Attention Sinks Are Provably Necessary in Softmax Transformers: Evidence from Trigger-Conditional Tasks
Abstract: Transformers often display an attention sink: probability mass concentrates on a fixed, content-agnostic position. We prove that computing a simple trigger-conditional behavior necessarily induces a sink in softmax self-attention models. Our results formalize a familiar intuition: normalization over a probability simplex must force attention to collapse onto a stable anchor to realize a default state (e.g., when the model needs to ignore the input). We instantiate this with a concrete task: when a designated trigger token appears, the model must return the average of all preceding token representations, and otherwise output zero, a task which mirrors the functionality of attention heads in the wild (Barbero et al., 2025; Guo et al., 2024). We also prove that non-normalized ReLU attention can solve the same task without any sink, confirming that the normalization constraint is the fundamental driver of sink behavior. Experiments validate our predictions and demonstrate they extend beyond the theoretically analyzed setting: softmax models develop strong sinks while ReLU attention eliminates them in both single-head and multi-head variants.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “Attention Sinks Are Provably Necessary in Softmax Transformers: Evidence from Trigger-Conditional Tasks”
Overview: What is this paper about?
This paper asks why Transformers (the kind of AI model behind many chatbots) often focus a lot on the first token in a sentence—the special “start” token—no matter what the words say. This strong, fixed focus is called an “attention sink.” The authors show that for a common kind of behavior—“do nothing unless a special trigger appears”—this sink isn’t just a weird habit. In Transformers that use softmax attention (the standard kind), it’s actually required to make the model behave correctly.
The big questions (in simple terms)
The paper investigates:
- Why do Transformers often “look” at the first token so much?
- Is this just something that happens during training, or is it necessary for certain jobs?
- Can we design attention in a different way so this sink doesn’t happen?
Key idea in everyday language
- Think of attention as where the model “looks” when deciding what to output.
- “Softmax” attention means the model must split its “attention” like a pie: all the slices add up to 100%.
- An “attention sink” is like a drain: when the model isn’t sure what to do, a lot of its attention flows into a default place—often the first token (BOS = “beginning of sequence”).
- A “trigger-conditional” task means: do nothing unless a special trigger appears. When the trigger appears, do a specific job.
What exactly did they test?
The authors built a simple but realistic task that copies what some attention heads in real models do:
- Most of the time: output zero (do nothing).
- If a special “trigger token” appears: output the average of all the earlier tokens (a way of “mixing” or summarizing past information).
To make this concrete, they gave tokens:
- A special BOS (start) token.
- A trigger token that shows up once in the sequence.
- Other tokens with random content (like “words”). The correct behavior is:
- Before the trigger: output zero.
- At the trigger: output the average of all previous tokens (including the trigger itself).
- After the trigger: output zero.
They tried solving this with two kinds of attention:
- Softmax attention (the standard one, where attention weights must add up to 1).
- ReLU attention (an alternative where weights aren’t forced to add up to 1).
How did they approach it?
The paper combines math proofs with small experiments:
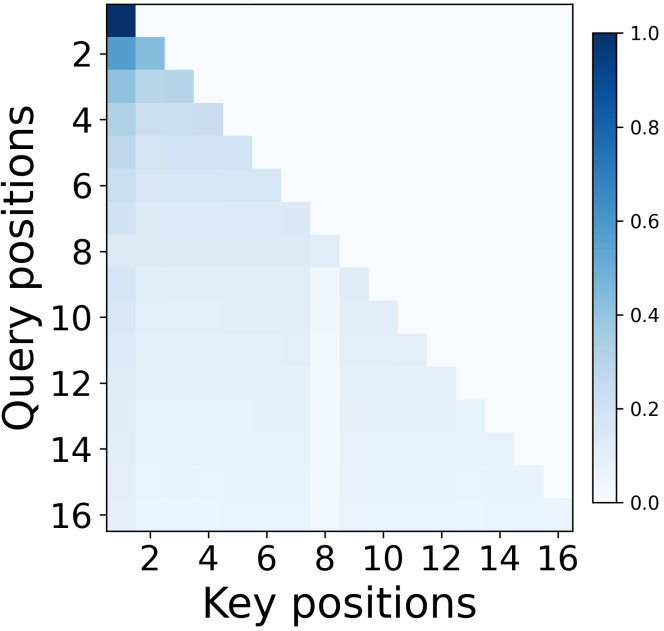
- Proofs: They show that with softmax attention, if the model is required to “do nothing” at most positions but “do a specific calculation” when a trigger appears, then the model must create a sink—i.e., put almost all attention on a fixed token (the BOS token) when there’s no trigger.
- Construction: They build a ReLU attention model that solves the same task perfectly without any sink at all. This shows the sink comes from the softmax rule (the “attention pie” that must sum to 100%), not the task itself.
