- The paper demonstrates that ES can match or exceed GRPO in final task accuracy while employing high-dimensional, random-walk parameter updates.
- It quantitatively shows that ES induces significant off-task interference and catastrophic forgetting in continual learning regimes, unlike GRPO’s focused updates.
- The findings reveal that despite distinct update geometries, ES and GRPO converge within a contiguous loss landscape, underscoring the role of geometry in generalization and knowledge preservation.
Matching Accuracy, Distinct Geometry: Comparative Analysis of ES and GRPO in LLM Post-Training
The paper rigorously explores the relationship between solution accuracy and the geometric properties of model parameter updates induced by Evolution Strategies (ES) and Group Relative Policy Optimization (GRPO) when fine-tuning LLMs. The study investigates whether matching or even surpassing accuracy with ES implies similar effects on model generality, catastrophic forgetting, and parameter-space geometry compared to the gradient-based, on-policy RL method GRPO. The research design leverages Qwen3-4B-Instruct-2507 across four tasks—Countdown (arithmetic reasoning), Math, SciKnowEval-Chemistry, and BoolQ—utilizing both single-task and sequential continual learning regimes, with fine-grained monitoring of held-out generalization, weight norm evolution, and KL divergence dynamics.
The results demonstrate that ES, when provided an equal or greater iteration budget, matches or sometimes exceeds GRPO in final task accuracy across all considered tasks. For instance, ES (300 steps) yields 76.5% on Chemistry versus GRPO's 74.9%; similar patterns are observed elsewhere. However, in the continual learning setting, excessive iteration (ES 300) induces pronounced forgetting, with severe degradation on previously acquired tasks, while a conservative step budget (ES 100) preserves knowledge almost to GRPO's competitive baseline.
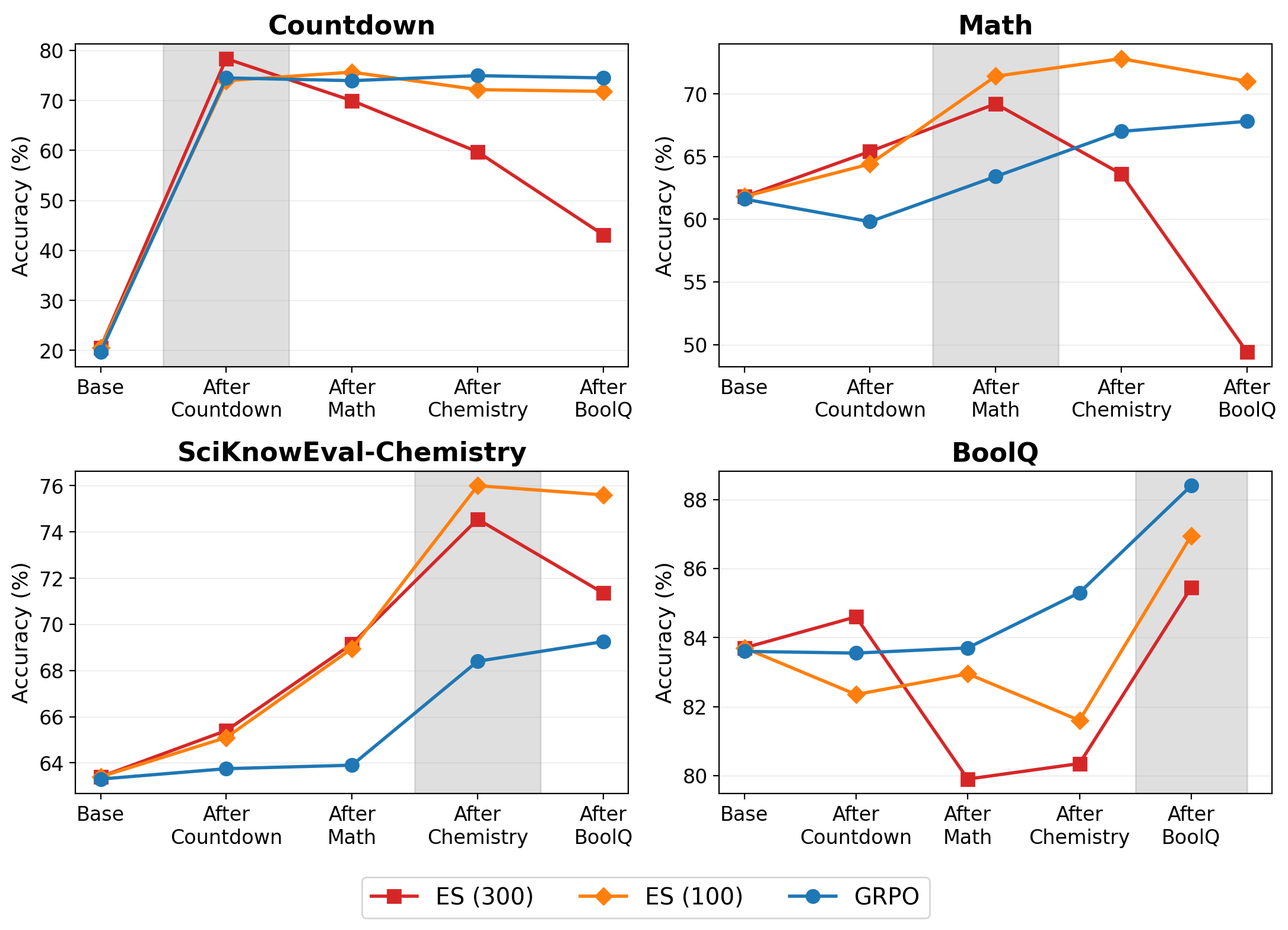
Figure 1: Sequential task accuracy, evidencing pronounced earlier-task forgetting in ES (300), with ES (100) and GRPO maintaining stability.
