The Spike, the Sparse and the Sink: Anatomy of Massive Activations and Attention Sinks
Abstract: We study two recurring phenomena in Transformer LLMs: massive activations, in which a small number of tokens exhibit extreme outliers in a few channels, and attention sinks, in which certain tokens attract disproportionate attention mass regardless of semantic relevance. Prior work observes that these phenomena frequently co-occur and often involve the same tokens, but their functional roles and causal relationship remain unclear. Through systematic experiments, we show that the co-occurrence is largely an architectural artifact of modern Transformer design, and that the two phenomena serve related but distinct functions. Massive activations operate globally: they induce near-constant hidden representations that persist across layers, effectively functioning as implicit parameters of the model. Attention sinks operate locally: they modulate attention outputs across heads and bias individual heads toward short-range dependencies. We identify the pre-norm configuration as the key choice that enables the co-occurrence, and show that ablating it causes the two phenomena to decouple.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in a nutshell)
This paper looks inside LLMs that use Transformers and asks: why do two odd behaviors often show up together?
- Massive activations (“spikes”): a few parts of a model’s internal signal suddenly become huge for a small number of tokens (often the very first token or punctuation like a period).
- Attention sinks (“sinks”): certain tokens act like attention magnets; many attention heads keep looking at them even when they aren’t very meaningful.
The authors show these two effects often appear together not because they must, but mostly because of specific design choices in modern Transformers. They also show how to separate or reduce them without hurting the model’s language ability.
