Addressing Performance Saturation for LLM RL via Precise Entropy Curve Control
Abstract: Reinforcement learning (RL) has unlocked complex reasoning abilities in LLMs. However, most RL algorithms suffer from performance saturation, preventing further gains as RL training scales. This problem can be characterized by the collapse of entropy, a key diagnostic for exploration in RL. Existing attempts have tried to prevent entropy collapse through regularization or clipping, but their resulting entropy curves often exhibit instability in the long term, which hinders performance gains. In this paper, we introduce Entrocraft, a simple rejection-sampling approach that realizes any user-customized entropy schedule by biasing the advantage distributions. Entrocraft requires no objective regularization and is advantage-estimator-agnostic. Theoretically, we relate per-step entropy change to the advantage distribution under minimal assumptions, which explains the behavior of existing RL and entropy-preserving methods. Entrocraft also enables a systematic study of entropy schedules, where we find that linear annealing, which starts high and decays to a slightly lower target, performs best. Empirically, Entrocraft addresses performance saturation, significantly improving generalization, output diversity, and long-term training. It enables a 4B model to outperform an 8B baseline, sustains improvement for up to 4x longer before plateauing, and raises pass@K by 50% over the baseline.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
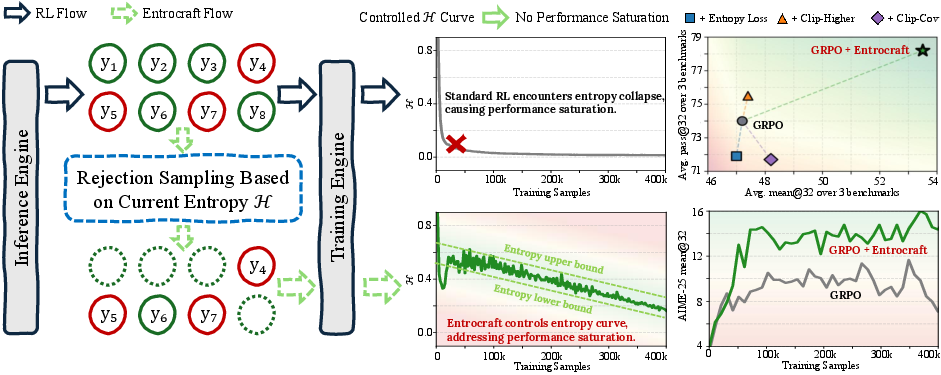
This paper is about teaching LLMs to reason better using reinforcement learning (RL) without getting “stuck.” The authors noticed that when you train LLMs with RL for a long time, performance often stops improving (it “saturates”). They trace this to a drop in “entropy,” which you can think of as how varied and open-minded the model’s answers are. Their new method, called Entrocraft, keeps that variety at healthy levels throughout training, so the model keeps exploring good ideas instead of locking into a few habits too early.
What questions the researchers asked
The paper focuses on a few simple questions:
- Why do RL-trained LLMs stop improving after a while?
- How exactly does a model’s “entropy” (variety of choices) change during RL?
- Can we precisely control that entropy over time, like using a thermostat for temperature?
- Which “entropy schedule” (a plan for how much variety we want at each point in training) works best?
How they approached the problem
To make this understandable, let’s define a few ideas in everyday terms:
- Reinforcement learning (RL): The model tries answers, gets feedback (rewards), and changes to do better next time—like a student practicing with a coach.
- Entropy: A measure of how spread out the model’s guesses are. High entropy = the model explores many options; low entropy = it sticks to a few. Think of entropy like the “adventurousness” of the model.
- Advantage: A score of how much better a particular answer is compared to average. Positive advantage = better than usual; negative advantage = worse than usual.
- Rollouts: Sampled attempts or answers the model generates during training.
- Rejection sampling: A simple filter that keeps some attempts and discards others based on a rule—like a bouncer letting in only people who fit a dress code.
Key insight from their theory
The authors analyze how each training step changes entropy and show, in simple terms:
- Using more positively scored answers usually lowers entropy (the model becomes more sure of a few paths).
