To Use or not to Use Muon: How Simplicity Bias in Optimizers Matters
Abstract: For a long period of time, Adam has served as the ubiquitous default choice for training deep neural networks. Recently, many new optimizers have been introduced, out of which Muon has perhaps gained the highest popularity due to its superior training speed. While many papers set out to validate the benefits of Muon, our paper investigates the potential downsides stemming from the mechanism driving this speedup. We explore the biases induced when optimizing with Muon, providing theoretical analysis and its consequences to the learning trajectories and solutions learned. While the theory does provide justification for the benefits Muon brings, it also guides our intuition when coming up with a couple of examples where Muon-optimized models have disadvantages. The core problem we emphasize is that Muon optimization removes a simplicity bias that is naturally preserved by older, more thoroughly studied methods like Stochastic Gradient Descent (SGD). We take first steps toward understanding consequences this may have: Muon might struggle to uncover common underlying structure across tasks, and be more prone to fitting spurious features. More broadly, this paper should serve as a reminder: when developing new optimizers, it is essential to consider the biases they introduce, as these biases can fundamentally change a model's behavior -- for better or for worse.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in simple terms)
This paper asks a practical question: when training AI models, should we use a new, fast optimizer called Muon, or stick with older ones like SGD (stochastic gradient descent)? The authors show that Muon’s speed comes from a different way of learning that can change what a model ends up knowing. In short: Muon is fast, but it removes a helpful “simplicity bias” that SGD naturally has—and that can matter a lot for what the model learns and how well it generalizes.
The main questions the authors ask
- What learning “path” does Muon take that makes it so fast?
- Does Muon remove the “simplicity bias” (a tendency to learn simple patterns first) that SGD has?
- When does this difference help, and when can it hurt—especially for discovering shared structure across tasks or avoiding spurious (misleading) features?
How they studied the problem (explained simply)
To keep things clear and mathematical, the authors analyze a very simple kind of neural network called a deep linear network. Think of it as a stripped-down calculator made of matrix multiplications—no activation functions—so it’s easy to see exactly how learning works.
They compare two ways of updating the model during training:
- SGD (stochastic gradient descent): the classic method, which tends to learn the strongest, simplest patterns first and adds complexity gradually.
- Spectral GD: a simplified, Muon-like method used for theory. It takes the model’s “change” and spreads it evenly across all directions at once (using a math tool similar to breaking a move into “independent directions”). Muon approximates this idea in practice.
