PackForcing: Short Video Training Suffices for Long Video Sampling and Long Context Inference
Abstract: Autoregressive video diffusion models have demonstrated remarkable progress, yet they remain bottlenecked by intractable linear KV-cache growth, temporal repetition, and compounding errors during long-video generation. To address these challenges, we present PackForcing, a unified framework that efficiently manages the generation history through a novel three-partition KV-cache strategy. Specifically, we categorize the historical context into three distinct types: (1) Sink tokens, which preserve early anchor frames at full resolution to maintain global semantics; (2) Mid tokens, which achieve a massive spatiotemporal compression (32x token reduction) via a dual-branch network fusing progressive 3D convolutions with low-resolution VAE re-encoding; and (3) Recent tokens, kept at full resolution to ensure local temporal coherence. To strictly bound the memory footprint without sacrificing quality, we introduce a dynamic top-$k$ context selection mechanism for the mid tokens, coupled with a continuous Temporal RoPE Adjustment that seamlessly re-aligns position gaps caused by dropped tokens with negligible overhead. Empowered by this principled hierarchical context compression, PackForcing can generate coherent 2-minute, 832x480 videos at 16 FPS on a single H200 GPU. It achieves a bounded KV cache of just 4 GB and enables a remarkable 24x temporal extrapolation (5s to 120s), operating effectively either zero-shot or trained on merely 5-second clips. Extensive results on VBench demonstrate state-of-the-art temporal consistency (26.07) and dynamic degree (56.25), proving that short-video supervision is sufficient for high-quality, long-video synthesis. https://github.com/ShandaAI/PackForcing




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about making AI models better at creating long, smooth, and interesting videos. Most current models are great at short clips (like 5–10 seconds) but struggle with longer ones because they run out of memory, repeat motions, or slowly drift away from the original idea. The authors introduce a new method called PackForcing that lets a model remember the past in a smart, compact way, so it can generate high-quality videos up to 2 minutes long—even if it was only trained on 5-second clips.
What questions are they trying to answer?
- How can we stop small mistakes from piling up when a model makes a long video, so the story and look stay consistent over time?
- How can we prevent the model’s memory from growing too big as the video gets longer?
- Is it possible to train on short videos but still create long, coherent videos during generation?
How did they do it? (Methods in simple terms)
Imagine the model is making a movie scene-by-scene. To keep track of what happened before, it keeps a “scrapbook” of notes. The problem is, if it saves everything at full detail, the scrapbook gets too heavy. PackForcing fixes this by organizing and compressing the scrapbook in three smart ways.
Here’s the idea in everyday language:
- The model makes videos one chunk at a time and needs to look back at what happened earlier. This memory is called a “KV cache” (think: a notebook of key facts about past frames).
- If the notebook grows with every new chunk, it gets too big to carry. So the authors split it into three parts and compress the middle part a lot.
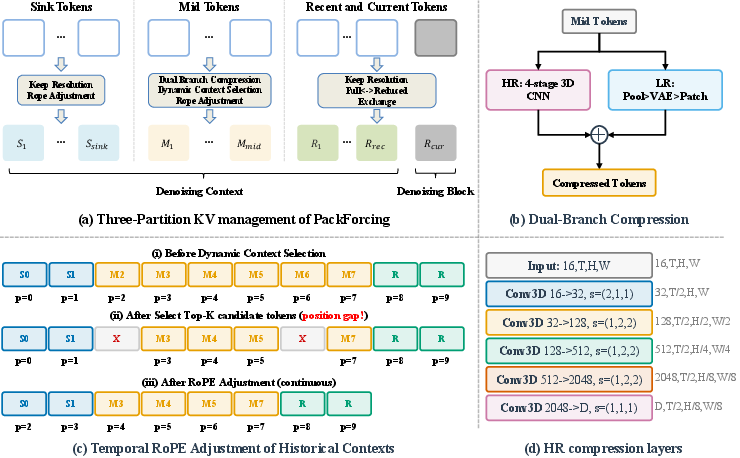
The three memory parts (the “three-partition KV cache”)
- Sink tokens: These are like sticky-note bookmarks on the very first frames. They’re kept at full quality forever to lock in who the characters are, the overall scene, and the style. This prevents the video from drifting away from the original idea.