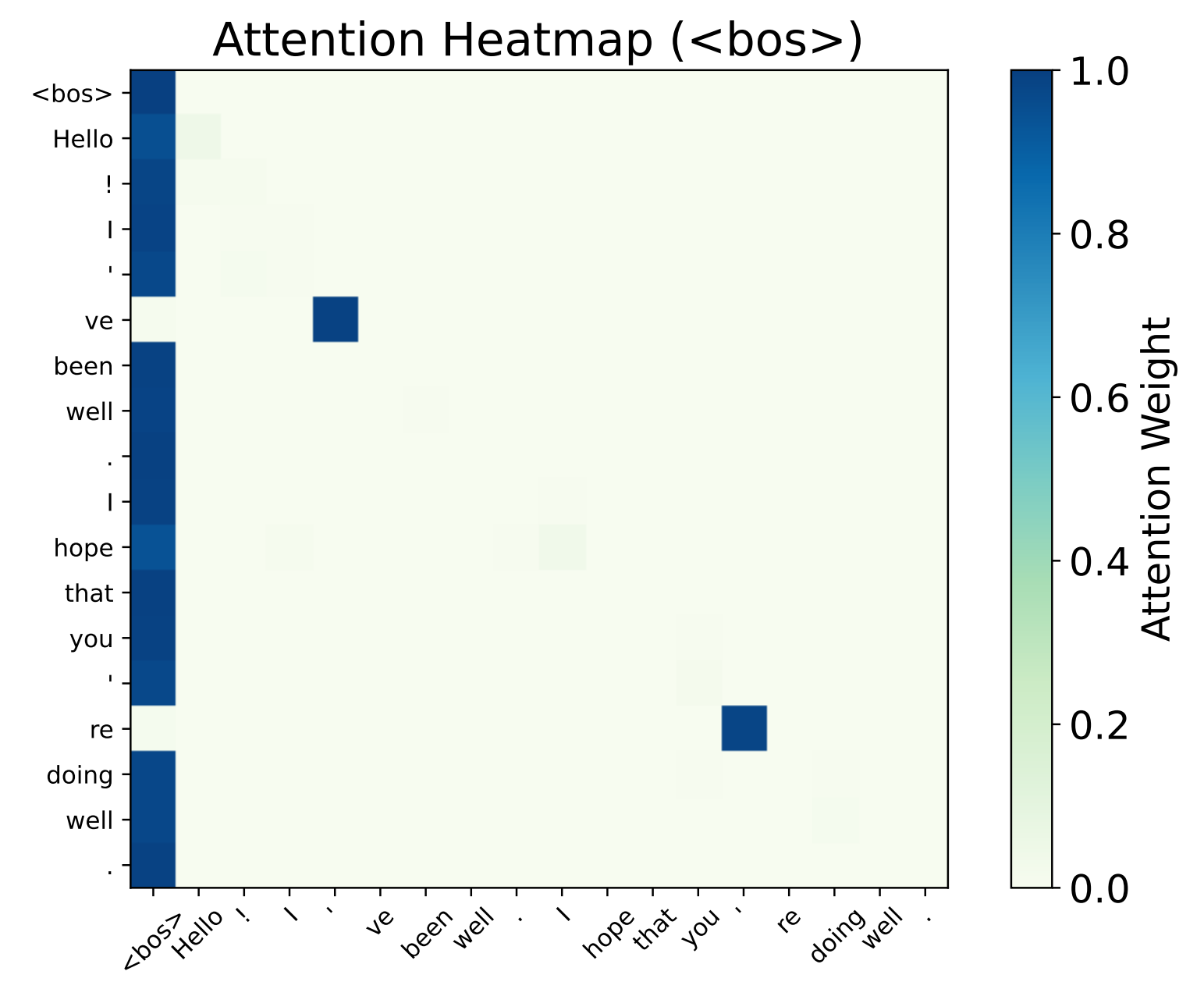
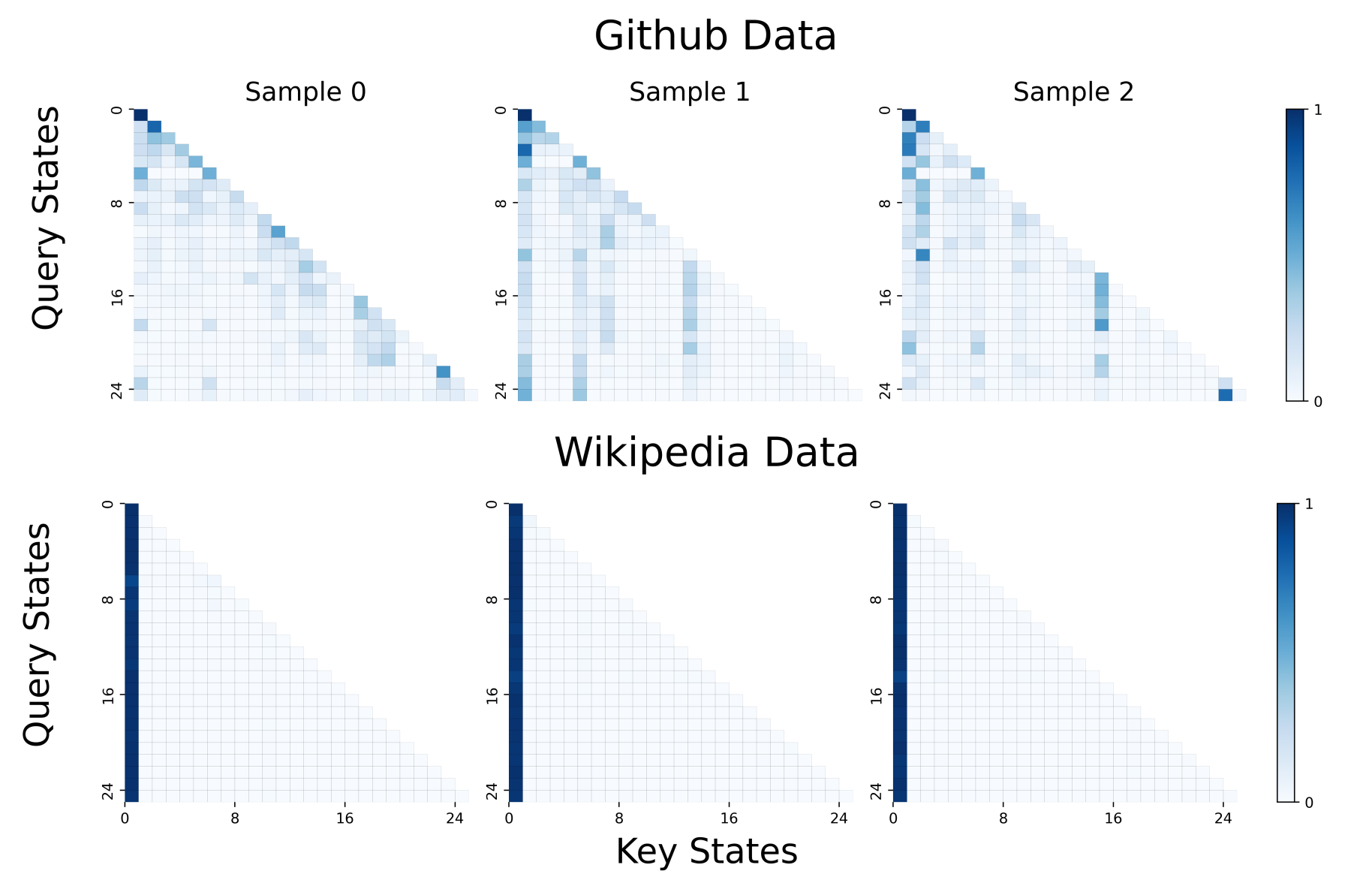
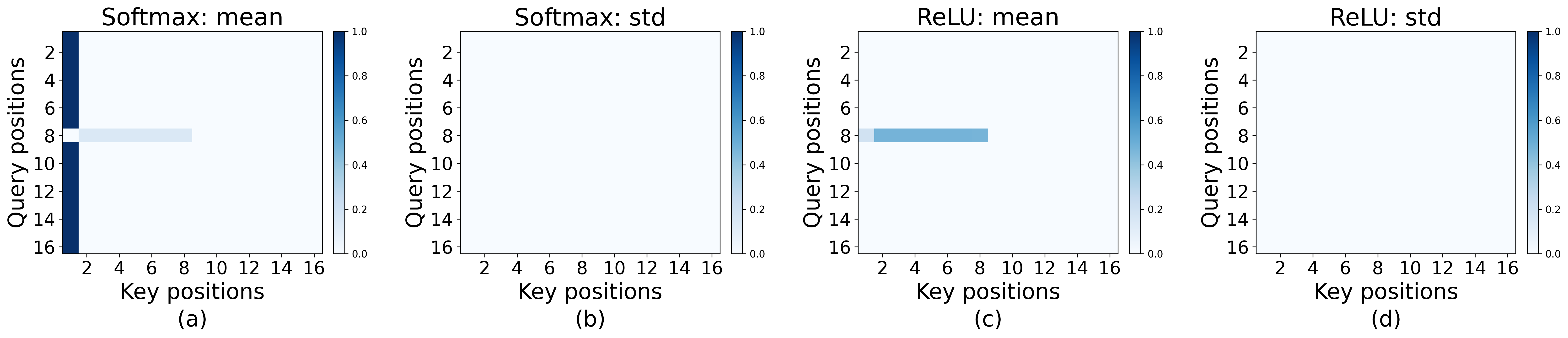
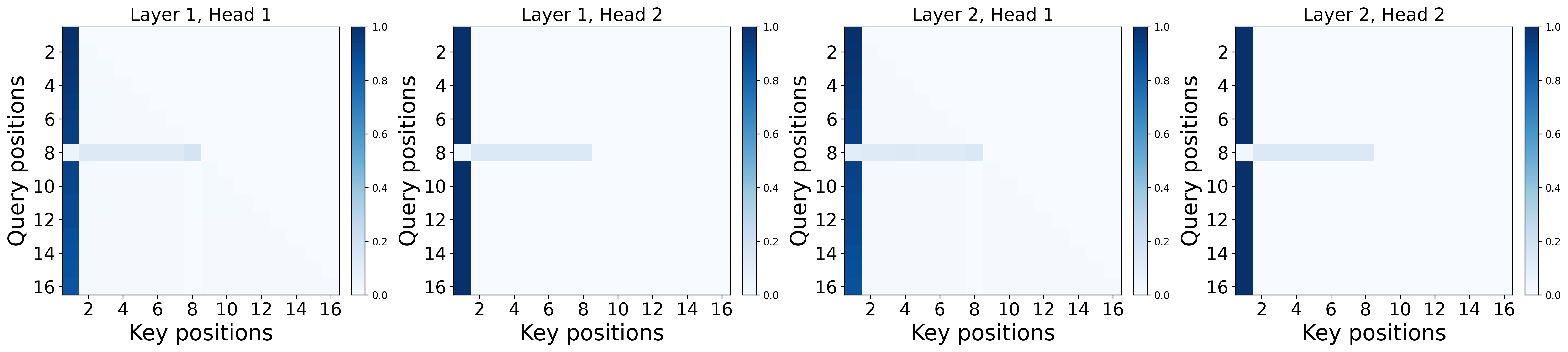
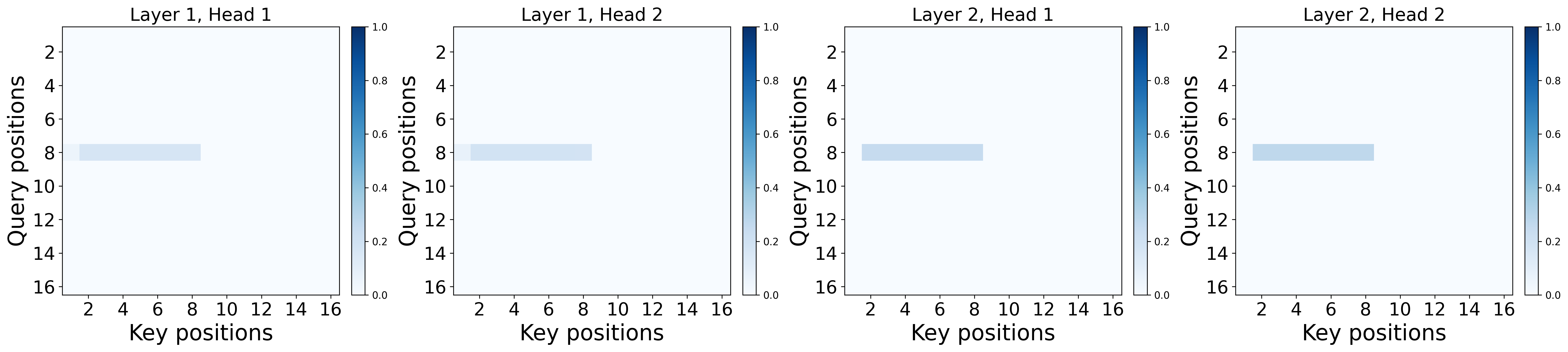
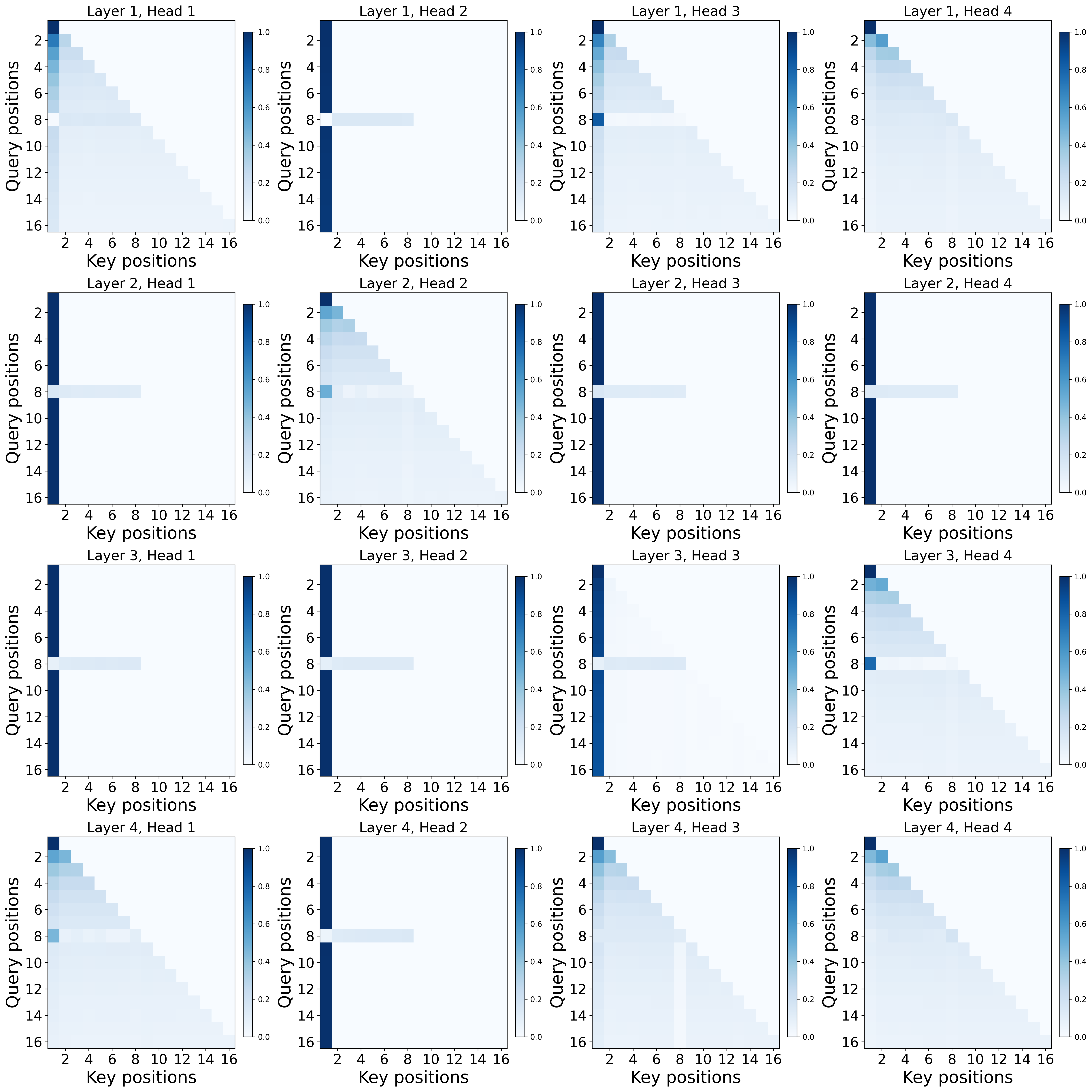
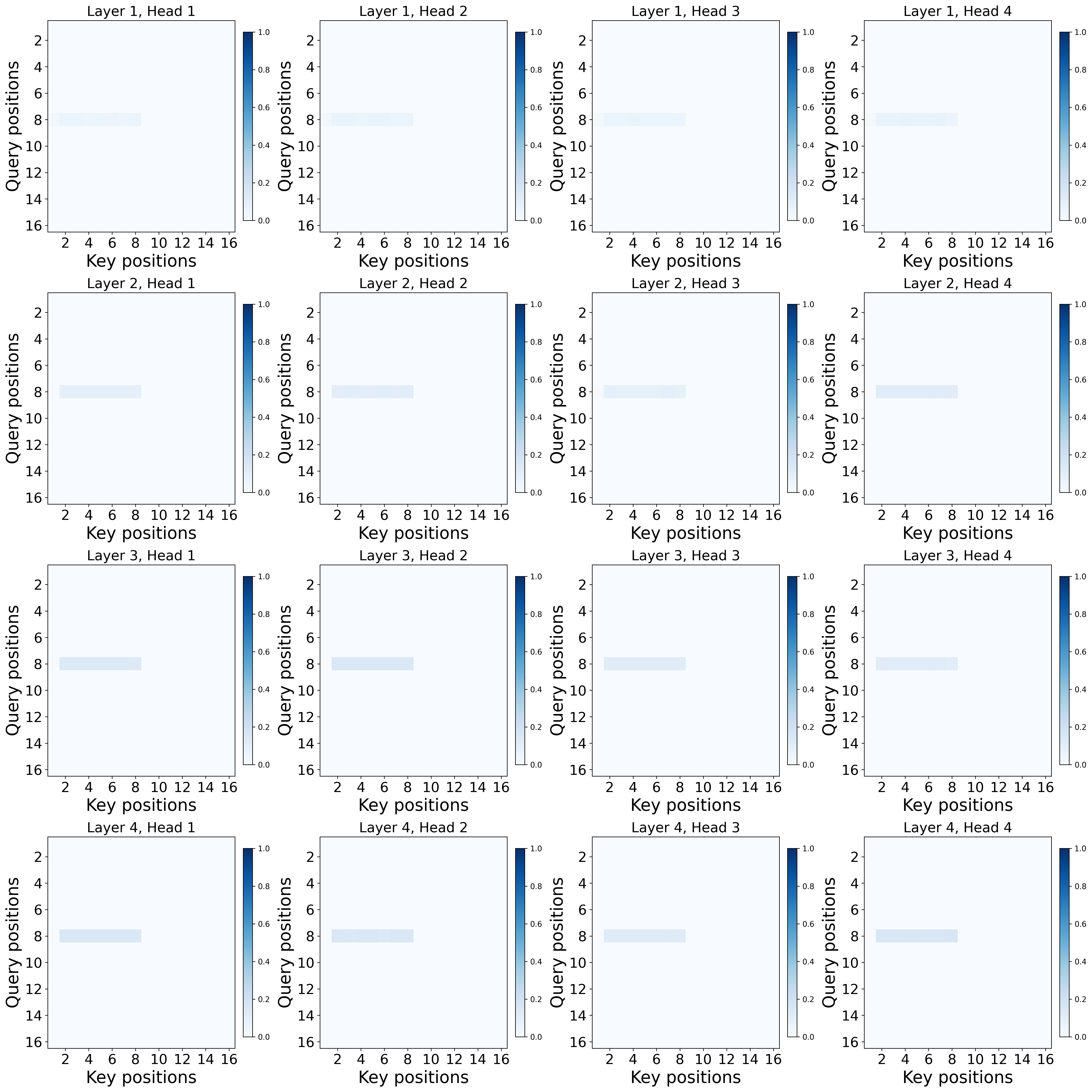
- Experiments: They train small Transformers on this task and visualize where the attention goes. With softmax, a strong sink forms at the first token. With ReLU attention, no sink forms, but the model still solves the task.
Main findings and why they matter
Here are the core results:
- In a single-layer softmax Transformer: to do the trigger-conditional task well, the model must put almost all of its attention on the first token at the non-trigger positions. In other words, a sink is necessary to represent the “do nothing” default.
- In multi-layer softmax Transformers: at least one layer must have this sink somewhere before the trigger. Not every head or layer needs a sink, but at least one does.
