Reasoning Theater: Disentangling Model Beliefs from Chain-of-Thought
Abstract: We provide evidence of performative chain-of-thought (CoT) in reasoning models, where a model becomes strongly confident in its final answer, but continues generating tokens without revealing its internal belief. Our analysis compares activation probing, early forced answering, and a CoT monitor across two large models (DeepSeek-R1 671B & GPT-OSS 120B) and find task difficulty-specific differences: The model's final answer is decodable from activations far earlier in CoT than a monitor is able to say, especially for easy recall-based MMLU questions. We contrast this with genuine reasoning in difficult multihop GPQA-Diamond questions. Despite this, inflection points (e.g., backtracking, 'aha' moments) occur almost exclusively in responses where probes show large belief shifts, suggesting these behaviors track genuine uncertainty rather than learned "reasoning theater." Finally, probe-guided early exit reduces tokens by up to 80% on MMLU and 30% on GPQA-Diamond with similar accuracy, positioning attention probing as an efficient tool for detecting performative reasoning and enabling adaptive computation.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple explanation of “Reasoning Theater: Disentangling Model Beliefs from Chain-of-Thought”
1) What is this paper about?
This paper looks at how AI “reasoning” models think and explain their answers. The authors ask: do these models really need all the step-by-step text they write (“chain-of-thought”), or are they sometimes just performing—writing long explanations even after they’ve already decided on an answer? They call this “reasoning theater.”
2) What questions did the researchers ask?
They focus on a few simple questions:
- When does a model actually “make up its mind” about an answer while it’s writing out its steps?
- Are long explanations always helpful, or are they sometimes just for show?
- Do harder questions force models to truly think step by step more than easier questions do?
- Can we detect the moment the model already knows the answer and stop it early to save time and cost?
3) How did they study it? (Everyday analogies included)
They tested two large reasoning models on two kinds of multiple-choice tests:
- MMLU (many school-like subjects, often answerable by recalling facts).
- GPQA-Diamond (very hard science questions that usually need multi-step reasoning).
They used three main tools, which you can think of like this:
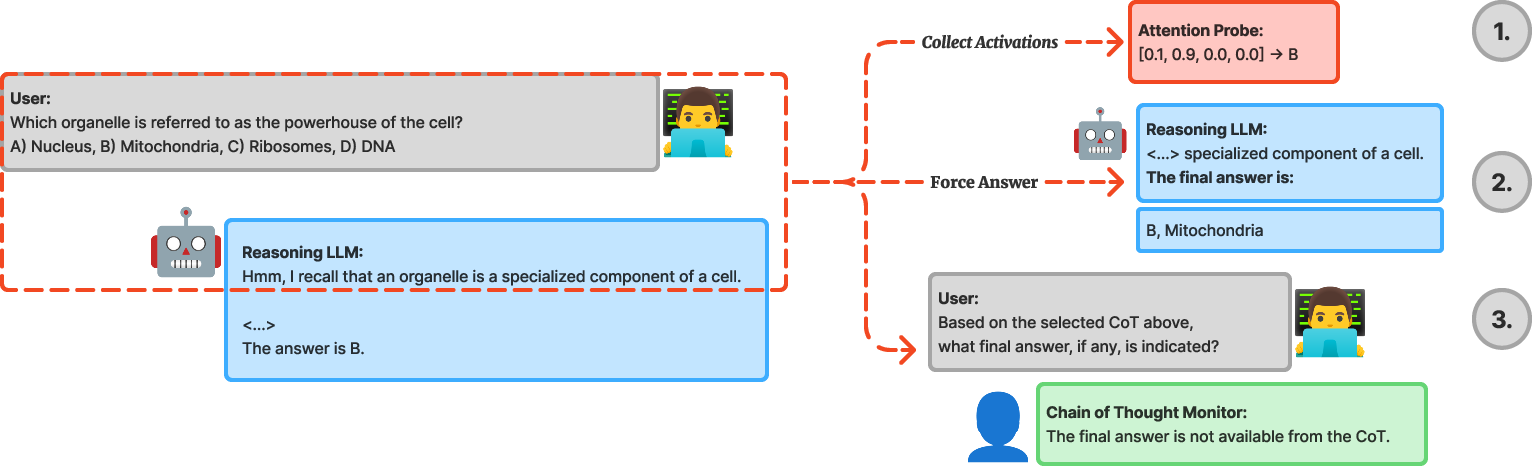
- Attention probes (like a “brain scan” for the model): They trained a tiny classifier that reads the model’s internal activations (its hidden signals while thinking) to guess which answer the model is leaning toward at every point. If the probe can guess the final answer early, it means the model has already decided internally—even if it keeps writing steps.
- Forced answering (like interrupting a student mid-scratch work): They stop the model partway through its reasoning and say, “Answer now.” If it can correctly answer early, that shows it didn’t need all the remaining steps.
- Chain-of-thought monitor (like a teacher reading notes): A separate AI reads the partial explanation and tries to tell if the model has already settled on an answer. This only uses the visible text, not the internal signals.
By comparing these three, they can spot when the model “knows” the answer internally but keeps writing as if it doesn’t.
4) What did they find, and why is it important?