- Mid tokens (compressed): This is the big middle of the story. Instead of saving every detail, the model saves a super-compact summary—about 32 times smaller in “token” count. Think of this like turning many pages of the scrapbook into a few highlight cards that still keep the important info.
- Recent tokens: These are the latest frames used to make the next ones. They’re kept at full quality to make motion smooth and natural between nearby frames.
To choose what’s most helpful from the compressed middle, the model uses Dynamic Context Selection: it picks only the most relevant highlight cards to look at right now, based on what it’s currently trying to draw.
How do they compress without losing what matters?
They use a “dual-branch” compressor—two simple ideas working together:
- HR branch: Shrinks the video information step-by-step using 3D filters (like shrinking an image but keeping edges and structure sharp).
- LR branch: Briefly turns the frames back into pictures, downsizes them, then re-encodes them. This keeps the big-picture meaning and layout.
The two results are added together, so the compressed memory keeps both detail and meaning while being much smaller.
How do they move old frames into the compressed memory smoothly?
They use Dual-Resolution Shifting:
- While the model uses full-quality recent frames, it also quietly creates a small backup version in the background.
- When frames get older, the full-quality version is swapped out and the compact version slides into the mid-memory. This keeps everything smooth with no waiting.
What if some old compressed chunks are removed?
Imagine you remove some oldest pages from a notebook—you might need to re-number the remaining pages. The model does a tiny “time re-numbering” tweak called Temporal RoPE Adjustment. It fixes the time positions of the saved memory so everything lines up correctly again, without recomputing everything. This is fast and keeps the story in order.
What did they find?
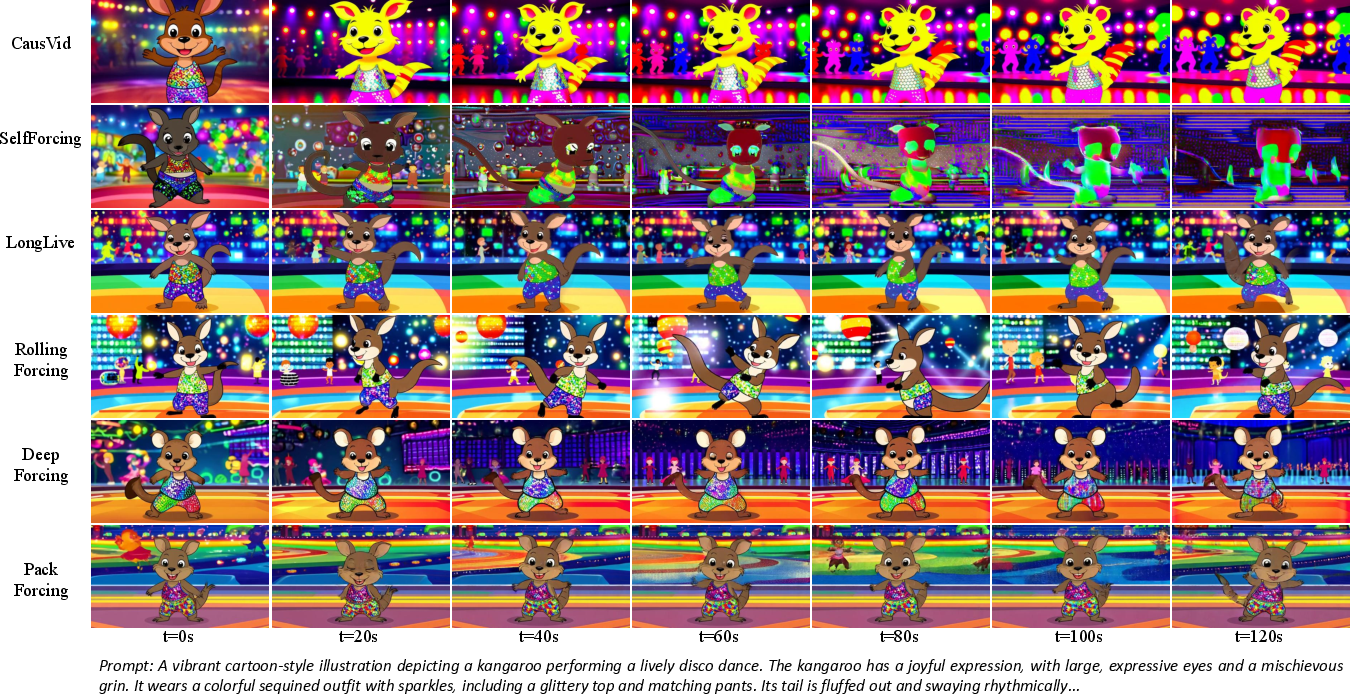
- Long videos on one GPU: The method can make 2-minute videos at 832×480 resolution and 16 FPS on a single H200 GPU.
