Learning 3D Representations for Spatial Intelligence from Unposed Multi-View Images
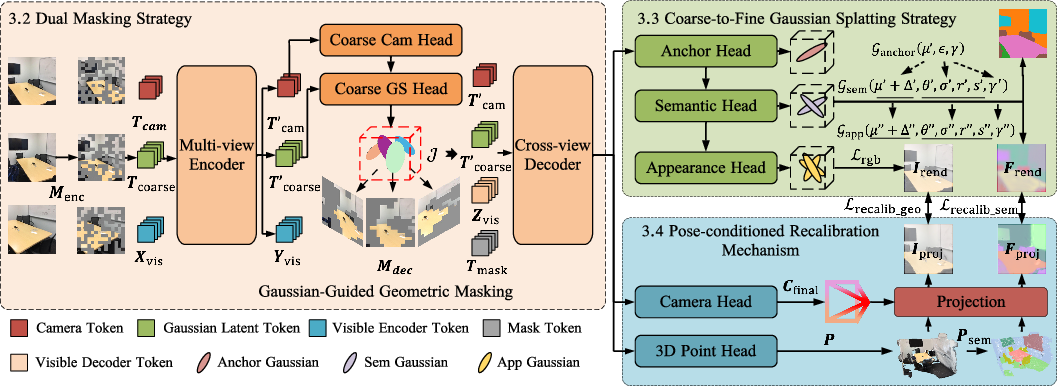
Abstract: Robust 3D representation learning forms the perceptual foundation of spatial intelligence, enabling downstream tasks in scene understanding and embodied AI. However, learning such representations directly from unposed multi-view images remains challenging. Recent self-supervised methods attempt to unify geometry, appearance, and semantics in a feed-forward manner, but they often suffer from weak geometry induction, limited appearance detail, and inconsistencies between geometry and semantics. We introduce UniSplat, a feed-forward framework designed to address these limitations through three complementary components. First, we propose a dual-masking strategy that strengthens geometry induction in the encoder. By masking both encoder and decoder tokens, and targeting decoder masks toward geometry-rich regions, the model is forced to infer structural information from incomplete visual cues, yielding geometry-aware representations even under unposed inputs. Second, we develop a coarse-to-fine Gaussian splatting strategy that reduces appearance-semantics inconsistencies by progressively refining the radiance field. Finally, to enforce geometric-semantic consistency, we introduce a pose-conditioned recalibration mechanism that interrelates the outputs of multiple heads by re-projecting predicted 3D point and semantic maps into the image plane using estimated camera parameters, and aligning them with corresponding RGB and semantic predictions to ensure cross-task consistency, thereby resolving geometry-semantic mismatches. Together, these components yield unified 3D representations that are robust to unposed, sparse-view inputs and generalize across diverse tasks, laying a perceptual foundation for spatial intelligence.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about teaching computers to understand 3D spaces from regular photos taken at different angles, even when we don’t know where the camera was for each photo. The goal is to build a single, strong “3D brain” (a representation) that knows:
- Geometry: the shape and layout of the scene (where things are in 3D)
- Appearance: how things look (colors, textures, lighting)
- Semantics: what things are (their meanings, like “chair” or “table”)
The authors call their method UniSplat. It learns all of this quickly in one pass, without needing special camera setups or hand-made 3D labels. This kind of 3D understanding is a key building block for spatial intelligence—helpful for robots, AR/VR, and scene understanding.
What questions were the researchers asking?
In simple terms, they asked:
- How can we learn a 3D model of the world from a few photos when we don’t know the camera positions?
- How can we make the model pay attention to real 3D structure (not just flat textures)?
- How can we make appearance (how things look) and semantics (what things are) agree with the geometry?
- Can the learned 3D knowledge help with many tasks, like making new views of the scene, estimating depth, recognizing objects, and even controlling robots?
How did they study it? (Methods explained with simple analogies)
Think of building a 3D scene like completing a tricky jigsaw puzzle with pieces from different photos. UniSplat introduces three main tricks to make the puzzle easier and more accurate.