Here are the main takeaways, with why they matter:
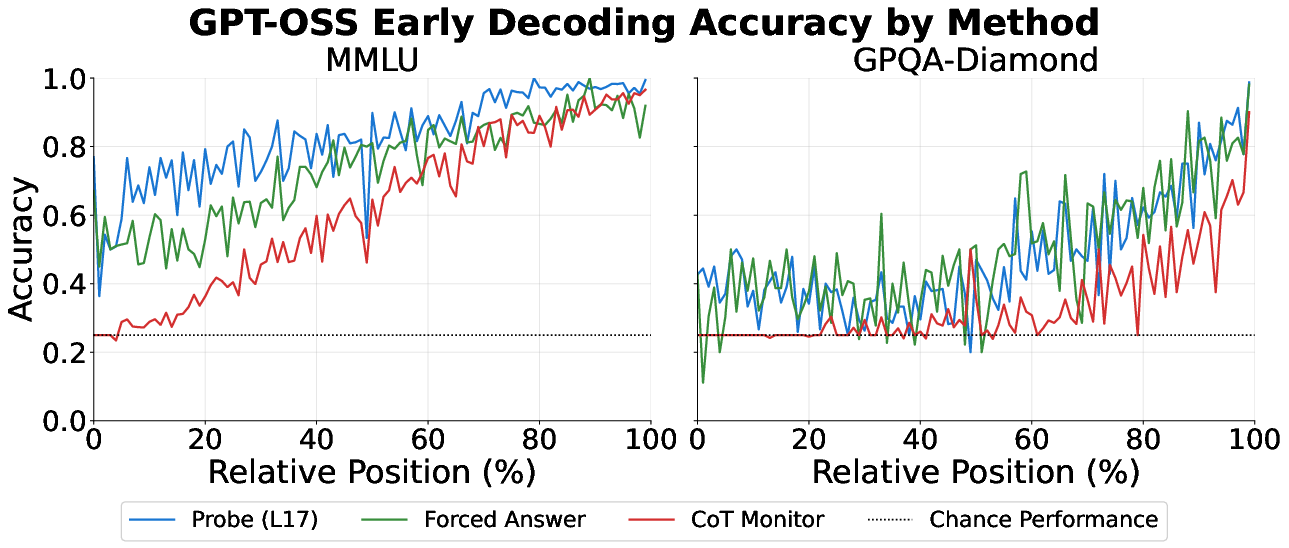
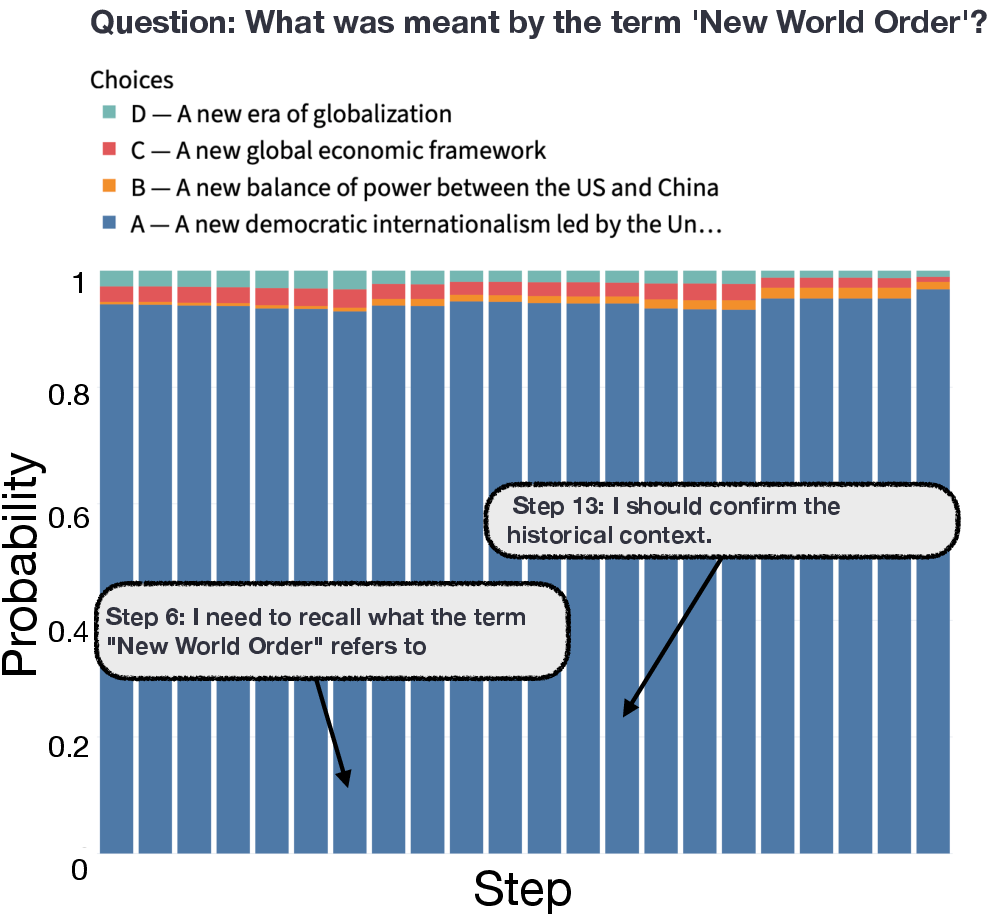
- Easier questions often produce “reasoning theater.” On the easier MMLU questions, the probe and forced answering could predict the final answer very early, but the chain-of-thought monitor (reading only the text) didn’t see a clear commitment until much later. Why it matters: The model is confident inside but acts uncertain outside—so reading its steps can be misleading if you’re trying to judge whether it has really decided.
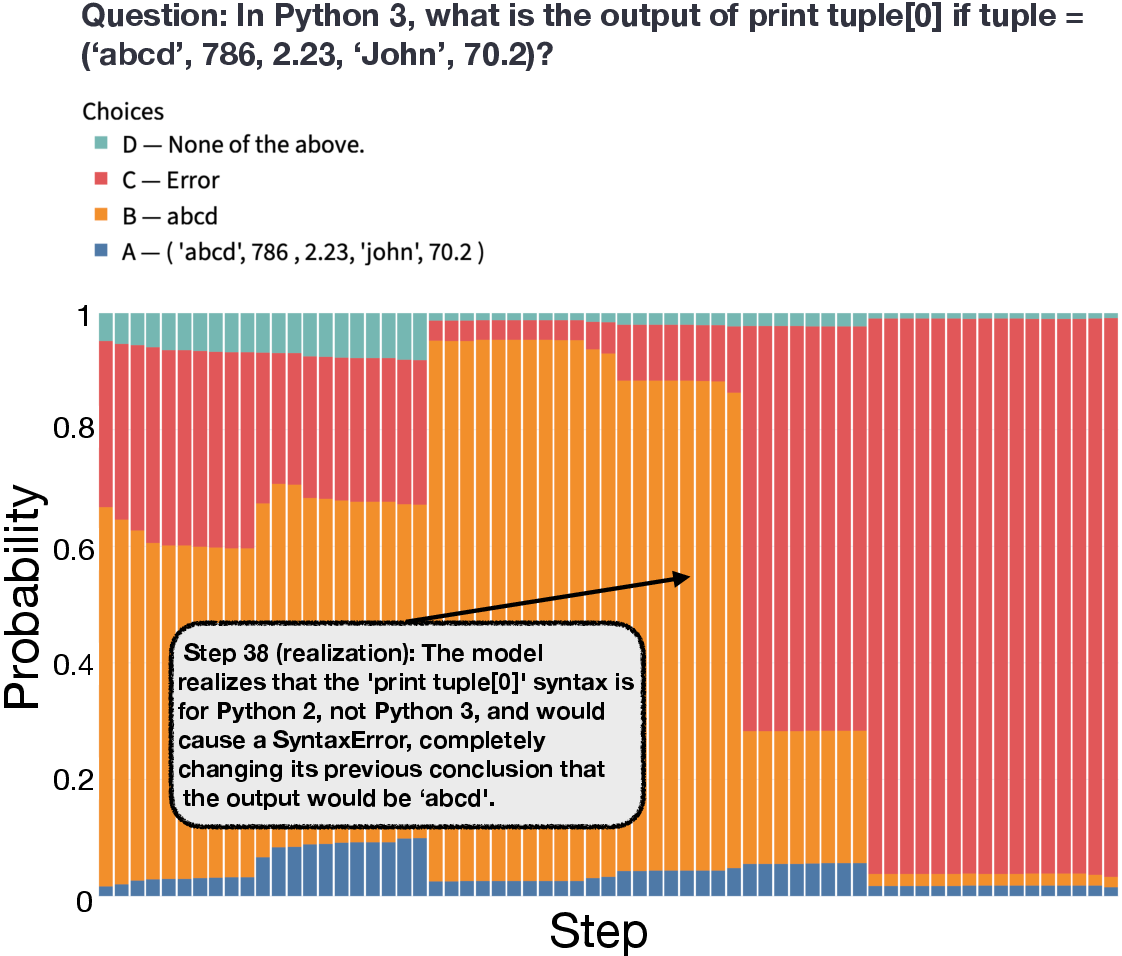
- Hard questions show more genuine reasoning. On the very hard GPQA-Diamond questions, all three methods improved together over time. The internal confidence rose gradually and matched what the text suggested. Why it matters: For tough problems, the model’s written steps are more honest about what it knows and when it figures things out.