- Small, steady memory: The model’s memory stays bounded at around 4 GB, instead of growing without limit.
- 24× longer than training: Even when trained on only 5-second clips (or used without extra training), it can generate 120-second videos that stay coherent.
- Strong quality and motion: On a popular benchmark (VBench), PackForcing achieves state-of-the-art scores in temporal consistency and motion richness (Dynamic Degree), meaning the videos move naturally and stay consistent over time.
- Stable text alignment: The match between the prompt and the video (measured by CLIP score) stays high over time, while other methods drift.
Why this matters:
- It proves you don’t need huge training videos to create long ones at test time.
- It shows you can keep memory small and still remember what matters.
Why does it matter?
PackForcing makes long video generation more practical, efficient, and reliable:
- Creators could make longer, more dynamic videos with less powerful hardware.
- Studios or apps could generate real-time, story-consistent content without constant glitches or repetition.
- Researchers can train on widely available short clips and still get long, coherent outputs.
In short, this work shows that with smart memory management—bookmarking key beginnings, compressing the middle well, and keeping the latest frames sharp—short training can be enough to make long, high-quality videos. This opens the door to more accessible, scalable, and creative AI video tools.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of concrete gaps, uncertainties, and open problems that remain unresolved and could guide future research.
Scalability and efficiency
- Lack of comprehensive throughput benchmarks: no end-to-end latency breakdown (tokenization, compression, selection, attention, VAE decode/re-encode) or tokens-per-second across different GPUs (e.g., A100, 4090, L4), batch sizes, and mixed precision settings.
- Ambiguity in “16 FPS” claim: unclear whether the method achieves real-time wall-clock synthesis at 16 FPS for 832×480 or only outputs 16 FPS videos; streaming latency and jitter under continuous generation are not reported.
- Scaling to higher resolutions and frame rates (e.g., 1080p/4K, 24–60 FPS) is untested; the compression ratio, KV budget, and attention cost may need re-tuning—no guidance or empirical scaling laws are provided.
- Upper bound on duration is not explored: quality beyond 120 s (e.g., 5–10+ minutes) and the impact of repeated eviction cycles on long-range narrative coherence remain unknown.
- Memory accounting for the “archived” compressed history is unclear: how large is the total archive, how is it bounded, and what are the costs of managing it over very long sequences?
Compression and KV cache management
- Sensitivity of performance to compression ratio is not studied: no ablation on varying temporal/spatial strides or target token counts; unclear where the quality-memory Pareto frontier lies.
- Alternative compression designs are not evaluated: comparisons to token merging, vector quantization, low-rank adapters, learned pooling, or cross-attention distillation into compact memories are missing.
- Compute overhead of the LR branch (pixel-space decode + pool + re-encode) is not quantified; impact on streaming latency and energy efficiency is unknown.
- Training objectives for the compressor are under-specified: no explicit reconstruction/distillation losses are described to guarantee information preservation; it is unclear how alignment between compressed and full-res tokens is enforced.
- Per-layer cache budgets and compression behaviors are fixed; no study of layer-wise heterogeneity (e.g., deeper layers possibly needing different N_sink/N_mid/N_recent or compression rates).