When evaluating on held-out benchmarks MMLU and IFEval throughout the sequential training, divergent behaviors manifest: ES shows monotonically declining performance on MMLU (−3.7%), but a modest gain on IFEval (+2.2%), whereas GRPO's MMLU accuracy increases (+0.8%) but shows a post-BoolQ drop in IFEval. In all cases, off-manifold generalization is more robust in GRPO, aligning with the result that its parameter updates are sharply concentrated in task-relevant subspaces.
KL Divergence and Inter-Task Interference
A detailed analysis of KL divergence with respect to the base model after each training phase reveals that ES, in the sequential regime, induces substantially broader distributional drift. Non-diagonal (off-task) KLs are markedly elevated for ES relative to GRPO, indicating task interference and generalized drift in response distributions even with matched downstream accuracy. This is consistent with large, isotropic parameter updates, contrasting with GRPO’s localized, high-granularity interventions.
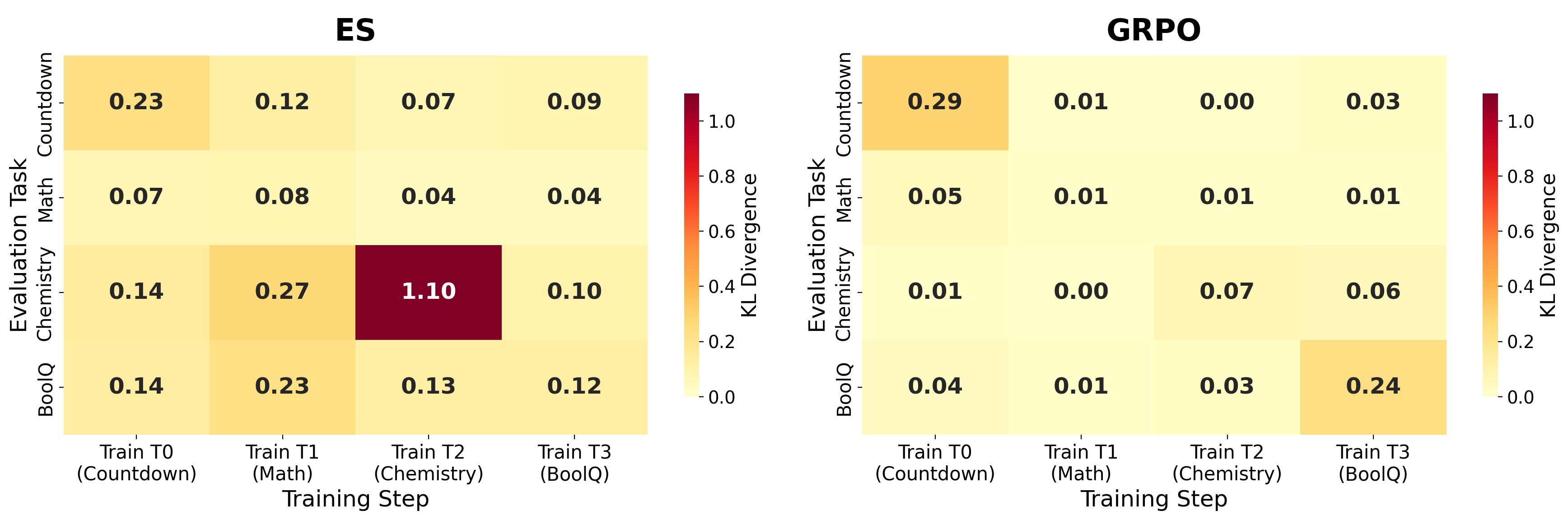
Figure 2: Incremental KL divergence matrix per training step, showing ES's pervasive off-diagonal drift versus the highly localized KL profile of GRPO.
