- The paper presents a dVAE-based method that constructs variable-length semantic IDs to allocate shorter codes for frequent items and longer codes for rare ones.
- The approach leverages Gumbel-Softmax relaxation and a truncated geometric prior to achieve efficient, scalable, and stable training across large datasets.
- Experiments show improved recommendation recall and coverage, with variable-length codes optimizing token efficiency under fixed budgets.
Variable-Length Semantic IDs for Recommender Systems
Motivation and Context
Generative modeling is increasingly integral to the architecture of modern recommender systems, where item catalogs reach extreme cardinalities—often multimillion or billion-scale. Traditional vector-based item IDs introduce significant challenges for generative models; both computationally (prohibitive softmax operations) and in the integration with LLMs, resulting in a substantial vocabulary gap between item identifiers and natural-language tokens. Fixed-length semantic IDs address partial issues by mapping items to discrete low-cardinality token sequences, improving efficiency for both generative retrieval and LLM connection. However, fixed-length assignment to all items fails to respect the frequency distribution of real-world catalogs and contravenes the linguistic principle encoded by Zipf’s law of abbreviation, where popular items are described more succinctly.
Emergent communication literature, focusing on agent-based discrete communication games, has demonstrated the advantages of variable-length code schemes—shorter codes for frequent objects, longer codes for rare ones—but such mechanisms have not been adopted systematically in recommendation settings.
Methodology
The paper proposes a principled approach to variable-length semantic ID construction using discrete variational autoencoders (dVAE) with Gumbel-Softmax reparameterization. This circumvents the instability endemic to REINFORCE-based training typical in emergent communication, and eliminates the fixed-length constraints of previous recommendation models. Each item embedding x∈Rd is represented as a sequence z=(z1,...,zL) of variable length L≤T, using a shared vocabulary V. The generative process models p(x,z,L)=p(L)p(z∣L)p(x∣z1:L), with a truncated geometric prior governing p(L) and a uniform symbol prior pV(zt). The encoder autoregressively samples message tokens and termination probabilities, avoiding dependency on an explicit EOS token.
Optimization leverages the ELBO, with reconstruction, vocabulary, and length regularization terms. The length prior induces a direct message length penalty and ensures frequent items receive shorter codes without explicit popularity conditioning. Gumbel-Softmax relaxation enables efficient, differentiable optimization, with soft residual quantization and KL annealing for stability.
Empirical Evaluation
Experiments utilize large-scale datasets (Yambda, VK-LSVD, Amazon Toys & Games), contrasting the proposed dVAE variable-length model with R-KMeans (fixed-length) and REINFORCE (variable-length) baselines. Metrics include reconstruction loss, token perplexity, code length distribution, recommendation recall/coverage, and scalability.
Efficiency and Quality: Variable-length dVAE achieves comparable semantic reconstruction quality to fixed-length methods with fewer tokens on average. Increasing the length penalty λ yields progressively shorter codes, optimizing the trade-off between conciseness and informativeness. Frequent items are consistently represented with shorter codes, and rare/cold items with longer codes, emerging naturally from the ELBO formulation. Catalog- and data-weighted length statistics confirm that popular items dominate with short codes (Table results).
Downstream Impact: Sequential recommendation experiments demonstrate favorable Recall@100 and Coverage@100 for variable-length dVAE models, outperforming fixed-length baselines under a fixed token budget. The shorter codes allow more user-item events to fit within constrained budgets, enhancing both ranking quality and diversity of recommendations.
Training Stability: dVAE shows superior stability and effectiveness compared to REINFORCE approaches in large-scale regimes. REINFORCE training typically collapses codebook utilization and reconstruction metrics, even when LSTM encoders and advanced regularization are employed.
Scalability: Increasing maximum allowed code length (T) and vocabulary size results in improved reconstruction quality, with variable-length dVAE maintaining stability and effective utilization of discrete capacity as these parameters scale.
Detailed diagnostics show that reconstruction quality improves with each token added (progressive reconstruction), and token perplexity increases for later code positions, indicating increased vocabulary utilization for finer semantic distinction. With long codes (e.g., maxlen=20), the first 10–15 positions use maximum vocabulary, while late positions collapse to a small set:
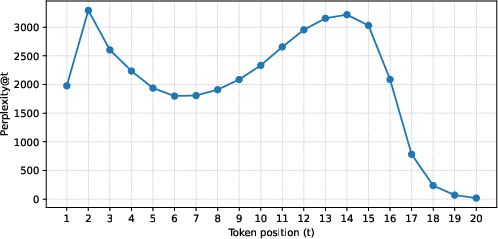
Figure 1: Position-wise token perplexity for varlen dVAE with maxlen=20 on Yambda, showing maximum diversity at intermediate code positions and rapid collapse for long suffixes.
Theoretical and Practical Implications
The introduction of variable-length semantic IDs aligns discrete representations of items in recommendation with efficient coding principles observed in natural language. By bridging emergent communication and recommendation system methodologies, the framework provides a scalable, stable, and theoretically grounded solution for item representation. It enables resource allocation based on information-theoretic considerations (code length adapts to item frequency), facilitating efficient integration with generative models and LLMs, and enhancing sequential recommendation.
Practically, variable-length semantic IDs serve as a foundational building block for next-generation generative retrieval pipelines. The method's robustness and scalability support application in industrial-scale recommender systems, including music and short-video platforms, and enable more nuanced conversational interfaces with LLMs. Theoretically, this approach advances the understanding of representation learning in large discrete spaces, connecting efficient communication theory and variational inference.
Future Directions
Potential developments include dynamic adjustment of length penalty during training to optimize system-wide efficiency/quality, adaptation to multimodal item representations, and integration with unified cross-modal models for joint search and recommendation. Further investigation into compositionality and transferability of learned semantic vocabularies may facilitate broader use of generative retrieval and conversational recommendation frameworks.
Conclusion
Variable-length semantic IDs provide an efficient coding scheme for recommender systems, allocating representational capacity according to item frequency and enabling favorable efficiency–quality trade-offs. The proposed dVAE-based methodology ensures stable, scalable training and bridges theoretical gaps between emergent communication and recommendation. These advances set the stage for widespread adoption of variable-length semantic representations in generative recommender architectures (2602.16375).