- Practical KV-cache quantization/low-precision storage (e.g., 8-bit/FP8) for further memory savings is not explored.
Dynamic selection and positional encoding
- The top-k selection uses query-key affinity computed only at the first denoising step and with subsampled queries/heads; the effect of this approximation on retrieval quality over time and across layers is not evaluated.
- No comparison to alternative routing signals (e.g., learned saliency predictors, cross-step momentum of importance, long-term novelty scores) or multi-criteria selection (semantic, motion, identity cues).
- Per-layer vs shared selection policies are not analyzed; selection granularity might need to differ across layers/heads for optimal retrieval.
- Stability and numerical behavior of repeated incremental RoPE temporal shifts for very long durations are untested; potential drift at large rotation angles and compatibility with other positional schemes (ALiBi, YaRN) remain open.
- Handling variable frame rates, dropped frames, or asynchronous stream inputs with temporal RoPE adjustment is not addressed.
Training data, schedule, and generalization
- Minimal training regime (≈3,000 iterations on 5 s windows) is reported without analysis of training duration/data scale effects; how much additional training is beneficial and where diminishing returns begin is unknown.
- Dataset composition and diversity (domains, motion types, identities, long-horizon narratives) are insufficiently specified; transfer to out-of-domain prompts or styles is not evaluated.
- Dependence on the Wan2.1-T2V-1.3B backbone is untested; portability to other architectures (e.g., CogVideoX, MovieGen, Open-Sora DiTs) and model sizes is unknown.
- No study of curriculum or augmentation strategies specialized for long-horizon behavior (e.g., synthetic scene changes, occlusion events) to improve robustness.
Evaluation and fairness of comparison
- Evaluation focuses on VBench metrics and CLIP; human studies and narrative consistency/plot coherence metrics over minutes-long videos are absent.
- Hard cases are under-explored: multi-subject interactions, frequent occlusions, fast camera motion, drastic scene changes, identity switching, or re-appearing objects after long gaps.
- Fairness and reproducibility of baselines: training/inference settings, prompts, and hyperparameters for baselines may differ; standardized re-runs and compute-normalized comparisons are not reported.
- Lack of ablations on key hyperparameters (N_sink, N_recent, N_mid/top-k) across a wide range; no guidance for automatic or adaptive scheduling of these budgets.
Robustness and failure modes
- Sink tokens as immutable anchors could be harmful under scene cuts or intentional topic shifts; there is no mechanism to detect scene changes and refresh/retire sinks dynamically.
- Catastrophic forgetting of early content when selection repeatedly deprioritizes older blocks is not quantified; recall of long-past events (e.g., callbacks after 90+ s) is untested.
- Robustness to noisy or conflicting prompts, long instruction chains, and fine-grained attribute constraints (e.g., color/number consistency) is not evaluated.
- Identity preservation under occlusions, large viewpoint changes, and across multiple similar characters is not systematically measured.
- Failure analysis is limited to aggregate scores; no taxonomy of observed artifacts (e.g., temporal popping, geometry drift, texture flicker) or correlation with design choices (e.g., compression rate, selection policy).
Extensions and applications
- Applicability to video editing/continuation, inpainting, or multimodal conditioning (audio, depth, motion cues) is not studied; required adaptations of the three-partition cache are unclear.
- Integration with planning or story-level controllers (e.g., shot graphs, script-based control) to handle scene transitions while preserving long-term coherence remains unexplored.
- Compatibility with real-time interactive generation (user interventions mid-stream, prompt updates) and how to update sinks/mid buffers on-the-fly is an open question.
- Safety, content moderation, and long-horizon drift into unsafe or off-prompt content are not discussed; monitoring/correction mechanisms over minutes-long outputs are missing.
- Environmental/energy costs of long video generation under the proposed pipeline are not reported.
Practical Applications
Overview
Below are actionable, real-world applications that flow directly from the paper’s findings and innovations—especially the three-partition KV-cache, dual-branch compression, dynamic top‑k context selection, and incremental Temporal RoPE adjustment. Each item names likely sectors, the kinds of products/workflows that could emerge, and the key assumptions/dependencies that shape feasibility.