What questions the paper asks
The paper focuses on three simple questions:
- Why do “spikes” (massive activations) and “sinks” (attention magnets) appear together?
- Do they play the same role, or are they doing different jobs inside the model?
- Can we change the model’s design so we keep good performance but reduce one or both effects?
How they studied it (explained simply)
To understand what’s happening, the authors:
- Watched signals layer by layer: They tracked how big certain internal numbers get across the model’s depth. Think of following the “volume” of certain features from the start to the end of the network.
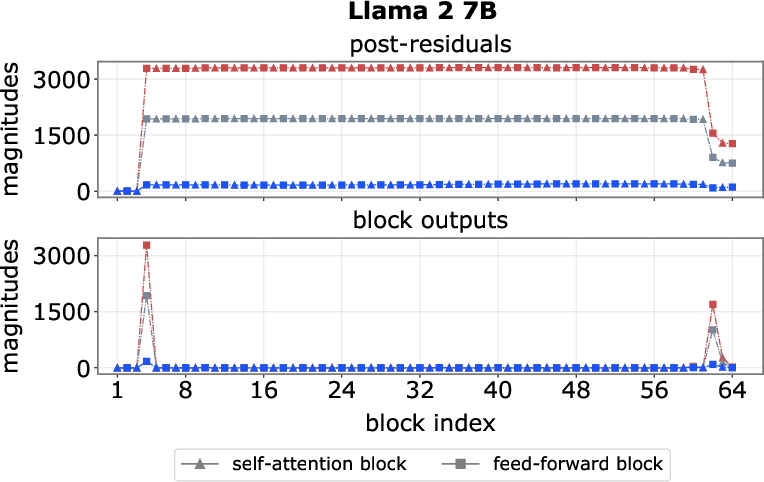
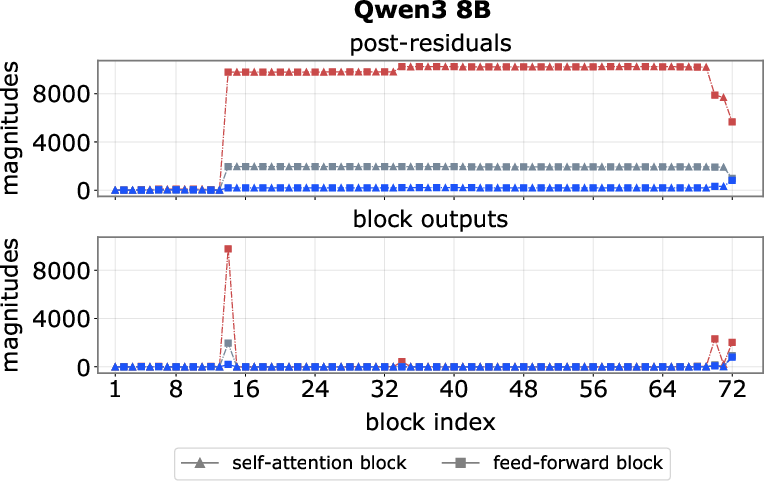
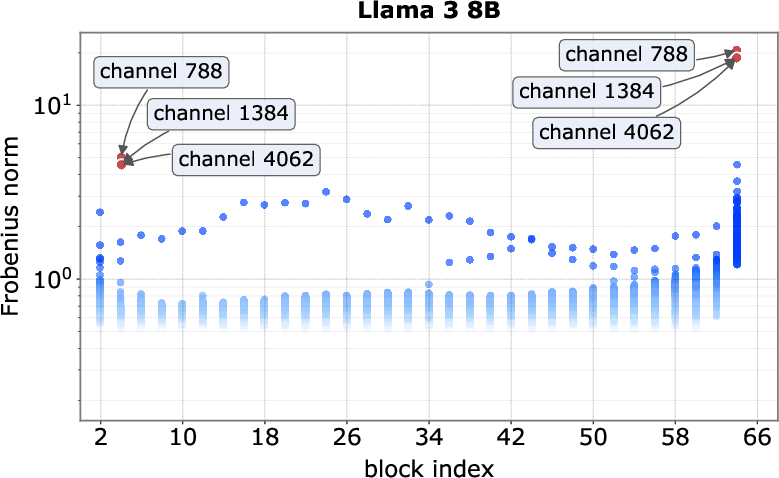
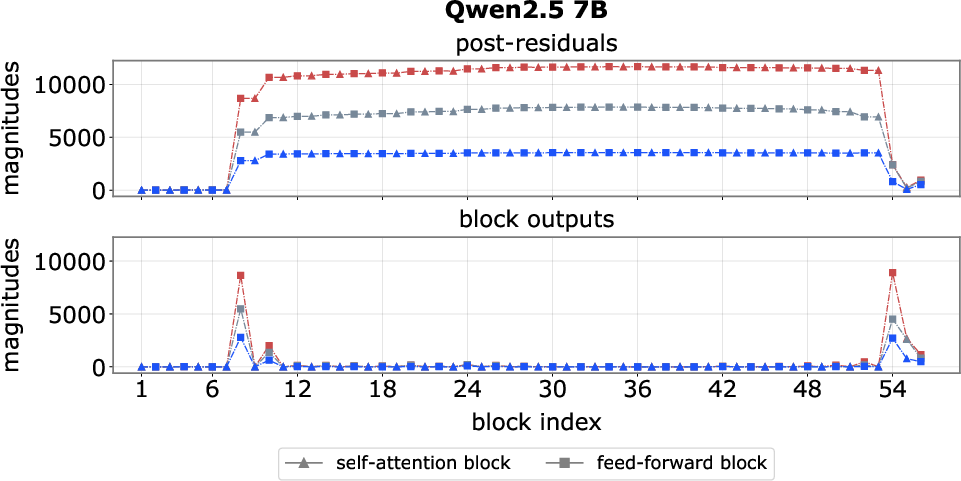
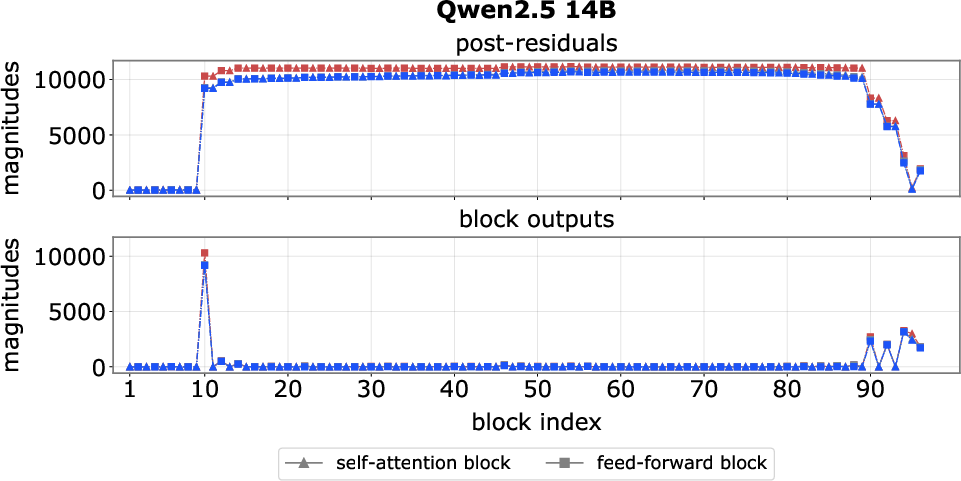
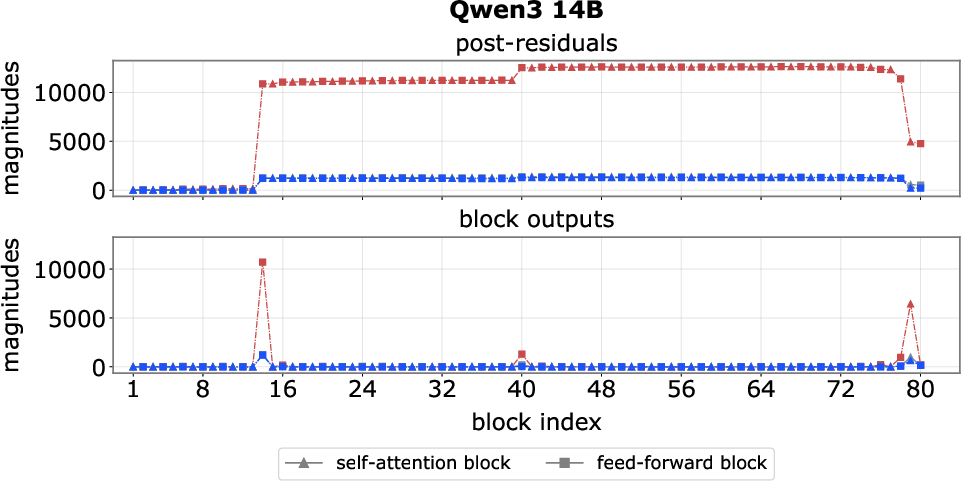
- Pinpointed where spikes start and stop: They found early “step-up” layers that blow up the signal (like pressing a turbo button) and late “step-down” layers that cancel it out.
- Looked at the “amplifier”: The model’s feed-forward part (a small neural network inside each layer) often acts like a directional amplifier—if the input points the “right way,” it gets boosted a lot. This explains why only certain tokens turn into spikes.
- Zoomed in on normalization: A standard step called “RMSNorm” (a kind of scaling that evens out sizes) sits before attention in many modern models (“pre-norm”). It turns those huge spikes into a limited, very sparse, nearly constant pattern. That stable pattern helps create attention sinks.
- Ran controlled swaps (ablations): They retrained models while changing one design detail at a time (like the type of normalization, number/size of attention heads, or the feed-forward design) to see what breaks, what stays, and what matters most.