Parameter-Space Geometry and Solution Connectivity
A central finding is that the ℓ2-norm of the ES parameter delta from initialization is two orders of magnitude greater than that of GRPO. For example, after full sequential training, ES reaches ||Δθ|| ≈ 173.0, whereas GRPO remains at ||Δθ|| ≈ 1.84. Despite this dramatic geometric discrepancy, the solutions are linearly connected—model accuracy along the interpolation path between ES and GRPO remains flat or improves, indicating no loss barrier and confirming that both final states reside in a contiguous basin of the loss landscape.
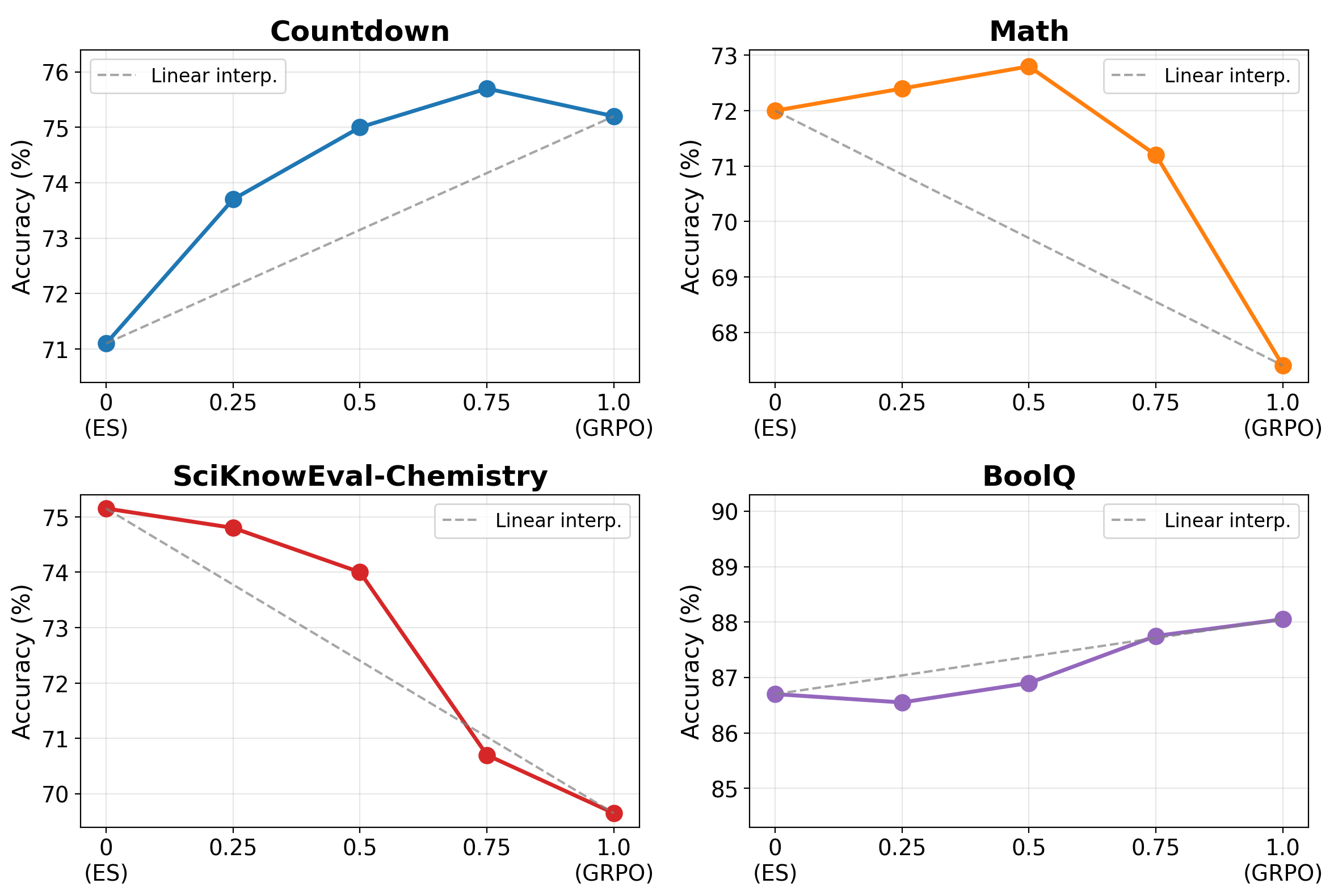
Figure 3: Per-task accuracy along the linear interpolation between ES and GRPO endpoints, illustrating robust mode connectivity and absence of intermediate accuracy collapse.