- Using more negatively scored answers usually raises entropy (the model stays open to more paths).
- If the model is very confident in an answer, that effect is even stronger.
This explains why RL often “collapses” into a narrow set of answers over time: as the model improves, it sees more positive samples and becomes even less exploratory.
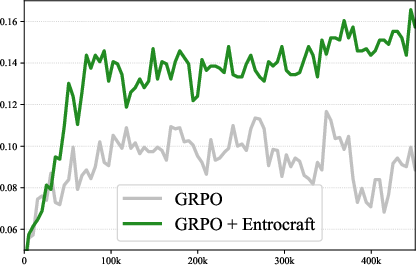
Entrocraft: a smart “entropy controller”
Instead of changing the RL loss or adding extra penalties, Entrocraft adds one simple piece to the training pipeline: a rejection-sampling filter guided by entropy.
- If entropy is too low (the model is too narrow), Entrocraft prefers to keep more negative/low-advantage rollouts and filters out many highly positive ones. This nudges entropy upward so the model explores more.
- If entropy is too high (too random), it keeps more positive rollouts and filters out many negative ones. This nudges entropy downward so the model stays focused.
- The method is “algorithm-agnostic,” meaning it can plug into many RL methods without redesigning the math.
- Because it directly filters which examples affect learning, entropy moves to the target quickly and stays there.
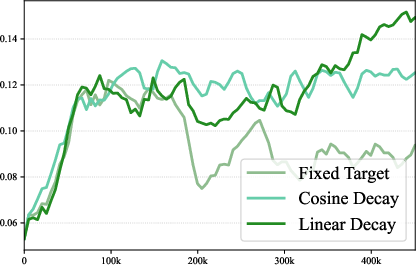
Crafting “entropy schedules,” like a training plan
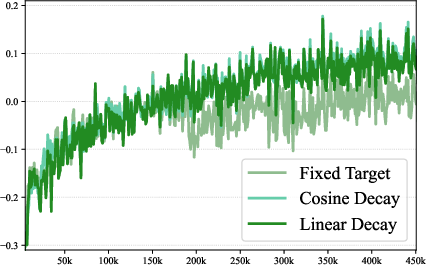
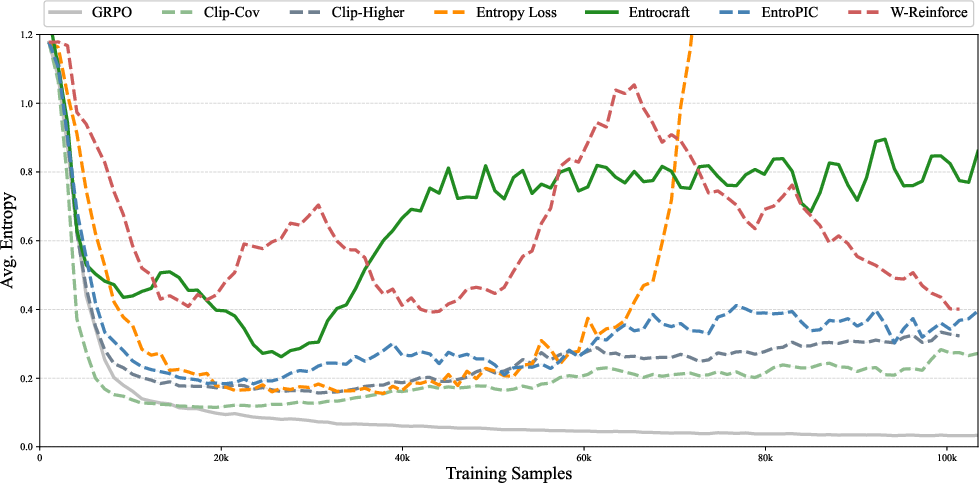
With Entrocraft, you can set a desired “entropy curve” over training—like a schedule for how exploratory the model should be at each stage. The authors tried different plans and found that a simple linear annealing schedule worked best: start with higher entropy (explore a lot), then gradually decrease to a slightly lower level (focus more) as training goes on.