Immediate Applications
- Long-form marketing and ad video generation (industry: media, advertising, SMBs)
- What emerges: 60–120 s text-to-video campaigns, explainers, and product showcases generated on a single high-end GPU; “long-form T2V” SaaS that reduces per-video compute cost via bounded KV cache and compressed mid-history.
- Dependencies/assumptions: Access to a modern datacenter GPU (e.g., H100/H200 or comparable), licensing for a capable base model (e.g., Wan 2.1), prompt engineering and safety filters; 832×480 at 16 FPS may require upscaling for final delivery.
- Previs and storyboarding for film/game production (industry: entertainment, game studios)
- What emerges: Previsualization of multi-minute scenes with consistent subjects and motion dynamics; “streaming previs renderer” that keeps semantic anchors (sink tokens) while compressing history to maintain coherence across long shots.
- Dependencies/assumptions: Creative supervision for style and continuity; integration with existing DCC tools; upscaling or post-processing for 4K pipelines.
- Rapid cutscene and trailer prototyping (industry: game development, software)
- What emerges: Long cutscene drafts with coherent characters and settings; pipeline to iterate narrative beats using bounded-memory T2V to avoid expensive full-sequence retraining/inference.
- Dependencies/assumptions: Model alignment with character/style references; rights for any IP; acceptance of current resolution and frame rate.
- SMB social content and how-to videos (industry: retail, consumer services)
- What emerges: 1–2 minute how-to/product walkthrough videos generated from scripts; templated workflows (script→prompt→generation→light editing) powered by memory-bounded inference that scales on a single GPU.
- Dependencies/assumptions: Brand and compliance reviews; upscaling for platform requirements; predictable style control.
- E-learning clips and lesson explainers (sector: education)
- What emerges: Lesson-length (1–2 min) segments with preserved topic coherence; templated educational content generation with short-training, long-inference generalization.
- Dependencies/assumptions: Pedagogical review; accessibility (captions, alt text); content appropriateness checks.
- Long-form B‑roll and stock sequences (industry: media libraries)
- What emerges: Cohesive, motion-rich B-roll packs (e.g., “city at night,” “forest drone shots”) generated efficiently using the compressed mid-context and dynamic retrieval.
- Dependencies/assumptions: Curated prompts; metadata tagging and provenance; aesthetic QA.
- Cloud inference cost reduction for T2V services (sector: software/cloud)
- What emerges: Lower VRAM/compute footprint per stream via bounded KV cache (~4 GB) and O(1) attention; higher concurrency per GPU for long-video workloads.
- Dependencies/assumptions: Engineering to integrate the three-partition cache and RoPE adjustment in existing inference stacks; profiling for different backbones.
- Research acceleration with short-clip training (sector: academia/industry labs)
- What emerges: Lower data collection/training cost by supervising on 5 s clips while evaluating long-horizon coherence; reproducible long-video benchmarks leveraging VBench-Long.
- Dependencies/assumptions: Comparable base model capacity and tokenization; adherence to the same compression and RoPE schemes for apples-to-apples results.
- General KV‑cache management libraries for video transformers (sector: software tooling)
- What emerges: An SDK implementing three-partition KV caches, dual-branch compression, and incremental temporal RoPE; plug-ins for Diffusers or video DiT stacks.
- Dependencies/assumptions: API compatibility with target backbones; performance tests across model sizes and resolutions.
- Risk management and provenance practices (sector: policy/compliance)
- What emerges: Immediate need for watermarking, content provenance (e.g., C2PA), and long-form deepfake detection tuned to multi-minute outputs that this approach enables.
- Dependencies/assumptions: Organizational policies and regulatory guidance; integration with watermark/detection tools; clear user disclosures.
- Personal content creation (sector: consumer, daily life)
- What emerges: Vacation highlights, storytelling vlogs, or family event videos produced as coherent 1–2 minute clips; basic editors that let users refine subjects and scenes.
