Image Generation with a Sphere Encoder
Abstract: We introduce the Sphere Encoder, an efficient generative framework capable of producing images in a single forward pass and competing with many-step diffusion models using fewer than five steps. Our approach works by learning an encoder that maps natural images uniformly onto a spherical latent space, and a decoder that maps random latent vectors back to the image space. Trained solely through image reconstruction losses, the model generates an image by simply decoding a random point on the sphere. Our architecture naturally supports conditional generation, and looping the encoder/decoder a few times can further enhance image quality. Across several datasets, the sphere encoder approach yields performance competitive with state of the art diffusions, but with a small fraction of the inference cost. Project page is available at https://sphere-encoder.github.io .









Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple explanation of “Image Generation with a Sphere Encoder”
What is this paper about?
This paper introduces a new way to make computers generate images very quickly. The idea is called a “Sphere Encoder.” Instead of needing hundreds or thousands of steps like many popular image models (such as diffusion models), this method can make a good image in just one step, and even better images in only a few steps.
What were the researchers trying to figure out?
Here are the main questions they asked:
- Can we build a generative model that makes sharp images in one or just a few steps?
- Can we avoid slow, many-step processes (like diffusion) and still get high-quality results?
- Can we design a simple “latent space” (a kind of hidden code for images) that’s easy to sample from directly?
- Will this method work for both unconditional image generation (just “make a picture”) and conditional generation (e.g., “make a picture of a cat”)?
How does the Sphere Encoder work? (Explained with simple ideas)
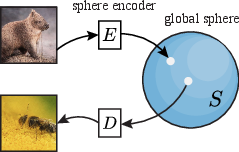
Think of turning images into secret codes and then turning those codes back into pictures. The Sphere Encoder uses two parts:
- An encoder: reads an image and turns it into a code.
- A decoder: takes a code and draws an image from it.
The special twist:
- All codes are “spread out” evenly on the surface of a big sphere (like evenly placing pins all over a globe). This makes the space of codes simple and predictable.
- If codes are evenly spread on the sphere, then making a new image is as easy as picking a random point on the sphere and decoding it.
How they train it:
- Reconstruction: The model learns to reproduce the original image from its code (so the decoder becomes good at drawing).
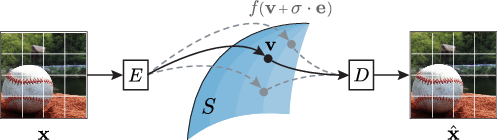
- Add a little “noise”: During training, they slightly “nudge” the code in different directions (like a tiny push around the sphere) and ask the decoder to still make a similar image. This helps the model handle nearby points on the sphere, not just exact training codes.
- Consistency: They add two kinds of “consistency” checks:
- Pixel consistency: nearby codes should make similar-looking pictures.
- Latent consistency: if you re-encode a generated image, its code should be close to the original code. This helps keep the “sphere” organized and meaningful.
Few-step “polishing”:
- One-step generation is already good, but they can loop the encode/decode process a few times to polish the result, like sketching once, then tracing again to sharpen.
Conditional generation:
- If you want a specific type of image (like a dog), the model can accept a “condition” (a class label). It can also use a common trick called classifier-free guidance (CFG), which is like turning a dial to make the output more strongly match the chosen class.
What did they find?
- Fast image generation: The Sphere Encoder can produce nice images in one step and very strong results in fewer than five steps. That’s much faster than many-step diffusion models.
- Competitive quality: On several datasets (CIFAR-10, Oxford-Flowers, Animal-Faces, and ImageNet), it reaches quality close to or competitive with advanced models, but with far fewer steps.
- Easy sampling: Because the encoder spreads codes evenly on a sphere, picking a random point on the sphere and decoding it usually gives a realistic image. This avoids a common problem in older autoencoders (like VAEs) where random samples often look bad.
- Good control: It supports conditional generation (e.g., “make a tulip”) and works with guidance (CFG) if you want stronger class-specific results.
- Useful behaviors:
- “Fast transitions” in the code space: when you move across the sphere, the image quickly switches between object types instead of making weird blends (like half-cat/half-dog). This means random samples are less likely to look like strange hybrids.
