NOBLE: Accelerating Transformers with Nonlinear Low-Rank Branches
Abstract: We introduce NOBLE (Nonlinear lOw-rank Branch for Linear Enhancement), an architectural augmentation that adds nonlinear low-rank branches to transformer linear layers. Unlike LoRA and other parameter-efficient fine-tuning (PEFT) methods, NOBLE is designed for pretraining from scratch. The branch is a permanent part of the architecture as opposed to an adapter for finetuning on top of frozen weights. The branch computes σ(xWdown)Wup where σ is a learnable nonlinearity. We evaluate several activation functions and find that CosNet, a two-layer cosine nonlinearity with learnable frequency and phase with a linear projection in between them in the bottleneck space, performs best. NOBLE achieves substantial improvements with minimal overhead: up to 1.47x step speedup to reach baseline eval loss (up to 32% fewer training steps), with as low as 4% additional parameters and 7% step time overhead, resulting in up to 1.22x net wallclock speedup. Experiments on LLMs (250M and 1.5B parameters), BERT, VQGAN, and ViT consistently show improved training efficiency. We identify one caveat: Mixup/CutMix augmentation interferes with NOBLE's benefits in Imagenet classification along with other stochastic augmentations, but when disabled, ViT also improves. This discrepancy is possibly explained by regularization techniques that encourage smoother fits to the target function while NOBLE may specialize more in sharper aspects of the target function.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Easy-to-Understand Summary of “NOBLE: Accelerating Transformers with Nonlinear Low-Rank Branches”
Overview: What is this paper about?
This paper introduces NOBLE, a small upgrade you can add to the “linear” parts of transformer models (the kind used in ChatGPT, BERT, and Vision Transformers). The goal is to help these models learn faster during training without making them much bigger or slower. NOBLE adds a tiny “side branch” that uses curved, wave-like math (cosines) to capture details the straight-line parts can’t. That helps the model reach the same quality in fewer training steps.
Key questions the researchers asked
The authors focused on a few simple questions:
- Can we make transformers learn faster by adding a small, clever side branch that’s trained from the very start (not just for fine-tuning)?
- What kind of nonlinearity (the “shape” of the function in the branch) works best?
- Does this idea help across different types of models and tasks (language and vision)?
- What’s the tradeoff between the extra work per step and the total time saved?
How NOBLE works (with simple analogies)
Transformers use lots of “linear layers,” which you can think of as tools that draw straight lines. They’re fast and powerful, but sometimes you also need curves to capture fine details.
NOBLE adds a small “bypass lane” around each linear layer:
- It compresses the input into a few numbers (this is the “low-rank” part — think of squeezing information through a narrow hallway).
- It bends that compressed signal using a nonlinear function (a curve), then
- Expands it back and adds it to the original output.
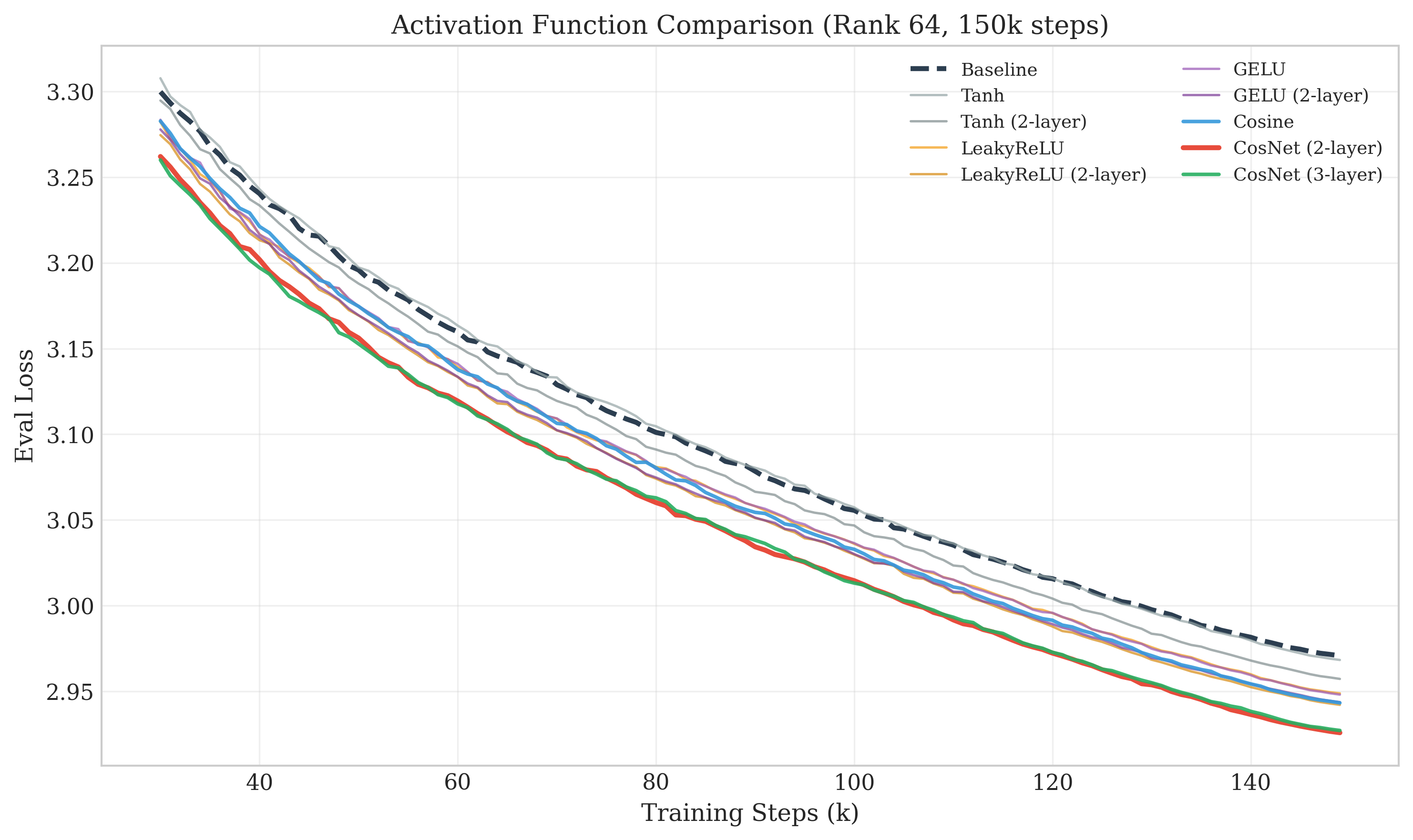
The special sauce is the nonlinearity called “CosNet,” which uses cosine waves with adjustable frequency and phase (like changing the pitch and timing of a sound). Using two of these wave steps with a tiny mixing layer in between helps the model capture patterns that straight lines miss — especially the “fine-grained” or “wiggly” patterns.
