- The paper presents a multi-level feature distillation framework that merges distinct dataset-trained teachers into a joint teacher for enhanced model learning.
- The methodology involves fusing teacher features at various representation levels, enabling accurate knowledge transfer and reducing dataset bias.
- Experiments across CIFAR-100, ImageNet-Sketch, and TinyImageNet demonstrate up to a 12% accuracy improvement over traditional baselines.
Multi-Level Feature Distillation of Joint Teachers Trained on Distinct Image Datasets
Introduction
The paper proposes a Multi-Level Feature Distillation (MLFD) framework designed to leverage diverse datasets to improve model generalization. The methodology involves fusing individually trained teachers into a joint architecture, which then distills its multi-level learned representations into student models specific to each dataset. The framework addresses the limitations posed by single-dataset training and dataset bias, aiming to capitalize on complementary knowledge across datasets.
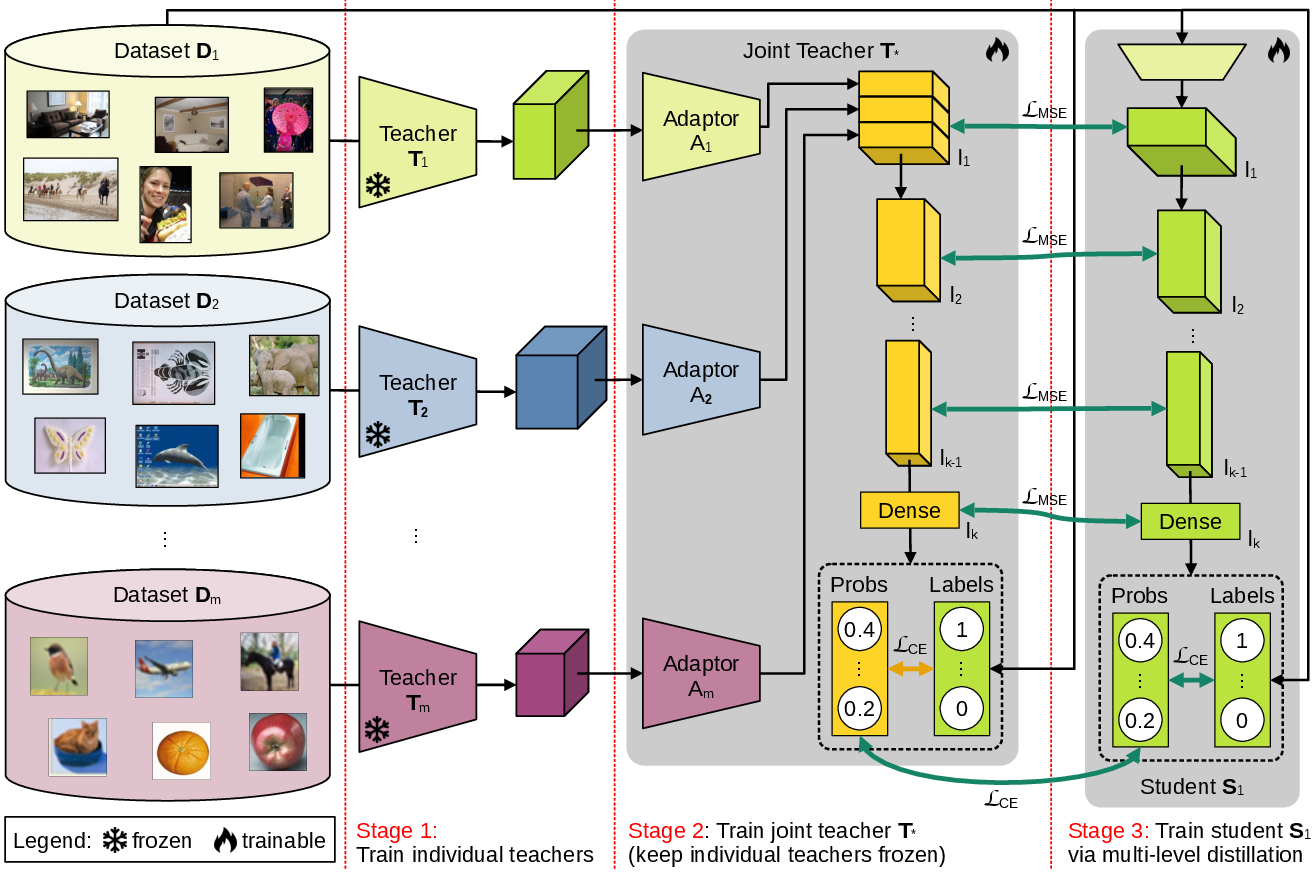
Figure 1: Our multi-level feature distillation (MLFD) framework is based on three stages. In the first stage, individual teachers are trained on each dataset. In the second stage, the individual teachers are merged at a certain representation level (l1) into a joint teacher T∗. Finally, in the third stage, each student Si is trained via multi-level feature distillation from the joint teacher T∗.