- Image editing: Without extra training, you can do simple edits by repeatedly encoding and decoding an image while telling the model what class you want it to resemble. You can also “stitch” parts of two images and let the model blend them smoothly over a few steps.
Why this matters
- Speed and cost: Fewer steps mean faster image generation and lower compute costs. This can help run image models on smaller devices or make big systems cheaper to use.
- Simplicity: Training is done with straightforward reconstruction and consistency losses—no complicated diffusion process is required.
- Flexibility: It naturally supports class-conditional images and could be extended to other conditions (like text prompts in the future).
- Practical potential: Faster, high-quality generation is useful for games, creative tools, education, and any app where quick, realistic images are helpful.
Quick recap
The Sphere Encoder is a new way to generate images by mapping them onto a sphere-shaped code space. Because the codes are spread evenly, it can decode random points into good images—often in one step, and even better in just a few steps. It’s fast, fairly simple, and works well on multiple datasets, while also enabling handy editing tricks.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list highlights what remains missing, uncertain, or unexplored in the paper and suggests concrete directions for future work:
- Formal guarantees: Provide theoretical conditions under which the proposed spherification-with-noise plus reconstruction/consistency losses produce a latent distribution that is (conditionally) uniform on the hypersphere, and quantify how close to uniformity the learned distribution is.
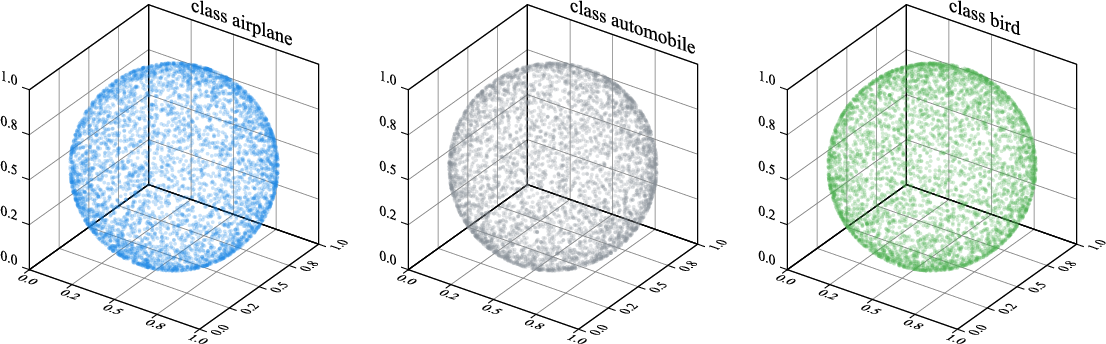
- Uniformity measurement: Develop rigorous metrics to assess (conditional) uniform coverage (e.g., spherical discrepancy, pairwise angular distribution, spherical cap occupancy, nearest-neighbor angular spacing) across all classes, and report those metrics for ImageNet-1k rather than visual random projections for a few classes.
- Sampling validity: Systematically test the proportion of uniformly sampled latent directions that decode to realistic images per class (success rate), including failure modes and hybrid/ambiguous outputs, to substantiate claims of reliable decoding from random points.
- Convergence analysis: Analyze the iterative encode–decode refinement (few-step generation) as a dynamical system (e.g., contraction mapping, fixed points, basin of attraction), including proofs or empirical guarantees of convergence, stability, and conditions under which the process diverges or oscillates.
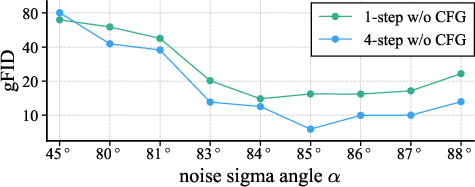
- Automatic noise tuning: Replace heuristic angle/sigma selection with an adaptive or learned schedule (global or per-sample), and quantify performance sensitivity; evaluate whether a learned tangent-plane perturbation (geodesic noise) improves coverage and stability vs. adding Gaussian noise before re-projection.
- Training–inference mismatch: Investigate the impact of training with jittered noise magnitudes while using fixed maximum noise at inference; test matched schedules or curriculum strategies and measure their effect on quality and stability.
- Loss design trade-offs: Quantify the impact of pixel-space losses vs. latent-only or adversarial losses on edge sharpness, global semantics, and FID/CLIP-FID; test hybrid objectives (e.g., GAN heads, contrastive losses, multi-stage perceptual features) to reduce subtle blurring noted by the authors.