What they found and why it matters
The results show that precisely controlling entropy helps the model keep improving longer and generalize better:
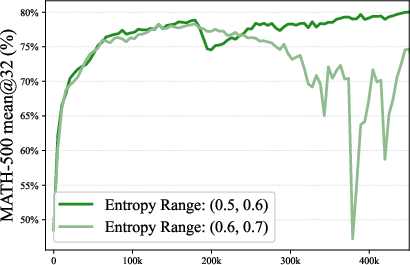
- Prevents performance saturation: The model keeps improving for up to 4× longer before plateauing.
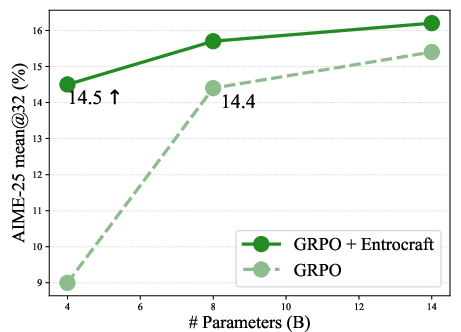
- Better generalization: A 4-billion-parameter model trained with Entrocraft beats an 8-billion-parameter baseline trained in the standard way.
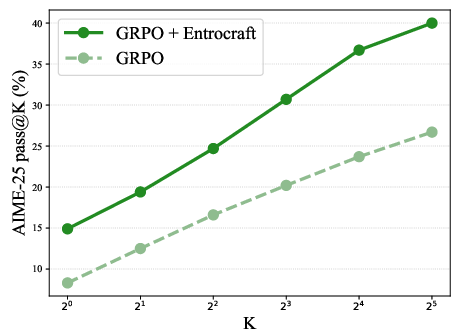
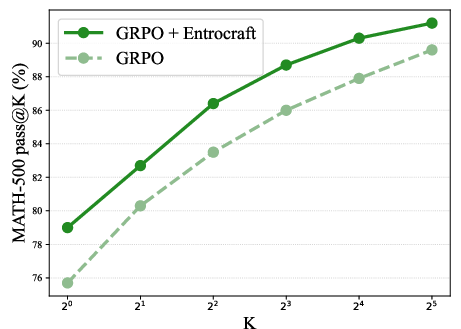
- More diverse outputs: The chance that at least one of multiple attempts is correct (often reported as “pass@K”) went up by about 50%. In plain terms, if you let the model try, say, 32 different answers to a question, you’re much more likely to get a correct one.
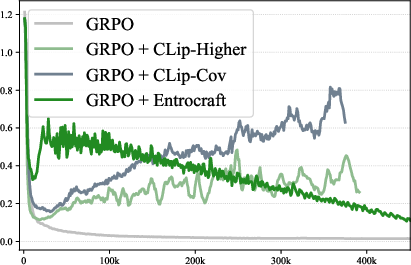
- Stable training: Entrocraft avoids the “entropy collapse” (too narrow) and the “entropy explosion” (too random) that make training unstable.
Why this research is important
- It tackles a major training bottleneck: models stopping improvement even when you add more data and compute.
- It keeps small models competitive: with better training, smaller models can sometimes beat larger ones, which saves resources.
- It’s practical and easy to use: Entrocraft is a simple add-on that works with many RL methods; no complicated new loss functions are required.
- It opens a new lever for training: being able to “program” the model’s exploration level over time—just like tuning a learning rate—gives researchers and engineers a powerful, intuitive control.
In short, the paper shows that controlling entropy precisely during RL can keep LLMs learning longer, exploring smarter, and performing better—especially on tough reasoning tasks like math.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, phrased to guide future research:
- Theory assumes a small learning rate and ignores PPO-style clipping and importance sampling in derivations; extend analysis to realistic clipped/importance-weighted updates and quantify deviations.
- Sequence-level theorem assumes “all tokens share the same outcome reward,” which is unrealistic under token-level credit assignment; generalize proofs to shaped/tokenwise advantages.
- Results establish the sign of entropy change but not tight bounds on its magnitude or its accumulation over multiple updates; derive quantitative bounds and convergence guarantees.