- Dependencies/assumptions: Access to consumer-facing interfaces; safety settings to avoid misuse; post-processing for platform formats.
Long-Term Applications
- Real-time or interactive long-video generation (sectors: entertainment, live events, gaming)
- What could emerge: On-the-fly scene extension and user-driven branching narratives in streams or games, using streaming autoregressive blocks and bounded context.
- Dependencies/assumptions: Further speedups (distillation, kernels), stronger latency hiding, and higher resolution support; responsive prompt control.
- On-device or edge long-video synthesis (sectors: mobile, XR)
- What could emerge: Local generation of coherent minute-long scenes for AR/VR storytelling with compressed mid-context; privacy-preserving creative tools.
- Dependencies/assumptions: Heavy model compression/quantization; efficient VAE and conv branches on edge NPUs/GPUs; battery/thermal constraints.
- Long-horizon robot world models and planning (sector: robotics)
- What could emerge: Memory-bounded video predictors that maintain long-term scene state (via sink + compressed mid tokens) for plan simulation and failure prediction.
- Dependencies/assumptions: Training on robotics video/action datasets, action-conditional modeling, safety validation; bridging generative video with control policies.
- Autonomy and simulation-at-scale (sectors: automotive, logistics)
- What could emerge: Long-duration scenario generation for AV/AD testing with consistent actors/traffic flow; scalable simulators leveraging compressed KV caches.
- Dependencies/assumptions: Domain-conditioned prompts; multimodal (sensor) fusion; regulatory acceptance of synthetic data in test suites.
- Long-range, consistent video editing and retargeting (sector: creative software)
- What could emerge: “Edit once, propagate for minutes” tools where global anchors suppress drift and dynamic selection preserves relevant history across edits.
- Dependencies/assumptions: Fine-grained edit controls (masks, keyframes), robust identity preservation, I/O with pro editors; licensing for commercial use.
- Multimodal assistants with persistent session memory (sectors: software, enterprise AI)
- What could emerge: Agents that summarize, generate, and modify long-form video while retaining compact historical context; unified audio–video compression analogs of the three-partition cache.
- Dependencies/assumptions: Cross-modal RoPE/positional schemes; audio/token compression; safety and privacy policies for prolonged sessions.
- Long-video understanding with compressed memory (sectors: media analytics, sports, security)
- What could emerge: Adapt the dual-branch compression and dynamic retrieval to recognition/QA models for efficient long-context analysis (not only generation).
- Dependencies/assumptions: Architectural adaptation to discriminative tasks; training with supervised labels; evaluation on long-video QA/analytics benchmarks.
- Standards and governance for long-form synthetic media (sector: policy)
- What could emerge: Guidelines on length/labeling thresholds, traceable provenance over minutes-long outputs, and audit requirements tailored to memory-efficient T2V.
- Dependencies/assumptions: Multi-stakeholder consensus (platforms, regulators, creators); standardized watermarking/detection protocols.
- Content localization at scale (sectors: media, education, corporate training)
- What could emerge: Automated, minute-long variants of videos per locale (backgrounds, attire, signage) while keeping scene semantics stable through the sink tokens.
- Dependencies/assumptions: Cultural review; prompt libraries per locale; guardrails to avoid stereotyping or sensitive imagery.
- Higher-fidelity, longer-than-2‑minute generation (sectors: media, entertainment)
- What could emerge: TV-length scenes or episodic drafts using hierarchical multi-stage packforcing and improved compression ratios, while preserving coherence.
- Dependencies/assumptions: Model scaling, stronger compression without artifacts, distributed inference; more sophisticated dynamic retrieval.
- Cross-domain token-compression for other media (sectors: audio/music, 3D/NeRFs)
- What could emerge: Generalized mid-context compression and positional realignment for long audio/music generation or 4D scene synthesis to manage memory growth.
- Dependencies/assumptions: Domain-appropriate “dual-branch” designs (e.g., temporal pyramids for audio); adapted RoPE for specific modalities.