You can think of training as hiking down a landscape (the “loss”). SGD often moves in a way that focuses on the most obvious slope first, then the next, and so on—pausing near “flat spots” (saddles). Spectral GD/Muon tries to move evenly in all directions at once, avoiding some of those flat spots. That’s faster, but it changes the order in which things are learned.
They also run two experiments:
- A “routing” task (like a multi-language converter) where success means discovering a shared, reusable representation across different input sources.
- An image classification task (MNIST digits) with a planted spurious feature (a bright pixel tied to the label), to see which optimizer stays focused on the real digit versus the shortcut.
What they found and why it matters
1) Theory: how learning unfolds is different
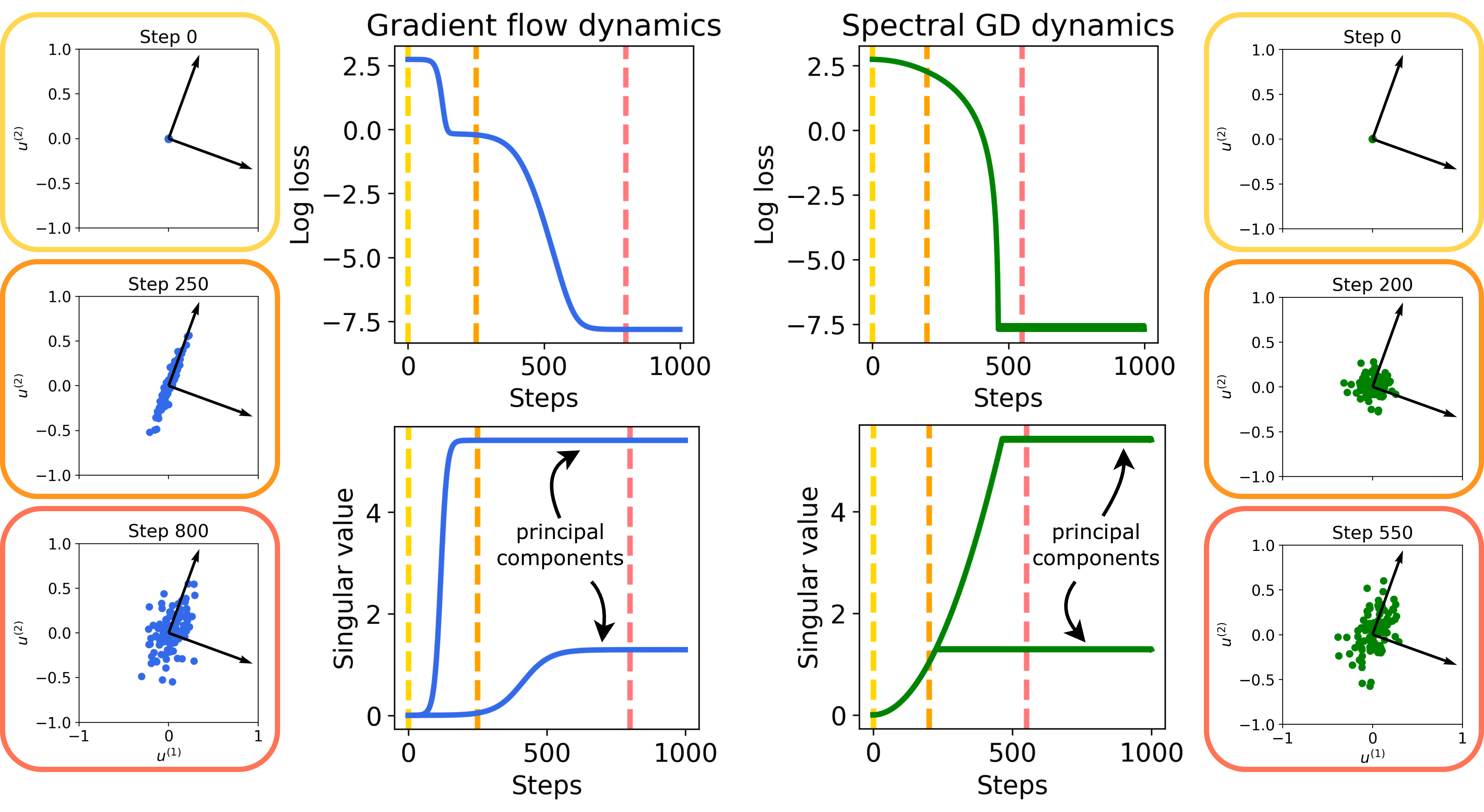
- With SGD, learning is sequential: the model first locks onto the strongest pattern in the data, then the next, and so on. This gradually increases model complexity (like learning the basics before the fancy stuff). This is called a “simplicity bias.”
- With Spectral GD (Muon-like), learning happens across all patterns at the same time and more evenly. This makes training faster, especially when some patterns are rare or weak—but it removes the “learn-simple-first” behavior.
Why that’s important: the order of learning acts like an implicit curriculum. Sometimes learning simpler structure first helps the model find shared rules and generalize better. If you skip that and learn everything at once, you may speed up—but risk memorizing or relying on shortcuts.
2) Experiment A: learning shared representations (“routing” task)
- Task idea: map numbers from different input sources (think different “languages” for the same four symbols) into the same correct outputs. The best solution finds a common code that works across all sources—even for input–output pairs never seen during training.
- Result:
- SGD discovers this shared representation and generalizes to unseen source pairs.
- The Muon-like optimizer gets perfect training loss but mostly memorizes the seen pairs, failing to generalize to unseen ones.
- Why it matters: when your goal is to uncover a common underlying structure (like learning a shared dictionary across languages or a shared feature space across sensors), SGD’s simplicity bias can help; Muon’s even, all-at-once learning can push the model toward memorization instead.
3) Experiment B: spurious features (“shortcut” MNIST)
- Setup: every digit image has a class-specific bright pixel (a spurious shortcut). All optimizers can eventually latch onto it because it’s an easy cue.
- Result:
- All methods do well on a test set that includes the spurious pixel.
- On a clean test set (no spurious pixel), SGD stays accurate longer during training—so with early stopping, SGD achieves a higher best (peak) accuracy than Muon or Adam.
- If the spurious pixel is made very strong, the “dominant” pattern flips. Then SGD becomes worse (it learns the strong shortcut first and takes longer to learn the real digit), while Muon is less affected because it learns both sources of signal together.