- Conditional encoder necessity: Compare conditional vs. unconditional encoders for class-conditional decoders across large ontologies (ImageNet-1k), and measure conditional uniformity and sample quality to validate the claim that a conditional encoder is essential.
- CFG placement and design: Systematically study classifier-free guidance applied in latent vs. pixel space (and jointly), including step-wise schedules, strength tuning, and interactions with the iterative process; report quantitative gains beyond anecdotal observations.
- Sampling scheme theory: Explain why sharing the same noise vector across steps helps; derive or empirically validate that shared-noise refinement follows a beneficial geodesic or gradient direction on the sphere; explore alternatives (e.g., learned update directions).
- Evaluation protocol: Recompute gFID/IS on held-out test sets (not training sets), and include precision/recall for generative models, sFID, CLIP-FID, human preference studies, and semantic consistency metrics to avoid overestimating performance and to capture trade-offs in global semantics vs. local texture.
- Fair comparisons: Ensure apples-to-apples comparisons with baselines (e.g., same resolution, conditioning, dataset splits, number of samples, compute budgets) and report training and inference throughput, latency, NFE, energy, and memory to substantiate efficiency claims.
- Scaling to higher resolutions: Test the approach at 512×512 and 1024×1024 with realistic training budgets; analyze failure modes (e.g., blur or texture artifacts) and architectural modifications (multi-scale decoders, upsamplers) needed for high-resolution generation.
- Text-to-image conditioning: Extend the method beyond discrete ImageNet classes to continuous text prompts (e.g., CLIP/LMM-based conditioning, cross-attention), and verify conditional uniformity and reliable decoding for long-tail, compositional prompts.
- Data efficiency and overfitting: Quantify memorization risks (especially on small datasets with many epochs) via membership inference, nearest-neighbor analyses, and precision/recall; propose mitigation strategies (stronger augmentation, regularization) and measure their effects.
- Robustness and OOD behavior: Systematically evaluate out-of-domain inputs (beyond a single example), adversarial perturbations, distribution shifts, and safety filters; characterize how the encoder projects OOD content into latent space and the resulting generation behavior.
- Latent geometry choices: Compare RMS normalization vs. L2 normalization, learned radius, hyperspherical priors (e.g., vMF), or elliptical/anisotropic manifolds; test whether tangent-space parameterizations or normalizing flows on the sphere improve training or sampling.
- Latent spatial resolution: Generalize the ablations to more latent shapes and compression ratios across datasets, and explain why certain resolutions/compression ratios work best; connect to information bottleneck principles and decoder capacity.
- Training stability: Analyze why the MLP-Mixer + RMSNorm bounding is “critical”; provide failure case studies and mitigation strategies (optimizer settings, gradient clipping, norm constraints, weight decay schedules) to ensure reproducible training at large scale.
- Iterative editing guarantees: Formalize why iterative encoding/decoding achieves “image crossover” and manipulation without noise through the encoder; measure fidelity to sources, boundary blending quality, and failure rates; compare with diffusion-based editing baselines.
- “Fast transitions” quantification: Move beyond qualitative claims by measuring class transition sharpness along geodesic paths in latent space (e.g., classifier confidence curves, mutual information, attribute continuity), and relate this property to lower rates of hybrid/implausible images.
- Failure characterization: Catalog typical artifacts (e.g., “waffle” patterns, “paper art” oversharpening), identify when they arise (datasets, steps, CFG strengths), and propose targeted remedies (loss tweaks, architecture changes, step scheduling).
- Compute reporting: Provide detailed training compute (GPU-hours), memory footprint, parameter counts per component, and scaling curves vs. quality metrics; compare training cost with diffusion models to clarify the total cost-benefit trade-off.
- Generalization across modalities: Explore whether spherical latent encoders extend to audio, video, 3D, or multimodal tasks; define modality-specific spherification and consistency losses and evaluate uniformity and one-step/few-step generation quality.
Practical Applications
Below is an overview of practical, real-world applications enabled by the paper’s Sphere Encoder—an efficient, one- to few-step image generation framework that learns a uniformly covered spherical latent space and decodes random points into realistic images. Each item notes sector relevance, potential tools/workflows, and key assumptions or dependencies.
