- The paper introduces a novel process-level critic that actively intervenes to mitigate error propagation in multi-turn agentic reasoning.
- It refines reinforcement learning by rewinding and correcting low-scoring actions, achieving significant performance gains on benchmarks.
- Empirical results demonstrate that proactive process critique improves sample efficiency and surpasses the limits of standard RL exploration.
ProCeedRL: Process Critic with Exploratory Demonstration Reinforcement Learning for LLM Agentic Reasoning
Multi-turn agentic reasoning with LLMs is fundamentally constrained by the structural interplay between cumulative context and environmental stochasticity. In standard RL with verifiable rewards (RLVR), unpredictable or suboptimal agent actions result in noisy or misleading feedback, which, once incorporated into the context, further degrades agent reasoning in subsequent steps. This spiraling dependency generates a vicious cycle: error propagation becomes progressively reinforced, limiting both sample efficiency and the attainable upper bound in exploration. These effects are observed to be most pronounced in weaker models, which demonstrate sharper degradation curves under increased noise (Figure 1).
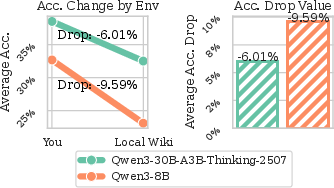
Figure 1: Impact of accumulated contextual noise on multi-turn agentic task performance; compounding noise rapidly reduces model accuracy, particularly for smaller LLMs.
Traditional RLVR frameworks, which typically rely on independent repeated exploration, cannot mitigate this cascade. The inherent outcome-based reward sparsity in multi-turn environments exacerbates credit assignment and pushes agents toward localized optima determined by their initialization and capacity, with environmental feedback amplifying initial reasoning errors. The inability to recover from mid-trajectory derailments renders vanilla RLVR exploration both inefficient and saturating, as demonstrated empirically in search-augmented QA and embodied agent tasks.
ProCeedRL Framework: Active Process Critique and Step-Level Intervention
ProCeedRL introduces a process-level critic-augmented rollout in which exploration is transitioned from a passive, outcome-driven collection model to one with active, in-situ intervention. The critical mechanism is the introduction of a step-wise process critic ϕ that evaluates every action within a trajectory based on its realized effect, providing both a granular score and actionable critique.
Upon detection of an adverse (low-scoring) step, generative reflection is invoked: the agent is rewound to the previous context and the action is refined using a policy μ, typically instantiated by the policy model itself or a stronger external LLM. The trajectory resumes with the refined demonstration, effectively pruning error amplification and providing both on-distribution and off-distribution (refined) exploration signals for subsequent optimization.
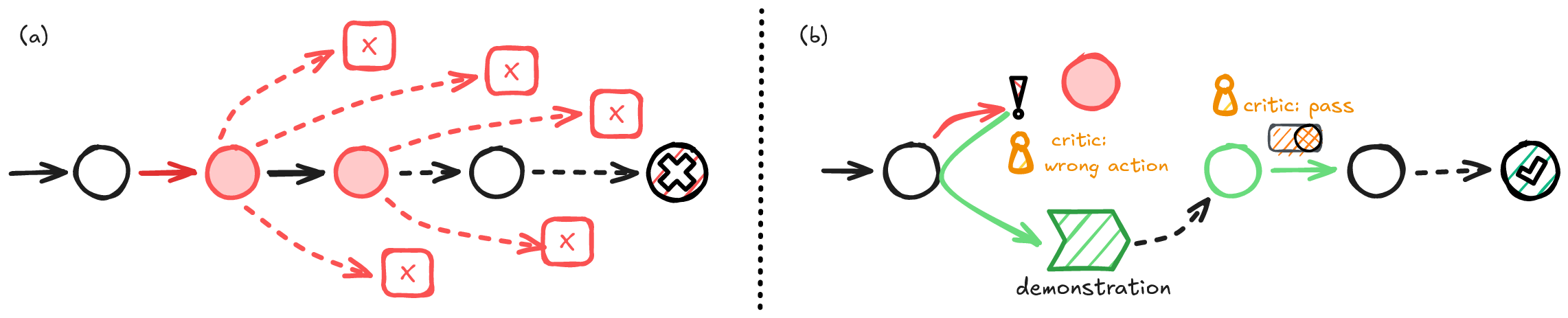
Figure 2: Standard repeated sampling (left) suffers from compounding error; ProCeedRL (right) intercedes with a critic, rewinding and providing intervention to prevent exploration derailment.
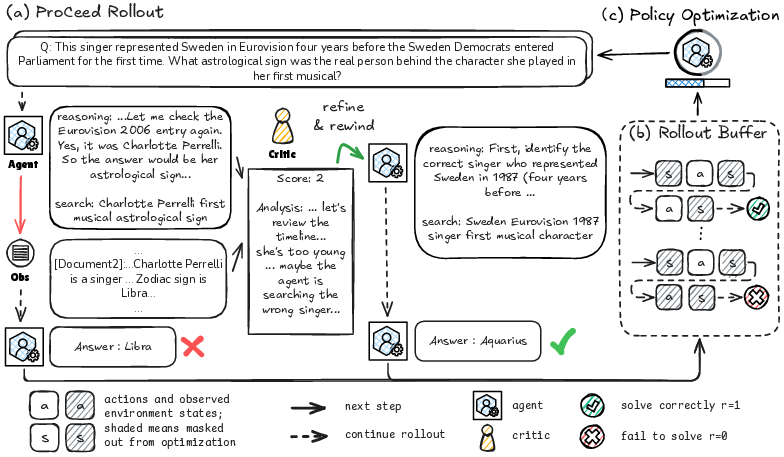
Figure 3: Full workflow example of ProCeedRL, highlighting in-process rewinding and demonstration use for recovery from suboptimal decisions.