- Dual Masking: learning structure by guessing hidden parts
- Analogy: Imagine studying a picture where some important parts are covered. To fill in the blanks, you must understand the 3D layout, not just copy patterns.
- What they do: They hide (mask) patches twice—once in the “encoder” (the part that reads the images) and again in the “decoder” (the part that rebuilds the scene). The second mask targets structure-heavy areas (edges, shapes). This forces the model to infer the scene’s shape, not just textures.
- Coarse-to-Fine Gaussian Splatting: painting the scene with fuzzy dots
- Analogy: Picture “spraying” lots of tiny, semi-transparent, fuzzy balls of color (called Gaussians) into space to form the scene. First you place big, rough blobs for overall structure, then add more, smaller dots to sharpen the look and details.
- What they do: They first create coarse “anchor” blobs to capture global shape, then expand them into semantic blobs (tied to meanings), and finally refine into fine appearance blobs for high-detail textures. This step-by-step process keeps semantics and appearance aligned with the geometry.
- Pose-Conditioned Recalibration: checking 3D predictions by “projecting” them back onto the photo
- Analogy: Shine a projector through your 3D model back onto the photo. If the projection doesn’t match the real image (in colors and in labeled regions), correct the model until it does.
- What they do: The model estimates camera positions (poses) and a 3D point map. Then it reprojects these 3D predictions into the 2D image and compares them with what the appearance and semantic parts predict. This keeps geometry, appearance, and semantics consistent.
- Training without expensive labels: self-supervision plus “teachers”
- Self-supervised learning: The model teaches itself by trying to reconstruct hidden or new views (like predicting missing puzzle pieces).
- Knowledge distillation: They borrow hints from powerful, frozen “teacher” models:
- A vision-LLM (for open-vocabulary semantics—recognizing many categories).
- A geometry teacher (for camera poses and 3D points).
- This speeds up learning and improves accuracy without needing hand-labeled 3D data.
What did they find, and why does it matter?
- Stronger 3D understanding from few, unposed photos:
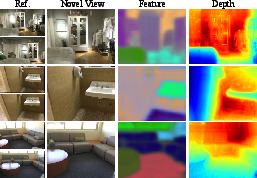
- Better novel view synthesis: The model makes sharper, more accurate new views of the scene from unseen angles.
- Better depth and camera pose: It estimates how far things are and where the camera was more reliably.
- More consistent semantics: Labels like “chair” stay consistent across different views, and they agree with the 3D shape.
- Fast and general:
- Feed-forward: It works in a single shot (no slow per-scene tuning).
- Cross-dataset robustness: Trained on one dataset, it still performs well on very different scenes (indoors/outdoors/objects).
- Helps robots and embodied AI:
- Using UniSplat’s visual features improved success on many robot control benchmarks (like RLBench, LIBERO, Meta-World, and Franka Kitchen). That means the learned 3D “sense” transfers to real tasks like moving, grasping, and following instructions.
Why it matters: These results show UniSplat builds a reliable 3D “common sense” for space that is both detailed and meaningful. This balance is crucial for machines that must see, decide, and act in the real world.
What’s the bigger impact?
- More capable robots: With a unified 3D view that ties together shape, look, and meaning, robots can navigate, pick up objects, and plan actions more safely and efficiently.
- Easier 3D capture: No need for precise camera calibration or costly 3D labels—regular photo collections can be enough.
- Better AR/VR and scene editing: Producing high-quality new views and consistent labels makes virtual experiences more realistic and interactive.
- A step toward spatial intelligence: UniSplat shows how to fuse geometry, appearance, and semantics into one coherent 3D representation—an important foundation for machines to understand and reason about the physical world.
Knowledge Gaps
Below is a single, focused list of knowledge gaps, limitations, and open questions that remain unresolved and could guide future research:
- Reliance on teacher models: The approach depends on 2D semantic distillation from LSeg and geometric distillation from VGGT; the paper does not quantify sensitivity to teacher noise, domain shift, or confidence calibration, nor provide a teacher-free alternative for semantics and geometry.
- Scale and intrinsics recovery: Camera evaluation reports angular AUC but omits absolute translation/scale errors and intrinsics accuracy; it remains unclear how well UniSplat recovers metric scale and camera intrinsics from unposed inputs and under varying lens distortions.