Simple analogies:
- Residual connection = adding up all changes so far, like layering stickers on top of each other.
- Spike = someone shouting in a quiet room.
- RMSNorm = a volume limiter that prevents shouting from being too loud, but keeps the “shape” of who is loud vs. quiet.
- Keys and queries in attention = name tags and questions; if your question matches someone’s tag, you pay attention to them.
- Attention sink = a person who everyone keeps looking at by default, even when they’re not the most helpful.
What they found (and why it matters)
Here are the main results, presented simply:
- Spikes are created early, persist, then get canceled:
- Early “step-up” feed-forward blocks crank up a few channels for certain tokens (often the first token or delimiters like “.” or “\n”).
- The model’s “add everything up” design (residuals) makes these huge values stick around through many layers.
- Late “step-down” blocks add the opposite value to bring things back to normal before the output.
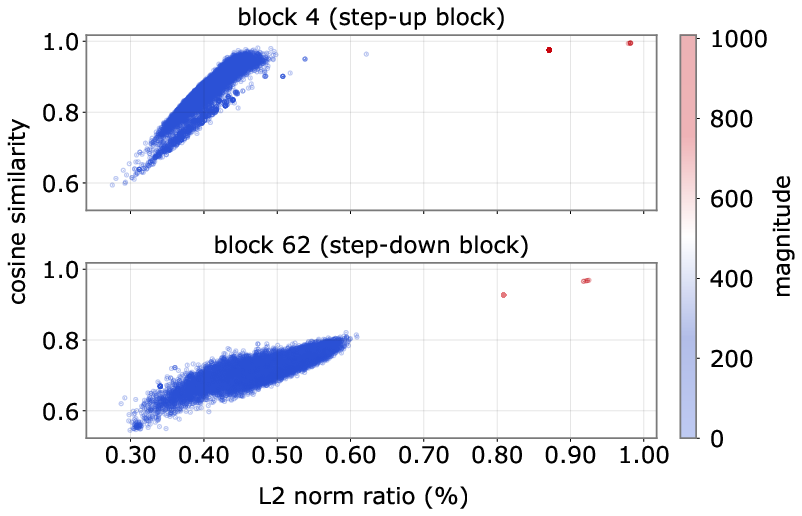
- The feed-forward block acts like a directional amplifier:
- It boosts signals a lot when the input is pointed in a specific direction (like a guitar amp tuned to one note).
- Different “spike channels” often share the same favored direction, so when a token aligns with it, multiple channels spike together in fixed ratios.
- Why some tokens spike (first tokens and delimiters):
- The very first token often only “looks at itself” in attention, so its path is very stable—perfect for lining up with the amplifier’s favored direction.
- Punctuation and newlines often behave similarly in early layers, making them candidates for spikes too.
- Normalization turns spikes into attention sinks:
- Pre-norm (RMSNorm before attention) squashes those huge values into a bounded, very sparse, almost identical pattern across different spike tokens.
- Because this pattern is so stable, the attention “keys” for these tokens look almost the same across many inputs.
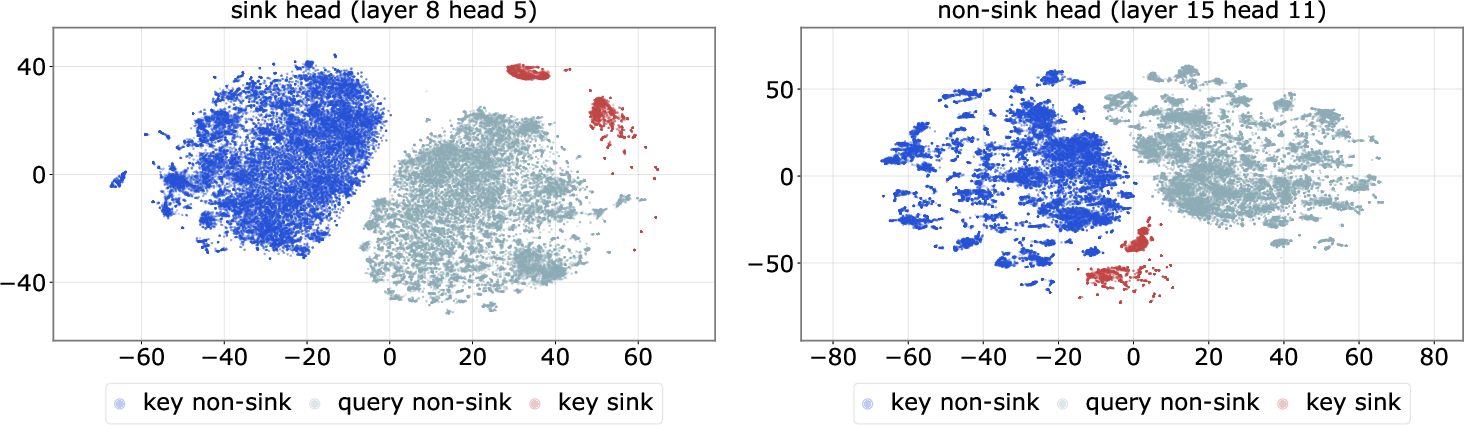
- In attention heads whose “query space” lines up with that stable key, these tokens become attention sinks—heads keep giving them extra attention no matter what else is going on.
- Spikes and sinks do different jobs and can be separated:
- Spikes act globally: they create near-constant hidden patterns that persist across layers, almost like extra built-in knobs the model can use.
- Sinks act locally: they bias specific attention heads toward looking nearby in the text (short-range patterns like sentence structure).
- Changing the normalization setup can reduce spikes while keeping sinks, and vice versa. This shows co-occurrence is mostly an architectural side effect, not a necessity.