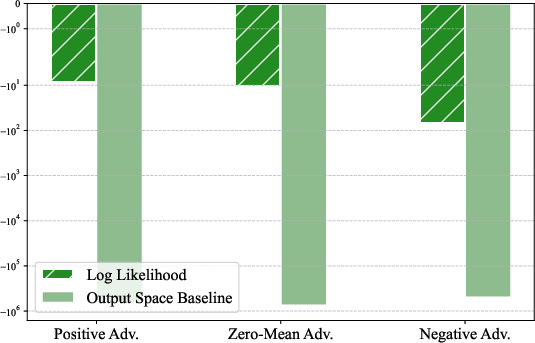
- The “output space baseline” condition is empirically verified on one setup; characterize when this condition holds (or fails) across tasks, model sizes, vocabularies, and temperatures.
- Entropy is computed from the learner policy but rollouts come from a sampler checkpoint; analyze the bias this induces and whether on-/off-policy gaps affect guarantees.
- No formal analysis of the optimization bias introduced by rejection sampling (selecting rollouts by advantage sign); characterize bias, fixed points, and stability of the resulting learning dynamics.
- Gradient variance under rejection sampling is not measured; quantify how acceptance filtering changes variance and sample complexity, and design variance-reduction strategies.
- Compute/sample-efficiency impact is not reported; measure wall-clock, token throughput, and effective sample size versus baselines, and explore weighting alternatives that avoid discarding rollouts.
- Sensitivity to noisy or miscalibrated advantage estimates is unstudied; assess robustness when advantage signs are wrong and explore uncertainty-aware acceptance or calibration methods.
- Hyperparameter γ (acceptance sharpness) lacks ablations; study sensitivity, schedule γ over training, or learn γ adaptively to stabilize acceptance rates.
- Choice and scaling of (h_low, h_high) and the target trajectory are heuristic; develop automatic target-setting controllers (e.g., PI/PID, bandit/Bayesian optimization) tied to reward/entropy feedback.
- Controller uses batch-averaged entropy; investigate per-prompt, per-state, or per-token entropy control to mitigate averaging artifacts and tailor exploration to instance difficulty.
- Annealing result (linear best) is empirical on math tasks; test across tasks and provide theoretical rationale for when linear vs cosine or other schedules are optimal.
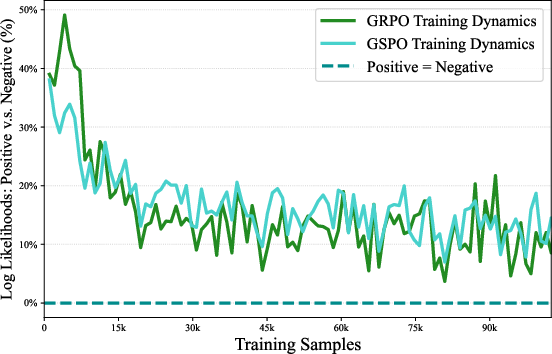
- Failure mode with scarcity of negative-advantage samples is noted; design mechanisms (e.g., targeted data collection, synthetic negatives, debiasing rewards) to maintain balanced polarity late in training.
- Interaction with KL-to-reference penalties common in RLHF is not analyzed; study how entropy control and KL terms trade off and whether targets need KL-aware adjustment.
- Compatibility with preference-based objectives (DPO/IPO/ORPO) and critic-based actor-critic variants is untested; adapt/reformulate Entrocraft for these settings and evaluate.
- Generalization beyond math reasoning remains open; evaluate on code generation, multi-step planning, instruction following, safety-critical dialogue, and multilingual/multimodal tasks.
- Scaling behavior on larger models (e.g., 30B–70B+) and across architectures is unreported; assess stability, throughput, and gains at scale.
- Safety and alignment implications of increased exploration are not measured; track toxicity, jailbreak rates, hallucination, and factuality under different entropy schedules.
- Output length and verbosity effects are unexamined; analyze whether entropy control changes length distributions and confounds metrics (e.g., pass@K, mean@K).