- Sparse-view limits: Although an ablation varies 3–10 views, there is no characterization of minimal view counts, view overlap, or baseline conditions required for stable geometry and semantics, especially in extreme sparse or wide-baseline settings.
- Dynamic/transient scenes: All evaluations use static datasets; the method’s assumptions and robustness under motion (moving objects, non-rigid scenes, transient lighting) are not addressed.
- High-resolution fidelity: Training/inference at 256×256 leaves open how rendering quality, depth accuracy, and semantic coherence scale to higher resolutions and what memory/compute trade-offs arise.
- Computational efficiency and scalability: Training requires 300 epochs on 8×A100 GPUs, but the paper does not analyze training/inference throughput, memory footprints (e.g., number of Gaussians), or performance on commodity hardware.
- Gaussian budget and allocation: The coarse-to-fine scheme uses fixed ratios (e.g., Ns = 10Ng); sensitivity to these choices, adaptive allocation, pruning strategies, and their impact on quality/efficiency remain unexplored.
- Failure modes and robustness: There is no systematic analysis of failure cases (e.g., low-texture regions, reflective/transparent surfaces, severe occlusions, low light), nor strategies to mitigate them.
- Geometry–semantic consistency quantification: The pose-conditioned recalibration is motivated qualitatively; explicit metrics isolating improvements in 2D–3D consistency (beyond task-level scores) and ablations on its stability are missing.
- Uncertainty modeling: While point-map confidence from the teacher is used, the model lacks explicit uncertainty estimates for its own pose, geometry, and semantics; incorporating and evaluating uncertainty-aware training/inference is open.
- Photometric variability: Robustness to exposure changes, color shifts, and photometric calibration across unposed views is not studied; photometric normalization or learned radiometric handling could be needed.
- Open-vocabulary 3D semantics: Evaluation reduces ScanNet labels to 8 categories and aligns to LSeg features; comprehensive open-vocabulary segmentation with text queries, multi-dataset semantics, and zero-shot generalization in 3D is not assessed.
- Embodied AI usage of 3D outputs: Downstream policies use the frozen ViT encoder, not the explicit 3D Gaussian/point predictions; whether explicit 3D representations (e.g., point maps or semantic Gaussians) improve policy learning remains untested.
- Real-world robotics: Embodied evaluations are in simulators; sim-to-real transfer, perception under real sensor noise, latency constraints, and deployment on physical robots are unaddressed.
- Pose estimation stability: The recalibration uses predicted cameras to enforce consistency, potentially creating circular dependencies; training stability, convergence behavior, and initialization requirements are not analyzed.
- Cross-domain generalization breadth: Generalization is shown for indoor→outdoor and object-centric rendering, but not for more diverse environments (e.g., urban driving, industrial scenes) or multimodal inputs (depth, IMU); the benefits/limitations of multi-sensor fusion are open.
- Depth evaluation scope: Depth metrics are reported for source views; target-view depth generalization, geometric completeness (holes), and mesh/occupancy accuracy metrics are absent.
- Masking strategy sensitivity: Dual masking improves performance, but the paper only varies ratios; sensitivity to how “geometry-rich” regions are detected, effects on features in low-importance areas, and potential biases introduced by the importance map are unstudied.
- Degenerate minima and bootstrap risks: The pipeline uses coarse camera/geometry to drive masking and later refinement; conditions under which these early estimates mislead the model and mechanisms to escape degenerate solutions are not investigated.
- Radiance–semantics coupling risks: The coarse-to-fine scheme diffuses appearance from semantics; the impact of semantic errors on appearance quality (semantic leakage) and strategies to decouple or correct misaligned semantics are not evaluated.
- Fairness of comparisons: Some baselines assume known poses or per-scene optimization; the paper does not normalize for these assumptions or include stronger recent pose-free/self-supervised baselines across all tasks for fully controlled comparisons.
- Incremental/online operation: UniSplat is feed-forward but not evaluated for online mapping or incremental updates as new views arrive; extending to streaming inputs with state maintenance is an open direction.
