Scal3R: Scalable Test-Time Training for Large-Scale 3D Reconstruction
Abstract: This paper addresses the task of large-scale 3D scene reconstruction from long video sequences. Recent feed-forward reconstruction models have shown promising results by directly regressing 3D geometry from RGB images without explicit 3D priors or geometric constraints. However, these methods often struggle to maintain reconstruction accuracy and consistency over long sequences due to limited memory capacity and the inability to effectively capture global contextual cues. In contrast, humans can naturally exploit the global understanding of the scene to inform local perception. Motivated by this, we propose a novel neural global context representation that efficiently compresses and retains long-range scene information, enabling the model to leverage extensive contextual cues for enhanced reconstruction accuracy and consistency. The context representation is realized through a set of lightweight neural sub-networks that are rapidly adapted during test time via self-supervised objectives, which substantially increases memory capacity without incurring significant computational overhead. The experiments on multiple large-scale benchmarks, including the KITTI Odometry~\cite{Geiger2012CVPR} and Oxford Spires~\cite{tao2025spires} datasets, demonstrate the effectiveness of our approach in handling ultra-large scenes, achieving leading pose accuracy and state-of-the-art 3D reconstruction accuracy while maintaining efficiency. Code is available at https://zju3dv.github.io/scal3r.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about building big, accurate 3D maps from long phone- or car-like videos (just regular color images, no depth sensor). The authors introduce a method called Scal3R that can handle thousands of frames and reconstruct kilometer‑scale scenes. The key idea is to give the model a smart “memory” so it can remember the big picture of a place while it’s working on smaller parts, leading to more accurate and consistent 3D reconstructions.
What questions did the researchers ask?
- How can we rebuild very large 3D scenes from long videos without the model getting confused or forgetting earlier parts?
- How can we make this work fast and efficiently, even with thousands of images?
- Can we do this using only RGB images (no special sensors), and still get accurate camera paths and 3D shapes?
- How can we help a model “think globally” (see the big picture) while it processes local chunks of the video?
How did they do it?
The starting point: a fast 3D “translator”
The team builds on a strong 3D model (called VGGT) that can take a set of images and directly “translate” them into:
- Where each camera was (its position and direction),
- A depth map for each image (how far things are),
- A 3D point cloud of the scene.
This model is fast and accurate for small-to-medium image sets. But for very long videos, it becomes hard to keep everything consistent because:
- Attention (the part that finds relationships between many image patches) gets very expensive as images multiply.
- Splitting the video into chunks makes it lose the global context (the big-picture structure), so mistakes can build up.
The new idea: a scene “memory” that learns on the fly
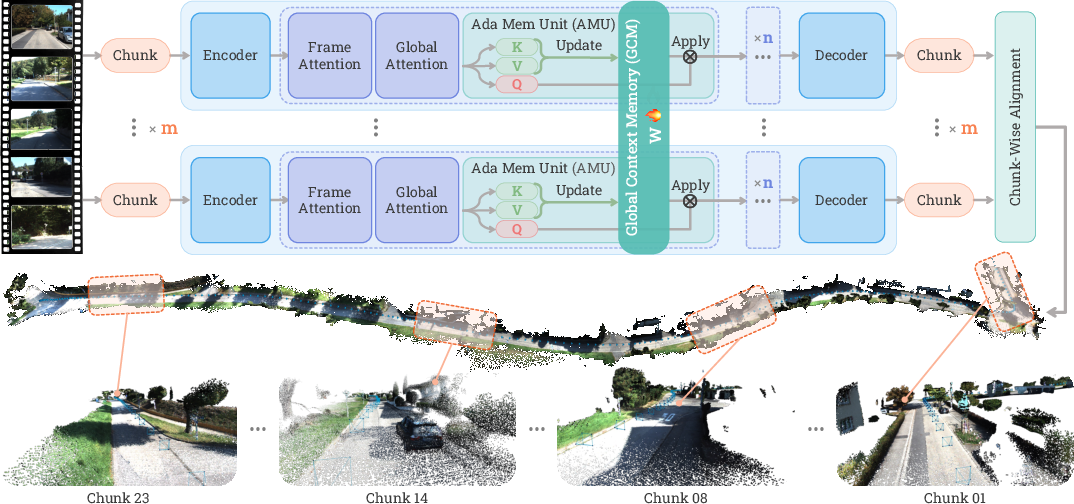
Scal3R adds a new component called Global Context Memory (GCM). Think of it as a shared notebook:
- As the model processes each chunk of the video, it writes helpful notes about the global structure (roads, buildings, layouts).