- Decoding-time robustness is unclear; evaluate performance sensitivity to test-time temperatures, nucleus/top-k settings, and determinism after training with entropy control.
- Diversity-quality trade-offs are only partially assessed via pass@K; include calibration (Brier/NLL), coverage, distinct-n, and reward-calibrated diversity metrics.
- Dataset breadth is limited (Numina-Math for training; MATH-500/AMC/AIME for eval); test cross-dataset transfer, OOD generalization, and curriculum or non-stationary data regimes.
- Fairness of baseline tuning is uncertain; provide hyperparameter sweeps, seed variability, confidence intervals, and rigorous significance tests for all methods.
- Practical deployment questions remain: how to maintain target entropy in continual learning, multi-turn conversations, or streaming data where distribution shifts over time.
- Theoretical treatment is single-step; extend to multi-step closed-loop dynamics, including how controller lag and nonstationarity affect stability and long-horizon performance.
- Explore alternatives to hard rejection (e.g., soft weighting by calibrated advantage/uncertainty) to improve sample efficiency while retaining precise entropy control.
- Provide principled guidance for choosing initial/terminal entropy targets across vocabularies and tasks (normalize entropy by log|V| or use temperature-equivalent targets).
Practical Applications
Summary
The paper introduces Entrocraft, a plug‑and‑play, entropy‑guided rejection sampling method for reinforcement learning (RL) with LLMs. It precisely controls the “entropy curve” during RL (including annealed schedules like linear decay), preventing entropy collapse and the resulting performance saturation. Entrocraft is objective‑agnostic and integrates with policy‑gradient methods (e.g., GRPO/GSPO/PPO). Empirically, it improves generalization, output diversity (higher pass@K), and sustains longer training with smaller models exceeding larger baselines.
Below are actionable, real‑world applications categorized by immediacy, with sectors, potential products/workflows, and feasibility notes.
Immediate Applications
These can be deployed now with existing RLHF/RLAIF pipelines and tooling.
- Software (code generation)
- Application: Improve pass@K and inference-time scaling for coding assistants by training with entropy-curved RL to avoid premature mode collapse, yielding more diverse, correct code candidates.
- Tools/products/workflows: “Entropy Scheduler” module for TRL/VerL/DeepSpeed-Chat pipelines; pass@K monitoring dashboards; YAML-configurable entropy targets/annealing; CI workflows that auto‑tune schedules per repository domain.
- Assumptions/dependencies: Reliable reward model or verifiable tests; availability of multi-sample rollouts per prompt; stable advantage estimates; compute to support rejection sampling without starving batches.
- Customer support and enterprise copilots
- Application: Maintain diversity in suggested resolutions and step-by-step reasoning to reduce overfitting to few scripts; better generalization to novel tickets.
- Tools/products/workflows: Entropy‑guided RLHF plugin; entropy/coverage KPIs in alignment dashboards; fallback to higher-entropy phases for new intents.
- Assumptions/dependencies: Robust preference data; guardrails to prevent diversity from harming consistency on regulated answers.
- Education (tutoring and assessment)
- Application: Train LLM tutors to present multiple solution paths, improving learning outcomes while maintaining correctness.
- Tools/products/workflows: Curriculum‑aware entropy schedules (higher early exploration, anneal later); pass@K‑to‑pedagogy mapping (e.g., show K distinct strategies).
- Assumptions/dependencies: Grounded scoring of solutions; domain-specific evaluation (step validity, reasoning rubrics).
- Data labeling and reward modeling ops
- Application: Use higher-entropy early phases to surface diverse candidate responses for labeling, reducing annotator bias and improving reward model coverage.
- Tools/products/workflows: Labeling queues seeded by entropy-controlled rollouts; active-learning loops that adjust entropy to fill coverage gaps.
- Assumptions/dependencies: Annotation budget; mechanisms to detect diminishing returns and anneal exploration.
- Product search, recommendations, and knowledge assistants
- Application: Train LLM rankers/agents to explore diverse recommendation rationales while converging to stable quality with annealing.