- What controls sinks the most:
- The size of each attention head (head dimension) matters a lot. Bigger heads can more easily separate sink keys from other keys, making sinks stronger.
- The number of heads matters less than their size, if total capacity is the same.
- Special “gated attention” designs (which dynamically control attention) can reduce sinks and spikes without hurting performance.
- Training settings and performance:
- The “sink ratio” (how much attention goes to sinks) often grows when training is going well, so it can be a rough sign of optimization health.
- The sheer size of spikes doesn’t reliably track performance; very big spikes aren’t necessarily better.
Why this is important:
- It explains puzzling behaviors in LLMs.
- It shows how to redesign models to be more stable and efficient or better for long inputs, memory use, and compression (quantization and pruning).
What this means going forward
- Architecture choices matter a lot: Putting normalization before attention (pre-norm) plus certain feed-forward designs makes spikes and sinks appear together. Changing these choices can decouple them.
- We can build models that keep strong performance while:
- Reducing massive spikes (for easier compression and safer numerics),
- Controlling attention sinks (for better long-context behavior and more meaningful attention patterns).
- Practical payoffs include better memory handling, smoother quantization, more robust pruning, and potentially more interpretable attention.
In short, the paper shows that “the spike and the sink” are not mysterious must-have ingredients of Transformers. They are mostly consequences of design choices—and we can adjust those choices to get the behavior we want.
Knowledge Gaps
Unresolved gaps, limitations, and open questions
Below is a single, actionable list of what the paper leaves missing, uncertain, or unexplored, prioritized toward items future researchers can directly investigate.
- Generalization beyond decoder-only, pre-norm LLMs:
- Does the proposed spike→sink mechanism hold in post-norm Transformers, encoder–decoder models, mixture-of-experts, multimodal Transformers, and vision Transformers? A direct replication across these architectures is missing.
- Positional encoding dependence:
- The role of positional encoding (RoPE vs ALiBi vs learned absolute/relative) is not isolated. How do different positional schemes affect (i) first-token alignment to the spike direction and (ii) sink formation?
- BOS/first-token handling:
- The “first-token as linear map” account suggests BOS-centered sinks; how do models without an explicit BOS, or with special BOS handling, behave? Are sink/spike patterns sensitive to BOS placement and preprocessing?
- Cross-tokenizer and multilingual effects:
- The analysis focuses on Llama/Qwen tokenizers and primarily English-like data. Do spike channels and sink behavior persist under different tokenizers (BPE vs SentencePiece vs unigram) and in non-Latin scripts or multilingual pretraining?
- Training-data and context-length distribution:
- The paper posits that sinks are driven by attention-space dimensionality and training context-length distribution but does not fully ablate or quantify this. How do different context-length curricula and short/long-context data mixes causally modulate sink intensity and locality bias?
- Formation dynamics during training:
- When and how do step-up/step-down blocks emerge over training? Are their indices stable across seeds and checkpoints? A temporal analysis of spike and sink formation (and their variability) is absent.
- Origin of rank-one dominance in FFN quadratic forms:
- Why do the FFN quadratic forms develop shared principal directions and large leading eigenvalues? Are these induced by optimization biases, data statistics, or initialization? A causal account of weight alignment is missing.
- Role and parameterization of normalization:
- The paper both omits and invokes RMSNorm’s learnable scale; the exact contribution of the per-channel scale parameters (γ) to spike sparsification and near-constancy is not isolated. A controlled ablation of γ (frozen, per-layer, per-channel, removed) is needed.
- Post-norm and alternative norms:
- Beyond “sandwich norm” and QKNorm, how do LayerNorm, ScaleNorm, RMSNorm variants, or normalization-free transformers affect spike propagation and sink formation? A broader normalization survey is missing.
- QK scaling and softmax temperature:
- The standard 1/√d_head scaling is assumed. How does altering QK scaling, learned temperatures, or per-head temperature schedules affect sink formation and logit gaps?
- Mechanistic role of V/O projections:
- The emphasis is on Q/K geometry; the contribution of V and W_O (e.g., whether values amplify or counteract sinks, or how W_O couples heads) is not analyzed. Can modifying V/O projections modulate sink behavior independently of Q/K?
- Gated attention mechanisms:
- The gated-attention section is incomplete; comprehensive comparisons across gating schemes (content-conditioned vs position-conditioned vs learned scalar gates), their stability, and mechanistic impact on spikes/sinks remain open.
- Task-level consequences beyond perplexity:
- Most conclusions rely on perplexity and sink ratio. Effects on downstream tasks (reasoning, code, long-context retrieval, compositional generalization), calibration, and robustness are untested. Do sink-suppressing designs hurt/help specific abilities?
- Practical implications for systems:
- Although spikes/sinks are linked to quantization, pruning, KV-cache and long-context inference, there are no end-to-end evaluations showing how proposed mitigations (e.g., sandwich norm, DynamicTanh, head-dimension tuning) improve latency, memory, or accuracy under quantization/low-bit deployments.
- Long-context behavior and distance bias:
- The claim that sinks bias heads toward short-range dependencies is not supported with quantitative head-level distance distributions or syntactic/semantic span analyses. Rigorous measurements of attention distance profiles and their changes under interventions are missing.
- Stability and reproducibility:
- Variance across random seeds and training runs, and sensitivity to optimizer/config choices beyond those tested, are not reported. Confidence intervals or statistical tests for sink ratio and spike magnitudes are lacking.
- Numerical formats and precision:
- The impact of FP16 vs BF16 vs FP8 (and mixed-precision scaling) on spike magnitude, normalization-induced sparsity, and sink formation is unstudied. Are spikes exacerbated by lower precision or accumulation strategies?