- Why it matters: which optimizer is better can depend on your data. If real features are dominant, SGD’s bias helps avoid shortcuts (for a while). If shortcuts dominate, Muon’s even learning can be more robust.
What this means going forward
- Optimizers do more than change training speed—they shape what a model learns. Muon’s design often speeds training, especially when you want to learn many components evenly (e.g., imbalanced or multi-part data). But it can remove a helpful “simple-first” curriculum that encourages discovering shared structure and avoiding shortcuts.
- There’s no one-size-fits-all optimizer. If your task needs strong generalization, shared representations, or you plan to use early stopping, SGD may be safer. If you need speed and balanced learning across many patterns, Muon can shine.
- Big picture: when inventing or choosing optimizers, we should think not only about speed but also about their learning biases—because those biases can change model behavior in good or bad ways.
Key takeaways
- Muon (and its simplified version) learns faster by pushing all patterns at once.
- This removes SGD’s “simplicity bias,” which can help discover common structure.
- In tasks needing shared representations or resilience to shortcuts, SGD can outperform.
- In tasks where signals are uneven and you want balanced, fast learning, Muon can be better.
- Choose your optimizer with the problem’s goals and data properties in mind.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper, intended to guide future research.
- Gap between Spectral GD and Muon: The theory analyzes a simplified optimizer (exact SVD, no momentum, full-batch) rather than Muon with Newton–Schulz orthogonalization, momentum, and stochastic mini-batches. A formal analysis of Muon’s implicit bias, stability, and dynamics under its actual update rule is missing.
- Discrete-time effects and stability: Results are derived in gradient flow; discrete-time behavior with finite step sizes is not characterized. The observed oscillations under discretized Spectral GD lack a stability analysis and step-size/approximation conditions that guarantee convergence.
- Approximate orthogonalization error: The effects of inexact Newton–Schulz iterations (number of iterations, numerical precision, conditioning) on implicit bias, stability, and convergence are not quantified.
- Momentum’s role: How momentum in Muon interacts with orthogonalization to shape trajectory, rank growth, and implicit bias is not analyzed theoretically or empirically.
- Stochasticity and gradient noise: The impact of mini-batch noise on simplicity bias under orthogonalized updates is unexplored (e.g., whether noise can partially restore GD-like bias).
- Strong data assumptions: Theory assumes Σxx=I and joint diagonalizability/silent alignment from small initialization. The dynamics and bias under anisotropic Σxx, non-commuting statistics, and realistic initializations remain open.
- Beyond 2-layer linear models: Extensions to deeper linear networks and modern nonlinear architectures (convolutions, transformers, residuals, attention) with normalization layers (BatchNorm/LayerNorm) are not analyzed.
- Operator-norm steepest descent interpretation: Theoretical consequences of optimizing under an operator-norm constraint (e.g., mirror descent equivalences, invariances, implicit regularization properties) are not fully developed for Muon.
- Formalization and measurement of “simplicity bias”: The paper uses rank growth heuristics; a precise, testable definition and standardized metrics (e.g., effective rank trajectories, subspace angles, spectral decay) across optimizers are not provided.
- Spectral GD phase dynamics: The claimed “equal learning” rate and convergence time proportionalities (e.g., ∝√sk) for singular modes are not fully proved for discrete-time or for approximate orthogonalization; conditions for phase transitions with multiplicities are not formalized.
- Layerwise interactions: It is unclear how orthogonalized updates applied per layer interact across deep networks to produce or remove simplicity bias, and whether specific layers (e.g., MLP vs attention) are more affected.
- Robustness and regularization interactions: The interplay between Muon and common regularizers (weight decay, dropout, data augmentation, label smoothing) and schedules (warmup, cosine decay) on implicit bias and OOD generalization is not studied.
- Scaling behavior: The dependence of Muon’s bias and performance on model width/depth, dataset size, and training length is not characterized; small-scale toy tasks may not extrapolate to large-scale settings.
- Generality of empirical findings: Experiments are limited (routing toy task, MNIST with a single spurious pixel). Broader evaluations on real multimodal tasks, varied spurious correlations (prevalence, strength, types), and multiple OOD benchmarks are needed.
- Baseline coverage and fairness: Comparisons exclude several strong optimizers (e.g., Lion, AdaFactor, Shampoo/Sophia); hyperparameter tuning budgets, wall-clock parity, and ablations (batch size, LR schedules, orthogonalization intensity) are not systematically controlled.