Methodology
The MLFD method comprises three stages:
- Teacher Training: Individual teachers are trained on distinct datasets. This step can be omitted if pre-trained models are used.
- Joint Teacher Formation: Features from these individual teachers are fused at various representation levels to form a joint teacher which trains on all datasets. The fusion occurs at pre-specified layers, facilitating the transfer of multi-faceted knowledge.
- Student Model Training: Knowledge is distilled into individual student models using embeddings and output probabilities at multiple depth levels. The distillation leverages joint teachers' representations to enhance dataset-specific model performance.
Algorithm \ref{alg_MLFD} provides pseudocode for implementing this multi-level feature distillation, detailing how teacher features are integrated and how student models are trained using the transferred knowledge.
Experimental Setup
Experiments span across CIFAR-100, ImageNet-Sketch, and TinyImageNet datasets. The MLFD framework demonstrated superior performance gains across diverse architectures (e.g., ResNet, EfficientNet). These improvements were quantified using metrics such as top-1 and top-5 accuracy, significantly surpassing traditional single-dataset models and various multi-dataset baselines.
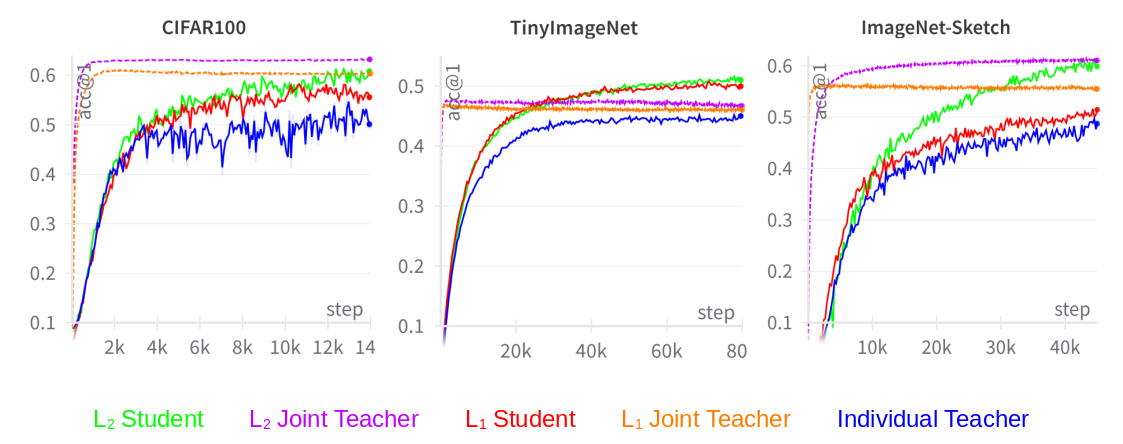
Figure 2: Top-1 accuracy evolution during the training process for models in T1. Best viewed in color.
Results and Analysis
Results revealed consistent improvements across all networks involved, highlighting the efficacy of the MLFD approach. Compared to single-dataset baselines, multi-level distillation models showed a notable improvement in generalization and performance, up to 12% in accuracy across benchmarks. Importantly, employing multi-level (L2) distillation demonstrated enhanced performance, underscoring the necessity of multi-representation level incorporation.