- Scale and data limitations:
- The main from-scratch experiments use 7B-scale models trained for 100B tokens on DCLM. Do results extrapolate to ≥30B+ models and trillion-token training? Replications at larger scales and on different corpora are absent.
- Intervention minimality and trade-offs:
- The paper claims spikes and sinks can be suppressed without degrading LM performance, but “performance” is proxied by perplexity. What are the trade-offs for convergence speed, stability, compute cost, and generalization? Do interventions introduce other pathologies (e.g., under-attention, mode collapse of heads)?
- Alternative nonlinearity exploration:
- While GeLU and SwiGLU are tested, a wider sweep (ReLU, ReGLU, GEGLU, GELU-Tanh hybrids, bounded vs unbounded activations) and their specific propensity to produce directional quadratic amplification is not explored.
- Subspace analysis rigor:
- The geometric story relies on t-SNE visualizations. Quantitative measures (principal angles between subspaces, projection residuals, subspace overlap metrics) are not reported, leaving the separation claims only qualitatively supported.
- First-token and delimiter mechanisms:
- The assertion that delimiters gain self-attention due to “near-collinearity with RMSNorm scaling” is plausible but unverified with targeted measurements (e.g., channel-wise γ alignment, per-token norm dynamics). A direct causal test is missing.
- Soft interventions at inference:
- Can we reduce sink mass at inference (e.g., reweight BOS keys, per-head temperature, K/V rescaling) without retraining? The paper does not evaluate lightweight inference-time controls and their side-effects.
- KV-cache and memory policies:
- Given sinks’ role in attention mass routing, can sink-aware KV-cache pruning or compression be safely deployed? Quantitative studies on cache hit rates, memory savings, and perplexity/regression are absent.
- Safety and controllability:
- Do spikes/sinks interact with adversarial prompts, jailbreaks, prompt injection, or instruction-following stability? The security and alignment implications are unexplored.
- Checkpoint-wise persistence of spike channels:
- Are the identities of spike channels and step-up/step-down blocks stable across checkpoints and seeds, or do they drift while preserving function? This would clarify whether spikes are tied to specific neurons or to distributed mechanisms.
- Interaction with instruction-tuning/RLHF:
- Do supervised fine-tuning and RLHF amplify, dampen, or repurpose spike/sink mechanisms learned in pretraining? No analysis is provided.
- Theoretical guarantees:
- Approximations (e.g., SiLU ≈ identity, RMSNorm-induced sparsification) are offered without formal conditions on when they hold. Can we prove bounds on when spikes yield near-constant normalized vectors and when head subspaces can separate sink keys?
Practical Applications
Overview
This paper explains why “massive activations” (spikes) and “attention sinks” co-occur in pre-norm decoder-only Transformers, and shows how to decouple, control, or exploit them. Key findings with practical consequences include:
- Spikes are globally persistent outliers injected by early feed-forward “step-up” blocks and neutralized by late “step-down” blocks; after RMSNorm, they act like near-constant, sparse vectors (implicit parameters).
- Attention sinks are largely a geometric outcome of head dimensionality and context-length training distribution; they locally bias heads toward short-range dependencies and can be modulated via normalization, gating, and head design.
- Normalization is the causal bridge: pre-norm encourages co-occurrence; sandwich normalization, QKNorm, or bounded element-wise transforms suppress spikes (and can preserve or reshape sinks) without harming perplexity.
- Sink ratio behaves as a surprisingly good proxy for optimization health; spikes and sinks can be independently suppressed with negligible perplexity impact.
Below are concrete applications, organized by time horizon.
Immediate Applications
These can be adopted in current training and inference pipelines with minimal engineering risk.
- Stabilize training and inference by choosing normalization that tames spikes
- Sectors: software/ML infrastructure, cloud/edge deployment, energy efficiency
- Tools/workflows: switch to sandwich normalization (post-block RMSNorm), apply QKNorm (normalize only Q,K), or replace block-level norms with bounded element-wise transforms (e.g., DynamicTanh)
- Benefits: reduces numerical outliers, improves quantization robustness, helps KV-cache stability
- Assumptions/dependencies: results demonstrated on Llama-style pre-norm decoder-only models; re-tuning may be required for large proprietary architectures
- Improve quantization pipelines via spike- and sink-aware calibration
- Sectors: software/ML infrastructure, mobile/edge, healthcare/finance compliance (on-device models)
- Tools/workflows: per-channel scaling for spike channels; apply targeted clipping only to spike channels; calibrate with first-token and delimiter-heavy prompts; integrate with existing SmoothQuant-style flows
- Benefits: fewer quantization artifacts, better 8/4-bit accuracy, reduced energy use
- Assumptions/dependencies: requires reliable spike-token/channel detection; modest data collection for calibration
- Optimize KV-cache and long-context inference with sink-aware policies
- Sectors: long-context apps (RAG, code, legal), enterprise SaaS
- Tools/workflows: compress or de-duplicate near-constant sink keys; deprioritize cache updates in sink heads; adaptive cache eviction for sink tokens
- Benefits: lower memory and latency with negligible perplexity loss
- Assumptions/dependencies: attention-pattern telemetry required; validate on target long-context distributions
- Tune attention head geometry to control sinks and short-range bias
- Sectors: model training, domain adaptation (code, biomedical text)
- Tools/workflows: concentrate capacity into fewer, larger heads (larger head dimension) to encourage stronger, controllable sink behavior; or keep more, smaller heads to dilute sinks
- Benefits: task-driven control of locality bias, perplexity/performance trade-offs
- Assumptions/dependencies: head-dimension effects are strong drivers; rebalancing requires small recipe tweaks
- Suppress sinks and spikes with conditional gated attention during training
- Sectors: safety/reliability, regulated domains
- Tools/workflows: multiplicative gates conditioned on current hidden states; avoid purely positional or static gates
- Benefits: dramatically lowers sink ratio and spike magnitudes with minimal perplexity change
- Assumptions/dependencies: implementation in attention kernels; validate downstream task effects beyond perplexity