Other practical choices they make so this works well:
- Start the bypass very small so it doesn’t overwhelm the main path at the beginning.
- Give the bypass certain parts a slightly higher learning rate so they learn fast enough.
- Train everything from scratch together (this is different from LoRA-style adapters, which are usually added later for fine-tuning a frozen model).
To test NOBLE, the team tried it on:
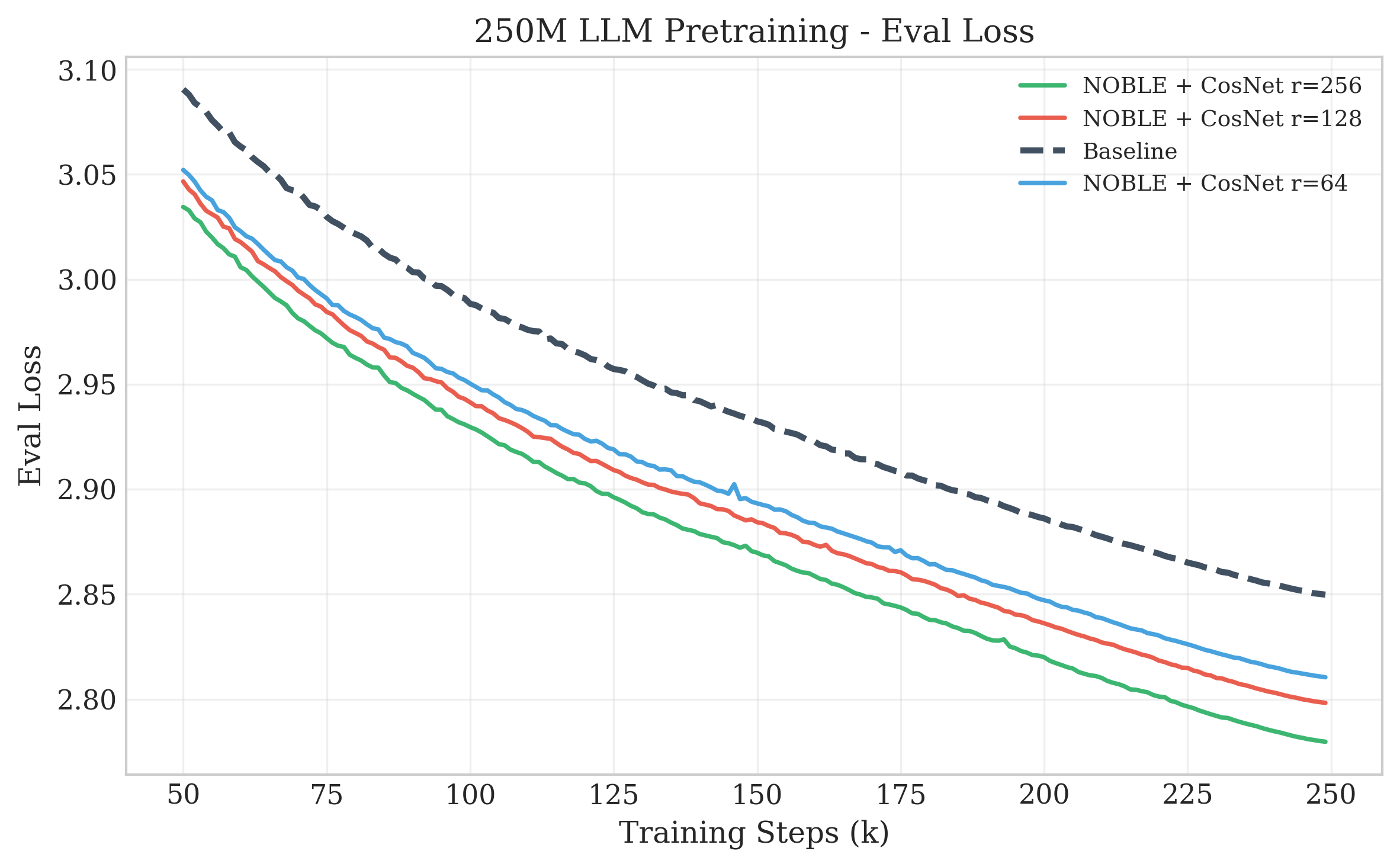
- LLMs at 250M and 1.5B parameters (predicting the next word),
- BERT (predicting missing words),
- A Vision Transformer (ViT) on ImageNet,
- An image token model (predicting the next image token, similar to predicting the next word in text).