Immediate Applications
- Fast, low-latency image generation services
- Sector: software/cloud, media/advertising, e-commerce
- What: Replace many-step diffusion inference with one- to four-step Sphere Encoder pipelines to serve thumbnails, banners, product hero shots, and concept imagery with drastically lower compute and latency.
- Tools/workflows:
- API endpoints exposing D(f(e)) for one-step generation or the iterative E/D loop for quality bumps (2–4 steps).
- Class-conditional generation via AdaLN, optional CFG for controllability.
- Recommended fixed noise strength with shared noise across steps, per paper’s sampling ablation.
- Assumptions/dependencies: Requires domain-specific training (or fine-tuning) and class labels for conditional uniformity; quality depends on dataset, sigma/angle tuning, and model scale.
- On-device generative imaging for mobile/AR
- Sector: mobile/edge, AR/VR, creative apps
- What: Deploy small Sphere Encoder variants (e.g., quantized ViT-L) on smartphones or AR glasses for instant style filters, avatars, scene decoration, or sticker/icon generation.
- Tools/workflows:
- One-step generation for real-time UX.
- Optional few-step refinement when devices can afford 2–4 iterations.
- CFG for user-adjustable “style strength.”
- Assumptions/dependencies: Model compression/quantization needed; energy and memory constraints; domain-specific training improves quality for target features (faces, objects, textures).
- Training-free image editing: conditional manipulation and crossover
- Sector: creative tools, social media, design
- What: Iteratively encode/decode an input image while conditioning on target classes to adjust content and texture; “image crossover” blends stitched composites into coherent outputs without retraining.
- Tools/workflows:
- UI for selecting target class; iterative E/D loop (2–10 steps).
- Noise scheduling: fixed or decayed r, shared noise vector across steps.
- Out-of-domain manipulation (e.g., stylizing arbitrary photos toward target classes).
- Assumptions/dependencies: Requires a class ontology; semantic fidelity depends on dataset’s coverage and conditioning strength; CFG can further control edits but may be optional.
- Balanced class sampling for synthetic dataset generation
- Sector: robotics/autonomy, computer vision R&D, simulation
- What: Generate balanced per-class synthetic images leveraging conditional uniformity on the sphere to fill data gaps or support domain randomization.
- Tools/workflows:
- Uniform sphere sampling per class to ensure even coverage.
- Iterative refinement (2–4 steps) for higher realism.
- Integrated pipelines for labeling and QA metrics (gFID/IS, diversity checks).
- Assumptions/dependencies: Class structure must align with downstream tasks; validation needed to avoid overfitting/memorization (noted risk for small datasets); realistic textures/structures depend on training data quality.
- Cost and energy savings for large-scale content operations
- Sector: cloud platforms, sustainability/compliance
- What: Replace hundreds-to-thousands-step diffusion inference with a few-step Sphere Encoder to cut inference compute (NFE) and carbon footprint for high-volume image generation.
- Tools/workflows:
- Operational dashboards tracking NFE, power draw, and throughput.
- Roll-out plans prioritizing workflows where one-step or few-step quality suffices (e.g., small images, thumbnails).
- Assumptions/dependencies: Requires performance benchmarking against existing pipelines; may need hybrid deployments (Sphere Encoder for speed-sensitive tasks, diffusion for highest photorealism).
- Rapid prototyping and education in generative modeling
- Sector: academia/education
- What: Use the Sphere Encoder to teach and experiment with high-dimensional spherical latent spaces, RMS normalization, and consistency losses; run ablations on noise angle α and sampling schedules.
- Tools/workflows:
- Classroom demos: visualizing conditional uniformity via random projections, latent interpolation with fast transitions.
- Reproducible experiments to compare VAE posterior hole vs spherical uniformity.
- Assumptions/dependencies: Access to code, compute for training; understanding of ViT/MLP-Mixer components and perceptual/latent consistency losses.
- Content moderation and safer deployment ergonomics
- Sector: platform safety, trust & safety
- What: Deterministic few-step generation (shared noise) facilitates reproducible moderation checks and auditing; balanced per-class sampling can reduce skew in outputs.
- Tools/workflows:
- Moderation pipelines with deterministic seeds for appeals/review.