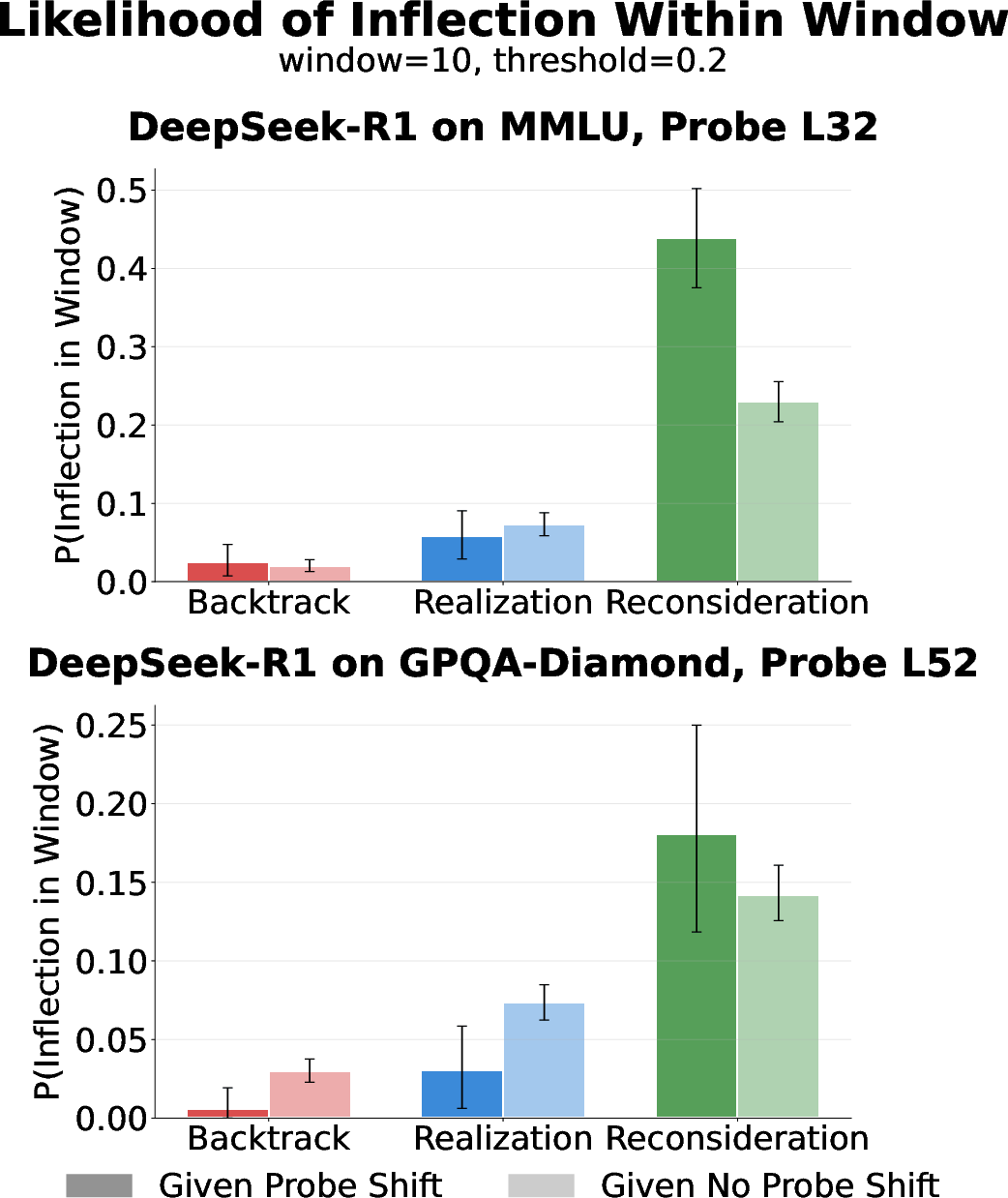
- “Aha” moments and backtracking usually reflect real changes in belief. When the model’s explanation shows a realization, reconsideration, or backtrack, those moments tend to happen more in answers where the internal confidence is changing—meaning they’re often genuine, not just for show. Why it matters: Not all long explanations are fake; signs of struggle can be real and informative.