Main findings and why they matter
Here are the most important results:
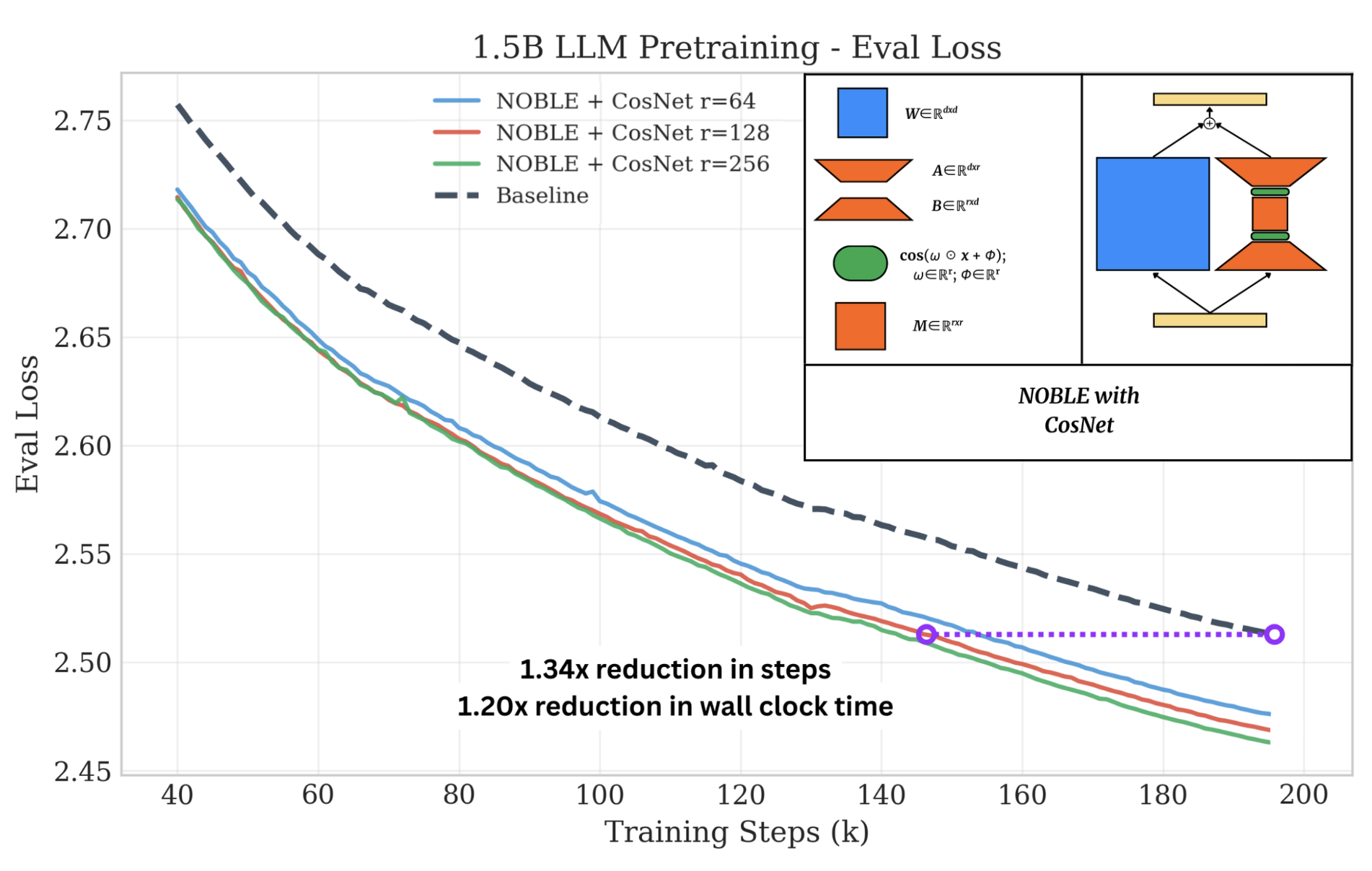
- It reaches the same quality in fewer steps:
- 21–32% fewer training steps (up to 1.47× “step speedup”).
- It adds only a little extra work per step:
- About 4–24% more parameters and 7–21% longer time per step.
- Net effect: total training time still gets better:
- 1.17–1.22× faster in wall-clock time.
- It often ends with better final quality:
- Slightly lower evaluation loss (better performance) than the standard model.
Where it worked best:
- LLMs (both sizes),
- BERT-style masked language modeling,
- Autoregressive image token modeling.