- Use sink ratio as an optimization-health KPI
- Sectors: MLOps, training operations
- Tools/workflows: training dashboards tracking sink ratio alongside loss, LR, β2, and weight decay; early warnings for unhealthy regimes (e.g., extreme LR or disabled weight decay)
- Benefits: faster diagnosis of bad training states and recipe regressions
- Assumptions/dependencies: metric collection during training; set task-specific thresholds
- Prune or route compute using spike/sink anatomy
- Sectors: inference acceleration, cost reduction
- Tools/workflows: prune persistently non-informative heads/channels; dynamically skip or downweight sink heads for tokens where sinks dominate; head-level routing in speculative decoding
- Benefits: speedups and cost savings with minimal accuracy loss
- Assumptions/dependencies: safe pruning policies; guardrails for out-of-distribution prompts
- Prompt and data curation guidelines to avoid pathological sinks
- Sectors: industry prompt engineering, education, daily use
- Tools/workflows: avoid excessive delimiter bursts at critical reasoning points; use short, neutral prefixes to shape or neutralize sinks; mix context lengths in fine-tuning corpora
- Benefits: better stability and reasoning locality
- Assumptions/dependencies: mild user/process training; verify task-specific impacts
- Safer deployment via sink/spike audits
- Sectors: safety, governance, policy
- Tools/workflows: pre-release audits reporting sink ratio, spike magnitudes, step-up/down block indices; regression tests on sink-heavy prompts
- Benefits: standardized risk reporting and reproducibility
- Assumptions/dependencies: community consensus on metrics; integration into existing model cards
- Targeted adapters/distillation that respect spike channels
- Sectors: model compression, fine-tuning
- Tools/workflows: LoRA/adapter layers that explicitly re-normalize or de-emphasize spike channels; distillation losses that penalize excessive sink reliance
- Benefits: more robust small models with fewer activation outliers
- Assumptions/dependencies: adapter capacity and proper loss balancing required
Long-Term Applications
These require further research, scaling studies, or ecosystem adoption.
- Architectures that decouple or eliminate spike–sink coupling by design
- Sectors: foundation models, open-source model ecosystems
- Tools/products: non pre-norm stacks, sandwich/QK-only normalization defaults, broader use of bounded element-wise transforms (e.g., DynamicTanh), and conditional gating as first-class primitives
- Benefits: inherently stable activations; controllable attention locality; simpler quantization
- Assumptions/dependencies: large-scale pretraining validation; compatibility with rotary/positional schemes
- Automated head-geometry and normalization search targeting sink metrics
- Sectors: AutoML, model engineering
- Tools/products: NAS/AutoML objectives that jointly optimize perplexity and sink ratio/short-range bias; head-size allocation schedulers
- Benefits: task-aligned locality and better scaling laws
- Assumptions/dependencies: reliable surrogate metrics; compute budget for search
- Sink-aware hardware and kernels
- Sectors: accelerators, compilers
- Tools/products: kernels that detect near-constant normalized vectors and compress them; mixed-precision that assigns higher precision only to spike channels; KV-cache hardware with sink de-duplication
- Benefits: energy and memory savings; improved throughput
- Assumptions/dependencies: ISA/compiler support; robust online detection with negligible overhead
- Training curricula that shape context-length distribution to control sinks
- Sectors: large-scale training, education/assistive AI
- Tools/products: schedulers that dynamically adjust short/long context sampling to achieve desired short-range bias; domain-specific curricula (code vs prose)
- Benefits: improved long-context generalization and controllable locality
- Assumptions/dependencies: data availability; monitoring infrastructure for locality metrics
- Formal safety and robustness guarantees against sink exploitation
- Sectors: safety, regulated industries
- Tools/products: certified bounds on attention logits under bounded-normalization regimes; audits for adversarial first-token or delimiter attacks that hijack attention
- Benefits: stronger assurances for high-stakes deployment
- Assumptions/dependencies: tractable verification frameworks for Transformer attention
- Standardization of spike/sink reporting in model cards and evals
- Sectors: policy, procurement, governance
- Tools/products: community benchmarks and reporting templates (e.g., sink ratio, spike-channel counts, step-up/down locations, sensitivity to head dimension)
- Benefits: comparability, transparent risk/efficiency profiles
- Assumptions/dependencies: alignment among labs and standards bodies
- Cross-modal and multi-agent extensions with controlled locality
- Sectors: vision–language, speech, robotics
- Tools/products: attention designs that modulate short-/long-range biases across modalities; sink-aware planners for tool-use agents; controllers minimizing activation bursts in control loops
- Benefits: latency stability, better grounding, safer real-time behavior
- Assumptions/dependencies: modality-specific validation; careful integration with positional encodings
- “Attention Inspector” and “SpikeGuard” class products
- Sectors: observability/MLOps
- Tools/products: runtime and training-time telemetry, alerts, and automated mitigations (e.g., insert post-norm patches, re-tune gates, adjust head geometry)
- Benefits: faster debugging, proactive mitigation of regressions
- Assumptions/dependencies: vendor support in major frameworks; low-overhead hooks
- Advanced compression via sink-aware KV and head pruning at scale
- Sectors: enterprise LLM platforms, on-device assistants
- Tools/products: production-grade KV dedup/quantization tuned to sink patterns; policy engines to drop or merge sink-heavy heads
- Benefits: large memory savings with bounded quality loss
- Assumptions/dependencies: broad A/B testing across workloads; fallback/guardrail logic
- Interpretable “implicit parameter” controllers
- Sectors: finance/healthcare (auditability), education
- Tools/products: exposing spike-induced near-constant vectors as configurable knobs controlling locality or stylistic defaults; governance dashboards linking these controls to outputs
- Benefits: improved interpretability and governance
- Assumptions/dependencies: stable mapping from implicit parameters to behavior across domains
Notes on general feasibility:
- Most evidence is on Llama-style, pre-norm decoder-only Transformers; extrapolation to encoder–decoder or post-norm stacks needs validation.