- Robustness to extreme camera intrinsics: How well the model adapts to atypical intrinsics (fisheye lenses, rolling shutter, strong distortion) and whether additional calibration layers are needed is unknown.
Practical Applications
Practical Applications Derived from the Paper
The paper introduces UniSplat, a feed‑forward, self-supervised framework that learns unified 3D geometry–appearance–semantics from unposed, sparse multi‑view images. Its core innovations—dual masking for strong geometry induction, coarse‑to‑fine Gaussian splatting for appearance–semantics fidelity, and pose‑conditioned recalibration for geometric–semantic consistency—enable fast, SfM‑free reconstruction and open‑vocabulary 3D understanding. Below are actionable applications, grouped by deployment horizon.
Immediate Applications
These can be prototyped or deployed now with existing GPUs and pre‑trained models, especially for indoor or moderately controlled environments.
- Pose‑free photogrammetry accelerator (software, AEC, media)
- Use UniSplat to predict camera intrinsics/extrinsics and depth/point maps from unposed photos, then initialize conventional SfM/MVS (e.g., COLMAP) to cut matching/optimization time and improve robustness when SfM is brittle.
- Tools/workflows: “SfM bootstrapper” CLI/SDK; plugin for COLMAP/Meshroom.
- Assumptions/dependencies: multiple views with parallax; mostly static scenes; access to a pretrained UniSplat; GPU for inference.
- Instant room scans from casual photos (AR/VR, real estate, retail)
- Generate view‑consistent 3D radiance fields with semantic layers from short photo sets; export to Gaussian‑splat or mesh formats for staging, walkthroughs, and AR placement.
- Tools/products: mobile scanning SDK; Unity/Unreal importer for semantic 3DGS.
- Assumptions/dependencies: 6–10 diverse viewpoints significantly improve fidelity; performance depends on scene texture and lighting; reflective/transparent surfaces remain challenging.
- Warehouse and retail digital inventory from sparse captures (robotics, logistics)
- Feed-forward 3D reconstruction and open‑vocabulary semantics enable shelf/stock mapping, aisle topology estimation, and “what‑where” queries from handheld or robot images without calibration.
- Tools/workflows: visual inventory pipeline; semantic change detection between capture sessions.
- Assumptions/dependencies: stable lighting, limited occlusion; category coverage tied to VLM teacher; privacy/compliance for workplace imaging.
- Faster robot perception backbone for manipulation and navigation (robotics)
- Replace or augment depth/SLAM modules with UniSplat features and point maps for grasping, obstacle avoidance, and language‑conditioned pick‑and‑place; demonstrated gains on RLBench, Meta‑World, LIBERO, and Franka Kitchen.
- Tools/products: ROS2 node providing depth, pose, semantic features; policy training with frozen UniSplat encoder.
- Assumptions/dependencies: static or quasi‑static scenes during capture; finetuning may be needed for novel sensor domains; real‑time performance depends on GPU.
- Forensic scene reconstruction from heterogeneous cameras (public safety, insurance)
- Reconstruct scenes from unposed CCTV/body‑cam/phone images; estimate relative camera poses; produce consistent 3D for trajectory analysis.
- Tools/workflows: evidence ingestion → UniSplat 3D → trajectory/visibility analysis.
- Assumptions/dependencies: sufficient overlap across views; temporal synchronization not required but helps; chain‑of‑custody and privacy constraints.
- Semantic 3D datasets bootstrapping and label propagation (academia, data ops)
- Use rendered semantic fields and point maps to create pseudo‑labels, propagate 2D tags across views, and reduce manual annotation cost; generate consistent camera and depth pseudo‑GT for training other models.
- Tools/workflows: dataset curation tool that exports depth/pose/semantic maps per frame.
- Assumptions/dependencies: teacher VLM biases transfer; quality varies with domain shift.
- AR occlusion, physics, and spatial anchors without LiDAR (software, mobile AR)
- Use the unified 3D to provide colliders, occluders, and semantic zones (e.g., “place mug on table”) in AR apps from a few photos.
- Tools/products: mobile AR plugin for instant colliders/anchors.