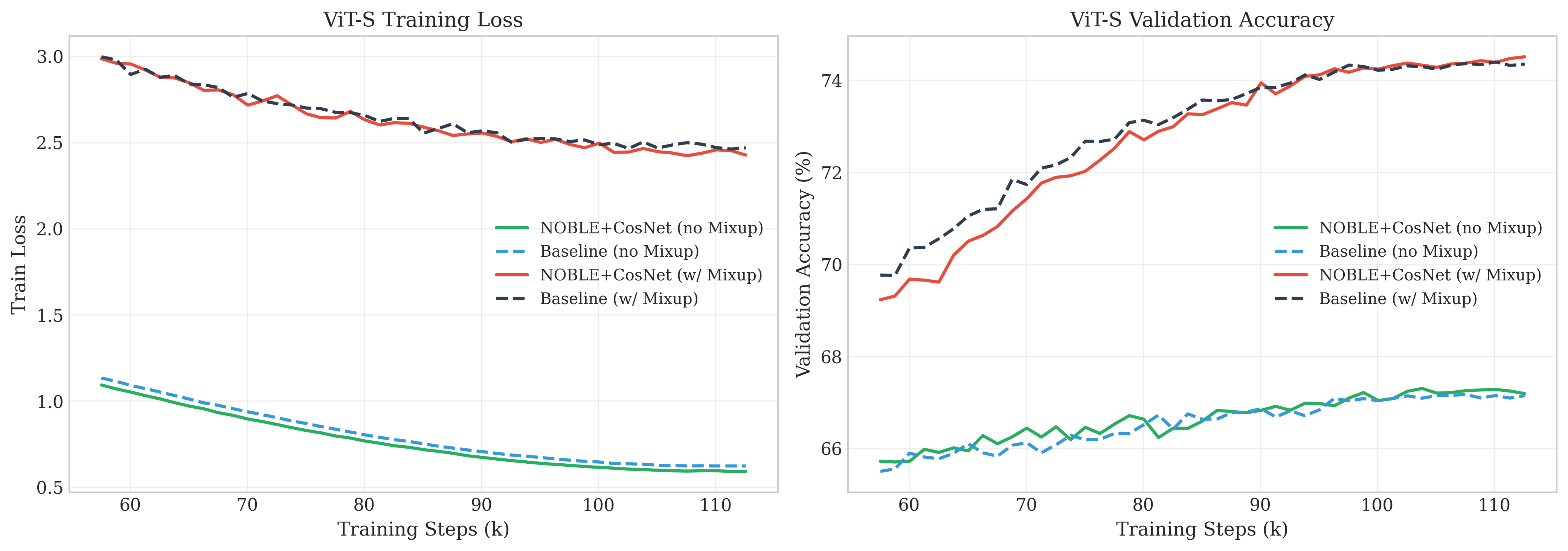
One caveat in vision:
- On ImageNet with ViT, when strong data mixing tricks like Mixup and CutMix were turned on (these make training targets very smooth), NOBLE’s advantage mostly disappeared. When those were turned off, NOBLE lowered training loss, but didn’t clearly boost validation accuracy.
- Why? The authors think NOBLE’s “wavy” branch is great at learning sharp, detailed patterns. But Mixup/CutMix intentionally smooths patterns. If the target is very smooth, the extra “detail learner” provides less benefit.
Why this matters:
- Training large models is expensive and slow. Getting to the same quality faster saves a lot of time and money.
- NOBLE’s extra cost is modest, and the overall training still finishes faster.
- It’s a simple architectural tweak, not a complicated system.
What this could mean for the future
- NOBLE could become a standard way to speed up pretraining for transformers in language and image tasks.
- It suggests a design idea: pair a “straight” main path with a tiny “curvy” branch to quickly learn fine details.
- For vision, you might get more benefit when you don’t heavily smooth the data (or if you tune augmentations carefully).
- There’s a small permanent cost at inference (about 6–12% more compute), so deployments that are very speed-sensitive should weigh the tradeoff.
- Future work could explore which layers benefit most, try other nonlinearities, and test at larger scales or on more vision tasks.
In one sentence
NOBLE adds a small, wave-powered side branch to transformer layers that helps models learn tricky details faster, cutting total training time with only a small extra cost — especially when training isn’t forced to be overly smooth.
Knowledge Gaps
Below is a concise list of the paper’s unresolved knowledge gaps, limitations, and open questions that future work could address.
- Layer selection: No ablation on where to apply NOBLE (e.g., only FFN vs only attention projections vs a subset like K/V or output). Determine per-module impact and the minimal set of layers that yields most of the gains.
- Rank allocation strategy: No study of heterogeneous or adaptive ranks across layers; investigate layerwise rank schedules, depth-dependent ranks, and compute-aware rank budgeting.
- Learning rate and initialization ablations: The elevated LRs for W_up/M, reduced main-weight init, near-zero W_up init, and frequency/phase LR multipliers were not ablated individually; quantify each factor’s contribution and sensitivity.
- Nonlinearity design space: Beyond cosine, only a small set of activations was tested; evaluate sine, learned mixtures of periodic functions, gated periodic units, piecewise-linear periodic approximations, and other smooth non-saturating activations.
- Depth of bottleneck network: 2-layer CosNet outperformed 1-layer, but deeper stacks were minimally explored; assess whether residual/skip connections or normalization in the bottleneck help.
- Theoretical grounding: Provide formal analysis (e.g., frequency-domain decomposition, Jacobian spectra, Lipschitz/curvature properties) to explain why cosine bottlenecks improve optimization and sample efficiency in pretraining.
- Compatibility with regularization: Only Mixup/CutMix were probed; systematically map interactions with dropout, label smoothing, weight decay strength, stochastic depth, RandAugment intensity, noise injections, and spectral normalization.