- Mechanistic diagnostics: The causal link between “dominant features” and singular spectrum is hypothesized but not validated (e.g., tracking feature attribution, gradient spectra, and representation subspaces over training).
- Early-stopping and curricula: The observation that SGD attains higher peak OOD accuracy with early stopping is not translated into principled schedules for Muon (e.g., spectral annealing, rank-scheduled orthogonalization) that might restore a curriculum-like bias.
- Design of “simplicity-preserving” spectral optimizers: Concrete algorithms that blend spectral steps with rank growth or spectral tempering (e.g., soft-thresholding of singular values, annealed operator-norm bounds) are not proposed or analyzed.
- Stability bounds for Muon: Conditions on step size, momentum, and orthogonalization accuracy that avoid oscillations and ensure convergence for Muon are not derived.
- Interaction with normalization and scale invariances: How orthogonalization interacts with LayerNorm/BatchNorm and reparameterization invariances (and their effect on implicit bias) is not explored.
- Practical overheads and trade-offs: Wall-clock speedups are cited from prior work, but this paper does not quantify compute/energy overheads of orthogonalization versus gains, across model sizes and hardware.
- Reproducibility and statistical significance: Detailed hyperparameters, seeds, tuning procedures, and statistical tests for observed differences (especially in OOD/generalization) are limited; robustness across runs is not reported.
Glossary
- Associative memory model: A theoretical framework where the system retrieves stored patterns based on content similarity; often used to study memorization in networks. "motivated by associative memory model, show that Muon outperforms Adam on a memorization task(QA dataset about biographical information) task where each dataset entry appears with different frequency."
- Compact SVD: A reduced-form singular value decomposition that retains only non-zero singular values and corresponding singular vectors. "The SVD performed is the compact, meaning the diagonal matrix is of dimension ( being the rank of ) and contains only positive singular values."
- Constraint optimization problem: An optimization setup where the objective is minimized subject to explicit constraints on the variables. "Another way of observing orthogonalizing weight update, as suggested by \citet{bernstein2025deriving}, is as the optimal step of constraint optimization problem:"
- Critical point: A parameter value where the gradient is zero; can be minima, maxima, or saddles. "Critical Points: Any point such that (for ) with , is a critical point of the dynamics."
- Deep linear network: A neural network composed solely of linear layers; useful for analyzing learning dynamics analytically. "Let a forward pass of a 2 layer deep linear network be "
- Effective rank: A soft measure of matrix complexity based on the distribution of singular values rather than a strict count. "the Spectral GD solution exhibits a significantly higher effective rank with a heavy-tailed spectrum"
- Empirical risk minimization (ERM): The principle of minimizing average loss over the training data to learn a model. "the implicit bias of empirical risk minimization with the log-loss leads to faster learning"
- Frobenius norm: The Euclidean norm of a matrix viewed as a vector; the square root of the sum of squared entries. "The usual gradient descent in this setting has instead the constraint with Frobenius norm, where represents the Euclidean norm of the flattened matrix entries."
- Gradient flow: The continuous-time limit of gradient descent dynamics, described by differential equations. "Here we use gradient flow on the whole dataset, starting from infinitesimal initializations ."
- Heavy-tailed spectrum: A singular value distribution with slowly decaying tail, indicating many moderately large components. "exhibits a significantly higher effective rank with a heavy-tailed spectrum"
- Implicit regularization: A bias introduced by the optimization process itself that favors certain solutions (e.g., simpler or lower-rank) without explicit penalties. "the trajectory GD takes sequentially increases the rank of the solution, acting as an implicit regularization."
- Inductive bias: The set of assumptions an algorithm uses to generalize beyond the training data. "Ultimately, we emphasize that the distinction between optimizers lies not only in convergence speed but also in their inherent inductive biases"
- Isotropic curvature model: A theoretical model assuming curvature is the same in all directions, used to analyze optimization behavior. "From the theory side, \citet{su2025isotropic} analyses Muon optimizer on isotropic curvature model."
- Joint diagonalizability: The property that multiple matrices can be simultaneously diagonalized by the same basis. "We also assume the joint diagonalizability of , and ."