Notes on Core Assumptions and Dependencies Across Use Cases
- Compute and hardware: While KV cache is bounded (~4 GB), high-quality long-form generation still assumes a capable GPU (H100/H200-class or equivalent). Consumer-grade deployment needs additional compression/distillation.
- Base model and licensing: Access to a strong video backbone (e.g., Wan 2.1) and a VAE, with appropriate licenses.
- Resolution and speed: Results reported at 832×480, 16 FPS; higher resolutions or real-time interactivity require further optimization.
- Data and training: The paper shows strong extrapolation from 5 s clips; domain-specific applications may still need fine-tuning or curated prompts/datasets.
- Safety and compliance: Longer coherent outputs amplify deepfake and misinformation risks; require watermarking, provenance, content filters, and human oversight.
- Integration complexity: Adopting three-partition KV caches, dual-branch compression, and RoPE adjustments demands engineering effort and careful benchmarking across architectures.
Glossary
- Attention sink: A set of early tokens kept to stabilize attention and preserve global semantics in long-context generation. "Inspired by the attention-sink phenomenon in StreamingLLM"
- Autoregressive video diffusion models: Generative models that produce videos sequentially, conditioning each step on previously generated frames within a diffusion framework. "Autoregressive video diffusion models have demonstrated remarkable progress"
- Causal KV caching: Storing past key and value tensors for causal attention so each new block can attend to historical context efficiently. "We first introduce the background on flow matching and causal KV caching"
- Classifier-free guidance: A conditioning technique that mixes conditional and unconditional model outputs to steer generation strength without a separate classifier. "we utilize a classifier-free guidance scale of $3.0$"
- CLIP score: A text-video alignment metric computed by the CLIP model to measure how well generated frames match the prompt. "with its CLIP score dropping from 33.89 to 27.12"
- Diffusion Transformers (DiTs): Transformer-based architectures tailored for diffusion models, handling spatiotemporal tokens with attention. "Diffusion Transformers (DiTs) have emerged as the dominant architecture"
- Dual-branch compression module: A two-path compressor combining a high-resolution 3D-convolutional branch with a low-resolution VAE re-encoding branch to shrink token counts while preserving semantics. "The dual-branch compression module fuses a High-Resolution (HR) branch (a progressive 4-stage 3D CNN) with a Low-Resolution (LR) branch (pooling followed by VAE re-encoding) via element-wise addition"
- Dual-Resolution Shifting Mechanism: A pipeline that keeps both full-resolution and compressed KV caches, shifting recent tokens into compressed memory without latency. "Dual-Resolution Shifting Mechanism."
- Dynamic Context Selection: A routing strategy that selects only the most relevant compressed mid-history blocks for attention based on importance scoring. "We employ Dynamic Context Selection (Sec.~\ref{sec:participative})"
- Flow Matching: A generative training paradigm that learns a velocity field to transport noise to data, often used instead of standard diffusion. "Our base model builds upon the flow matching framework"
- Heavy-hitter keys: Keys with consistently high attention weights that are prioritized for retention in long-context caching. "selecting heavy-hitter keys based on attention scores"
- Incremental RoPE adjustment: A lightweight correction to cached keys’ rotary position embeddings to maintain temporal continuity after evicting old tokens. "Dual-Resolution Shifting and Incremental RoPE adjustment"