- Robustness to augmentation strength: Identify thresholds of augmentation severity where NOBLE’s benefits vanish and whether modified CosNet or regularization schedules can recover gains.
- Generalization vs overfitting trade-off: In ViT without Mixup/CutMix, train loss improved while validation did not; explore countermeasures (e.g., tuned WD, early stopping, targeted regularizers) to retain generalization.
- Scaling behavior: Largest model is 1.5B; test at >7B–70B to assess scaling laws, compute-optimal training, and whether gains persist or saturate with scale.
- Data/domain coverage: Language results are on OpenWebText; evaluate on The Pile, C4, multilingual corpora, code datasets, and domain-shifted distributions to assess robustness and breadth.
- Downstream task transfer: Only pretraining losses reported; measure gains on standard downstream benchmarks (e.g., GLUE/SuperGLUE, MMLU, SQuAD, ImageNet linear probe, COCO detection/segmentation) to validate practical impact.
- Long-context regimes: Effects were measured at 1k tokens; test longer contexts (4k–32k) and tasks reliant on long-range dependencies to see if NOBLE helps or hurts context scaling.
- Optimizer and schedule dependence: Only AdamW variants used; test Lion, Adafactor, momentum schedules, different warmups/decays, and cosine vs linear decay to ensure optimizer-agnostic benefits.
- Hardware and precision portability: Step-time overhead measured on H100 with bf16 and torch.compile; verify on A100/V100/TPUs, with FP8/INT8/bfloat16, and different compiler stacks (XLA, Triton, TensorRT-LLM).
- Inference-time mitigation: Since NOBLE cannot be trivially merged, explore distillation, functional approximation, or low-degree polynomial/cosine expansions to fuse or compress the branch post-training.
- Quantization and pruning: Cosine operations complicate common quantization pipelines; assess quantization-aware training, post-training quantization, and structured pruning of the branch without losing gains.
- Memory/activation overhead: Parameter and step-time overhead are reported, but training-time memory footprint and activation checkpointing costs were not quantified; measure peak memory and throughput under realistic memory constraints.
- Stability/pathologies: Analyze whether learnable frequencies/phase lead to training instabilities, aliasing, or gradient pathologies; develop frequency regularizers or schedules to prevent degenerate solutions.
- Tokenizer dependence in vision: Autoregressive image results rely on a specific VQGAN tokenizer; test other discrete tokenizers (VQ-VAE-2, RVQ, residual vector quantization) and codebook sizes to isolate tokenizer effects.
- Heterogeneous application across modalities: Beyond ViT classification and AR image tokens, evaluate detection, segmentation, video, and self-supervised vision (MAE, DINO) to understand modality-specific behavior.
- Interaction with advanced architectures: Study synergy or redundancy with MoE layers, gated MLPs (SwiGLU vs GeGLU), attention kernel improvements (Flash/Linear attention), and encoder–decoder setups (cross-attention).
- PEFT usage: Although designed for pretraining, assess NOBLE as a fine-tuning adapter (frozen backbone vs unfrozen), and whether partial training of the branch delivers parameter-efficient adaptation.
- Fairness of baselines: NOBLE uses altered initializations and LR multipliers; re-tune baselines with equal rigor (e.g., scaled initializations, μP-guided LRs) to rule out tuning confounds.
- Metrics beyond NLL: Evaluate calibration (Brier score, ECE), uncertainty, out-of-distribution robustness, and generation quality (e.g., text toxicity, image FID) to check for unintended side effects of high-frequency fitting.
- Rank beyond 256 and diminishing returns: Characterize the efficiency frontier at higher ranks, identify the point of diminishing returns, and design compute-optimal rank selection policies.
- Per-layer diagnostics: Measure gradient norms, curvature (e.g., Hessian traces), spectral characteristics of W and branch outputs during training to validate the “high-frequency residual” hypothesis empirically.
Practical Applications
Immediate Applications
The following items outline practical use cases that can be deployed now, with sector tags, indicative tools/workflows, and key assumptions or dependencies noted.
- Faster foundation-model pretraining in AI infrastructure (software/ML platforms)
- What: Integrate NOBLE branches (CosNet) into transformer linear projections (Q/K/V, output, FFN) for new LLM pretraining runs to achieve 21–32% fewer steps and ~1.17–1.22× wallclock speedups.
- Tools/Workflows: PyTorch/Hugging Face extension to wrap
nn.Linearwith a NOBLE branch; learning-rate scaling policy forW_upandM; near-zero initialization; training monitors tracking “steps-to-baseline-loss.” - Assumptions/Dependencies: Replication depends on correct initialization and LR scaling, bf16 mixed precision, and torch.compile/runtime (tested on H100s). Inference overhead (≈6–12% FLOPs) is acceptable for server-side deployments.
- Continued pretraining to lower eval loss within fixed compute budgets (software/enterprise AI)
- What: Use NOBLE for “continued pretraining” of partially trained LLMs/BERT to reach target loss faster or achieve lower loss at equal budget.
- Tools/Workflows: Resume checkpoints, keep optimizer states, enable NOBLE branch with CosNet and elevated LR for
W_up/M. - Assumptions/Dependencies: Although NOBLE is designed for pretraining from scratch, the paper notes potential for continued pretraining; verify compatibility with existing optimizer states.
- Domain-specific BERT/LLM training for enterprise search and document intelligence (enterprise software)
- What: Accelerate masked language modeling (MLM) or autoregressive pretraining on in-domain corpora (legal, finance, pharma) to reduce time-to-deploy.