Probing the loss landscape along the update directions, accuracy rapidly saturates in the GRPO direction but only after small displacement, while ES requires far greater movement to achieve equivalent results, and its direction behaves similarly to random, non-task-aligned perturbations. This holds for both target and holdout tasks.
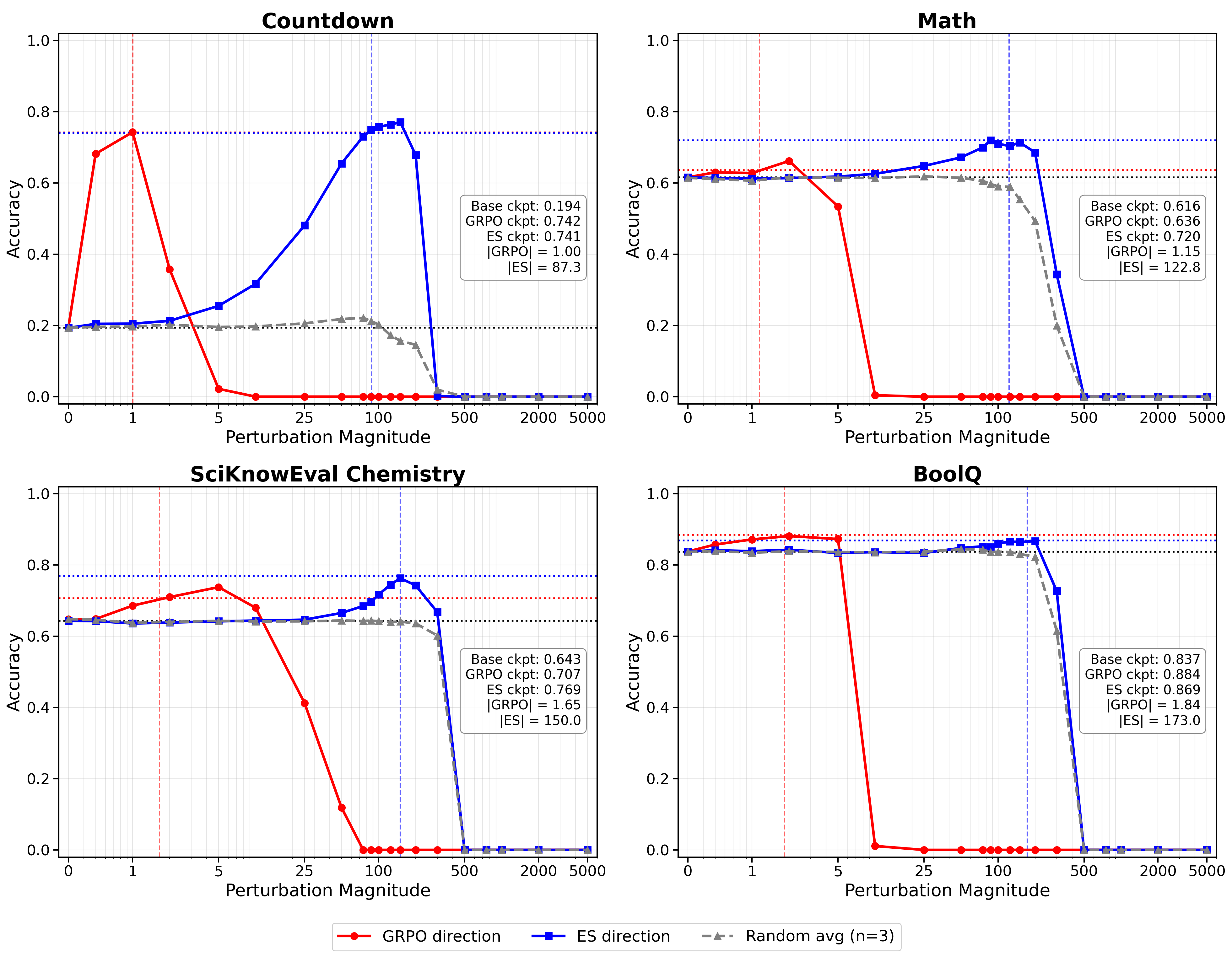
Figure 4: Task accuracy as a function of magnitude along ES, GRPO, and random directions; ES requires much larger displacement to achieve similar accuracy.