- Class-conditioned guardrails (denylist classes).
- Assumptions/dependencies: Requires policy mapping of classes; ongoing safety testing; monitoring for memorization or unwanted artifacts.
- Creative ideation and concept exploration
- Sector: marketing, industrial design, entertainment
- What: One-step ideation for moodboards, concept art, and variations; few-step refinements for clarity without the cost of long diffusion chains.
- Tools/workflows:
- Integration into design tools with sliders for steps, CFG, and conditioning strength.
- Latent interpolation grids (fast transitions) for brainstorming across styles or categories.
- Assumptions/dependencies: Domain-specific training may be needed to reflect brand aesthetics or specific product categories.
- E-commerce visual A/B testing and personalization
- Sector: retail/e-commerce
- What: Rapidly generate product display variants (backgrounds, colors, arrangements) and personalize imagery per user segment with negligible latency.
- Tools/workflows:
- Conditional embeddings for product categories; per-class balanced sampling.
- Backend experimentation platform to compare CTR/engagement across variants.
- Assumptions/dependencies: Data rights and brand constraints; checks for realism and avoidance of misleading renderings.
Long-Term Applications
- Text-to-image and multimodal conditioning
- Sector: creative tools, software platforms
- What: Extend class conditioning to language embeddings (CLIP/LLM-based) for text-to-image with few-step generation.
- Tools/workflows:
- Replace class embeddings with text encoders; integrate CFG and iterative refinement.
- Safety layers for prompt moderation and style constraints.
- Assumptions/dependencies: Large-scale captioned datasets; training stability with multimodal encoders; robust semantic alignment.
- High-resolution, photorealistic generation (≥1024px)
- Sector: media/advertising, photography
- What: Scale Sphere Encoder to larger resolutions with pyramid/tiling strategies, enhanced losses (latent-only or multi-stage GAN losses) to reduce pixel-space blur.
- Tools/workflows:
- Progressive latent resolutions; multi-stage decoders; improved perceptual/latent losses.
- Hybrid pipelines combining Sphere Encoder for speed with texture-enhancing modules.
- Assumptions/dependencies: Significant training compute; careful architecture/scaling; potential trade-offs between FID and global coherence.
- Video generation and temporal editing
- Sector: entertainment, social media, simulation
- What: Extend spherical latent manifold to sequences, modeling temporal consistency for few-step video generation or stylization.
- Tools/workflows:
- Temporal encoders/decoders; spatiotemporal consistency losses; per-frame shared noise scheduling.
- Assumptions/dependencies: Larger memory/computation; datasets with temporal annotations; robust temporal smoothing.
- Synthetic data for robotics and autonomy at scale
- Sector: robotics, autonomous driving, industrial inspection
- What: Generate diverse, balanced visual datasets (objects, scenes) to pretrain or augment perception models, reducing reliance on costly data collection.
- Tools/workflows:
- Scenario libraries; domain randomization on spherical latents; target distribution tuning (lighting, backgrounds, occlusions).
- Assumptions/dependencies: Validation for sim-to-real transfer; domain gap mitigation; safety certification where relevant.
- Medical imaging augmentation under governed workflows
- Sector: healthcare
- What: Carefully vetted synthetic augmentation (e.g., anatomical variations) to support training radiology models with few-step generation pipelines.
- Tools/workflows:
- Strict governance (IRB, legal), traceability, and bias audits; medically informed conditioning (anatomical labels).
- Assumptions/dependencies: High-quality, consented datasets; clinical validation; strong safeguards against hallucinations or diagnostic errors.
- Federated and privacy-preserving personalization
- Sector: mobile/edge privacy, enterprise
- What: On-device fine-tuning/personalization of sphere latents (styles, preferences) without sharing raw data, with fast local generation.
- Tools/workflows:
- Federated training of encoder/decoder; differential privacy; model compression.
- Assumptions/dependencies: Efficient fine-tuning methods; privacy guarantees; hardware acceleration.
- Provenance, watermarking, and detection research
- Sector: policy/governance, platform integrity
- What: Explore spherical-latent fingerprints or embedded watermarks that survive few-step generation, aiding provenance tracking and deepfake detection.
- Tools/workflows:
- Latent-level watermark schemes; robust detection models exploiting uniformity or noise-direction consistency.