- Loss landscape: The surface defined by the loss as a function of model parameters, including minima, saddles, and plateaus. "The key point is that different optimizers make different path traversals in the loss landscape"
- Muon (optimizer): An optimizer that orthogonalizes gradient updates (approximately via Newton–Schulz) to speed training, especially on matrix-structured parameters. "Specifically, we focus on the Muon optimizer \citep{jordan2024muon}, which attracted a large audience due to its performance on NanoGPT Speedrun competition"
- Newton–Schulz iterations: An iterative method to approximate matrix inverses or orthogonal factors efficiently. "Muon employs Newton-Schulz iterations to efficiently approximate orthogonalization"
- Operator norm: The largest singular value of a matrix; measures the maximum amplification factor over unit vectors. "Here the operator norm is defined as , which corresponds to the largest singular value of the matrix."
- Orthogonalization: Transforming a matrix or set of vectors so that directions are orthogonal; in Muon, equalizing non-zero singular values of the update. "This process is termed orthogonalization of ."
- Principal components: Directions (eigenvectors/singular vectors) capturing maximal variance or signal in data/mappings. "the principal components of do align with the ones of early on in the training"
- Saddle point: A critical point that is neither a local minimum nor maximum, with directions of both ascent and descent. "we see that geometrical reason GD is slower is because it has to break many saddle points along the way."
- Saddle-to-saddle dynamics: Training dynamics where trajectories pass near a sequence of saddle points, often increasing solution complexity progressively. "Saddle-to-saddle dynamics \citep{jacot2021saddle, abbe2023sgd, zhang2026saddletosaddle} is a phenomenon observed across architectures"
- Silent alignment: Early-training alignment of weights with data’s principal directions that occurs without explicit supervision or noticeable loss changes. "a phenomena known as silent alignment \citep{hu2020surprising, jacot2021saddle}."
- Simplicity bias: The tendency of learning algorithms to favor simpler, lower-complexity solutions first. "Muon optimization removes a simplicity bias that is naturally preserved by older, more thoroughly studied methods like Stochastic Gradient Descent (SGD)."
- Singular spaces: Subspaces spanned by singular vectors corresponding to particular singular values of a matrix. " learns singular spaces of in the same time, at the same rate, until saturation."
- Singular value: A non-negative scalar from SVD indicating the strength of a corresponding singular direction. "The -th singular value of the product matrix evolves according to a sigmoid function"
- Singular Value Decomposition (SVD): A factorization of a matrix into orthogonal matrices and a diagonal matrix of singular values. "where is the Singular Value Decomposition (SVD) of "
- Spectral design: An approach focusing on spectral properties (singular values/vectors) of updates or weights to shape learning behavior. "This suggests that Muonâs spectral design promotes balanced learning of these components, leading to superior generalization."
- Spectral GD: An optimizer that orthogonalizes the gradient via exact SVD without momentum, learning all principal directions simultaneously. "We also introduce Spectral GD \citep{7347351, pmlr-v38-carlson15}, as its optimization step is more tractable to analyze mathematically, but also keeps the important properties of Muon, such as orthogonalization."
- Spurious correlations: Non-causal statistical associations that can mislead learning and hurt out-of-distribution generalization. "we use a setting with spurious correlations, where while the task could be solved by capturing a spurious feature, we would prefer if the model learns to rely on features that generalize."
- Spurious features: Features that correlate with the target in training data but do not reflect true causal structure. "be more prone to fitting spurious features."
- Stochastic Gradient Descent (SGD): An optimization algorithm that updates parameters using noisy gradients computed on minibatches. "The core problem we emphasize is that Muon optimization removes a simplicity bias that is naturally preserved by older, more thoroughly studied methods like Stochastic Gradient Descent (SGD)."
Practical Applications
Practical Applications of “To Use or not to Use Muon: How Simplicity Bias in Optimizers Matters”
The paper provides theoretical and empirical evidence that Muon’s spectral updates remove the simplicity bias that gradient descent exhibits, leading to faster, more uniform learning across components but with risks of memorization and reliance on spurious features. Below, we translate these insights into concrete applications across sectors, noting immediate versus longer-term opportunities and dependencies that affect feasibility.
Immediate Applications
- Bias-aware optimizer selection playbook for ML teams
- Sector: software, healthcare, finance, education
- Use case: Create a decision checklist to choose SGD/Adam/Muon based on task properties (need for shared representations, presence of spurious correlations, data imbalance, importance of OOD generalization).
- Tools/workflows: A documented “optimizer choice rubric” embedded in model cards and design reviews; add an “optimizer bias” section to experiment templates.