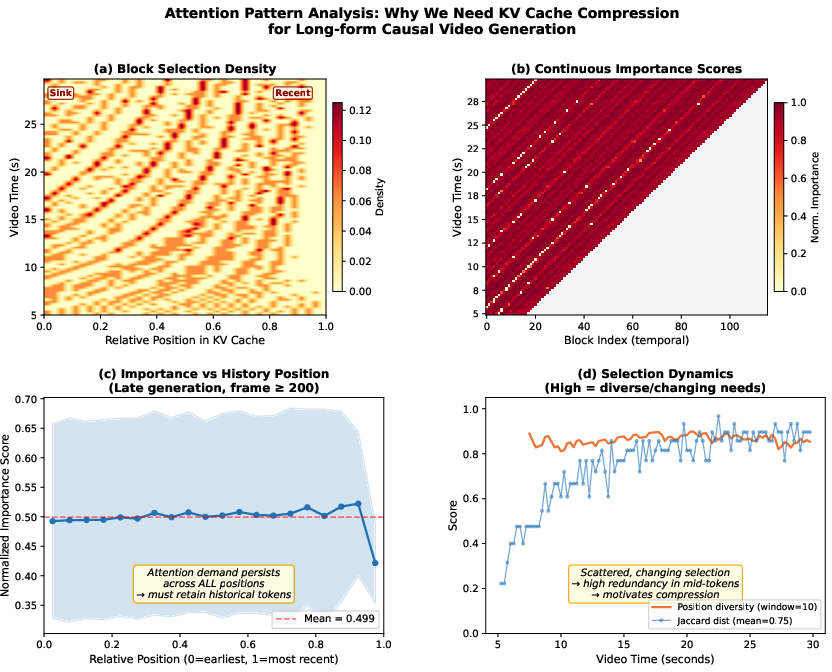
- Jaccard distance: A set-similarity measure used here to quantify diversity between selected historical blocks across steps. "High Jaccard distance ($0.75$) and position diversity () show rapid, diverse block retrieval"
- Key-value (KV) caching: Retaining previously computed key and value tensors so later queries can attend to past information without recomputation. "maintaining historical context via key-value (KV) caching"
- Low-resolution VAE re-encoding: Decoding frames to pixels, pooling them, then re-encoding with a VAE to obtain compact yet semantically rich latents. "fusing progressive 3D convolutions with low-resolution VAE re-encoding"
- O(1) attention complexity: Constant attention computation with respect to total video length by bounding and selectively retrieving context. "ensuring attention complexity without discarding any past memory"
- ODE-based initialization: Initializing an autoregressive student model via trajectories defined by ordinary differential equations for stable generation. "exploring ODE-based initialization"
- Patchification: Converting frames into a grid of patches that become tokens for transformer processing. "After spatial patchification, each block yields tokens"
- Participative compression: A token-reduction approach (from prior work) that keeps informative tokens based on attention while compressing or dropping others. "introduces attention sinks and participative compression"
- Query-key affinity: A relevance score computed from query–key interactions to rank which historical blocks should be attended. "we introduce a dynamic context selection mechanism based on query-key affinity"
- RoPE interpolation: A technique to extend rotary position embeddings to longer contexts by interpolating positional frequencies. "extending context via RoPE interpolation"
- Rotary Position Embeddings (RoPE): Positional encoding that applies complex-valued rotations to queries and keys, capturing relative positions naturally. "Our backbone uses 3D Rotary Position Embeddings (RoPE)"
- Sink tokens: Early “anchor” tokens stored at full resolution to preserve global semantics and prevent drift over long generations. "Sink tokens, which preserve early anchor frames at full resolution to maintain global semantics"
- Spatiotemporal compression: Reducing token counts by jointly compressing spatial and temporal dimensions while retaining critical information. "achieve a massive spatiotemporal compression ( token reduction)"
- Temporal extrapolation: Generating videos far longer than the training duration while maintaining coherence. "enables a remarkable temporal extrapolation ()"
- Temporal RoPE Adjustment: A correction that re-aligns temporal positions in rotary embeddings when tokens are dropped or shifted. "a Temporal RoPE Adjustment is utilized to re-align and enforce continuous positional indices across the historical contexts."
- Three-partition KV cache: A cache split into sink, mid (compressed), and recent tokens to bound memory while preserving long-range context. "a novel three-partition KV-cache strategy"
- Top- selection: Choosing the K most informative items (here, mid tokens) according to an importance score to include in the active context. "we introduce a dynamic top- context selection mechanism"
- VAE latent: The latent-space representation produced by a variational autoencoder, used as the video model’s working space. "The HR branch operates directly on the VAE latent"
- VBench: A benchmark suite and set of metrics for evaluating video generation quality and consistency. "Extensive results on VBench demonstrate state-of-the-art temporal consistency"
Collections
Sign up for free to add this paper to one or more collections.