- Assumptions/dependencies: Watermark robustness to transforms; regulatory alignment; open standards.
- 3D/scene generation and digital twins
- Sector: gaming, architecture, manufacturing
- What: Adapt spherical latent ideas to multi-view or 3D representations (e.g., NeRF-like latents) for fast scene synthesis or worldbuilding.
- Tools/workflows:
- Spherical latents across views; consistency losses for geometry and appearance; few-step refinement for coherence.
- Assumptions/dependencies: 3D datasets; managing view-consistency; substantial training compute.
- Model compression and distillation for IoT
- Sector: embedded systems, consumer devices
- What: Distill large Sphere Encoder models into compact versions for wearables, smart displays, or in-car systems.
- Tools/workflows:
- Knowledge distillation; low-bit quantization; hardware-aware pruning.
- Assumptions/dependencies: Maintaining image quality under aggressive compression; hardware-specific optimization.
- Sustainable AI policy and procurement standards
- Sector: policy/regulation, enterprise governance
- What: Encourage adoption of few-step generative solutions (like Sphere Encoder) in standards that prioritize energy-aware AI deployments.
- Tools/workflows:
- Policy templates specifying NFE targets, reporting of energy/latency metrics; sustainability scoring in RFPs.
- Assumptions/dependencies: Cross-industry coordination; benchmarking transparency; exceptions for specialized HQ tasks.
Notes on feasibility and dependencies across applications:
- Training data quality, scope, and licensing materially affect realism and ethical deployment.
- Conditional uniformity depends on using a conditional encoder (not just decoder), per the paper’s analysis.
- Image quality vs. FID trade-offs require careful choice of losses (pixel + latent consistency) and noise angle α, with fixed/shared noise schedules recommended for stability.
- Model sizes (up to ~1.3B params in the paper) and long training epochs imply nontrivial training cost; benefits are predominantly at inference time.
- Risk of memorization exists for small datasets at high epochs; mitigation via auditing and regularization is advisable.
- Safety and bias audits are necessary before production use in sensitive domains (healthcare, civic applications).
Glossary
- AdaLN: A conditioning mechanism that modulates layer normalization parameters based on conditioning signals (e.g., class). "conditional generation using AdaLN"
- AdaLN-Zero: A variant of AdaLN initialized to zero to stabilize conditional modulation at the start of training. "we implement AdaLN-Zero in both the encoder and decoder"
- anisotropic Gaussian: A Gaussian noise distribution whose variance differs across directions/dimensions. "where $\be \sim \mathcal{N}(0, \mathbf{I}) \in \real^L$ is random anisotropic Gaussian"
- Class-conditional generation: Generating images conditioned on class labels to control output categories. "For class-conditional generation, we implement AdaLN-Zero"
- Classifier-free guidance (CFG): A guidance technique that trades off between conditional and unconditional predictions to control fidelity versus diversity. "classifier-free guidance (CFG)"
- Concentration of measure: A high-dimensional phenomenon where random vectors become nearly orthogonal and norms concentrate tightly. "Because of the concentration of measure phenomenon, $\be$ is nearly orthogonal to $\bv$"
- Conditional manipulation: Editing an input by iteratively conditioning generation on a target class to steer semantics. "Conditional Manipulation."
- Conditional uniformity: The property that, for each condition (e.g., class), encoded latents uniformly cover the spherical latent space. "Conditional Uniformity."
- Cosine similarity: A similarity measure based on the angle between vectors, often used in latent space comparisons. "computing the cosine similarity between their latent representations."
- Diffusion models: Generative models that synthesize data by iteratively denoising from noise through a learned stochastic process. "competing with many-step diffusion models"
- Few-step generation: Producing images with a small number of iterative refinement steps instead of hundreds or thousands. "Few-step generation results on CIFAR-10."
- FID: Fréchet Inception Distance; a metric comparing generated and real image distributions via feature statistics. "Because low FID scores do not always align with perceptual realism"
- gFID: Generation FID; FID computed on generated samples to assess generation quality. "generation FID (gFID)"
- Image crossover: Combining pieces of multiple source images and iteratively projecting them onto the learned manifold to blend coherently. "Image Crossover."