- Tools/products/workflows: Entropy-controlled RL over click/quality feedback; A/B frameworks with entropy telemetry.
- Assumptions/dependencies: Reward fidelity and de-biasing; constraints to avoid unsafe exploration in sensitive content.
- Smaller-model deployment and cost optimization
- Application: Use Entrocraft to close performance gaps so smaller models outperform larger baselines, reducing inference cost.
- Tools/products/workflows: “Small beats big” RL recipes; model portfolio selection based on entropy-controlled training curves.
- Assumptions/dependencies: Comparable data and reward quality; careful tuning of schedules across domains.
- Model safety and robustness (alignment operations)
- Application: Prevent echo-chamber amplification during RL post-training by maintaining controlled exploration; reduce reward hacking via schedule-aware training.
- Tools/products/workflows: Safety dashboards tracking entropy, KL, and novelty; policy to decelerate entropy decay when drift is detected.
- Assumptions/dependencies: Reliable red‑teaming signals and reward penalties; monitoring and rollback capabilities.
- Research pipelines (academia/industrial labs)
- Application: Systematically study exploration–exploitation schedules, replicate results across GRPO/GSPO, and benchmark entropy dynamics.
- Tools/products/workflows: Open-source Entrocraft module; experiment templates to compare fixed/linear/cosine schedules; per-step entropy logging.
- Assumptions/dependencies: Access to training internals (rollouts, advantages); standard evaluators (MATH, AIME, domain tasks).
- Agentic tool-use and planning (software ops)
- Application: Train agents to retain exploration in tool chains (search, retrieval, API calls) to avoid brittle plans; anneal entropy as plans stabilize.
- Tools/products/workflows: Planner RL with schedule control; telemetry on plan diversity and success rates.
- Assumptions/dependencies: Verifiable rewards for plans; sufficient negative samples early on.
- Monitoring and SRE for RL training
- Application: Add “entropy curve SLOs” to long-running RL jobs to detect saturation or explosion early; automate schedule adjustments.
- Tools/products/workflows: W&B/Prometheus/Grafana panels; autoschedulers that adjust target ranges; gating policies for batch acceptance rate.
- Assumptions/dependencies: Instrumentation to compute batch entropies; thresholds tailored per domain.
Long-Term Applications
These require further research, scaling, or domain validation before broad deployment.
- Healthcare (clinical decision support and differential diagnosis)
- Application: Maintain exploration of differential hypotheses during RL while safely converging, potentially improving coverage of rare conditions.
- Tools/products/workflows: Entropy‑aware RL with verifiable, clinician‑curated rewards; schedule regimes aligned to case complexity.
- Assumptions/dependencies: High-assurance rewards and audits; regulatory approval; strict bounds on exploration to avoid unsafe suggestions.
- Finance (risk analysis, strategy discovery)
- Application: Encourage exploration of diverse risk scenarios or trading rationales early, anneal toward deployable strategies.
- Tools/products/workflows: Backtesting pipelines integrated with entropy schedules; guardrails to prevent overexploitation of spurious correlations.
- Assumptions/dependencies: Reliable, leakage‑free rewards; compliance and auditability; robust out-of-sample validation.
- Robotics and embodied agents
- Application: For LLM-driven high-level policies, control exploration in long‑horizon planning and instruction following, reducing collapse to narrow behaviors.
- Tools/products/workflows: Hierarchical RL with entropy control at plan and action levels; sim-to-real curricula with annealing.
- Assumptions/dependencies: Stable interfaces between LLM plans and low-level controllers; safe exploration constraints.
- Multimodal foundation models (vision-language, speech-language)
- Application: Prevent mode collapse in multimodal reasoning (e.g., chart QA, VQA-cot) and improve diversity of rationale candidates.
- Tools/products/workflows: Entropy control tied to multimodal token distributions; schedule design per modality mix.
- Assumptions/dependencies: Accurate advantage estimation in multimodal settings; computational overhead of larger rollouts.
- Policy and governance of AI training processes
- Application: Standardize reporting and oversight of exploration–exploitation management (e.g., “entropy schedule disclosures”) for RL-aligned models.