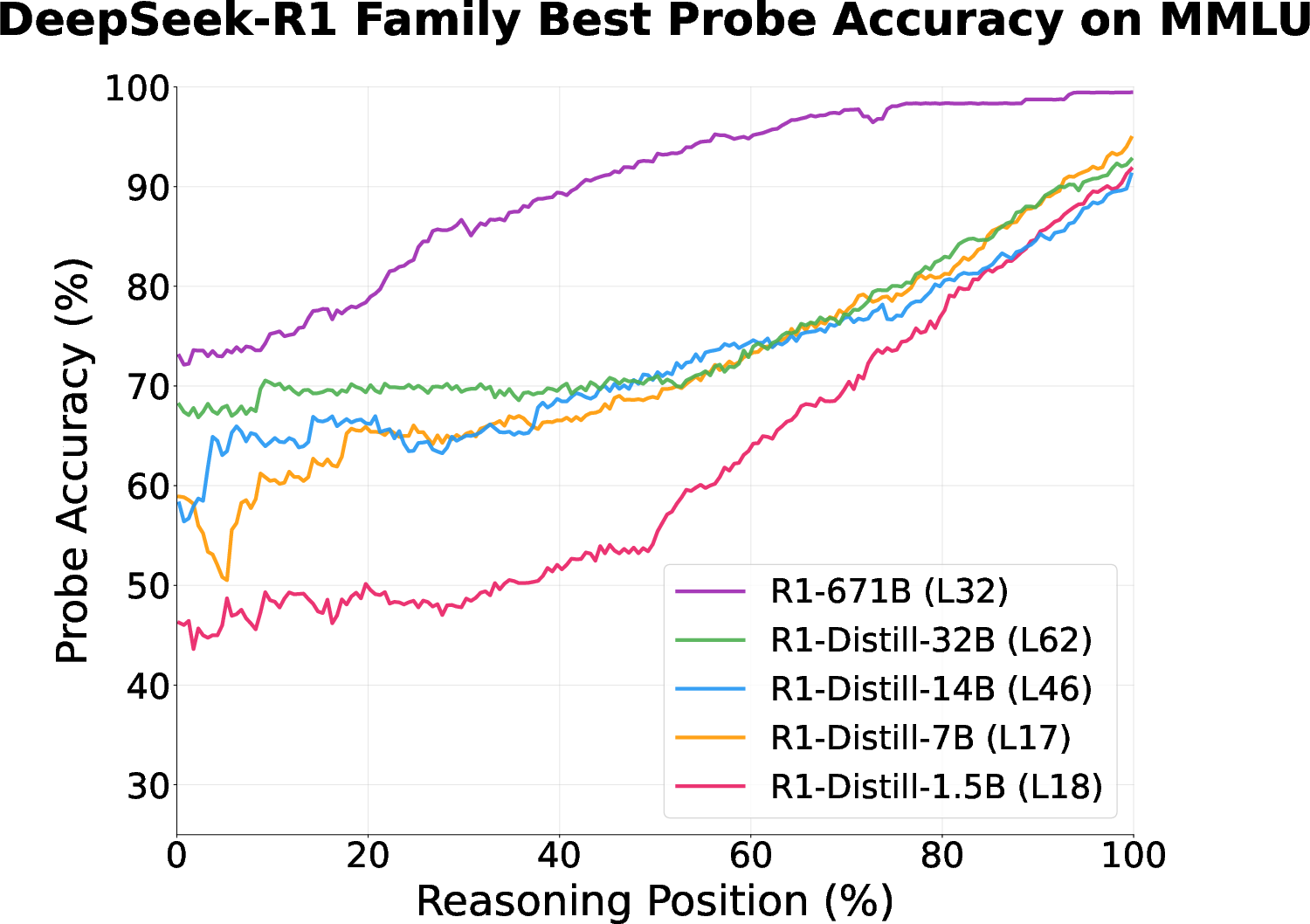
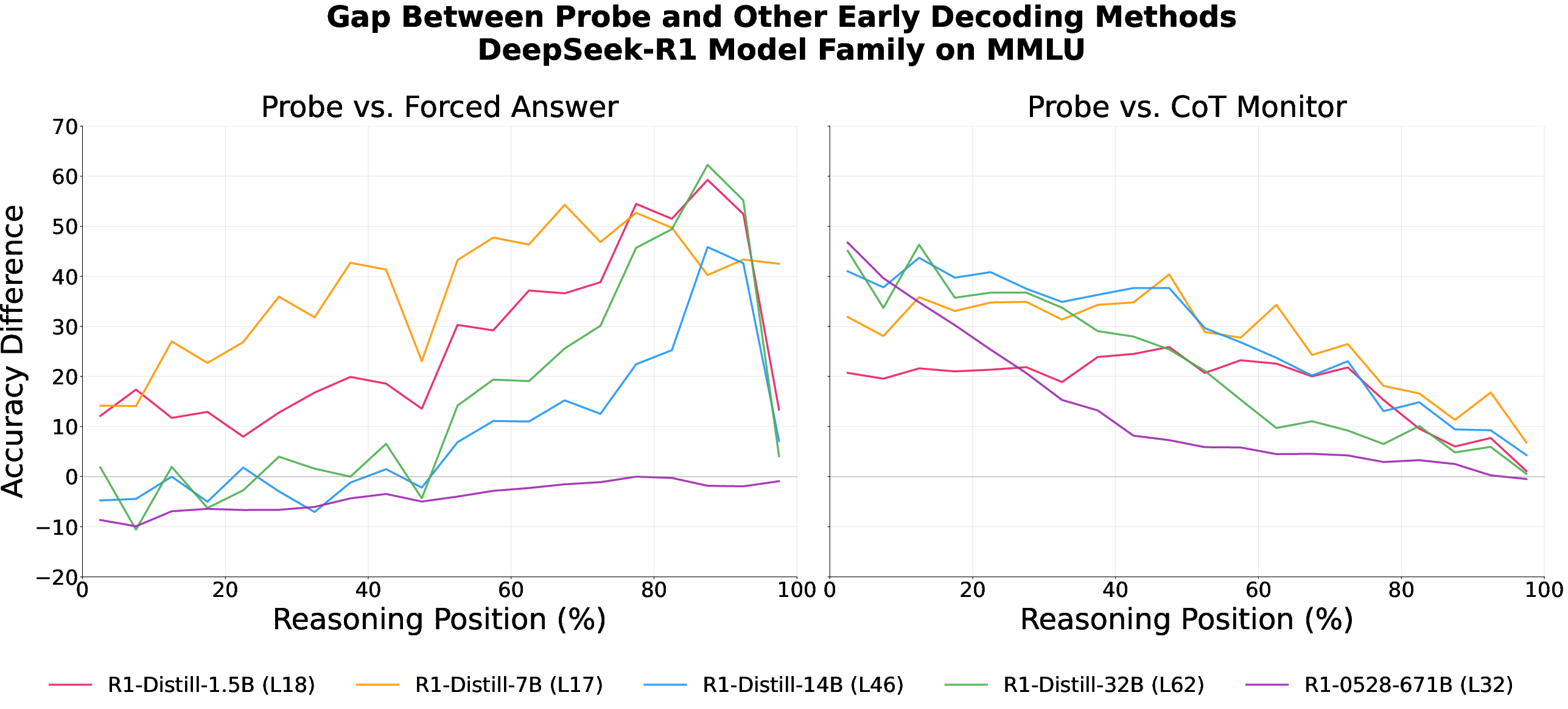
- Bigger models can be more performative on easy tasks. Larger models often “know” the answer earlier on easy questions and still keep writing. Smaller models tend to need more real thinking time and are less performative in that setting. Why it matters: Model size and task difficulty both affect how faithful the chain-of-thought is.