- Using ReLU attention (no softmax normalization): the same task can be solved perfectly without any sink. The model can represent “do nothing” by simply turning attention off, instead of pushing it all into a fixed spot.
Why this matters:
- It explains a real pattern people keep seeing in big models: heads that “wake up” on triggers and otherwise stare at the first token.
- It shows this pattern is not just a training accident—it’s built into how softmax attention works when you need a reliable “off” state.
- It suggests that if you want to avoid sinks (for better interpretability, stability, or efficiency), you may need to change the attention mechanism itself, not just tweak training tricks.
What this means going forward
- If your model needs a strong “off” mode (output zero unless triggered) and uses softmax attention, a sink is likely part of the solution, not a bug.
- Trying to “fight” the sink inside softmax (like forcing attention to spread out) might break the model’s reliable “off” behavior, or the sink may just reappear somewhere else.
- If sinks cause problems (e.g., they waste attention or make analysis confusing), using non-normalized attention (like ReLU), explicit gates, or other designs can give the model a true “off” without creating a sink.
Helpful definitions (light and brief)
- Token: a chunk of text the model reads (often a piece of a word).
- BOS token: a special token at the start of the sequence.
- Attention: the mechanism that lets the model “look back” at earlier tokens to decide what to output now.
- Softmax: a function that turns scores into probabilities that add up to 1 (like dividing a 100% pie among tokens).
- Attention sink: when most of the attention focuses on a fixed token (often the first one), regardless of content.
- ReLU attention: an attention variant that doesn’t force the attention weights to add up to 1, allowing true “zero” attention without piling it into a sink.
In short, this paper shows that attention sinks are not always a flaw—they can be the simplest way for softmax Transformers to stay “off” until a trigger says “go.” If you want “off” states without sinks, you’ll need a different kind of attention.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper advances a clear necessity result for softmax attention on a specific trigger-conditional task, but it leaves several concrete issues open for future investigation:
- Task generality: Formalize the full class of trigger-conditional computations (e.g., key–value retrieval, copy, gating, multi-token triggers, repeated or nested triggers) that provably necessitate sinks under softmax, beyond the “mean of past tokens” analyzed here.
- Distributional assumptions: Relax and test the bounded, i.i.d., continuous content-coordinate assumptions (and BOS having zero content) to more realistic embedding distributions with correlations, heavy tails, and discrete or structured components; characterize which assumptions are critical to the necessity proof.