- This memory is made of small, lightweight neural sub-networks called Adaptive Memory Units (AMUs).
- These AMUs get quickly updated during test time (while the model is running) using self-supervision—no labels needed. It’s like the model teaching itself, using patterns it sees in the images.
Analogy:
- Without memory: It’s like exploring a city block by block without a map; you might miss how the blocks connect.
- With Scal3R’s memory: It’s like adding each block you visit to a shared sketch map, so the next block you visit fits better with the whole city layout.
How the memory updates itself (simple explanation)
- For each chunk of images, the model extracts key patterns (like “sightwords” of the scene).
- The AMUs adjust their internal settings so they can “recognize and recall” these patterns.
- Next time the model sees related image patches, it can use the memory to make better guesses about depth and camera position.
In everyday terms: the memory learns to connect “what I’m seeing now” with “what I saw before” so the model doesn’t drift off or break the scene apart.
Sharing memory across devices: teams syncing their notes
Long videos are split into overlapping chunks and processed in parallel across GPUs (fast computers). To make sure each chunk benefits from what others learned:
- Scal3R uses Global Context Synchronization (GCS). Each GPU updates its local memory from its chunk, then all the updates are combined and shared back to everyone.
- This is like teammates exploring different parts of a city and regularly merging their sketch maps so everyone stays on the same page.
Training and running the system
- Training: The model is trained end-to-end on a wide mix of indoor/outdoor and real/synthetic datasets, so it generalizes well. It uses multi-task learning (predicting camera poses, depth, and 3D points together).
- Inference (running on new videos): The sequence is split into overlapping chunks, processed in parallel while sharing the global memory. Then the results (poses and depth) are aligned and fused into one big 3D reconstruction. Loop closures (when you return to a place you saw earlier) are handled to reduce drift.
What did they find, and why does it matter?
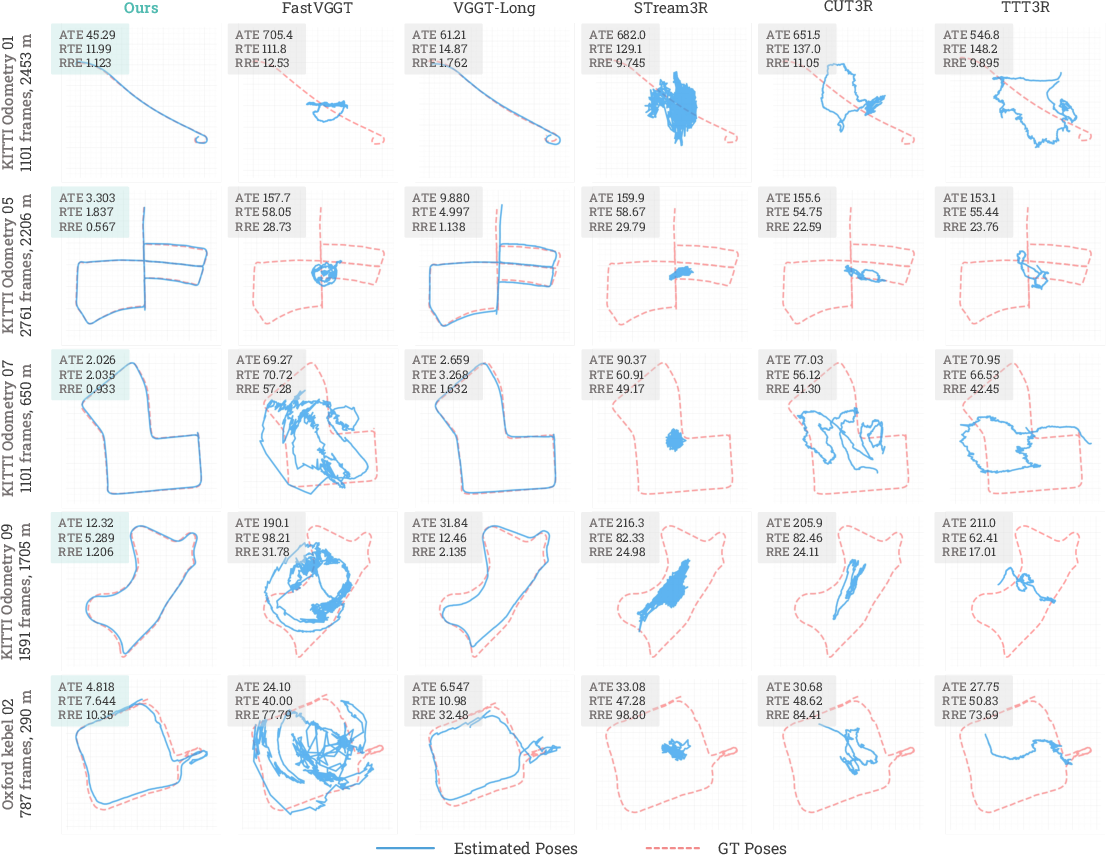
- Higher accuracy on long, challenging sequences: On benchmarks like KITTI Odometry and Oxford Spires, Scal3R achieves lower errors in camera trajectories and better 3D accuracy than strong baselines, including feed‑forward models, streaming methods, and some SLAM/SfM pipelines.