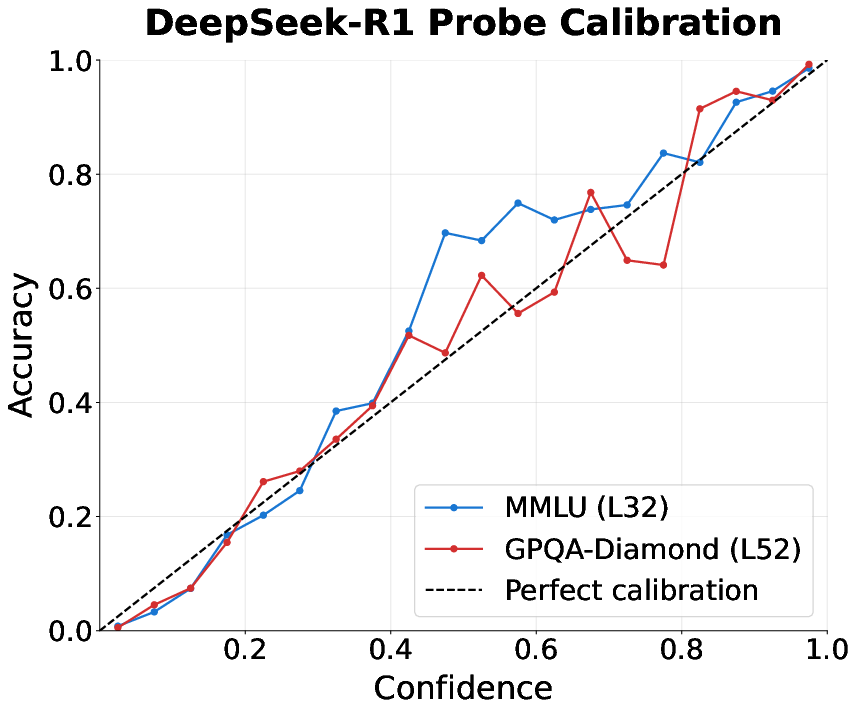
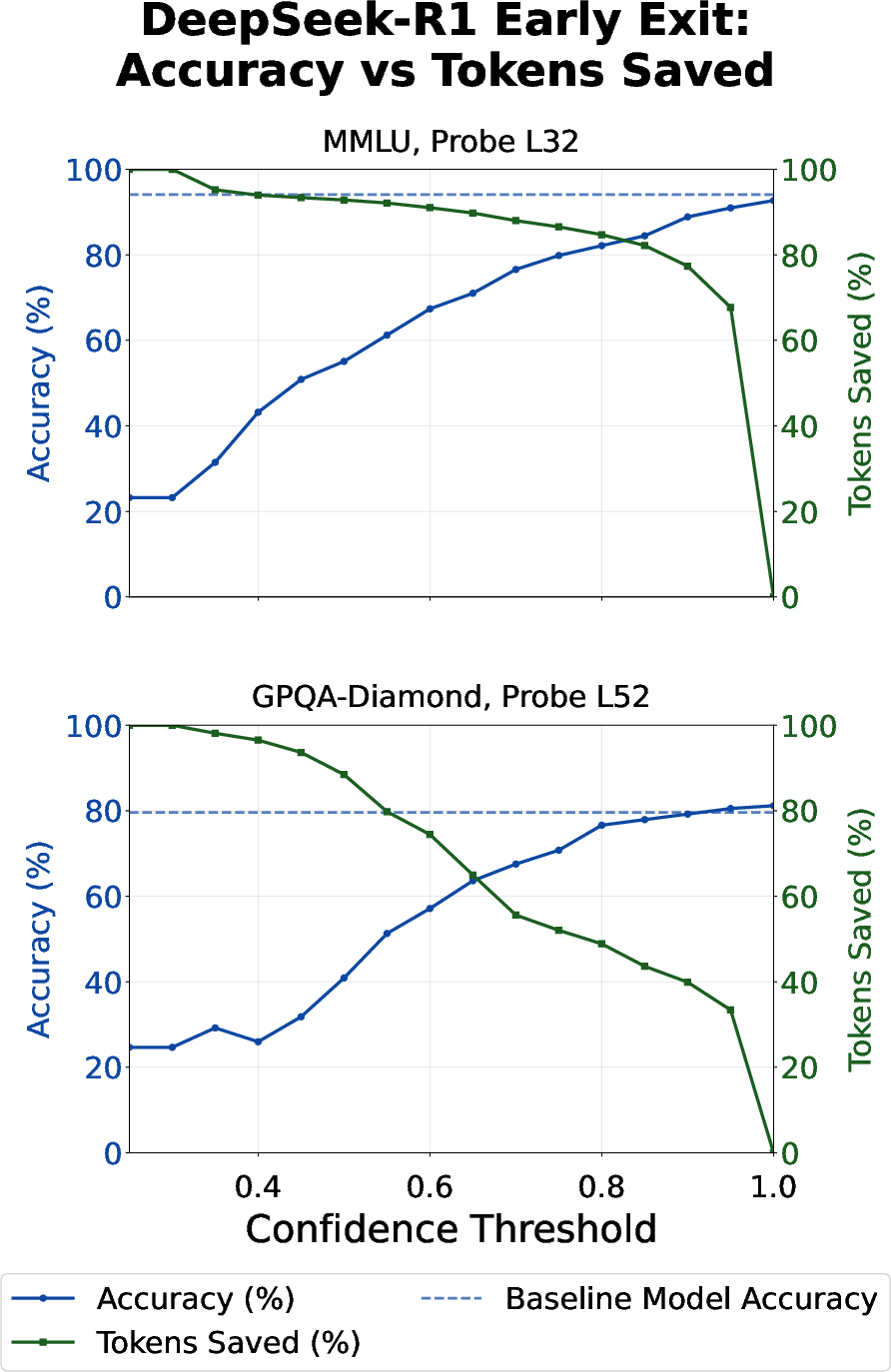
- You can save a lot of time and money by exiting early. Because the probes are well-calibrated (their confidence matches actual correctness pretty well), you can set a confidence threshold: once the model’s internal signal is strong enough, stop the reasoning and output the answer. Results: Up to about 80% fewer tokens on MMLU and around 30–40% fewer on GPQA, with almost the same accuracy. Why it matters: This makes AI systems faster and cheaper without hurting performance much.
5) What does this mean going forward?
- Don’t blindly trust long explanations. On easier, recall-based questions, a model might already know the answer and keep writing anyway. If you rely only on the written steps to judge confidence or honesty, you can be misled.
- For hard problems, the chain-of-thought is more likely to show genuine thinking. Signs like backtracking or “aha” moments often reflect real internal changes.
- Monitoring inside the model (with probes) can help detect early confidence and enable smart “early exits,” making AI systems more efficient.
- Safety and oversight tools that only read text should be used with caution. Models aren’t always “cooperative speakers”—they may not reveal their true confidence right away. Combining text monitoring with internal signals can give a fuller, more trustworthy picture.
In short: sometimes the model is performing, sometimes it’s genuinely reasoning. Knowing the difference helps us interpret its explanations better and build faster, more reliable AI systems.
Knowledge Gaps
Unresolved Knowledge Gaps, Limitations, and Open Questions
Below is a consolidated list of concrete gaps and open problems that the paper leaves unaddressed and that future work could act on:
- External validity across tasks: results are shown on two multiple-choice benchmarks (MMLU-Redux and GPQA-Diamond); it remains unknown whether findings hold for open-ended reasoning (math proofs, program synthesis, scientific explanations) or tasks without fixed answer options.
- Generalization beyond English and benchmark style: no analysis for multilingual settings, varying domain styles (legal, clinical), or longer-context scenarios where CoT is much longer or interleaved with tool use/retrieval.
- Model coverage: only two frontier open-weight reasoning models (plus R1 distills) are studied; effects on closed models (e.g., o1/o3), base models (pre-RL), non-transformer architectures, or models trained with different RL objectives are untested.