- Causal vs. bidirectional attention: Extend the necessity results to encoder-style/bidirectional attention and cross-attention settings; identify whether sinks remain necessary or change form without causal masking.
- Positional encoding and indicators: Replace hand-crafted indicator coordinates (BOS, trigger, non-BOS) with standard learned positional encodings and realistic preprocessing (MLP injection, layer norms) and prove the necessity (or non-necessity) of sinks under those conditions.
- Multi-head rigor: Provide a formal necessity theorem for multi-head single-layer attention (not just multi-layer existential results); clarify whether at least one head must sink at specified positions and quantify inter-head interactions.
- Multi-layer localization: Move beyond existential guarantees to characterize which layer(s) and position(s) must host sinks, and how optimization, depth, and residual pathways influence where sinks emerge.
- Strength–error tradeoff: Quantify explicit lower bounds relating sink mass (e.g., ) to approximation error and sequence length ; characterize how sink intensity scales with target accuracy.
- Temperature and scaling: Analyze how softmax temperature, logit scaling (e.g., ), entropy regularization, or attention entropy constraints affect the necessity and magnitude of sinks.
- Alternative normalizations: Systematically delineate which normalization schemes (e.g., sparsemax/entmax, rectified/shifted softmax, doubly-stochastic attention, normalized attention without a “probability cage”) inherit the sink necessity via the paper’s “normalization + monotonicity” conditions, and which ones avoid it.
- Gating and hybrid mechanisms: Theoretically analyze gated attention, GLU-like controls, mixture-of-experts in attention, and other mechanisms that can implement no-ops without normalization over a simplex; specify minimal architectural features that break the necessity.
- ReLU attention variants: Remove the bespoke averaging-scale factor in the ReLU construction (or adjust the task to sums) and characterize general conditions under which non-normalized attention avoids sinks while computing similar trigger-conditional functions.
- Robustness to approximate triggers: Extend theory to probabilistic/soft triggers, ambiguous triggers, or trigger detection errors; assess whether near-zero outputs still force near-unit sinks under softmax in approximate or noisy regimes.
- Multiple anchors and “secondary” sinks: Analyze whether the BOS-specific sink is essential or if any stable token can serve as an anchor; formally study “secondary attention sinks” and conditions under which alternative positions become sinks.
- Interaction with FFNs and layer norms: Incorporate feed-forward networks, layer normalization (pre/post), residual scaling, and biases into the theoretical model to confirm that sink necessity persists in more faithful Transformer blocks.
- Long-context behavior: Empirically and theoretically study how sink strength and location scale with sequence length (far beyond L=16), sliding-window/streaming setups, and long-context extrapolation regimes (e.g., ALiBi, RoPE).
- Cross-domain applicability: Generalize and test the necessity results in multimodal, vision, and diffusion LMs where sinks are observed, identifying domain-specific conditions for sink formation or avoidance.
- Optimization dynamics: While the results are expressiveness-based, it remains open how training dynamics select specific sink configurations (which layer/head/position), and whether certain initializations or curricula reduce harmful sink side-effects without violating necessity.
- Expected vs. worst-case loss: The proofs use a supremum (worst-case) loss; analyze whether analogous necessity holds under expected loss, and quantify how tail behaviors of the input distribution influence sink strength.
- Empirical breadth and reproducibility: Expand experiments beyond small, synthetic models to larger architectures with standard training stacks (LN, FFNs, RoPE), diverse seeds, and broader metrics (e.g., stability, calibration, quantization friendliness) to validate external validity.
- Practical trade-offs: Systematically compare softmax vs. ReLU (and other non-normalized) attention on standard benchmarks for accuracy, stability, and efficiency to evaluate whether sink-free mechanisms introduce other costs or failure modes.
- Mitigation strategies within softmax: Given the necessity, specify and test principled mitigation targets (e.g., sink relocation, controlled sink mass, or shared anchors) that preserve no-op guarantees while reducing harmful side-effects (interpretability distortions, massive activations).
- Formal taxonomy of “probability simplex” constraints: Develop a precise characterization of the minimal mathematical properties (beyond the current normalization–monotonicity footnote) that force sinks, to guide the design of sink-free yet stable alternatives.
Practical Applications
Immediate Applications
These are deployable now with existing tooling or minor engineering effort. Each item notes likely sectors, candidate tools/workflows, and key assumptions/dependencies.
- Adopt sink-free attention when “no-op while waiting for a trigger” is needed but sinks are undesirable
- Sectors: AI infrastructure, software, multimodal/vision, edge/embedded ML
- What to do: Train or fine-tune models using non-normalized attention (e.g., ReLU attention, gated attention) so “off” states don’t require probability mass on a fixed position.
- Tools/workflows: Replace softmax attention blocks with ReLU/gated attention variants in PyTorch/JAX codebases for new model training; incorporate normalization-free attention in internal research models; run side-by-side A/B evaluations on downstream tasks.
- Assumptions/dependencies: Requires (re)training (pretrained weights with softmax are not drop-in compatible); task quality must be validated; theoretical results are shown for a specific trigger-conditional task—general benefits should be verified per application.
- Make interpretability and attribution “sink-aware”
- Sectors: AI safety/interpretability, academia, applied ML
- What to do: When attention mass collapses to BOS/position 0 in softmax models, treat it as a functional no-op anchor rather than a content-dependent dependency; exclude BOS sink attention from causal narratives unless the head is in “triggered” mode.
- Tools/workflows: Update attention visualizers and analysis scripts to tag and optionally suppress sink contributions in reports; add a “sink-aware” mode to existing interpretability dashboards.