- Tools/Workflows: BERT-style training recipes with NOBLE; RoPE usage; rank sweeps (64–256) to balance cost vs. speedup.
- Assumptions/Dependencies: Gains observed at 110M BERT; generalization to larger BERT variants likely but untested.
- Autoregressive image token modeling for generative content (creative software/media)
- What: Faster training of image token transformers (e.g., VQGAN-coded tokens) for next-token prediction, improving iteration speed in generative pipelines.
- Tools/Workflows: Integrate NOBLE in causal image-token transformers; 2D RoPE; class-conditioning setup.
- Assumptions/Dependencies: Benefits observed without aggressive augmentation; tokenizer choice (e.g., VQGAN amused-512) influences results.
- Vision transformer training with adjusted augmentation (computer vision)
- What: Use NOBLE for ViT image classification when Mixup/CutMix are disabled, targeting lower train loss or faster convergence in regimes where augmentation is minimal or staged.
- Tools/Workflows: Augmentation compatibility checker; scheduled Mixup/CutMix (e.g., late-phase only); monitor overfitting risk.
- Assumptions/Dependencies: Mixup/CutMix can suppress NOBLE’s gains and may reduce generalization; carefully manage augmentation policies.
- Cost and energy savings in model training (energy/finance/operations)
- What: Reduce compute costs and energy usage by reaching target losses with fewer steps; integrate into sustainability accounting.
- Tools/Workflows: “NOBLE-aware” training planners that estimate energy and cost savings; reporting dashboards linking step-speedups to CO2e reductions.
- Assumptions/Dependencies: Savings depend on datacenter efficiency, hardware type, and actual wallclock improvements vs. added per-step overhead.
- Faster prototyping in academic labs and startups (academia/startups)
- What: Shorten experimentation cycles for transformer architecture research and ablations; use NOBLE as a baseline augmentation.
- Tools/Workflows: Reproducible recipes with CosNet; activation ablations; rank sweeps (64–256).
- Assumptions/Dependencies: Most gains shown at 250M–1.5B scales; extrapolation to larger models requires validation.
- Training workflow upgrades in MLOps (software/MLOps)
- What: Add NOBLE modules, LR scaling policies, and initialization changes to standard transformer pipelines; instrument “time-to-target-loss.”
- Tools/Workflows: Pipeline templates; autoscaling LR multipliers based on dimension/rank; CI checks for augmentation compatibility.
- Assumptions/Dependencies: Requires careful hyperparameter management and monitoring; minor code changes across Q/K/V/FFN layers.
- Early access to improved model quality (consumer/daily life via downstream products)
- What: Ship model upgrades sooner (LLM assistants, code copilots, content tools) due to faster pretraining; modestly better final losses at convergence.
- Tools/Workflows: Release cadence acceleration; A/B testing pipelines.
- Assumptions/Dependencies: Inference overhead must be acceptable; benefits realized indirectly through provider-side improvements.
- Sustainability reporting and internal policy alignment (policy/corporate governance)
- What: Incorporate NOBLE-based training efficiency into internal AI governance, sustainability KPIs, and procurement decisions focused on energy-aware AI development.
- Tools/Workflows: Policies that prefer training recipes with documented energy savings; vendor SLAs including efficiency metrics.
- Assumptions/Dependencies: Requires measurement frameworks and standardized reporting practices.
Long-Term Applications
These items require further research, scaling, or productization to be practical.
- Distillation or branch folding to remove inference overhead (software/edge/robotics)
- What: Train with NOBLE for speed and quality, then distill or compress the nonlinear branch into the backbone to eliminate inference cost.
- Tools/Workflows: NOBLE-to-vanilla distillation toolkits; teacher–student pipelines.
- Assumptions/Dependencies: Current paper notes permanent inference overhead; branch merging methods are future work.
- Automated rank and layer selection (AutoML/MLOps)
- What: Learn per-layer ranks (
r) and where to apply NOBLE for optimal speed-to-quality tradeoffs. - Tools/Workflows: AutoML rank tuner; layer-wise sensitivity estimation; spectral proxies to detect “high-frequency residual” needs.
- Assumptions/Dependencies: Requires robust heuristics/metrics and integration with training pipelines.
- What: Learn per-layer ranks (
- Task-aware augmentation scheduling (computer vision/general ML)
- What: Develop augmentation strategies compatible with high-frequency residual learning—e.g., phase-wise Mixup/CutMix scheduling or alternative regularizers.
- Tools/Workflows: Augmentation controllers that adapt based on spectral/curvature diagnostics; curriculum-style augmentation.
- Assumptions/Dependencies: Needs empirical validation across vision tasks beyond ImageNet classification.
- Scaling to 10B+ parameter models and multimodal systems (AI infra/multimodal)
- What: Validate NOBLE at larger scales and in multimodal pretraining (text–image–audio–video), and with memory-efficient kernels.
- Tools/Workflows: Distributed training support; kernel optimizations for CosNet; mixed-device strategies.
- Assumptions/Dependencies: Paper’s largest scale is 1.5B; benefits at extreme scales and in complex data regimes are unknown.
- Hardware/compiler co-optimization (semiconductors/compilers)
- What: Design kernels and compiler passes optimized for periodic activations and low-rank branches to reduce per-step overhead.
- Tools/Workflows: CUDA/ROCm kernels for cosine activations; graph fusions; ONNX and XLA compiler support.