Theoretical Synthesis: Signal-Diffusion Decomposition in High Dimensions
The observed phenomena are unified by a rigorous theoretical framework: ES parameter evolution decomposes into an on-manifold gradient-like (signal) component and an off-manifold, loss-invariant (diffusion) component. In the limit of high parameter dimension d and low-rank task structure, the random-walk contribution O(d) dominates, and the expected update norm grows as α2dT/N. This is in stark contrast to GRPO (and noiseless GD), where updates remain within a low-dimensional, task-aligned subspace (O(r) with r≪d). Empirical results validate these predictions: observed parameter drift in ES precisely follows the derived scaling law (R2=0.9943), with nearly all bulk drift assigned to inherently task-irrelevant parameter directions.
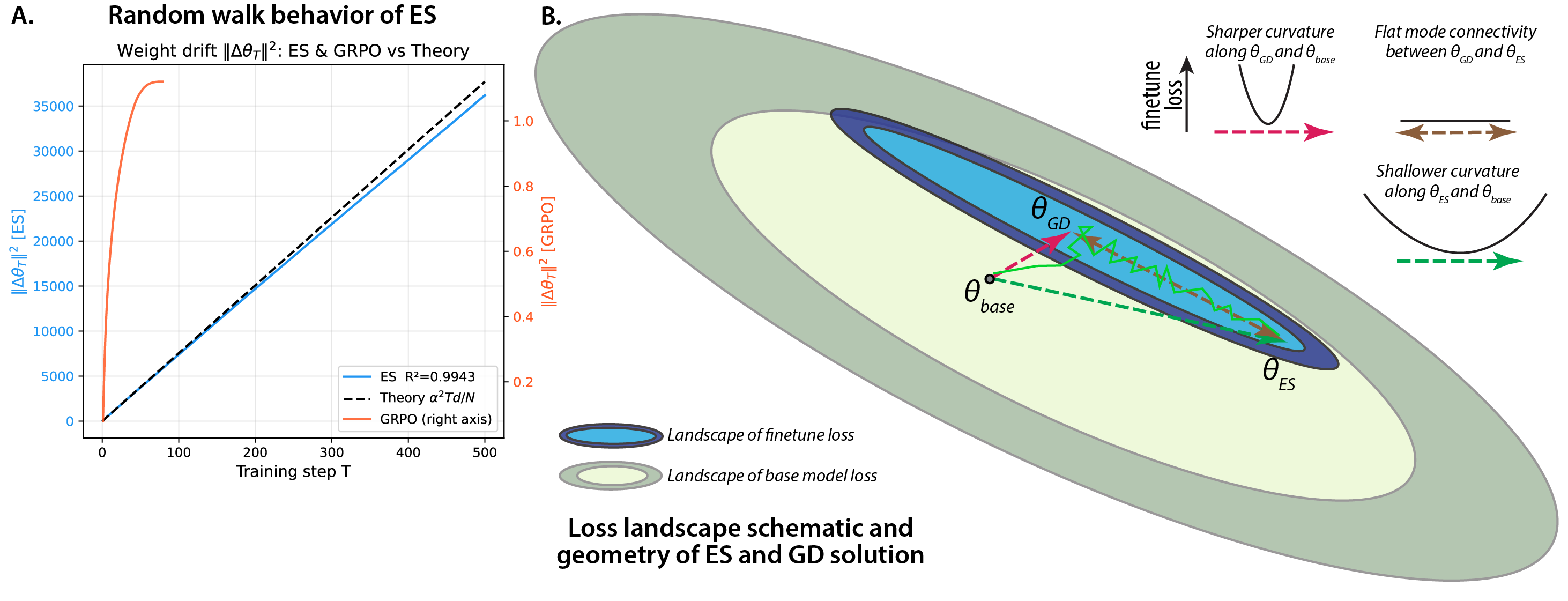
Figure 5: Schematic of the fine-tuning loss landscape, depicting low-dimensional GRPO moves versus ES's diffuse, almost orthogonal, isotropic random walk with substantial off-manifold movement.