- Perplexity parity does not guarantee downstream task parity; evaluate on target tasks.
- Some mitigations (e.g., dynamic gating) add engineering complexity to kernels and may require custom optimized implementations.
Glossary
- Ablation: An experimental technique where specific components or settings are removed or altered to test their causal impact on observed phenomena. "we perform targeted ablations to identify which architectural and training choices modulate these phenomena"
- Attention sink: Tokens that reliably attract a disproportionate amount of attention across heads and layers, often independent of semantic relevance. "attention sinks, in which certain tokens attract disproportionate attention mass regardless of semantic relevance."
- Autoregressive: A modeling approach that predicts each element conditioned on previous elements, factorizing a joint distribution into conditionals. "Autoregressive models address this by factorizing the joint distribution into a product of conditional probabilities:"
- Causal mask: A masking matrix that prevents positions from attending to future tokens, enforcing autoregressive decoding. "The causal mask enforces the autoregressive property:"
- Decoder-only Transformer: A Transformer architecture that uses only decoder blocks to model next-token prediction without an encoder. "decoder-only, pre-norm Transformers"
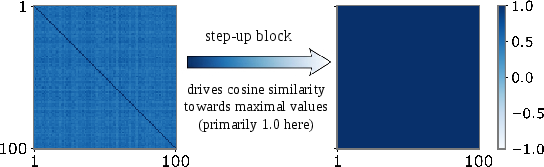
- Directional quadratic amplifier: A mechanism where the feed-forward block amplifies inputs aligned with a specific direction via a quadratic form, producing large activations. "functioning as a directional quadratic amplifier."
- DynamicTanh: A bounded, element-wise normalization/activation variant explored as an alternative to norm layers. "we replace standard normalization with an element-wise transformation, DynamicTanh"
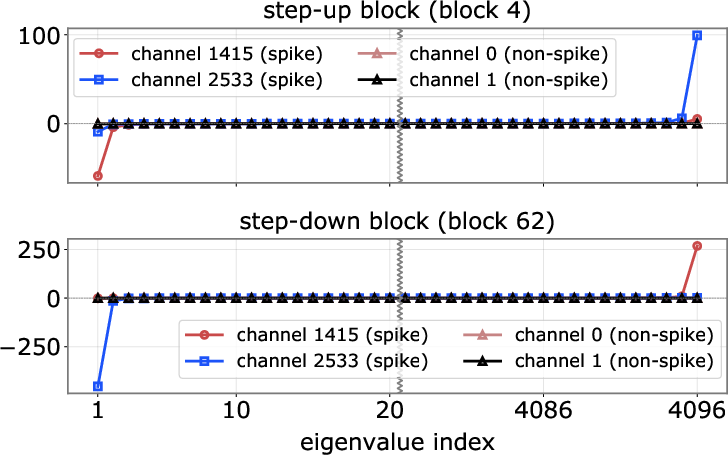
- Eigenvalue spectrum: The set of eigenvalues of a matrix, whose shape indicates properties like rank dominance. "Eigenvalue spectra of for spike vs.\ non-spike channels"
- Feed-forward block: The per-token nonlinearity and projection module in each Transformer layer, often implemented with gated activations. "the feed-forward block operates independently on each position."
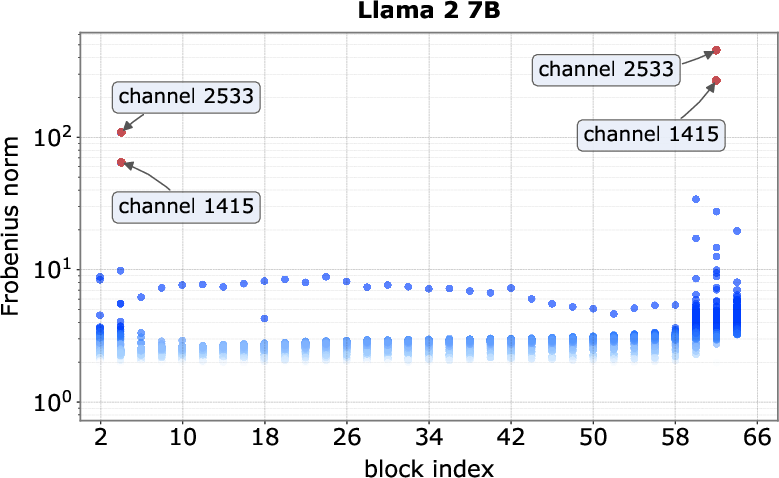
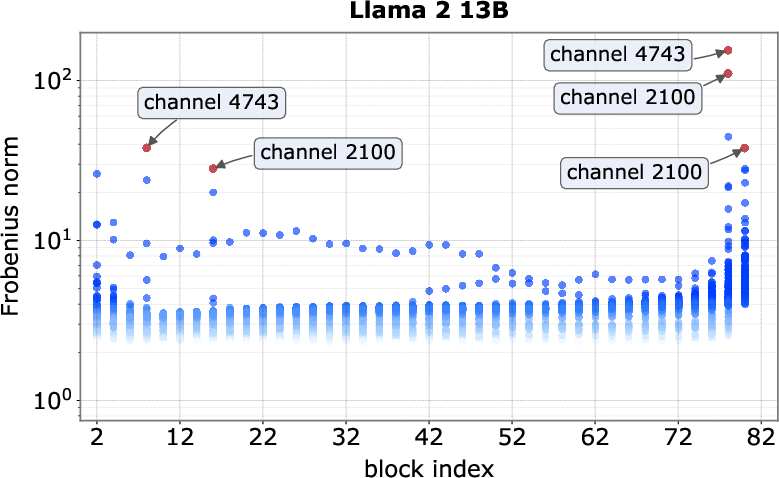
- Frobenius norm: A matrix norm equal to the square root of the sum of squared entries, used here to characterize quadratic forms. "Frobenius norms across all output coordinates"
- Gated attention: An attention variant where multiplicative gates modulate attention, studied for its effect on sinks and spikes. "one on gated attention~\cite{qiu2025gated}, which has been shown to reduce attention sinks and massive activations"
- GeLU: A smooth nonlinearity (Gaussian Error Linear Unit) used in standard Transformer feed-forward networks. "the standard two-layer GeLU-based feed-forward block"
- Hadamard product: The element-wise product of two vectors or matrices. "where denotes the element-wise (Hadamard) product."