- Assumptions/dependencies: device GPU budget; dynamic scenes degrade stability; scale ambiguity unless anchored to a known measurement.
- Construction progress snapshots and punch‑list generation (AEC)
- From periodic photo sweeps, reconstruct 3D with semantics to detect missing or misplaced assets (doors, fixtures), and generate issues.
- Tools/workflows: photo→3D→semantic diff→PDF/issue tracker.
- Assumptions/dependencies: repeated viewpoints improve comparability; VLM semantic coverage for construction objects may require prompt engineering or adaptation.
- Media and game asset capture without calibration rigs (VFX/games)
- Rapid capture of sets/props into 3DGS with consistent semantics for material masking and relighting; use predicted cameras for matchmove initialization.
- Tools/products: DCC plugins (Blender, Houdini) to import semantic 3DGS and export meshes.
- Assumptions/dependencies: still preferred to perform quick bracketed captures; fine relighting still requires shading proxies.
- Low‑power drone inspection with sparse imagery (industrial inspection)
- Use predicted relative poses and depth from few‑shot captures to create inspectable 3D of rooftops, facades, solar arrays when GNSS/IMU is degraded or camera calibration is unavailable.
- Tools/workflows: flight → photo burst → UniSplat 3D → defect tagging.
- Assumptions/dependencies: sufficient texture; wind‑induced motion may blur; safety/regulatory approval.
Long‑Term Applications
These are feasible with further research, domain adaptation, scaling, or systems engineering (e.g., on‑device acceleration, dynamic scenes, outdoor extremes, or regulatory pathways).
- Real‑time, on‑device spatial AI for AR glasses and mobile (consumer electronics, software)
- Continuous feed‑forward 3D with semantics at interactive frame rates for persistent anchors, occlusion, and language‑grounded interaction.
- Tools/products: Neural coprocessor runtime for UniSplat‑like backbones; SDK for app developers.
- Dependencies: model compression/quantization; hardware acceleration; power budget; robust handling of motion blur and dynamic objects.
- General‑purpose SLAM replacement with unified geometry–semantics (robotics, autonomy)
- A single feed‑forward module producing depth, pose, and open‑vocabulary semantics to drive navigation, mapping, and task planning indoors and outdoors.
- Tools/workflows: SLAM stack with language‑aware maps; lifelong map updates with coarse‑to‑fine refinement.
- Dependencies: outdoor generalization (illumination, scale), loop‑closure equivalents, dynamic scene modeling.
- Consumer‑grade “3D memories” with searchable semantics (consumer apps, media)
- Turn photo albums into explorable 3D scenes where users query “where is the red backpack?” or “show me the best view of the painting.”
- Tools/products: cloud app for 3D albuming; retrieval over semantic radiance fields.
- Dependencies: privacy controls, efficient storage/streaming of 3DGS, robust multi‑device capture workflows.
- Large‑scale city/asset digital twins from crowd‑sourced imagery (policy, urban planning, insurance)
- Aggregate public photos to maintain up‑to‑date, semantically labeled urban twins for planning, accessibility audits, or rapid disaster assessment.
- Tools/workflows: ingestion → quality control → UniSplat‑style reconstruction → governance dashboards.
- Dependencies: data licensing and privacy; bias mitigation; handling severe domain shift (weather/season); scalable distributed reconstruction.
- Medical endoscopy and minimally invasive 3D mapping from monocular videos (healthcare)
- Reconstruct anatomy from uncalibrated endoscopic sequences to aid navigation, lesion localization, or change detection.
- Tools/products: OR viewer with 3D recon and semantic overlays; QA tools for clinical trials.
- Dependencies: domain‑specific training, safety validation, regulatory approvals (FDA/CE), handling specularities/fluids/dynamics.
- Cultural heritage digitization at scale from tourist photos (museums, conservation)
- Robust, pose‑free reconstructions with semantic layers for restoration planning and public dissemination.
- Tools/workflows: heritage pipeline with crowdsourced ingestion, quality gating, and expert review.
- Dependencies: IP and cultural permissions; non‑Lambertian surfaces; extreme lighting.