- Tools/products/workflows: Audit artifacts (entropy curves, acceptance rates, pass@K trajectories); conformance checks in procurement.
- Assumptions/dependencies: Consensus on metrics; secure logging; alignment with regulatory frameworks.
- Continual and long-horizon RL for evolving domains
- Application: Use annealed or staged entropy schedules to prolong learning as data shifts (e.g., evolving regulations, new APIs).
- Tools/products/workflows: Auto‑curricula that raise entropy on distribution shifts and decays when stable; drift detectors triggering schedule changes.
- Assumptions/dependencies: Reliable drift detection; sustained supply of high-quality negative samples.
- Dataset and reward model construction
- Application: Use entropy-controlled sampling to build more balanced datasets and reward models (reduce long-tail sparsity).
- Tools/products/workflows: “Entropy-guided curation” services; difficulty-aware sampling regimes.
- Assumptions/dependencies: Human labeling budgets; mechanisms for de-biasing and deduplication.
- Federated/edge RL fine-tuning
- Application: Train smaller on-device models with controlled exploration to reach near-cloud quality while preserving privacy.
- Tools/products/workflows: Lightweight Entrocraft modules integrated into federated RL; schedule sharing via metadata.
- Assumptions/dependencies: Efficient, on-device advantage estimation; privacy-preserving reward signals.
- AutoML for RLHF/RLAIF pipeline tuning
- Application: Treat the entropy schedule as a first-class hyperparameter; automatically search schedules that optimize final task metrics.
- Tools/products/workflows: Schedule search spaces (initial target, slope, bounds); Bayesian optimization over schedules and PPO params.
- Assumptions/dependencies: Compute budget; reproducible pipelines; robust early‑stopping heuristics.
- Benchmarks and standards for exploration metrics
- Application: New community benchmarks that score not just accuracy but sustained improvement and diversity under controlled entropy schedules.
- Tools/products/workflows: Public leaderboards with entropy dynamics; standard reporting templates.
- Assumptions/dependencies: Broad adoption by research/industry; consistent evaluation protocols.
Notes on feasibility across applications:
- Core dependencies: high-quality rewards or verifiable metrics; advantage estimators compatible with policy-gradient methods; sufficient rollouts per prompt so rejection sampling does not starve updates; careful setting of target ranges and annealing schedules; adherence to small‑step update assumptions (e.g., Adam with typical LLM learning rates).
- Operational considerations: monitoring entropy, KL, acceptance rates, and pass@K; guardrails to avoid entropy explosion; ensuring stability when positive/negative sample balance shifts over long training; integrating with existing RL frameworks without significant throughput loss.
Glossary
- acceptance probability: The chance that a sampled rollout is kept during rejection sampling, often conditioned on current entropy. "The acceptance probability of rejection sampling depends on the current batch entropy"
- advantage distribution: The statistical distribution of estimated advantages across sampled rollouts; its shape influences entropy changes and training stability. "the advantage distribution becomes increasingly imbalanced"
- advantage estimator: A procedure or model that computes the advantage value for a rollout, typically denoted as A-hat. "advantage estimator "
- advantage function: In policy-gradient RL, a value estimating how much better a specific action/trajectory is than a baseline; drives the policy update. "the estimated advantage function"
- advantage-weighted updates: Policy updates where gradients are weighted by advantages, which can systematically affect entropy. "advantage-weighted updates"
- annealing schedule: A time-varying target or control schedule that gradually changes a training quantity (here, entropy) over training. "a linear annealing schedule performs best"
- clipping: A stabilization technique that limits update magnitudes or ratios (e.g., in PPO), often reducing high-advantage effects. "the clipping technique"
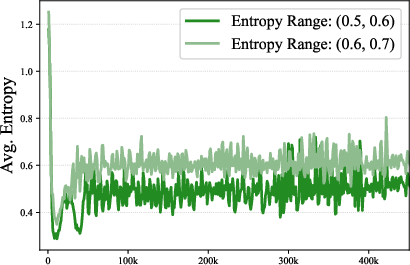
- entropy collapse: A drop in predictive entropy indicating reduced exploration and diversity during RL. "entropy collapse corresponds to a shrinking exploration ability during RL."