- KV-cache: A mechanism to store past keys and values for efficient autoregressive decoding across long sequences. "KV-cache management~\cite{ge2023model,su2025kvsink,wu2024layer}"
- Logit gap: The difference between attention logits that creates a stable preference, here favoring sink tokens. "This alignment produces large, consistent logit gaps in favor of the sink token across diverse inputs."
- Multi-head attention: An attention mechanism that splits computation across multiple heads to capture diverse patterns. "The attention mechanism is implemented as multi-head attention with heads"
- Multi-hot representation: A sparse vector with several active (nonzero) positions, generalizing one-hot encodings. "This transformation yields a sparse, approximately multi-hot representation"
- Negative log-likelihood: The training objective minimized by LLMs, equivalent to maximizing likelihood. "minimizing the expected negative log-likelihood:"
- Perplexity: A common metric for LLMs indicating how well a model predicts tokens; lower is better. "we ... report perplexity, sink ratio, and maximal activation magnitudes."
- Pre-norm configuration: Applying normalization to inputs of each block before the residual addition, affecting gradient flow and representation dynamics. "Every block employs a residual connection with pre-norm configuration:"
- Principal eigenvector: The eigenvector corresponding to the largest eigenvalue, indicating the dominant direction of a matrix. "their matrices share nearly the same principal eigenvector ."
- QKNorm: A normalization variant that applies normalization only to queries and keys in attention. "a variant utilizing QKNorm~\cite{olmo2025olmo}, where input normalization is applied only to queries and keys."
- Quadratic form: A scalar function of a vector defined by vT A v; used here to describe the FFN’s amplified outputs. "Each output coordinate then admits the quadratic form"
- Residual connection: A skip connection that adds a block’s output to its input, enabling stable deep training. "Every block employs a residual connection with pre-norm configuration:"
- Residual stream: The accumulated hidden representation across blocks due to residual connections. "Because the residual stream is additive,"
- RMSNorm: Root Mean Square Layer Normalization, a normalization technique applied row-wise to stabilize activations. "The function is applied row-wise:"
- Rotary Position Embeddings: A positional encoding method applied to queries and keys to inject position information. "In practice, Llama applies Rotary Position Embeddings \cite{su2024roformer} to the and before computing ."
- Sandwich normalization: A design that applies normalization at both input and output of a block to bound activations. "we test sandwich normalization~\cite{ding2021cogview}, which adds an extra at the block output"
- SiLU: The Sigmoid Linear Unit activation function, observed here to operate near identity in spike regimes. "We empirically observe that the nonlinearity operates in a near-identity regime ()"
- Sink head: An attention head in which attention systematically gravitates to sink tokens. "sink tokens and sink heads."
- Sink ratio: A quantitative measure of how much attention is allocated to sink tokens across the model. "we ... report perplexity, sink ratio, and maximal activation magnitudes."
- Spike channels: Specific hidden dimensions that exhibit unusually large activation magnitudes for spike tokens. "we refer to the tokens and channels that exhibit massive activations as spike tokens and spike channels"
- Spike tokens: Tokens whose representations trigger massive activations in certain channels, often first or delimiter tokens. "we refer to the tokens and channels that exhibit massive activations as spike tokens and spike channels"
- Step-down block: Late blocks that inject opposite-signed activations to neutralize earlier spikes. "we identify one or a few late blocks, termed step-down blocks"
- Step-up block: Early blocks that introduce massive activations into the residual stream. "we find that massive activations are reliably introduced by one or two early blocks, which we term step-up blocks."
- SwiGLU: A gated feed-forward activation (SiLU gate) commonly used in modern LLMs. "Modern LLMs typically employ the SwiGLU activation function"
- t-SNE: A dimensionality reduction method for visualizing high-dimensional representations. "As visualized via t-SNE~\citep{maaten2008visualizing} in~\cref{figure:tsne}"
- Teacher forcing: A training strategy where the model is fed ground-truth prefixes at each position. "During training, all conditionals are produced in parallel by supplying the ground-truth prefix at every position via teacher forcing \cite{williams1989learning}."
Collections
Sign up for free to add this paper to one or more collections.