- Scales to kilometer‑scale scenes: It can reconstruct very large areas from long RGB videos with good global consistency, which is hard for many models that either run out of memory or lose track over time.
- Efficient and practical: It remains usable on a single GPU and can go faster with multiple GPUs. It avoids the massive slowdowns seen in traditional systems that depend on heavy optimization or careful feature matching.
Why this matters: In long videos, tiny mistakes add up. Scal3R’s memory helps it keep the big picture straight, so local predictions (per chunk) are better and the final 3D scene is more consistent and accurate.
What’s the potential impact?
- Better maps for robots and self-driving cars: Reliable 3D reconstruction from long videos helps navigation and planning without needing extra sensors like LiDAR or IMUs.
- Digital twins and AR/VR: Building large, accurate 3D models from simple videos makes it easier to create virtual replicas of real places for games, training, or architecture.
- A general recipe for long-context AI: The idea of “test-time training as memory” could help other tasks that suffer from forgetting over long inputs (like long videos, story understanding, or long-term tracking).
In short, Scal3R shows a practical way to give 3D vision models a scalable, shared memory so they can handle very long videos and very large scenes—more like how people keep track of where they are while exploring a big place.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper. Each item identifies a concrete direction for future work.
- Sensitivity to chunking strategy: No ablation of chunk size M, overlap O, or chunk ordering on accuracy, drift, and runtime; robustness under small overlaps or uneven coverage is untested.
- Placement and quantity of GCM modules: Only “4 GCMs” are used; no study of where to insert them, how many to use, or how their depth/placement affects performance and stability.
- Gating mechanism behavior: The learnable gate vector α is introduced but not analyzed; lack of ablations on its magnitude, sparsity, or per-layer behavior and its impact on accuracy vs. stability.
- AMU architecture and capacity: Only compact MLP AMUs with 1–4M “state size” are explored; no comparison to alternative architectures (e.g., low-rank adapters, residual memories, key–value caches, or linear-state-space modules) or to larger/smaller capacities beyond 4M.
- Test-time training (TTT) stability: No analysis of inner-loop hyperparameters (learning rates η_i, update frequency), convergence, or safeguards against overfitting/drift in noisy or ambiguous segments.
- Self-supervised objective design: The dot-product objective lacks negatives or contrastive structure; no exploration of alternative losses (e.g., InfoNCE, reconstruction, geometric consistency) or regularizers to prevent collapse or bias.
- Memory saturation and forgetting: It is unclear how AMUs behave over very long sequences (e.g., >100k frames)—whether capacity saturates, when/if to reset, or how forgetting manifests over hours-long trajectories.
- Synchronization scalability: GCS relies on synchronous all-reduce; communication overhead, scalability vs. GPU count, bandwidth sensitivity, and degradation under limited interconnects are not evaluated.
- Single-device or low-resource inference: While a single-GPU mode is mentioned, there is no quantitative analysis of its speed/accuracy trade-offs, scaling limits, or memory pressure on commodity hardware.
- Real-time deployment: Reported throughput (e.g., ~2.5 FPS) is far from real-time robotics needs; latency breakdown (compute vs. communication) and pathways to real-time operation are not investigated.
- Loop closure and pose-graph details: The retrieval approach, thresholds, false-positive handling, and pose-graph refinement are underspecified; no ablation of its contribution or comparison to standard SLAM loop-closure pipelines.
- Chunk alignment robustness: Sensitivity of cross-chunk Sim(3) alignment to overlap size, gross local errors, or repetitive structures is not analyzed; failure cases for alignment and fallback strategies are absent.
- Global consistency without BA: The method avoids full bundle adjustment; the impact on long-range consistency and drift, and whether lightweight global optimization could further reduce error, remain open.
- Camera intrinsics estimation: Although the model regresses intrinsics, there is no explicit evaluation of intrinsics accuracy, per-frame variability (e.g., zoom), or sensitivity to rolling-shutter distortion.