- Assumptions/Dependencies: Requires vendor engagement and broad framework support.
- NOBLE variants for PEFT/fine-tuning (software/enterprise AI)
- What: Adapt NOBLE architecture for fine-tuning frozen backbones with nonlinear low-rank branches, bridging to adapter ecosystems.
- Tools/Workflows: PEFT libraries with nonlinear branches; compatibility layers with LoRA/DoRA/AdaLoRA.
- Assumptions/Dependencies: Paper focuses on pretraining; PEFT adaptation is plausible but needs benchmarking.
- Cross-domain adoption: speech, time-series, control (healthcare/finance/IoT/robotics)
- What: Apply NOBLE in ASR, EHR modeling, forecasting, and policy learning where high-frequency residuals may exist.
- Tools/Workflows: Spectral diagnostics for domain tasks; recipe porting; rank/activation ablations.
- Assumptions/Dependencies: Vision coverage is limited in the paper; cross-domain efficacy requires thorough trials.
- Retrieval-augmented and MoE synergy (software/AI infra)
- What: Combine NOBLE’s dense nonlinear capacity with MoE routing or retrieval augmentation to accelerate training and improve specialization.
- Tools/Workflows: Hybrid architectures; routing-aware rank allocation; retrieval data pipelines.
- Assumptions/Dependencies: Interaction effects with conditional computation and retrieval need study.
- Model selection helpers based on smoothness/high-frequency analysis (MLOps/AutoML)
- What: Tools that predict when NOBLE will help or hurt, using curvature/Lipschitz proxies or frequency-domain diagnostics of targets.
- Tools/Workflows: Training diagnostics; decision-support modules baked into AutoML systems.
- Assumptions/Dependencies: Requires reliable, lightweight metrics that correlate with NOBLE’s effectiveness.
- Policy and standards for energy-aware AI development (public policy/industry standards)
- What: Encourage methods that reduce training energy per target performance (including NOBLE-like architectures); establish reporting templates and benchmarks.
- Tools/Workflows: Standardized efficiency metrics and disclosures; procurement guidelines for energy-conscious AI.
- Assumptions/Dependencies: Needs consensus bodies and adoption by major AI labs/cloud providers.
Glossary
- Ablation: An experimental study that systematically removes or varies components to assess their impact. "with ablations on rank (64, 128, 256)."
- Adapter: A small module added to a pretrained model for task-specific fine-tuning without updating the main weights. "as opposed to an adapter for finetuning on top of frozen weights."
- Affine transformation: A linear mapping followed by a translation; in layers, it refers to linear projections plus bias. "are fundamentally limited to computing affine transformations within each layer."
- Autoregressive: A modeling approach that predicts the next element based on previous ones in a sequence. "LLM autoregressive training"
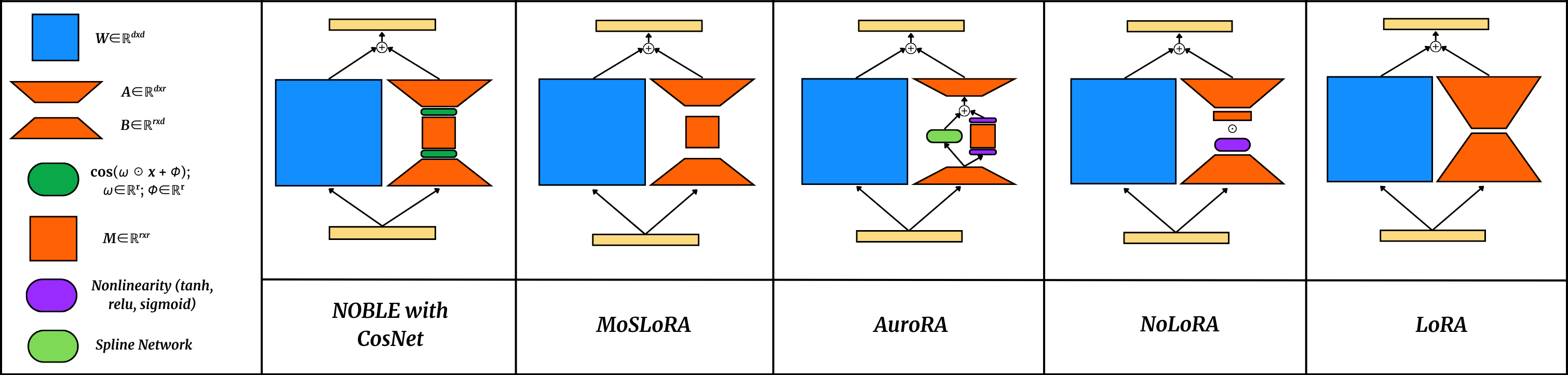
- AuroRA: A nonlinear LoRA variant introducing an adaptive nonlinear layer in the bottleneck for PEFT. "AuroRA incorporates an Adaptive Nonlinear Layer between linear projectors to capture fixed and learnable nonlinearities."