- Assumptions/dependencies: Analysis holds for softmax-style attention; some heads/layers may not exhibit sinks (existential result for multilayer models).
- Use a trigger-conditional benchmark to evaluate attention mechanisms
- Sectors: Model evaluation, academia, foundation model development
- What to do: Incorporate the paper’s trigger-conditional averaging task (or variants) as a litmus test: softmax models should form sinks; ReLU/gated variants should solve the task without sinks.
- Tools/workflows: Add this task to internal eval suites; automate attention-mass monitoring on BOS across training.
- Assumptions/dependencies: Synthetic task approximates “trigger-on/aggregate; otherwise no-op” circuits seen in practice; it’s a necessary condition test for softmax, not a comprehensive capability measure.
- Prioritize architectural over heuristic sink mitigations
- Sectors: AI infrastructure, model optimization, quantization/compression
- What to do: For circuits that need a robust default no-op, avoid interventions that merely redistribute softmax probability mass (e.g., BOS penalties) and instead consider normalization-free attention to remove the source of sink formation.
- Tools/workflows: Update mitigation playbooks to evaluate mechanism changes (ReLU/gated) before applying softmax-internal penalties; track sink metrics during compression/quantization trials.
- Assumptions/dependencies: Within softmax, suppressing sinks can harm the no-op guarantee or move the anchor elsewhere (another position/head/layer).
- Streamed/long-context inference optimization using sink behavior
- Sectors: Serving/inference platforms, enterprise AI, finance/legal document processing
- What to do: Exploit the fact that pre-trigger positions in softmax heads collapse to an anchor to simplify cache reads and reduce compute in dormant phases; detect trigger positions to switch to full attention only when needed.
- Tools/workflows: Add trigger detectors and early-exit patterns for pre-trigger tokens; cache-aware scheduling that bypasses full attention when heads are in sink mode.
- Assumptions/dependencies: Benefits are head/task-dependent; care is needed to avoid missing rare triggers.
- Risk assessment and red-teaming checklists that include sinks
- Sectors: AI governance/safety, regulated industries
- What to do: Add sink monitoring to auditing pipelines to identify circuits that stay dormant until a trigger appears—useful for evaluating latent behaviors and robustness.
- Tools/workflows: Automatic reports that flag strong BOS attention at non-trigger positions; scenario tests with/without triggers to observe behavior shifts.
- Assumptions/dependencies: Theoretical necessity shown for a specific task; use as a signal, not as sole evidence of risk.
- Model cards and documentation that disclose sink behavior
- Sectors: Industry, open-source model hubs, policy transparency
- What to do: Report whether strong sinks are observed, where (layers/heads), and under what inputs; indicate if normalization-free attention is used to avoid sinks.
- Tools/workflows: Extend model card templates with “Sink presence and triggers” section; attach plots/stats from the trigger-conditional benchmark.
- Assumptions/dependencies: Requires attention logging; standardization benefits from community conventions.
- Multimodal capacity reclaim in vision/LVLM pipelines
- Sectors: Vision, robotics, autonomous systems, AR/VR
- What to do: In tasks where non-content tokens cause visual attention sinks, trial normalization-free attention in new training runs to avoid wasting capacity on sink tokens.
- Tools/workflows: Prototype ReLU/gated attention in ViT/LVLM components; compare attention maps and task metrics.
- Assumptions/dependencies: Retraining required; downstream trade-offs must be measured on target datasets.
Long-Term Applications
These require further research, scaling, or ecosystem development before widespread deployment.
- Design and standardize sink-free attention mechanisms for production LLMs
- Sectors: Foundation model providers, open-source ecosystems
- What: Develop, benchmark, and adopt non-normalized or gated attention that supports robust no-op states without forming sinks (e.g., ReLU, gating, threshold/entropy-stable variants).
- Potential products: “Sink-free Transformer” libraries; drop-in attention modules with training recipes.
- Dependencies: Extensive pretraining experiments to ensure quality, stability, and compatibility with long-context and multimodal tasks.
- Hardware/accelerator co-design for normalization-free attention
- Sectors: Semiconductors, cloud providers
- What: Co-optimize memory, bandwidth, and compute paths for sparse/gated or ReLU-style attention where normalization is not a bottleneck.
- Potential products: Kernels and accelerators that prioritize non-normalized attention and trigger-conditional gating.
- Dependencies: Stable algorithmic baselines and widespread software adoption.
- Standards and policy for transparency on attention behavior
- Sectors: Governance bodies, industry consortia
- What: Establish reporting requirements and benchmarks for sink presence/strength and trigger-conditional circuits; include in safety audits and model cards.
- Potential tools: Shared benchmark suites; standardized metrics (e.g., pre-trigger BOS mass, head-level sink indices).
- Dependencies: Community consensus and cross-organization collaboration.
- Training recipes for sink-aware long-context and streaming models
- Sectors: Enterprise AI, RAG/agents, legal/finance analytics
- What: Architectures and curricula that intentionally represent no-op states without sinks to improve stability under quantization, reduce massive activations, and enhance streaming efficiency.
- Potential workflows: Curriculum with explicit triggers; loss terms that encourage clean off-states in non-normalized attention.
- Dependencies: Demonstrations at scale and robust tooling for deployment.
- Automated discovery and mapping of trigger-conditional circuits
- Sectors: Interpretability research, assurance/compliance
- What: Algorithms that leverage the paper’s necessity result to identify where sink-dependent no-op circuits live (layers/heads) and how they activate.
- Potential tools: “Circuit mapper” that correlates sinks with triggers and downstream behaviors, guiding pruning or refactoring.
- Dependencies: High-fidelity logging and scalable analysis.
- Security and robustness mechanisms leveraging sink diagnostics
- Sectors: AI security, critical infrastructure
- What: Use sink patterns to detect or constrain latent/unintended behaviors tied to triggers; develop sink-aware defenses and tests.