- Dynamic scene handling: Behavior in the presence of moving objects, crowds, or traffic is not characterized; no mechanisms to detect/discount dynamics in TTT updates or alignment.
- Adverse imaging conditions: Robustness to motion blur, low light, HDR/overexposure, specular/reflective surfaces, and extreme weather/lighting changes is not systematically evaluated.
- Domain shift and bias: Training mixes many datasets (synthetic/real, indoor/outdoor), but there is no systematic study of domain gaps, dataset imbalance, or fairness; generalization to domains unseen in training (e.g., underwater, aerial) remains untested.
- Unordered or sparse view settings: Although training sometimes shuffles images, inference assumes chunked sequences; performance on unordered photo-tourism sets or sparse capture regimes is not evaluated.
- Failure mode characterization: The paper does not report where Scal3R fails (e.g., low parallax, textureless regions, strong repetition, degenerate motion), nor diagnostics to detect or mitigate these cases.
- Alternative memory baselines within the same backbone: No controlled comparison of GCM/TTT against linear attention, explicit feature caches, or memory tokens when plugged into the same VGGT backbone.
- GCS update policy: Only synchronous, fully aggregated gradients are considered; effects of asynchronous updates, stale gradients, or per-chunk weighting on stability and performance are unknown.
- Contribution of each component: Limited ablations (mainly AMU size and with/without global context); missing component-wise studies (e.g., number of GCMs, gate α, loss variants, retrieval/pose-graph) to quantify marginal gains.
- Scale estimation and metric accuracy: Although RTE/RRE/ATE are reported, the stability of metric scale across long sequences and across chunks (pre- and post-alignment) is not explicitly analyzed.
- Map quality beyond point clouds: Only point-cloud Chamfer/F1 are reported; mesh fidelity, surface consistency, texture/appearance coherence, and suitability for downstream tasks (e.g., AR, navigation) remain unassessed.
- Robustness to sensor peculiarities: Rolling-shutter, varying framerates, camera noise models, and lens distortions (beyond what is implicitly learned) are not studied.
- Resource and environmental cost: Training uses 32 A800 GPUs (~3 days); energy consumption, cost-effectiveness, and options for lighter training regimens are not discussed.
- Memory reuse across sessions: AMUs are adapted per sequence; whether and how to persist, compress, or transfer learned scene memory across sessions or revisits is an open question.
- Safety of online updates: There are no safeguards or monitoring for harmful TTT updates (e.g., due to adversarial or out-of-distribution inputs); confidence estimation and rollback strategies are not proposed.
- Retrieval component choice: The visual retrieval backbone and its training are unspecified; comparing different retrieval methods and their effect on loop-closure quality is left open.
- Hyperparameter robustness: No systematic sensitivity analysis for η_i prediction, learning rates, optimizer choices, or gradient clipping thresholds for both backbone and GCM.
These gaps suggest concrete experiments: ablate chunking and module placement; stress-test TTT stability with alternative losses and regularizers; quantify GCS scalability; evaluate intrinsics/rolling-shutter robustness; characterize failure modes; compare memory mechanisms within the same backbone; and assess long-horizon, real-time, and dynamic-scene performance with richer mapping outputs.
Glossary
- Absolute Trajectory Error (ATE): A metric measuring the absolute deviation between an estimated trajectory and ground truth. "We report the Absolute Trajectory Error (ATE), Relative Rotation Error (RRE), and Relative Translation Error (RTE) after Sim(3) alignment with the ground truth."
- Adaptive Memory Units (AMUs): Lightweight neural sub-networks that store and adapt contextual information online as part of a memory module. "adaptive memory parameters are implemented by several Adaptive Memory Units (AMUs), as illustrated in Figure~\ref{fig:pipeline}."
- AdamW: An optimizer that combines Adam with decoupled weight decay for stable training. "We use AdamW optimizer with a peak learning rate of for GCM and for the backbone."
- all-reduce: A distributed operation that aggregates (e.g., sums) tensors across devices and shares the result with all. "This operation is efficiently implemented using the all-reduce primitives of PyTorch~\cite{paszke2019pytorchimperativestylehighperformance}, ensuring minimal communication overhead during both training and inference."
- bundle adjustment (BA): A nonlinear optimization that refines camera poses and 3D structure jointly from observations. "estimate camera poses and 3D structure through feature matching, triangulation, and bundle adjustment (BA)."
- camera intrinsics: Internal camera parameters (e.g., focal length, principal point) required for geometric computations. "they typically rely on known camera intrinsics ~\cite{mur2015orb,gao2018ldso,teed2021droid,teed2023deep,lipson2024deep}"
- Chamfer Distance (CD): A distance measure between two point sets used to evaluate reconstruction quality. "We report Chamfer Distance (CD) and F1 score."