- Cross‑modal, language‑grounded robot policies in the wild (robotics, home assistance)
- Leverage unified 3D semantics to follow natural language instructions with spatial constraints (“put the bowl inside the top left cabinet”).
- Tools/products: household robot stack with UniSplat‑like backbone; instruction‑following policies.
- Dependencies: robust object permanence in dynamic scenes; continual learning; safety guardrails.
- Autonomous infrastructure monitoring and change detection (energy, transportation)
- Periodic sparse captures of wind turbines, bridges, PV farms, with 3D+semantics for wear detection and compliance reporting.
- Tools/workflows: capture policy optimization; longitudinal 3D diffing; alerting.
- Dependencies: domain adaptation to outdoor extremes; scale normalization; integration with maintenance CMMS systems.
- Privacy‑preserving on‑prem 3D analytics (policy, enterprise IT)
- On‑device/on‑prem inference for facilities monitoring without sending images to cloud; run semantic queries over 3D without storing raw frames.
- Tools/products: edge appliance with accelerated UniSplat inference; secure query interfaces.
- Dependencies: hardware acceleration; governance and audit features; differential privacy for semantics.
- Automated content creation with controllable semantics (media, gaming)
- Generate editable 3D scenes from scripts/prompts by conditioning generative models on UniSplat‑style semantic fields; swap or restyle objects based on labels.
- Tools/workflows: text→semantic layout→3DGS→mesh bake; iterative scene co‑pilot.
- Dependencies: coupling with 3D generative models; semantic consistency guarantees; IP of training data.
Cross‑cutting Assumptions and Dependencies
- Data: needs multi‑view coverage with sufficient parallax; performance improves notably from 6–10 views; static scenes preferred.
- Scale and calibration: absolute scale can be ambiguous without a known reference; reflective/transparent/dynamic content is challenging.
- Models: open‑vocabulary semantics inherit biases from the 2D VLM teacher; domain adaptation may be needed outside indoor benchmarks.
- Compute: current training uses GPUs (e.g., A100s); inference is feed‑forward and fast but still benefits from GPU/NPUs; mobile requires compression.
- Compliance: privacy, safety, and licensing considerations for crowd‑sourced or workplace/medical data.
Glossary
- 3D Gaussian Splatting: An explicit 3D scene representation that uses Gaussian primitives for fast training and rendering. "3D Gaussian Splatting~\citep{kerbl20233d} accelerates training and rendering via explicit primitives"
- Abs Rel: Absolute Relative error; a depth estimation metric measuring relative error between predicted and ground-truth depths. "Depth Estimation (Abs Rel, Inlier Ratio)"
- alpha blending: A compositing technique that accumulates semi-transparent contributions along a ray to form the final pixel value. "via alpha blending:"
- anchor Gaussians: Base Gaussian primitives predicted first, from which denser semantic and appearance Gaussians are derived via learned offsets. "the Anchor Gaussian Head predicts anchor Gaussians"
- AUC: Area Under the Curve; here, an evaluation metric for relative pose estimation across angular thresholds. "relative pose estimation (AUC)"
- bilinear sampling: Differentiable interpolation of pixel values at continuous coordinates using the four nearest pixel neighbors. "values are interpolated via differentiable bilinear sampling"
- coarse-to-fine Gaussian splatting: A progressive rendering strategy that starts with coarse structure and refines to fine appearance details. "a coarse-to-fine Gaussian splatting strategy that reduces appearance-semantics inconsistencies by progressively refining the radiance field."
- cost volumes: Aggregations of per-pixel matching costs across depths/views used to reason about multi-view correspondence. "epipolar constraints, cost volumes, or pose-conditioned embeddings"
- Dense Prediction Transformer (DPT): A transformer architecture tailored for dense outputs such as depth or point maps. "uses a Dense Prediction Transformer (DPT) to regress per-view 3D point maps"
- dual-masking strategy: Masking both encoder and decoder tokens, with decoder masks biased to geometry-rich regions to strengthen structural reasoning. "a dual-masking strategy that strengthens geometry induction in the encoder"
- epipolar constraints: Geometric constraints between corresponding points in two views imposed by camera geometry. "epipolar constraints, cost volumes, or pose-conditioned embeddings"
- extrinsics: Camera parameters (rotation and translation) that map world coordinates to the camera frame. "intrinsics and extrinsics of images."