- entropy curve: The trajectory of model entropy values over training steps; used to monitor and control exploration. "control over the entropy curve"
- entropy curve annealing: Gradually lowering a target entropy over time to stabilize long-term RL training. "entropy curve annealing"
- entropy dynamics: The evolution of model entropy throughout training. "This evolution is known as entropy dynamics"
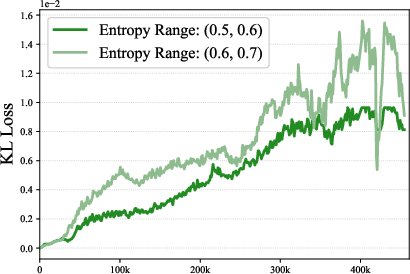
- entropy explosion: An uncontrolled increase in entropy that destabilizes training. "caused by entropy explosion (Fig.~\ref{fig:entropy_4})"
- entropy regularization: Adding an entropy term to the loss to promote exploration and prevent collapse. "requires no entropy regularization"
- entropy-preserving: Refers to methods designed to maintain entropy during RL training. "entropy-preserving techniques"
- explorationâexploitation balance: The trade-off between trying new actions and leveraging known good ones; its collapse can cause saturation. "collapse of the explorationâexploitation balance"
- Group Relative Policy Optimization (GRPO): A policy-gradient RL algorithm for LLMs that uses group-wise relative comparisons to compute advantages. "Group Relative Policy Optimization (GRPO)"
- Group Sequence Policy Optimization (GSPO): A policy-gradient RL algorithm operating on groups of sequences to optimize policies for LLMs. "Group Sequence Policy Optimization (GSPO)"
- importance sampling ratio: The ratio between current and sampling policies used to correct for off-policy effects in updates. "importance sampling ratio"
- inference-time scaling: Performance gains achieved by generating more samples at inference and selecting better outputs. "improves inference-time scaling"
- KL loss: The Kullback–Leibler divergence term used as a regularizer/metric of deviation between policies. "KL Loss"
- linear annealing: A simple schedule that decreases a target (e.g., entropy) linearly over training steps. "linear annealing"
- log likelihood: The logarithm of the probability the model assigns to observed sequences; reflects model confidence. "log likelihoods"
- output space baseline: A reference value derived from probabilities over the output vocabulary, used to interpret entropy changes. "output space baseline"
- pass@K: A metric measuring whether at least one of K sampled answers is correct. "pass@K"
- performance saturation: The phenomenon where continued training yields little to no performance gain despite more data/compute. "performance saturation"
- policy gradient: A class of RL methods that optimize policies by ascending expected returns via gradient estimates. "policy-gradient RL framework"
- PPO-style objective: An objective inspired by Proximal Policy Optimization that uses clipping and importance ratios for stable updates. "PPO-style objective"
- positive-negative decoupling: Designing separate objectives or weights for positive and negative samples to shape entropy and learning. "positive-negative decoupling"
- rejection sampling: A filtering method that accepts or rejects sampled rollouts based on a criterion (e.g., entropy control). "rejection sampling"
- rollout generation: Sampling model responses to prompts under the current or an old policy to collect data for updates. "rollout generation"
- sequence-level entropy: Entropy computed over entire generated sequences, reflecting uncertainty across time steps. "token-level entropy and sequence-level entropy"
- target entropy: A desired entropy value used to steer the model’s exploration during training. "against a target entropy"
- temperature coefficient: A scalar controlling the sharpness of acceptance probabilities in the rejection filter. "temperature coefficient "
- token-level entropy: Entropy computed at individual time steps over the token distribution, indicating per-token uncertainty. "token-level entropy and sequence-level entropy"
- zero-mean-advantage RL: RL setups where advantages are normalized to have mean zero, aiming to balance entropy changes. "zero-mean-advantage RL"
Collections
Sign up for free to add this paper to one or more collections.