- context aggregation mechanism: A procedure to collect and share global cues across data to improve local predictions. "We therefore design a context aggregation mechanism built on our neural global context that, at test time, coordinates the self-supervised online adaptation of the lightweight sub-networks so that global cues are aggregated and shared across the entire sequence."
- context parallelism: A parallelism strategy that partitions context across devices and synchronizes updates. "as a form of context parallelism~\cite{yang2024context}."
- cosine decay: A learning rate schedule that decays following a cosine function. "The learning rates follow a cosine decay with a 2k-iteration linear warm-up"
- DINOv2: A self-supervised vision transformer used here as an image feature encoder. "a DINOv2~\cite{caron2021emerging} encoder that patchfies and extracts features for each frame"
- differentiable BA: A formulation of bundle adjustment that is differentiable and can be integrated into neural networks. "or solve poses via differentiable BA~\cite{tang2018ba,gu2021dro,wang2024vggsfm}"
- divide-and-conquer strategy: An approach that splits a large problem into smaller chunks processed independently and later merged. "adopts a divide-and-conquer strategy that divides the whole sequence into overlapping chunks"
- dot-product loss: A loss function encouraging alignment via inner products between projected features. "We adopt a standard dot-product loss as the self-supervised objective"
- fast weights: Rapidly updated parameters used as dynamic memory during inference. "Test-Time Training (TTT)~\cite{sun2024learning} introduces fast weights, a set of rapidly adaptable neural parameters that dynamically store contextual information during inference through self-supervised updates~\cite{raina2007self}."
- frame-wise self-attention: Attention computed within each frame to capture intra-frame details. "alternate between frame-wise self-attention (within each image) and global self-attention (across images)."
- Global Context Memory (GCM): A module that stores long-range scene information via adaptable neural units for use during inference. "At the core of our architecture lies a novel neural Global Context Memory (GCM) module"
- Global Context Synchronization (GCS): A mechanism to synchronize and share memory updates across chunks/devices. "we introduce a Global Context Synchronization (GCS) mechanism that enables efficient cross-chunk aggregation and exploitation of global context during both training and inference"
- global self-attention: Attention computed across frames to capture inter-frame consistency. "alternate between frame-wise self-attention (within each image) and global self-attention (across images)."
- gradient clipping: A technique to cap gradient norms and stabilize training. "we apply gradient clipping with a max norm of 1.0."
- IMU: Inertial Measurement Unit; a sensor providing acceleration and rotation data to aid pose estimation. "(\eg, IMU~\cite{qin2018vins,zhang2015visual,qin2018relocalization}, LiDAR~\cite{zhang2014loam,cwian2021large})"
- LiDAR: A laser-based sensor that measures distances to reconstruct 3D structure. "(\eg, IMU~\cite{qin2018vins,zhang2015visual,qin2018relocalization}, LiDAR~\cite{zhang2014loam,cwian2021large})"
- linear-attention: Attention variants with linear complexity in sequence length, enabling longer contexts. "linear-attention~\cite{katharopoulos2020transformers,schmidhuber1992learning} variants such as Mamba~\cite{dao2024transformers,gu2024mamba}, RWKV~\cite{peng2023rwkv}, and DeltaNet~\cite{schlag2021linear,yang2024parallelizing}"
- loop closures: Reobservations of previously seen places used to correct accumulated drift. "with challenging loop closures across indoor and outdoor scenes."
- MLP network: A multi-layer perceptron used here as a compact learnable module within memory. "a compact MLP network serving as the AMUs"
- out-of-memory (OOM) errors: Failures due to exceeding GPU memory capacity during processing. "out-of-memory errors (e.g., FastVGGT~\cite{shen2025fastvggt})."
- pose-graph refinement: Optimization of a graph of poses (and constraints) to reduce drift and improve consistency. "followed by pose-graph refinement to reduce global drift."
- quadratic complexity of the attention: The O(N2) computational cost of standard attention with respect to sequence length. "directly applying VGGT~\cite{wang2025vggt} is infeasible due to the quadratic complexity of the attention~\cite{vaswani2017attention} operation."
- query-key-value projection layer: The projections that map inputs to Q/K/V representations for attention/memory operations. "the GCM module consists of three components: a query-key-value projection layer, a compact MLP network serving as the AMUs, and an output projection layer."
- Relative Pose Error (RPE): A metric assessing relative motion error between consecutive poses. "Runtime scaling with sequence length is further analyzed in the supplementary material, where runtime grows smoothly while Relative Pose Error (RPE) remains stable."
