implicit regularization: The tendency of an optimization or model architecture to prefer certain solutions (e.g., simpler ones) even without explicit penalties. "implicit regularization induced by specific architectural choices like the Self-regularized Gumbel Sigmoid."
- Indistinguishability Obfuscation (iO): A cryptographic primitive that makes two functionally equivalent programs computationally indistinguishable after obfuscation. "Indistinguishability Obfuscation (iO): While iO can build almost anything, including SNARGs"
- Inapproximability ratio: A bound indicating how close any efficient algorithm can get to the optimal value for a given problem. "inapproximability ratios"
- Kirszbraun Extension Theorem: A theorem guaranteeing the extension of Lipschitz maps between subsets of Euclidean spaces without increasing the Lipschitz constant. "linking Steiner trees to the Kirszbraun Extension Theorem"
- Knowledge of Exponent: A non-falsifiable cryptographic assumption asserting that certain proofs imply knowledge of discrete logarithms or exponents. "``Knowledge of Exponent,''"
- Learning with Errors (LWE): A foundational lattice-based hardness assumption where recovering hidden linear structure is hard in the presence of noise. "the learning with errors (LWE) assumption."
- Lipschitz extension: The operation of extending a Lipschitz continuous function from a subset to a larger space without increasing its Lipschitz constant. "linking Steiner trees to Lipschitz extensions"
- Marginal gain: The incremental increase in objective value from adding one item to a current set or allocation. "Let denote the marginal gain"
- Modular function: A set function whose value is a sum of independent item contributions (i.e., linear over sets). "the sum of a submodular function and a modular function"
- Neuro-symbolic pipeline: A workflow integrating neural LLMs with symbolic computation or code execution to propose, test, and refine solutions. "automated ``neuro-symbolic" pipelines."
- Online Submodular Welfare Maximization: An online allocation problem with submodular valuations, seeking to maximize total welfare as items arrive. "Online Submodular Welfare Maximization (Online SWM)"
- Post-quantum security: Security that is believed to hold even against adversaries equipped with quantum computers. "(post-quantum security)"
- Quadtree: A hierarchical spatial data structure that recursively partitions space into quadrants, often used for geometric algorithms. "adapting quadtrees for different norms"
- Random oracle model (ROM): An idealized cryptographic model where hash functions are treated as perfectly random functions accessible via oracle queries. "random oracle model (ROM)"
- Random order model: An input model where items arrive in a uniformly random permutation, often yielding better algorithmic guarantees than adversarial arrival. "random order model"
- SDP (Semidefinite Programming): Optimization over symmetric positive semidefinite matrices subject to linear constraints, used widely in approximation algorithms. "bounded-rank SDP solutions for Max-Cut"
- Self-regularized Gumbel Sigmoid: A specific stochastic relaxation/activation mechanism that introduces built-in regularization via Gumbel noise and a sigmoid transform. "Self-regularized Gumbel Sigmoid"
- Simplex: In geometry, the generalization of a triangle/tetrahedron to arbitrary dimensions; also used as a structured embedding configuration. "the \"Simplex is the Best for Graph Embeddings\" conjecture"
- SNARGs: Succinct non-interactive arguments—very short proofs verifiable efficiently without interaction between prover and verifier. "Succinct non-interactive arguments (SNARGs)"
- Steiner tree: A network design problem seeking the shortest tree connecting given terminals, possibly using extra intermediate points (Steiner points). "Euclidean Steiner Trees"
- Stone–Weierstrass Theorem: A classical result stating that certain subalgebras of continuous functions are uniformly dense, enabling approximation of continuous functions. "apply the Stone-Weierstrass Theorem"
- Sub-exponential hardness: An assumption that solving a problem requires time exponential in a sublinear function of the input size, weaker than full exponential time. "sub-exponential hardness"
- Submodular function: A set function with diminishing returns: adding an element gives less gain when the set is larger. "submodular function"
- Tree-based search: A reasoning or exploration strategy that branches over candidate solution paths and searches them in a tree structure. "tree-based search methods"
- Verifiable Outsourced Computation: A paradigm where a client delegates computation to a server and checks a succinct proof of correctness. "Verifiable Outsourced Computation: A weak client (like a smartphone) can offload a heavy computation"
- ZK-Rollups: Blockchain scaling constructions that use zero-knowledge proofs to batch many transactions into a single succinct proof. "ZK-Rollups"
- zk-SNARKs: Zero-knowledge succinct non-interactive arguments of knowledge—proofs that are short, quickly verifiable, and reveal nothing beyond validity. "zk-SNARKs"
Collections
Sign up for free to add this paper to one or more collections.