- BERT: A bidirectional transformer architecture commonly used for masked language modeling. "110M BERT-style masked language modeling"
- bf16 mixed precision: A reduced-precision floating-point format (bfloat16) used to speed training and reduce memory. "bf16 mixed precision, torch.compile using reduce-overhead mode and fullgraph=True"
- Bottleneck: A lower-dimensional intermediate representation used to constrain or compress information. "in the bottleneck space"
- BPE tokenizer: Byte Pair Encoding tokenizer that builds a subword vocabulary by merging frequent symbol pairs. "BPE tokenizer (50257 vocab)"
- Cosine annealing: A learning rate schedule that follows a cosine curve over training time. "cosine annealing with 5 warmup epochs"
- CosNet: A two-layer cosine-based nonlinearity in the low-rank branch with learnable frequency, phase, and a mixing projection. "CosNet, a sandwich of a learnable cosine activation, a linear projection, and then another learnable cosine activation"
- Causal attention: Attention that restricts each position to attend only to earlier positions, enabling autoregressive prediction. "Attention: Causal (raster-scan token order)"
- CutMix: A data augmentation technique that mixes images by cutting and pasting patches with combined labels. "CutMix (=1.0)"
- DoRA: A LoRA variant that decomposes weight updates into magnitude and direction components. "DoRA decomposes weights into magnitude and direction components."
- GeGLU: A feedforward block using a gated GELU activation for improved expressivity. "GeGLU feedforward blocks"
- GELU: Gaussian Error Linear Unit, a smooth, non-monotonic activation function. "ReLU-like activations (LeakyReLU, GELU) provide moderate improvement."
- Kaiming initialization: A weight initialization scheme designed for ReLU-like activations to maintain signal variance. "half the typical Kaiming scale"
- Label smoothing: A regularization technique that softens target labels to discourage overconfident predictions. "Label smoothing~\citep{szegedy2016rethinking} softens targets, discouraging sharp decision boundaries."
- LeakyReLU: A ReLU variant that allows a small, non-zero gradient for negative inputs. "ReLU-like activations (LeakyReLU, GELU) provide moderate improvement."
- Lipschitz (L-Lipschitz): A smoothness property bounding how fast a function can change with input changes. "A function is -Lipschitz if "
- LoRA: Low-Rank Adaptation; a method that fine-tunes large models using low-rank updates to frozen weights. "Low-Rank Adaptation (LoRA)"
- Masked language modeling (MLM): A training objective where some input tokens are masked and the model predicts them. "masked language modeling (15\% masking probability, standard 80/10/10 mask/random/unchanged split)"
- Mixture of Experts (MoE): An architecture with multiple expert sub-networks where a gating mechanism routes inputs to a subset. "MoE layers add capacity through conditional computation."
- Mixup: A data augmentation technique that trains models on convex combinations of pairs of examples and labels. "Mixup (=0.8)"
- MoSLoRA: A LoRA variant that uses a mixture-of-subspaces to increase expressiveness. "MoSLoRA introduces mixture-of-subspaces to improve LoRA's expressiveness."
- μP (muP): A scaling framework (Tensor Programs) for hyperparameter transfer across model sizes. "roughly following P~\citep{yang2022tensor}"
- Neural Radiance Fields (NeRF): A technique representing 3D scenes with neural networks using volumetric rendering; notable for periodic activations. "Sinusoidal representations have proven effective in neural radiance fields"
- NOBLE: Nonlinear lOw-rank Branch for Linear Enhancement; an architectural augmentation adding nonlinear low-rank branches to linear layers. "We introduce NOBLE (Nonlinear lOw-rank Branch for Linear Enhancement)"
- Parameter-Efficient Fine-Tuning (PEFT): Methods that adapt pretrained models with few additional parameters, often by freezing base weights. "parameter-efficient fine-tuning (PEFT)"
- Periodic activations: Activation functions like sine or cosine that are periodic and can model high-frequency signals. "Periodic Activations."
- QLoRA: A LoRA technique enabling fine-tuning with quantized base model weights to save memory. "QLoRA enables fine-tuning with quantized weights."
- Query–Key–Value (QKV) projections: Linear projections that produce queries, keys, and values used in attention mechanisms. "the attention mechanism's query, key, and value projections remain purely linear."
- RandAugment: An automated data augmentation method with a reduced hyperparameter search space. "RandAugment"
- RMSNorm: Root Mean Square Layer Normalization; normalizes activations using their RMS instead of mean/variance. "RMSNorm~\citep{zhang2019root}"
- RoPE (Rotary Position Embeddings): A positional encoding method that rotates query and key vectors by position-dependent angles. "RoPE positional encodings"
- SIREN: A neural network architecture using sine activations for implicit representations and high-frequency fitting. "SIREN~\citep{sitzmann2020implicit}"
- Spectral bias: The tendency of neural networks to learn low-frequency (smooth) functions before high-frequency details. "spectral bias: they naturally learn low-frequency components first"
- Spectral normalization: A technique that constrains a layer’s Lipschitz constant by normalizing its weight matrix’s spectral norm. "Spectral normalization~\citep{miyato2018spectral} directly bounds layer-wise Lipschitz constants."
- Tikhonov regularization: A regularization method equivalent to L2 weight penalty, linked to noise injection. "equivalent to Tikhonov regularization"
- torch.compile (reduce-overhead, fullgraph): A PyTorch compiler pathway that optimizes models by creating a single compiled graph with reduced overhead. "torch.compile using reduce-overhead mode and fullgraph=True"
- ViT (Vision Transformer): A transformer architecture applied to images using patch embeddings. "ViT-Small (22M parameters)"
- VQGAN: Vector-Quantized Generative Adversarial Network used for discrete image tokenization. "using a pretrained VQGAN"
- Xavier initialization: A weight initialization scheme balancing variance across layers for stable training. "Xavier initialization"
Collections
Sign up for free to add this paper to one or more collections.