- Relative Rotation Error (RRE): A metric measuring rotational drift per distance traveled. "We report the Absolute Trajectory Error (ATE), Relative Rotation Error (RRE), and Relative Translation Error (RTE) after Sim(3) alignment with the ground truth."
- Relative Translation Error (RTE): A metric measuring translational drift per distance traveled. "We report the Absolute Trajectory Error (ATE), Relative Rotation Error (RRE), and Relative Translation Error (RTE) after Sim(3) alignment with the ground truth."
- self-supervised objective: A loss defined without ground-truth labels, using the data itself as supervision. "We adopt a standard dot-product loss as the self-supervised objective"
- self-supervised updates: On-the-fly parameter updates driven by self-supervised signals during inference. "Test-Time Training (TTT)~\cite{sun2024learning} introduces fast weights, a set of rapidly adaptable neural parameters that dynamically store contextual information during inference through self-supervised updates~\cite{raina2007self}."
- Sim(3) alignment: Similarity transform alignment (scale, rotation, translation) used to compare trajectories or reconstructions. "We report the Absolute Trajectory Error (ATE), Relative Rotation Error (RRE), and Relative Translation Error (RTE) after Sim(3) alignment with the ground truth."
- structure-from-motion (SfM): A pipeline reconstructing 3D structure and camera motion from multiple images. "Classical structure-from-motion (SfM) methods ~\cite{snavely2006photo,agarwal2011building,schonberger2016structure,wilson2014robust,cui2015global,pan2024global}"
- Test-Time Training (TTT): A paradigm that adapts parts of a model at inference to exploit test-time context. "To overcome this limitation, Test-Time Training (TTT)~\cite{sun2024learning} introduces fast weights"
- token-merging technique: A method to reduce token count by merging similar tokens for efficiency. "FastVGGT~\cite{shen2025fastvggt} addresses the computational cost with a token-merging technique~\cite{bolya2023token}"
- Umeyama algorithm: A method for estimating the similarity transform between two point sets. "after aligning them to the ground truth using the Umeyama algorithm~\cite{umeyama2002least}."
- Visual simultaneous localization and mapping (SLAM): Systems that estimate camera trajectory and a map in real time from visual data. "Visual simultaneous localization and mapping (SLAM) methods, in contrast, estimate camera poses and build maps incrementally"
Practical Applications
Immediate Applications
Below are actionable uses that can be deployed now, leveraging the paper’s released code and demonstrated offline, chunked, multi-GPU inference pipeline.
- Autonomous driving and mobile robotics (software, robotics)
- Use case: Offline kilometer-scale mapping and trajectory recovery from dashcam, drone, or robot video to produce poses, depth maps, and dense point clouds without known intrinsics.
- Tools/products/workflows: “RGB-only Fleet Mapper” that ingests fleet video, runs Scal3R in the cloud, and exports aligned poses/point clouds for downstream localization or dataset curation.
- Assumptions/dependencies: Sufficient view overlap; quasi-static scenes; high-throughput compute (multi-GPU for large jobs, single GPU for smaller/longer runtimes); quality RGB video; post-hoc loop-closure and chunk fusion.
- AEC and digital twins (construction, facilities, software)
- Use case: Campus/facility-scale scans from handheld/camera walkthroughs for asset inventories, maintenance planning, and BIM alignment.
- Tools/products/workflows: Plug-ins that convert Scal3R outputs into formats for Autodesk ReCap, Navisworks, Bentley, or Unity/Unreal-based digital twin viewers.
- Assumptions/dependencies: Adequate coverage and overlap; controlled motion to reduce blur; offline processing pipeline.
- Surveying/GIS and urban planning (GIS, public sector)
- Use case: Rapid large-area photogrammetric reconstructions from ground or drone video for street inventories, sidewalk accessibility, curb management, and small-area city planning.
- Tools/products/workflows: “RGB-only Photogrammetry Pipeline” as a QGIS/ArcGIS add-in that aligns Scal3R point clouds with geospatial layers using control points.
- Assumptions/dependencies: Ground control or external alignment for georeferencing; sufficient overlap; compute resources.
- Film, VFX, and game development (media, software)
- Use case: Location scouting reconstruction from consumer/pro camera video to deliver quick, large-area environments for previsualization or set extension.
- Tools/products/workflows: Blender/Unreal importers that convert Scal3R depth/point clouds to meshes or proxies; automatic chunk alignment included.
- Assumptions/dependencies: Offline batch processing; capture quality influences mesh fidelity; additional meshing/cleanup may be required.