- feed-forward reconstruction: Predicting scene geometry, appearance, and semantics in a single pass without per-scene optimization. "Supervised feed-forward reconstruction methods infer geometry, appearance, and semantics directly from images"
- Geometric Prior Loss: A loss that transfers geometry knowledge (e.g., poses and point maps) from a teacher model to regularize learning. "Geometric Prior Loss."
- geometry induction: The process by which a model learns or infers 3D structure from 2D observations. "strengthens geometry induction in the encoder"
- Huber loss: A robust regression loss less sensitive to outliers than L2, used here for pose supervision. "Camera parameters are regularized via a Huber loss:"
- Inlier Ratio: The proportion of predictions within a specified error threshold, used as a depth estimation metric. "Depth Estimation (Abs Rel, Inlier Ratio)"
- intrinsics: Camera internal parameters (e.g., focal length, principal point) that define image formation geometry. "intrinsics and extrinsics of images."
- knowledge distillation: Training a model using guidance from a stronger teacher model’s outputs or features. "combines self-supervised learning with knowledge distillation"
- LPIPS: Learned Perceptual Image Patch Similarity; a metric that gauges perceptual similarity between images. "the LPIPS perceptual metric for image quality"
- masked autoencoding: A self-supervised pretext task reconstructing missing regions from partially masked inputs. "masked autoencoding~\citep{he2022masked,bao2022beit,dong2025embodiedmae}"
- multi-head decoder: A decoder with multiple prediction heads (e.g., for pose, points, semantics, appearance) sharing features but outputting different modalities. "a transformer encoder and a multi-head decoder"
- Neural Radiance Fields (NeRFs): Implicit neural representations that map 3D coordinates and viewing directions to radiance and density for view synthesis. "Neural Radiance Fields (NeRFs)\citep{mildenhall2021nerf}"
- novel-view synthesis: Rendering previously unseen views from learned 3D scene representations. "achieve high-fidelity novel-view synthesis"
- Open-Vocabulary 3D Segmentation: Segmenting scenes with labels not restricted to a fixed training set, typically leveraging language supervision. "Open-Vocabulary 3D Segmentation."
- Photometric Reconstruction Loss: A loss encouraging rendered images to match input views using pixel-wise and perceptual terms. "Photometric Reconstruction Loss ensures that the rendered appearance"
- pose-conditioned recalibration mechanism: A consistency module that reprojects predicted 3D outputs using estimated camera poses to align with 2D predictions. "a pose-conditioned recalibration mechanism"
- radiance field: A function describing color and density throughout 3D space, used to synthesize images from arbitrary viewpoints. "refining the radiance field."
- relative pose estimation: Inferring the rotation and translation between cameras from image inputs. "relative pose estimation (AUC)"
- reprojection loss: A loss comparing rendered images with reprojected predictions under estimated poses to enforce geometric consistency. "pose-conditioned reprojection loss:"
- semantic Gaussians: Gaussian primitives carrying semantic features, used to rasterize semantic maps consistently across views. "expands each anchor into semantic Gaussians"
- semantic scene fields: 3D fields encoding semantic information in addition to geometry/appearance for scene understanding. "semantic scene fields~\citep{zhi2021place,peng2021animatable,fan2024large,li2025semanticsplat} advance 3D semantic understanding"
- Structure-from-Motion (SfM): A pipeline that recovers camera poses and sparse 3D structure from multiple images. "Structure-from-Motion (SfM) preprocessing"
- transformer encoder: The self-attention-based component that encodes tokenized inputs into latent features. "a transformer encoder and a multi-head decoder"
- view-invariant features: Features that remain stable under viewpoint changes, aiding correspondence across views. "contrastive learning encouraged view-invariant features"
- vision-LLM (VLM): A model trained to align visual and textual representations, often used for open-vocabulary semantics. "a frozen 2D visionâLLM (VLM)"
Collections
Sign up for free to add this paper to one or more collections.