- Potential products: Red-teaming suites that induce/remediate sink-driven circuits; policies to constrain trigger pathways.
- Dependencies: Broader empirical validation beyond synthetic tasks; alignment with threat models.
- Head pruning and specialization guided by sink profiles
- Sectors: Model compression, edge AI
- What: Identify consistently dormant (sink-heavy) heads for pruning or refactoring; promote specialization via sink-aware training.
- Potential tools: Pruning frameworks that use sink metrics as salience signals; sink-aware MoE routing in attention.
- Dependencies: Guarantees that pruned heads are not critical under rare triggers; retraining stabilization.
- Multimodal and diffusion model architectures that avoid capacity loss to sinks
- Sectors: Vision/LVLMs, generative media
- What: Integrate sink-free attention to reduce wasted attention on anchors (e.g., BOS-like tokens or blank regions), improving compute utilization and robustness.
- Potential products: Diffusion/vision backbones with normalization-free attention and encoder–decoder designs that are sink-resistant.
- Dependencies: Task-specific validation; training stability on large-scale multimodal corpora.
- Developer-facing tooling for “attention mechanism swapping”
- Sectors: MLOps, enterprise ML
- What: Tooling to prototype and compare attention mechanisms (softmax vs. ReLU/gated) on internal datasets with automatic sink reporting and regressions.
- Potential products: CLI/plugins for popular frameworks (PyTorch, Hugging Face) that enable rapid swaps and benchmarking.
- Dependencies: Interface standardization and model architecture modularity.
Cross-cutting assumptions and dependencies
- Scope of theorems: Necessity is proved for a synthetic trigger-conditional averaging task; while this mirrors “trigger-on/aggregate; otherwise no-op” heads observed in practice, generalization to all tasks is not guaranteed and should be empirically verified.
- Architecture dependence: Results hinge on softmax normalization over a probability simplex; conclusions may not apply to architectures that use gating or other non-normalized attention.
- Multilayer nuance: For deep models, existence of at least one sink is guaranteed, but not ubiquity; interventions must consider head/layer heterogeneity.
- Migration costs: Moving from softmax to normalization-free attention typically requires retraining and careful evaluation of accuracy, stability, and efficiency.
- Trigger availability: Practical workflows that exploit or avoid sinks depend on clear trigger signals in the data or model-internal indicators.
Glossary
- active–dormant attention head: An attention head that switches between an active computation mode and a dormant, sink-focused mode depending on input type. Example: "an active--dormant attention head in Llama~2--7B."
- ALiBi: A positional bias technique (Attention with Linear Biases) enabling length extrapolation by adding position-dependent biases to attention scores. Example: "ALiBi, RoPE, and even without explicit positional encodings"
- attention sink: A phenomenon where attention probability mass collapses onto a fixed, often early position, largely independent of content. Example: "Transformers often display an attention sink: probability mass concentrates on a fixed, content-agnostic position."
- BOS (Beginning-of-Sequence) token: A special token marking the start of a sequence, often used as a stable anchor for attention. Example: "on a fixed sink token (the BOS token) at all non-trigger positions"
- diffusion LLMs: Generative LLMs that use diffusion processes for text generation. Example: "similar behavior shows up in multimodal and vision settings, as well as in diffusion LLMs"
- gated attention: An attention mechanism augmented with gating functions that can modulate or turn off attention pathways. Example: "sinks do not appear in gated attention or Mamba-based models"
- long-context inference: Performing inference over very long input sequences, where efficiency and stability issues can arise. Example: "and complicate streaming and long-context inference"
- Mamba-based models: Sequence models built on the Mamba architecture, offering alternatives to traditional softmax attention. Example: "sinks do not appear in gated attention or Mamba-based models"
- no-op (no operation): A default model behavior that writes nothing (zero vector) to the residual stream when no trigger is present. Example: "default no-operation (no-op)"
- positional encodings: Representations injected into token embeddings to encode position information for attention mechanisms. Example: "even without explicit positional encodings"
- probability simplex: The set of nonnegative vectors that sum to one; softmax attention probabilities lie on this simplex. Example: "normalization over a probability simplex must force attention to collapse onto a stable anchor"
- quantization: The process of reducing numerical precision of model parameters/activations to compress or accelerate inference. Example: "Sinks can also worsen numerical issues relevant to compression and quantization"
- ReLU attention: A non-normalized attention variant using ReLU on attention scores, avoiding probability simplex constraints. Example: "non-normalized ReLU attention can solve the same task without any sink"
- residual stream: The running hidden representation that layers read from and write to in a Transformer. Example: "write to the residual stream"
- RoPE (Rotary Position Embedding): A positional encoding method that rotates query/key vectors to encode relative positions. Example: "ALiBi, RoPE, and even without explicit positional encodings"
- simplex constraint: The requirement (from softmax normalization) that attention weights form a probability distribution summing to one. Example: "without relaxing the simplex constraint"
- softmax attention: The standard attention mechanism that normalizes exponentiated scores with softmax to produce probability weights. Example: "single-layer softmax attention model f"
- softmax normalization: The softmax operation that enforces attention weights lie on the probability simplex. Example: "the softmax normalization is the driver of sink formation"
- trigger-conditional task: A task where the model performs a specific operation only when a trigger is detected; otherwise it does nothing. Example: "We introduce a trigger-conditional task"
- trigger token: A special token whose presence activates a different computation (e.g., averaging past tokens). Example: "when a designated trigger token appears"
- value map: The value projection in attention that transforms token representations before aggregation. Example: "the value map must crush a positive-probability set of non-trigger tokens"
Collections
Sign up for free to add this paper to one or more collections.