- Cultural heritage and archaeology (heritage, education)
- Use case: Fast documentation of large archaeological sites or monuments from walkthrough videos where LiDAR is impractical.
- Tools/products/workflows: “Heritage Scan Kit” that packages capture guidance, Scal3R processing, and web-based viewers for sharing.
- Assumptions/dependencies: Static scenes; careful capture planning for coverage; offline compute.
- Inspection and disaster response (insurance, public safety)
- Use case: Post-event situational awareness from responder bodycams/UAV video to reconstruct areas for rapid triage and claims assessment.
- Tools/products/workflows: “Rapid Response Mapper” that queues uploads, runs Scal3R at reduced resolution for speed, and exports measurements and overlays.
- Assumptions/dependencies: Connectivity to a processing backend; moving objects may require masking; time-to-result depends on GPU availability.
- SLAM bootstrapping and BA warm-start (software, robotics)
- Use case: Use Scal3R poses/depth as an initialization prior for classical SLAM/SfM pipelines (e.g., DPVO, DROID-SLAM, COLMAP) to reduce failure modes in low-texture regions and long trajectories.
- Tools/products/workflows: ROS nodes that run Scal3R offline on logs, then refine with BA; optional real-time use as a prior in replay pipelines.
- Assumptions/dependencies: Integration work; refinement still recommended for highest precision; static or mostly static environments.
- Large-scale dataset curation and benchmarking (academia, ML tooling)
- Use case: Automatic pose/depth annotation for long uncalibrated video datasets, accelerating creation of 3D training corpora.
- Tools/products/workflows: “Scal3R Annotation Service” that produces camera intrinsics/extrinsics and depth for research datasets; QC dashboards for drift detection.
- Assumptions/dependencies: Storage and compute; human-in-the-loop checks for edge cases.
- Memory modules for long-context vision Transformers (software, ML infra)
- Use case: Reuse the Global Context Memory (GCM) and Global Context Synchronization (GCS) modules to enhance long-sequence tasks (e.g., long-horizon tracking, video QA, multi-camera fusion).
- Tools/products/workflows: A “TTT Memory Kit” (AMUs + chunk-wise updates + all-reduce sync) that plugs into Transformer backbones in PyTorch.
- Assumptions/dependencies: Training/inference code integration; availability of self-supervised TTT objectives; distributed compute for GCS.
- Cloud inference at scale (software, cloud)
- Use case: Distributed, chunked processing of very long videos using context parallelism with GCS for consistent global reconstructions.
- Tools/products/workflows: Kubernetes-based microservice that shards sequences across GPUs, all-reduces AMU gradients, and assembles aligned outputs.
- Assumptions/dependencies: Reliable interconnect (e.g., NVLink/InfiniBand) or optimized collective comms; observability for sync bottlenecks.
- Real estate and e-commerce (property tech)
- Use case: Large-property virtual tours and outdoor grounds reconstructions from agent-shot video where LiDAR scans are unavailable.
- Tools/products/workflows: “Tour-to-3D” service producing walkable scenes and measurements; integration with listing platforms and 3D viewers.
- Assumptions/dependencies: Lighting/texture sufficient for geometry; privacy controls for faces/license plates.
- Curriculum and lab exercises (education)
- Use case: Teaching long-context memory, TTT, and large-scale 3D vision concepts via hands-on reconstruction labs.
- Tools/products/workflows: Dockerized labs with provided sample sequences and checklists that highlight chunking, GCM, and GCS behaviors.
- Assumptions/dependencies: GPU access in labs; smaller sequences for classroom runtime constraints.
- Municipal asset inventories (policy, public sector)
- Use case: Low-cost inventories of signage, street furniture, and ADA compliance checks using drive-by video.
- Tools/products/workflows: Pipeline that feeds Scal3R reconstructions into object detectors for asset counts and geotagging.
- Assumptions/dependencies: Appropriate data collection permits; georeferencing; privacy preservation.
Long-Term Applications
These require further research, engineering for real-time/edge constraints, or robustness enhancements (e.g., dynamic scenes, on-device compute).
- Real-time onboard mapping for AVs and AR glasses (automotive, AR/VR, robotics)
- Use case: On-device, continuously updated 3D reconstructions with low-latency TTT updates for navigation and persistent AR.
- Tools/products/workflows: “Onboard Scal3R-lite” using quantization/pruning and incremental AMU updates; fused with IMU/GNSS when available.
- Assumptions/dependencies: Hardware acceleration; further optimization of AMUs and GCS for low latency; handling of dynamics and rolling shutter.