Training and Objective Harmonization
Exploration trajectories are collected as mixtures of vanilla on-policy rollouts and critic-refined demonstrations, forming the replay buffer B. Off-policy demonstrations—being conditionally sampled under guidance—are not fully aligned with the evolving policy distribution. To reconcile this, policy optimization applies dynamic weighting schemes, such as chord-ϕ (Zhang et al., 15 Aug 2025), which smooth the loss contribution of demonstration steps as a function of their likelihood under the current policy. This prevents distributional drift and instability, as recently highlighted in analyses of off-policy RL guidance in LLMs (Yan et al., 21 Apr 2025, Zhang et al., 15 Aug 2025). Demonstration steps are often masked out during failed optimization, reflecting their off-policy nature.
The pipeline is model-agnostic with respect to critic and refinement policy choice, enabling scalability without reliance on external evaluators at inference time. Critically, all procedural interventions are internalized during training; no critic or reflector is queried during deployment, confining computational overhead exclusively to training.
Experimental Validation and Numerical Outcomes
Empirical evaluation covers both deep search QA tasks (Bamboogle, MuSiQue, Frames, GAIA, WebwalkerQA) and long-horizon embodied environments (AlfWorld). Comparisons span RLVR baselines (GRPO, DAPO), rejection-finetuning, and recent agentic pipelines. Across all settings, ProCeedRL delivers consistently superior performance, validating its utility for escaping local optima resulting from the feedback loop of error propagation.
On the AlfWorld benchmark, ProCeedRL achieves improvements exceeding 10 absolute points relative to SFT and DAPO baselines. In deep search settings, average gains of up to 3.72% are observed, most significantly on noise-amplified or inherently challenging datasets such as MuSiQue and WebwalkerQA. Notably, ProCeedRL regularly exceeds the upper-bound achievable by vanilla repeated exploration, as evidenced in pass@k scaling curves (Figure 4).
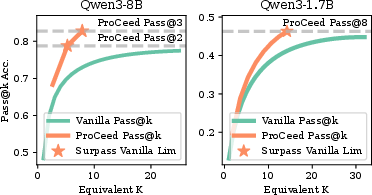
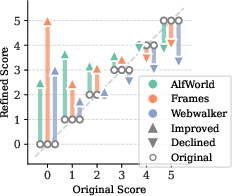
Figure 4: ProCeedRL pass@k versus computation-aligned vanilla rollout; efficiency and ceiling breakthroughs are observed, with ProCeedRL surpassing vanilla limits with fewer generations.
Ablation studies further dissect critic instantiation (self, homogeneous, external), rewind thresholds, and intervention frequency. All critic types—when properly tuned—yield gains, reinforcing the hypothesis that active horizon correction, not oracle guidance, is the key determinant. Excessive or aggressive intervention (high rewind thresholds) exhibits diminishing or negative returns due to over-correction (Figure 5).
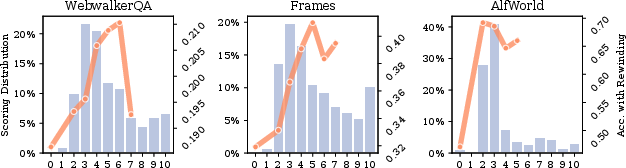
Figure 5: Accuracy and critic score distribution under varying rewind thresholds; optimal intervention point balances correction and step replacement noise.
Analysis of demonstration utility reveals that the largest benefits accrue when correcting low-rated actions; reflection on already optimal actions yields little or may decrease performance, making critic threshold selection for rewinding a parameter that trades off exploration efficacy and compute.
Implications and Future Prospects
ProCeedRL advances the state-of-the-art in RL optimization for agentic LLMs, especially under long-horizon stochastic interaction regimes. The framework provides a general recipe for integrating step-level process critique, on-the-fly demonstration, and critic-weighted objectives, and can be considered orthogonal to concurrent developments in dense process reward modeling (Zhang et al., 13 Jan 2025, Wang et al., 2023) or offline/hybrid RL (Liu et al., 30 May 2025, Zhao et al., 10 Apr 2025).
The results have both practical and theoretical implications. Practically, deploying ProCeedRL-trained agents in operational environments offers robustness to stochasticity, tool integration, and long-range dependencies frequently encountered in real-world applications (e.g., autonomous web navigation, composite planning). Theoretically, ProCeedRL operationalizes a mechanism for breaking exploration bottlenecks intrinsic to vanilla RLVR, suggesting that true agentic competence is a function not solely of reward specification but of strategic recovery policy and process-level critique.
Extensions may include hierarchical or cross-critic architectures to tighten bounds on improvement, more adaptive thresholding, and hybridization with explicit process reward models or prompt-based external reflection at test-time. Addressing asymptotic compute overhead remains a focus; nonetheless, empirical results demonstrate clear justification for the additional training expense through superlinear sample efficiency and solution quality gains.
Conclusion
ProCeedRL systematically addresses the core exploration inefficiencies in multi-turn agentic reasoning for LLMs by introducing a process-level critic and reflection-driven rollback, resulting in significant improvements both in efficiency and absolute performance ceilings on complex multi-step tasks. These findings reinforce the necessity of procedural critique and in situ demonstration for robust, scalable agentic LLMs, establishing a new baseline for RL-driven agent training (2604.02006).