- Training-procedure ablation: the paper does not isolate how RL for reasoning (vs. SFT-only vs. base) changes performativity; a controlled pre-/post-RL within-architecture study is missing.
- Sensitivity to decoding settings: temperature, nucleus sampling, and prompt formatting can change CoT style and commitment timing; the robustness of “performativity” claims to decoding hyperparameters is not evaluated.
- Monitor dependence: conclusions about CoT monitors rely on a single monitoring model (Gemini-2.5-Flash) and one prompt; no monitor ensemble, ablation of prompt strictness, or calibration of how often monitors mistakenly “compute the answer” vs. “listen” is provided.
- Performativity metric validity: the “performativity rate” (slope gap) is ad hoc and lacks uncertainty estimates; there is no statistical testing, bootstrap CIs, or sensitivity analysis to binning/smoothing choices.
- Ground-truth vs. model-belief disentanglement: probes are trained to predict the model’s final choice, not necessarily the correct answer; more direct analysis is needed to determine when early-decoded beliefs are correct vs. wrong and later corrected by genuine reasoning.
- Failure mode characterization of early exit: while average accuracy is retained, the paper does not analyze error types introduced by early exit (e.g., overconfident early wrong answers), nor the distribution of “rescued” vs. “doomed” cases if reasoning continues.
- Multiple-choice constraint: attention probes predict among four A–D choices; the method’s extension to free-form answers (span extraction, numeric answers, code) is not demonstrated.
- Probe selection bias: results are reported using the “best-performing layer”; it is unclear whether layer selection is validated without test-set leakage or how stable best layers are across tasks and seeds.
- Probe architecture breadth: only attention-pooling probes are tested; comparisons to alternative sequence pooling (e.g., multi-head pooling, hierarchical pooling), per-head probes, SAEs, or causal probes are missing.
- Causality of “internal commitment”: early decodability may reflect strong priors or shallow cues rather than commitment; causal tests (e.g., activation patching, representational ablations, logit-lens controls, label remapping) are needed to verify commitment vs. bias.
- Temporal granularity mismatch: probes operate at token-level while monitors operate at step-level; the impact of this mismatch on timing comparisons and “gap” estimates is not quantified.
- Step segmentation assumption: step boundaries are defined by “double newline” heuristics; robustness to alternative segmentation (sentence-level, punctuation-based, model-internal boundaries) is untested.
- Inflection labeling reliability: inflection points (backtracking/realization/reconsideration) are labeled by an LLM without human validation; inter-annotator agreement or adjudication is absent.
- Inflection–belief link ambiguity: the local window co-occurrence analysis shows sensitivity to thresholds and window sizes; more principled temporal models (e.g., point processes, dynamic Bayesian networks) or causal analyses are needed to map internal belief updates to verbal inflections.
- Monitor fairness and capability confound: the monitor’s knowledge and capability may differ from the reasoner’s; the paper does not quantify how monitor–reasoner capability gaps affect detection of early commitments.
- Robustness to adversarial prompting: the model might obfuscate or reveal confidence via prompt styles; whether performativity can be reduced or amplified by instructions (e.g., “be concise,” “state your current best guess”) is unknown.
- Adversarial robustness of probes: the paper does not test whether models can be trained (or prompted) to hide internal commitments from probes or to route answer information away from probed subspaces.
- Deployment feasibility: the compute/memory cost of collecting per-token per-layer activations and running probes in the decoding loop (especially on 100B+ models) is not quantified; wall-clock latency and throughput trade-offs for early exit are unclear.
- Closed-weight applicability: activation probing requires internal access; strategies for monitoring closed models (e.g., logit-only probes, API-observable features) are not explored.
- Early-exit policy design: only fixed confidence thresholds are studied; budgeted or risk-aware policies (e.g., constrained tokens, dynamic thresholds, per-task calibration) are not developed.
- Distribution shift and calibration: probe calibration is shown on MMLU/GPQA, but robustness under domain shift, new subjects, or longer contexts is untested; no temperature scaling or recalibration procedures are provided.
- Subject-level heterogeneity: MMLU has 57 subjects; the paper does not analyze which subjects are most/least performative, nor whether subject difficulty correlates with performativity within-dataset.
- Tool use and external knowledge: tasks without retrieval/tools may exaggerate “recall vs. reasoning” distinctions; whether tool-augmented reasoning reduces performativity is unknown.
- Safety trade-offs: early exit saves tokens but may remove textual evidence useful for downstream auditing/verification; the paper does not propose a joint strategy that preserves auditability while reducing compute.
- Mechanistic interpretability link: no circuit- or head-level mechanisms are identified to explain where and how answer information consolidates; integrating SAEs or causal tracing could turn phenomenology into mechanism.
- Training for cooperative speakers: the Gricean framing is not operationalized; concrete training interventions (rewarding calibrated commitment disclosure, penalizing unnecessary verbosity, or auxiliary losses for “belief state exposure”) are not tested.
- Monitor–speaker co-training: methods to co-train a reasoner and a monitor for mutual intelligibility (e.g., RSA-inspired objectives) remain an open avenue.
- Forced answer prompt confound: early answering entails extra forward passes that may aggregate information; the extent to which this alters internal state vs. reads it out is not disentangled.
- Token-level vs. step-level agreement: the exact timing at which answer information surpasses a confidence threshold vs. when the textual trace signals commitment is not rigorously aligned; more precise synchronization is needed.
- Public reproducibility: training/activations for a 671B model are compute-heavy; the paper does not provide lightweight surrogates, reduced-scale replications, or full activation releases to enable wider reproduction.
Practical Applications
Below are practical, real-world applications that follow from the paper’s findings and methods. Each item names sectors, suggests tools/products/workflows, and notes assumptions or dependencies that affect feasibility.
Immediate Applications
The following applications can be deployed now using existing open-weight models and standard ML engineering practices.
- Probe‑guided early exit for LLM inference cost/latency reduction
- Sectors: Software, Cloud AI, Enterprise IT, Energy/Sustainability
- Tools/workflows: Integrate an attention‑pooling activation probe into the inference loop; set a calibrated confidence threshold to stop chain-of-thought (CoT) generation and emit the answer; expose a “fast mode” API parameter that trades off tokens for confidence.
- Impact: Up to ~80% token savings on recall‑style tasks (e.g., MMLU‑like) and ~30–40% on harder tasks (e.g., GPQA‑like) with minimal accuracy loss, per the paper.
- Assumptions/dependencies: White‑box or semi‑white‑box access to model activations; per‑model probe training and calibration; small runtime overhead for probe forward passes.
- Adaptive “think budget” controllers in agent frameworks
- Sectors: Software/Agent frameworks, Robotics (planning modules), FinTech/Legal assistants
- Tools/workflows: Add a runtime controller that monitors probe confidence and halts ReAct/ToT style thinking when the model is already committed; escalate to more steps only if confidence remains low.