- Multi-robot shared-memory mapping (robotics, networking)
- Use case: Fleet robots exchanging lightweight AMU updates (GCS-style) to converge on shared global context and reduce drift collectively.
- Tools/products/workflows: Communication protocols for gradient/fast-weight sharing; consistency guards; bandwidth-aware synchronization.
- Assumptions/dependencies: Robust comms and security; conflict resolution across heterogeneous sensors; consensus under intermittent connectivity.
- City-scale, continuously updated digital twins (smart cities, energy, utilities)
- Use case: Periodic scans by vehicles/drones updating the urban twin for planning, traffic analysis, and utility asset management.
- Tools/products/workflows: “Digital Twin Updater” that ingests scheduled captures, runs Scal3R in the cloud, performs mesh differencing, and triggers analytics.
- Assumptions/dependencies: Data governance and storage at scale; standardization for change detection; integration with GIS/CAD.
- Dynamic scene modeling with semantics (software, robotics)
- Use case: Joint estimation of geometry, motion, and semantics to handle crowds, traffic, or deformable objects.
- Tools/products/workflows: Scal3R variants incorporating motion segmentation and semantic priors to disentangle static/dynamic components.
- Assumptions/dependencies: Additional training data with dynamics; extended objectives beyond geometric self-supervision.
- Edge and mobile deployment (consumer apps)
- Use case: Smartphone apps that turn hikes, bike rides, or neighborhood walks into 3D maps without cloud compute.
- Tools/products/workflows: Compressed backbones, efficient AMUs, and on-device TTT with optional opportunistic sync to cloud for refinement.
- Assumptions/dependencies: Significant model compression; power/thermal limits; intermittent connectivity.
- Regulatory-compliant mapping for public agencies (policy)
- Use case: Standardized, privacy-preserving workflows for large-scale RGB-only mapping (e.g., automatic face/license-plate anonymization in reconstructions).
- Tools/products/workflows: Auditable pipelines that log consent, redact sensitive content pre-reconstruction, and produce policy-compliant datasets.
- Assumptions/dependencies: Clear legal frameworks; robust anonymization; certification processes.
- Infrastructure inspection at corridor scale (energy, transportation)
- Use case: RGB-only monitoring of powerlines, pipelines, or rail corridors where light-weight payloads are critical.
- Tools/products/workflows: Drone workflows with capture guidance; periodic reconstructions and defect detection overlays.
- Assumptions/dependencies: Handling repetitive textures and vegetation occlusion; georeferencing with control or GNSS constraints.
- Insurance underwriting and risk modeling (finance/insurtech)
- Use case: Automated property risk assessments from user-submitted or drive-by video; flood/roof condition modeling via 3D context.
- Tools/products/workflows: “Video-to-Risk” pipeline integrating Scal3R with risk scoring models; automated QA flags for low-confidence reconstructions.
- Assumptions/dependencies: Data quality variability; bias and fairness reviews; regulatory acceptance.
- Generalized long-context memory in vision-language systems (software, AI R&D)
- Use case: Apply GCM+GCS and chunk-wise TTT to long video QA, multi-camera analytics, or embodied agents with persistent memory.
- Tools/products/workflows: Cross-task “Context Parallelism” libraries that abstract chunking and fast-weight synchronization across modalities.
- Assumptions/dependencies: Task-specific self-supervised losses; scalable distributed inference; stability under very long horizons.
- Privacy-preserving and federated reconstruction (policy, software)
- Use case: Local fast-weight updates on-device with only aggregated updates exchanged to a central server, minimizing raw video sharing.
- Tools/products/workflows: Federated TTT with differential privacy applied to AMU gradients; governance dashboards.
- Assumptions/dependencies: Privacy/utility trade-offs; secure aggregation; convergence guarantees.
Notes on Feasibility and Cross-Cutting Dependencies
- Compute: The demonstrated pipeline benefits from multi-GPU parallelism and high-bandwidth interconnects for all-reduce; single-GPU operation is possible with higher latency.
- Capture conditions: Sufficient image overlap, reasonable lighting, and mostly static scenes increase reliability. Dynamic scenes and severe motion blur remain challenging.
- Calibration: Scal3R estimates intrinsics/extrinsics from RGB only, removing a common deployment barrier but still benefiting from good image quality.
- Integration: For production use, expect additional steps (meshing, georeferencing, QA, semantic labeling) and potential refinement (e.g., BA) depending on accuracy requirements.
- Data governance: For public or commercial deployments, ensure consent, redaction, and compliance with local regulations on imaging and reconstruction.
Collections
Sign up for free to add this paper to one or more collections.