- Assumptions/dependencies: Findings generalize from deep linear analysis to common nonlinear architectures, but require validation per task; small initialization and typical training settings.
- Shadow validation sets for spurious feature auditing and early stopping
- Sector: healthcare, finance, vision/NLP, policy
- Use case: Maintain two validation sets—one with and one without known spurious features (e.g., artifacts, site-specific markers)—to monitor divergence. Prefer SGD (with momentum) and early stopping when spurious reliance is detected; switch to Muon only when OOD robustness is assured.
- Tools/workflows: Automated construction of spurious-free validation subsets and “divergence monitoring” dashboards; scheduled intensity sweeps (as in the MNIST pixel experiment) to quantify dominance thresholds.
- Assumptions/dependencies: Requires domain knowledge to identify spurious features; additional labeling/curation costs.
- Mixed-optimizer training schedules to balance structure discovery and speed
- Sector: multi-modal foundation models, robotics, software
- Use case: Train initially with SGD to encourage sequential, low-rank structure learning (shared representations), then switch to Muon for faster convergence once core components stabilize.
- Tools/workflows: “OptimizerSwitch” callbacks in PyTorch/TF/Keras; criteria based on spectral metrics (effective rank, singular value plateaus).
- Assumptions/dependencies: Needs instrumentation to detect when to switch; nontrivial hyperparameter tuning for transitions.
- Rank-regularized or spectral-aware training to reintroduce simplicity bias under Muon
- Sector: healthcare, education, vision/NLP
- Use case: Combine Muon with low-rank penalties (nuclear norm, factorization constraints), spectral dropout, or bottlenecked architectures to prevent memorization and favor shared representation learning.
- Tools/workflows: Add regularizers and architecture constraints; monitor effective rank of hidden layers; gate Muon updates on rank targets.
- Assumptions/dependencies: Regularization strength must be tuned; compute overhead from spectral monitoring.
- Spectral monitoring and diagnostics in MLOps
- Sector: software tooling, enterprise MLOps
- Use case: Instrument training to track singular value trajectories and effective rank of key layers; flag heavy-tailed spectra and oscillatory behaviors indicative of memorization or instability with spectral updates.
- Tools/products: “SpectralLogger” and “RankWatch” plugins that log SVD approximations, effective rank, and mode learning speed; alerts for early separation of in-distribution vs OOD validation curves.
- Assumptions/dependencies: Approximate SVDs required for scale (randomized SVD); overhead must be managed.
- Recipe for imbalanced modalities and long-tail memorization tasks
- Sector: LLMs, recommender systems, associative memory tasks
- Use case: Prefer Muon when learning needs to be more uniform across rare and frequent components (e.g., tail-end memories), but pair with OOD audits to avoid overfitting to modality-specific artifacts.
- Tools/workflows: Training scripts that select Muon for frequency-imbalanced datasets; add periodic OOD checks.
- Assumptions/dependencies: Benefits depend on how “mode dominance” maps to singular spectrum; requires curated OOD tests.
- Curriculum and causal-task training in robotics and education
- Sector: robotics, industrial automation, education
- Use case: For tasks that require sequential acquisition of causal subskills (implicit curriculum), use SGD or staged training to preserve simplicity bias; avoid Muon when greedier learning risks shortcut solutions.
- Tools/workflows: Stepwise curricula; layer freezing and progressive unfreezing; structured tasks emphasizing rank growth.
- Assumptions/dependencies: Task analysis needed to identify causal decompositions; may increase training time.
- Cross-site healthcare modeling and regulatory-grade generalization
- Sector: healthcare
- Use case: When training across hospitals/devices with heterogeneous distributions, choose optimizers and regularizers that favor shared latent structure (SGD + rank constraints); require OOD validation across sites in deployment gates.
- Tools/workflows: Site-held-out validation, optimizer-specific documentation in clinical model cards, bias audits.
- Assumptions/dependencies: Access to cross-site data; regulatory oversight expects transparent documentation.
- Cost-aware training with risk gating
- Sector: energy/compute operations, MLOps
- Use case: Use Muon to reduce wall-clock training cost when generalization risks are low or mitigated; otherwise gate its use behind spectral diagnostics and robust validation outcomes.
- Tools/workflows: A/B optimizer trials; “speed vs. robustness” scoring; dynamic job scheduling informed by optimizer risk.
- Assumptions/dependencies: Requires observability and governance to manage trade-offs.