- Assumptions/dependencies: Access to activations during generation; controller policy tuned per task domain; monitoring for distribution shifts.
- Confidence‑aware UX in assistants (“Quick Answer” vs “Deliberate” mode)
- Sectors: Consumer AI, Productivity suites, Education
- Tools/workflows: Surface a calibrated confidence indicator powered by probes; auto‑shorten or suppress rationales on easy queries; allow users to request deeper reasoning when confidence is low.
- Assumptions/dependencies: Reliable calibration across intents; guardrails to avoid misleading overconfidence; on some platforms, activations may be inaccessible (work with compatible open models).
- MLOps metric for performative CoT to choose prompting/training strategies
- Sectors: ML Platform/DevOps, Model evaluation
- Tools/workflows: Track “performativity rate” (gap between activation‑based early decoding and CoT‑monitor accuracy) per task; route tasks with high performativity to brief answers, and low performativity to full CoT.
- Assumptions/dependencies: Off‑policy CoT monitoring baseline; probe training on representative data; aggregation dashboards.
- Task routing: recall vs reasoning separation
- Sectors: Enterprise knowledge management, Customer support, Search
- Tools/workflows: Use early‑decoding signals to classify queries as recall‑heavy vs multi‑hop; apply short, efficient pipelines to recalls and longer deliberate pipelines to true reasoning items.
- Assumptions/dependencies: Stable mapping between benchmarks and real workloads; monitoring to prevent misclassification on domain shifts.
- Safety/oversight trigger for early commitment
- Sectors: AI Safety, Platform trust & safety, Regulated industries (Healthcare/Finance/Legal)
- Tools/workflows: If probes indicate strong early commitment to a risky action or answer while CoT remains noncommittal, pause or escalate to human review; log internal‑external divergence.
- Assumptions/dependencies: Policy definitions of “risky commitment”; accurate probe confidence in relevant domains; secure handling of activation data.
- Energy and cost accounting via adaptive compute
- Sectors: Cloud/Edge AI, Sustainability
- Tools/workflows: Automatically report and reduce per‑request energy/COGS by exiting early when probe confidence is high; surface sustainability KPIs.
- Assumptions/dependencies: Metering/token accounting; verification that accuracy remains within SLAs; calibration refresh as models update.
- Benchmarking and auditing of CoT faithfulness
- Sectors: Academia, Evaluation vendors, Procurement
- Tools/workflows: Add “performativity gap” and “slope difference” metrics to eval suites; publish dashboards comparing probe/forced‑answer/monitor curves across tasks and versions.
- Assumptions/dependencies: Reproducible access to activations and consistent inference settings; neutral monitoring model (e.g., Gemini‑class or internal).
- Data collection acceleration for distillation/fine-tuning
- Sectors: Model training, LLMOps
- Tools/workflows: Use probe confidence to truncate long CoTs during data generation, reducing token budgets while keeping accurate targets; label “aha/backtrack” segments for curriculum design.
- Assumptions/dependencies: Probes remain accurate during teacher model drift; ensure no degradation from shorter traces for student models.
- On‑device/edge assistants with lower latency/power
- Sectors: Mobile/Embedded, Automotive, IoT
- Tools/workflows: Deploy small open models with probe‑based early exit to reduce wall‑clock latency and power draw when questions are easy.
- Assumptions/dependencies: Memory budget for probe parameters; activation access on device; careful calibration due to smaller models’ different performativity profiles.
Long‑Term Applications
These require further research, vendor cooperation, or ecosystem changes (e.g., standardized activation access, training objective changes, or certification regimes).
- Standardized “activation API” from model vendors
- Sectors: Cloud AI platforms, Model providers
- Tools/workflows: Offer secure, bandwidth‑limited summaries or pooled signals sufficient for probe inference, enabling early exit and safety monitoring on closed models.
- Assumptions/dependencies: Privacy/security analysis; performance overhead controls; contractual/regulatory frameworks for internal signal exposure.
- Training objectives that align internal beliefs with CoT (reduce performativity)
- Sectors: Model training, Safety research
- Tools/workflows: Add auxiliary losses/rewards that penalize unnecessary verbosity post‑commitment or reward honest early commitment; integrate probe signals into RL training.
- Assumptions/dependencies: Avoiding reward hacking (e.g., silent commitments); balancing performance across hard tasks where extended CoT is beneficial.
- Certified “monitorability” benchmarks and procurement standards
- Sectors: Government, Enterprise procurement, Standards bodies
- Tools/workflows: Require vendors to report performativity metrics, probe calibration curves, and task‑dependent gaps to certify monitorability in high‑risk deployments.
- Assumptions/dependencies: Consensus on metrics and thresholds; third‑party auditing capacity.
- Real‑time intent/risk detectors using activation probes
- Sectors: Safety & compliance, Content moderation, Cybersecurity
- Tools/workflows: Train probes to detect early emergence of harmful intent or prohibited targets before they are verbalized; preempt generation or route to guarded tools.
- Assumptions/dependencies: High precision in adversarial settings; robust generalization beyond benchmarks; governance for false positives/negatives.
- Neuro‑symbolic controllers for compute allocation
- Sectors: Agents/Planning, Robotics
- Tools/workflows: Combine activation‑level belief tracking with planning heuristics to allocate token budgets adaptively across subgoals; finalize plans when belief stabilizes.
- Assumptions/dependencies: Reliable mapping from probe signals to subgoal completion; integration with planners.
- Cross‑model transferable probes and privacy‑preserving probing
- Sectors: Platforms, Research tools
- Tools/workflows: Develop probes that generalize across model families or use distilled representations/TEEs to avoid raw activation exposure while enabling early exit decisions.
- Assumptions/dependencies: Domain adaptation methods; performance trade‑offs vs per‑model probes; secure enclave or cryptographic mechanisms.
- Human‑centered explanation policies tied to internal belief dynamics
- Sectors: UX/Design, Regulated industries
- Tools/workflows: Dynamically adjust explanation length/structure based on whether the model truly “reasoned” vs recalled; disclose confidence and whether CoT contributed substantively.
- Assumptions/dependencies: Clear thresholds for “genuine reasoning”; user studies to validate trust/understanding impacts.
- Curriculum and assessment design that elicits genuine reasoning
- Sectors: Education, Certification, HR testing
- Tools/workflows: Use performativity diagnostics to construct assessments where reasoning is necessary (e.g., GPQA‑like), reducing misleading CoT effects.
- Assumptions/dependencies: Task authoring expertise; avoidance of construct‑irrelevant difficulty; fairness/equity considerations.
- Sustainable AI planning via compute‑aware pipelines
- Sectors: Sustainability programs, Cloud optimization
- Tools/workflows: System‑level schedulers that use activation‑derived confidence to cap token budgets fleet‑wide, meeting service and carbon targets.
- Assumptions/dependencies: Fleet telemetry; accuracy SLAs; dynamic calibration under traffic changes.