Implications and Theoretical Impact
The results establish that, for LLM post-training, gradient-free and gradient-based approaches with matched accuracy can yield solutions with fundamentally different parameter-space geometry and off-task effects. This has several non-trivial implications:
- Forgetting and Transfer: Weight update geometry, rather than accuracy alone, governs trade-offs between knowledge retention and task selectivity. ES’s isotropic drift induces broader off-task interference, explaining catastrophic forgetting absent in GRPO.
- Loss Landscape Structure: The linear mode connectivity and absence of loss barriers between geometrically orthogonal solutions confirms that fine-tuning for most tasks operates on broad, degenerate plateaus—a property generalizing prior findings on lottery ticket and mode connectivity phenomena.
- Scaling Population Size and Step Count: The theory shows that for ES, off-manifold diffusion is suppressed only by increasing the population size N, but for practical N≪d (where ℓ20), most update energy is wasted in task-irrelevant directions.
- Optimizer Selection: In scenarios demanding strong knowledge preservation or minimal task interference (e.g., continual learning, foundation model curation), geometry-aware metrics must be considered in optimizer design and performance benchmarking, not just downstream task accuracy.
Future Directions
The findings motivate investigation into hybrid or regularized ES variants that constrain off-manifold drift, e.g., via model editing, low-rank adaptation, or KL penalties, to harness ES’s parallel efficiency without sacrificing knowledge preservation. Further, they suggest that high-dimensional random walk dynamics may be a general phenomenon in large-scale neural systems and should be integrated as a foundational principle in theoretical analyses of post-training optimizers.
Conclusion
The paper offers a comprehensive, quantitative analysis demonstrating that Evolution Strategies and GRPO can converge to equally performant but geometrically distinct optima in LLM post-training. This divergence is driven by high-dimensional random-walk diffusion intrinsic to gradient-free optimization, as shown theoretically and empirically. The work delineates the criticality of parameter-space geometry for continual learning, transfer, and robustness, thus setting the agenda for geometry-aware optimization and evaluation protocols in future large-scale LLM adaptation.
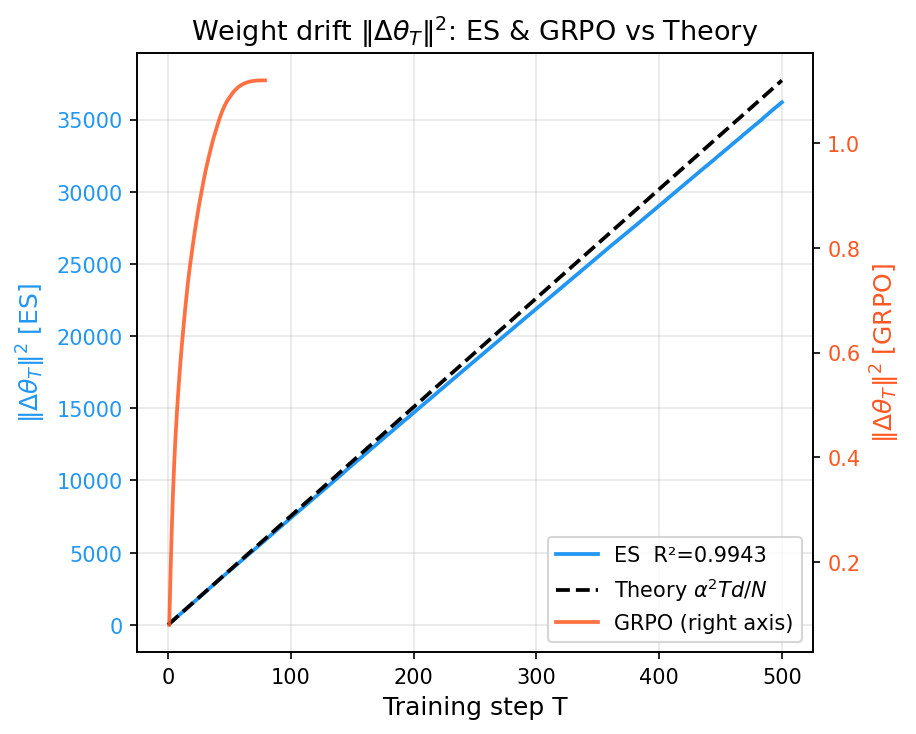
Figure 6: Empirical cumulative weight drift versus theoretical prediction; ES matches random-walk theory with high accuracy, while GRPO's drift is orders of magnitude smaller.