Long-Term Applications
- Design of hybrid spectral optimizers that retain simplicity bias
- Sector: software, academia
- Use case: Develop optimizers that combine operator-norm-constrained steps (Muon-like) with mechanisms enforcing sequential rank growth (rank annealing, spectrum scheduling, hybrid Frobenius/operator-norm constraints).
- Tools/products: New “spectral-annealed GD” packages; theoretical guarantees for saddle traversal without losing low-rank bias.
- Assumptions/dependencies: Requires research on convergence, stability, and practical approximations to SVD.
- AutoML systems for optimizer selection and dynamic switching
- Sector: enterprise ML platforms
- Use case: Build controllers that monitor spectral and validation signals to automatically select and switch optimizers during training (e.g., SGD→Muon→SGD as needed).
- Tools/workflows: Meta-learning policies; reinforcement learning controllers; integration with training orchestration.
- Assumptions/dependencies: Reliable real-time spectral metrics; generalizable policies across tasks.
- Standards and policy for “Optimizer Bias Disclosure”
- Sector: policy, governance, healthcare/finance regulation
- Use case: Incorporate optimizer choice, bias characterization, and OOD performance into model cards and compliance artifacts; mandate shadow validation against spurious features for safety-critical deployments.
- Tools/workflows: Documentation templates; audit checklists; third-party certification pipelines.
- Assumptions/dependencies: Consensus on metrics (e.g., effective rank, trajectory separation indices); institutional buy-in.
- Spurious feature early-warning systems
- Sector: safety-critical ML, finance, healthcare
- Use case: Build detectors that leverage trajectory separation (with vs. without spurious features) and spectral signatures to alert when training begins to prioritize shortcuts; trigger regularization or optimizer changes.
- Tools/products: “SpurGuard” service; APIs for divergence metrics and spectral alerts.
- Assumptions/dependencies: Requires engineered spurious-free validation; maintenance of domain-specific detectors.
- Spectral curriculum learning frameworks
- Sector: robotics, education, multi-modal AI
- Use case: Align curricula with spectral dynamics—design tasks that encourage dominant, generalizable components to be learned first; schedule constraints/regularizers to avoid greedy shortcut learning.
- Tools/workflows: Curriculum schedulers that modulate data exposure, regularization strength, and optimizer settings based on spectral feedback.
- Assumptions/dependencies: Deeper understanding of how spectral modes map to causal subskills in complex nonlinear models.
- Improved spectral-update robustness (damping oscillations)
- Sector: optimizer research, software tooling
- Use case: Address oscillatory behaviors observed with discrete spectral steps and Newton–Schulz approximations by adding damping, trust-region constraints, or adaptive operator-norm bounds.
- Tools/workflows: Implementation patches to Muon-like optimizers; stability monitors; convergence proofs.
- Assumptions/dependencies: Research into practical stabilization without losing speed advantages.
- Benchmark suites to evaluate optimizer-induced inductive biases
- Sector: academia, industry
- Use case: Curate tasks that probe shared representation learning, spurious reliance, modality imbalance, and curriculum dependence to compare optimizers systematically.
- Tools/workflows: Public datasets and leaderboards emphasizing OOD metrics and spectral diagnostics.
- Assumptions/dependencies: Community adoption; standardized protocols for spectral measurement.
- Bias-aware training pipelines for multi-modal foundation models
- Sector: large-scale AI, enterprise
- Use case: Architect pipelines that learn shared latent spaces (e.g., across text–image–audio) before accelerating with spectral optimizers; include continuous spectral auditing and OOD stress tests.
- Tools/workflows: Staged representation learning; spectrum-aware checkpoints; automated OOD probes.
- Assumptions/dependencies: Significant engineering and compute; needs task-specific mapping from spectra to semantics.
- Financial risk modeling guardrails
- Sector: finance
- Use case: Prevent shortcut learning on transient market artifacts by enforcing simplicity bias early; adopt optimizer switches and spectral regularization; mandate OOD backtests that remove suspected artifacts.
- Tools/workflows: Risk dashboards that incorporate spectral indicators; optimizer governance policies.
- Assumptions/dependencies: Availability of artifact-free test scenarios; strict compliance requirements.
In all cases, feasibility depends on the availability of spectral diagnostics at scale, careful validation of linear-theory insights in nonlinear models, and organizational willingness to trade some speed for generalization quality when warranted.
Collections
Sign up for free to add this paper to one or more collections.