- Legal/ethical frameworks for internal‑state monitoring
- Sectors: Policy, Compliance, Ethics
- Tools/workflows: Guidance on permissible use of internal activations for oversight; audit trails for internal‑external divergences; safeguards against manipulating internal states for deceptive transparency.
- Assumptions/dependencies: Stakeholder consensus; alignment with privacy and AI Act‑style regulations.
- Multi‑task, domain‑robust probing and continual calibration
- Sectors: Enterprise AI, Research
- Tools/workflows: Build probe training pipelines that continuously adapt to new domains; evaluate stability of calibration and performativity over time and model updates.
- Assumptions/dependencies: Data pipelines for incremental learning; monitoring for probe drift; rollback mechanisms.
Notes on feasibility and dependencies across applications:
- Activation access is the key dependency; most immediate gains are realizable today with open‑weight models or cooperative providers.
- Probes are model‑specific and require small but non‑zero training/maintenance; calibration quality governs safe thresholds for early exit.
- The performativity/genuineness split is task‑dependent; deployments should route tasks and set confidence thresholds per domain, and continuously evaluate on target distributions.
- CoT monitors alone can lag internal beliefs; combining activation‑level signals with textual monitors yields better coverage for both efficiency and safety.
Glossary
- Activation probing: Training lightweight classifiers on internal activations to decode latent information (e.g., the model’s belief or answer). Example: "Activation probing is a practical way to extract latent information from a model's internals"
- Adaptive computation: Dynamically allocating or terminating computation during inference based on confidence or internal signals. Example: "positioning attention probing as an efficient tool for detecting performative reasoning and enabling adaptive computation."
- Attention probes: Probes that use attention to pool token-level activations over a sequence to predict targets like the final answer. Example: "Attention Probes: We train attention probes on varying-length activations of text to predict the model's final answer."
- Attention-weighted pooling: Aggregating token representations with learned attention weights to form a pooled representation for prediction. Example: "via attention-weighted pooling of the model's hidden states:"
- Backtracking: A reasoning inflection where a model revises or reverses prior steps or conclusions. Example: "inflection points (e.g., backtracking, `aha' moments) occur almost exclusively in responses where probes show large belief shifts"
- Black-box approaches: Methods that analyze models via inputs and outputs without accessing internals. Example: "Black-box approaches study longer responses directly via the output text"
- Calibration curves: Plots comparing predicted probabilities to empirical accuracies to assess calibration. Example: "Calibration curves for the most accurate attention probes for DeepSeek-R1 on MMLU and GPQA-Diamond."
- Chain-of-thought (CoT): Step-by-step natural language reasoning produced by a model to solve a problem. Example: "Chain-of-thought (CoT) has emerged as a powerful method to improve LLM performance"
- Chain-of-thought monitor (CoT monitor): An LLM used to evaluate another model’s partial CoT for commitments or issues. Example: "A CoT monitor is a LLM for evaluating another model's response"
- Compound reward: An RL training objective combining multiple reward components. Example: "train R1 with a sophisticated compound reward"
- Cross-entropy loss: A standard classification loss measuring divergence between predicted and true distributions. Example: "using cross-entropy loss across all token positions in each reasoning trace."
- Distilled models: Smaller models trained to imitate larger ones, preserving behavior at reduced cost. Example: "the set of distilled DeepSeek-R1 Qwen2.5 models (1.5B, 7B, 14B, 32B)"
- Early answering: Forcing a model to give its final answer before completing its CoT. Example: "Forced answer prompting (i.e., early answering) is a method that has been used for validating whether models rely on their chain-of-thought reasoning"
- Early decoding: Inferring the model’s eventual final answer from early prefixes or internals. Example: "Early decoding helps us identify performative reasoning"
- Early exit: Halting generation once an internal or external criterion indicates sufficient confidence. Example: "enabling confidence-based early exit that substantially reduces generation without sacrificing accuracy."
- Forced answer prompting: A procedure that truncates reasoning and prompts the model to output its final choice immediately. Example: "Forced answer prompting (i.e., early answering) is a method that has been used for validating whether models rely on their chain-of-thought reasoning"
- GPQA-Diamond: A challenging subset of the GPQA benchmark requiring graduate-level science knowledge. Example: "GPQA-Diamond is a harder subset of the GPQA dataset"
- Gricean cooperation: The idea that communicators follow pragmatic maxims (quality, quantity, relation, manner); used to analyze CoT faithfulness. Example: "Gricean cooperation is incidental: Relation (relevance) and Quality (supported evidence) are typically aligned with reward, while Quantity (verbosity) and Manner (obscurity) are not."
- Inflection points: Notable moments in CoT such as backtracking, realizations, or reconsiderations that indicate shifts in reasoning. Example: "inflection points like backtracking, sudden realizations (`aha' moments), and reconsiderations appear almost exclusively in questions that also contain large shifts in internal confidence"
- Linear probes: Simple linear classifiers trained on activations to decode features; used here as a baseline. Example: "Traditional linear probes fail at this task"
- MMLU-Redux 2.0: A revised version of the MMLU benchmark spanning many domains. Example: "MMLU-Redux-2.0 is composed of 5700 questions across 57 domains"
- Multihop reasoning: Solving questions by chaining multiple intermediate steps or facts. Example: "multihop GPQA-Diamond questions."
- Off-policy: Refers to evaluation or prompting that does not follow the model’s original generation policy. Example: "off-policy nature of the prompting scheme."
- Performativity: The gap between internal belief (as probed or forced) and what is expressed in CoT. Example: "We define performativity as the gap in accuracy between the CoT monitor and the probe or forced answer methods."
- Performative chain-of-thought: CoT that performs step-by-step reasoning without faithfully reflecting the model’s internal commitments. Example: "performative chain-of-thought (CoT) in reasoning models"
- Performative reasoning: Generating reasoning text that does not reveal an already-formed internal answer or confidence. Example: "positioning attention probing as an efficient tool for detecting performative reasoning"
- Probe-guided early exit: Using probe confidence to decide when to stop generation. Example: "Finally, probe-guided early exit reduces tokens by up to 80% on MMLU and 30% on GPQA-Diamond with similar accuracy"
- Quadratic fit: A smoothing technique fitting a quadratic curve to measurements over steps. Example: "We apply a quadratic fit before computing slopes to smooth over response-count variance"
- Rational Speech Acts (RSA): A probabilistic framework modeling pragmatic speaker-listener reasoning. Example: "under rational speech acts (RSA)"
- Residual stream activations: The per-token hidden representations in a transformer’s residual stream used for probing. Example: "on residual stream activations"
- Test-time compute: The amount of computation performed during inference, such as extended CoT generation. Example: "Harder tasks that require test-time compute exhibit genuine reasoning"
- White-box approaches: Methods that access and use internal model states or parameters for analysis. Example: "compare black-box LM monitors and white-box attention probes"
Collections
Sign up for free to add this paper to one or more collections.