- Image manifold: The (approximate) subset of image space that corresponds to natural, valid images. "off the image manifold"
- Inception Score (IS): A generation metric measuring both image quality and diversity via a pretrained classifier’s predictions. "Inception Score (IS)"
- Jittering Sigma: Randomly varying the noise magnitude during training to cover diverse directions on the sphere. "Jittering Sigma."
- Latent consistency loss: A loss enforcing that decoding noisy latents yields images semantically consistent with clean latents when re-encoded. "Latent Consistency Loss."
- Latent diffusion models: Diffusion models that operate in a compressed latent space rather than directly in pixel space. "latent diffusion models"
- Latent interpolation: Interpolating between latent vectors to explore the structure and transitions on the learned manifold. "Latent Interpolation."
- Latent manifold: The set of latent representations corresponding to natural images; ideally smooth and structured. "the learned latent manifold."
- Latent spatial resolution: The spatial dimensions (h×w) of the latent tensor before flattening; affects detail retention and compression. "Latent Spatial Resolution."
- MLP-Mixer: An architecture that mixes information across tokens and channels using multilayer perceptrons. "we insert 4-layer MLP-Mixers"
- NFE (number of function evaluation): The count of forward passes used during guidance or sampling. "NFE (number of function evaluation) counts the dual forward passes required by CFG."
- Noise-to-signal ratio (NSR): The ratio of expected noise magnitude to signal magnitude, controlling perturbation severity. "We begin with the noise-to-signal ratio (NSR) "
- Null embedding: A learned embedding representing the unconditional input for CFG. "A learned {null} embedding is trained for classifier-free guidance (CFG) with a probability of $0.1$."
- Perceptual loss: A loss computed in a pretrained feature space (e.g., VGG) to better align perceptual similarity than pixel losses. "perceptual loss"
- Pixel Consistency Loss: A loss encouraging nearby latents to decode into similar images, promoting smoothness of the latent-image mapping. "Pixel Consistency Loss."
- Posterior hole problem: In VAEs, the mismatch where the aggregate posterior fails to match the prior, making prior samples decode poorly. "posterior hole problem"
- Random projection: A dimensionality reduction method using a random matrix to visualize or analyze high-dimensional data. "Latent space visualization using random projection on CIFAR-10 training set."
- RMS normalization: Normalizing a vector by its root-mean-square to project it onto a sphere of fixed radius. "via RMS normalization:"
- RMSNorm: A normalization layer that scales activations by their RMS without mean-centering. "A final RMSNorm layer \cite{rmsnorm} with learned affine parameters is added"
- RoPE positional embedding: Rotary positional embeddings that encode relative positions by rotating query/key vectors. "We use both RoPE positional embedding and sinusoidal absolute positional encoding."
- Sinusoidal absolute positional encoding: A fixed, deterministic positional encoding using sine and cosine functions. "sinusoidal absolute positional encoding."
- Spherifying function: The mapping that flattens latents and projects them onto the spherical surface. "we define a spherifying function, denoted as ."
- Spherifying with Noise: Adding noise to latents and re-projecting them to the sphere to train robustness and coverage. "Spherifying with Noise"
- Spherical latent space: A latent space constrained to points on a fixed-radius hypersphere, enabling uniform sampling. "a spherical latent space"
- Sphere Encoder: The proposed encoder–decoder framework that maps images to a uniform spherical latent and decodes random sphere points. "We introduce the Sphere Encoder"
- Stop-gradient: An operation that prevents gradients from flowing through a tensor during backpropagation. "denotes stop-gradient operation."
- Variational Autoencoder (VAE): A probabilistic autoencoder that learns to match an encoder’s posterior to a prior while reconstructing inputs. "variational autoencoders (VAEs)"
- vMF (von Mises–Fisher) distribution: A probability distribution on the unit sphere used as a spherical prior. "using priors such as the von Mises-Fisher distribution"
- VGG: A family of convolutional networks often used for perceptual feature extraction. "features produced by a static VGG model."
- Vision Transformer (ViT): A transformer-based architecture that applies self-attention to image patches. "Our architecture employs the standard ViT \cite{vit} for both encoder and decoder."
- Volume compression ratio: The ratio of input volume to latent volume, indicating the degree of compression. "volume compression ratio $3.0$"
Collections
Sign up for free to add this paper to one or more collections.