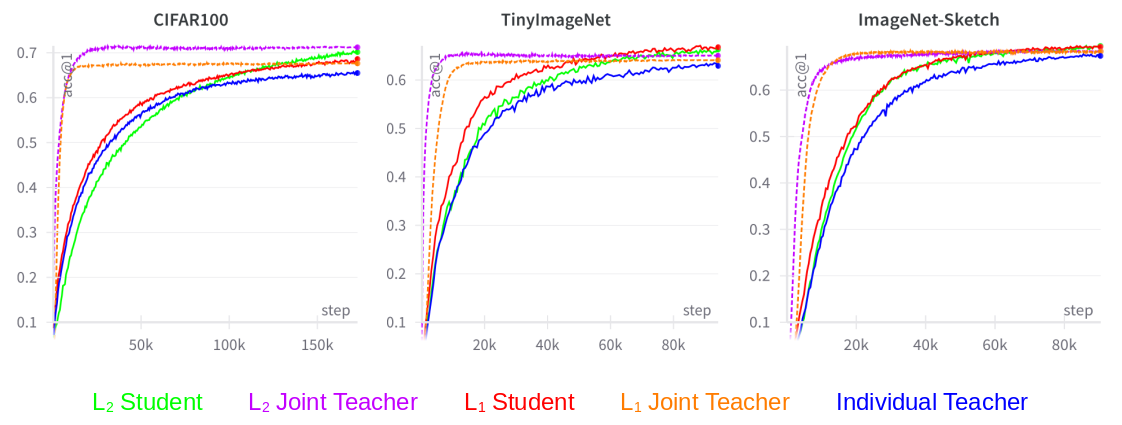
Figure 3: Top-1 accuracy during the training process for models in $\mathcal{T}_2. Best viewed in color.</p></p>
<h3 class='paper-heading' id='ablation-study'>Ablation Study</h3>
<p>The ablation study ensured the multi-layer approach's contribution by testing joint teacher architectures under various layer configurations (L1 through L4), confirming that layers closer to output terminals deliver better results due to more discriminative and dataset-specific learned features.
<img src="https://emergentmind-storage-cdn-c7atfsgud9cecchk.z01.azurefd.net/paper-images/2410-22184/Results-Teachers-Subscript.png" alt="Figure 4" title="" class="markdown-image" loading="lazy">
<p class="figure-caption">Figure 4: Performance evolution of joint teachers when using different sets of layers (from $L_1toL_4$) to extract features. Best viewed in color.
Conclusions
The Multi-Level Feature Distillation method effectively increases the generalization capability of image models by successfully aggregating and distilling information from multiple datasets. The strong empirical results under varied conditions bolster its applicability in wider domains such as object detection and context-aware applications. Future work involves extending this distillation framework to new model architectures and tasks beyond image classification, potentially exploring areas such as NLP.
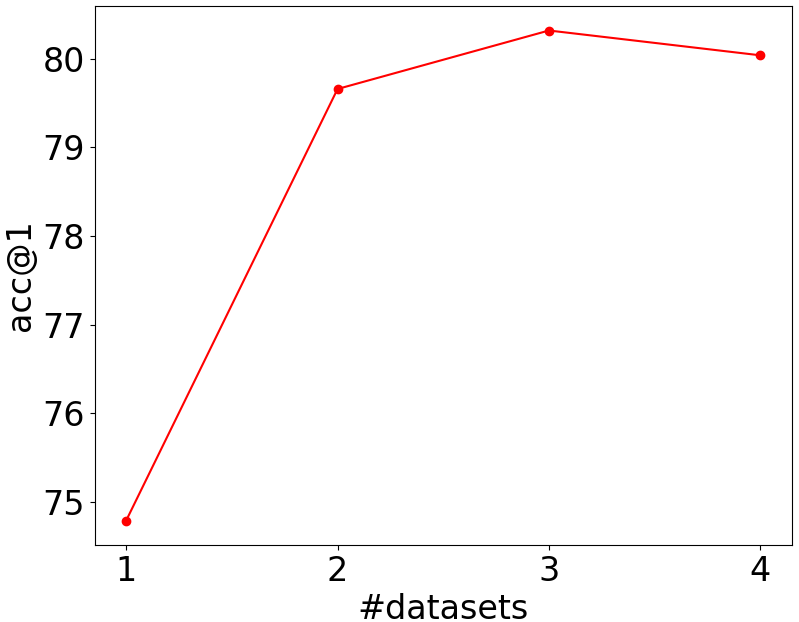
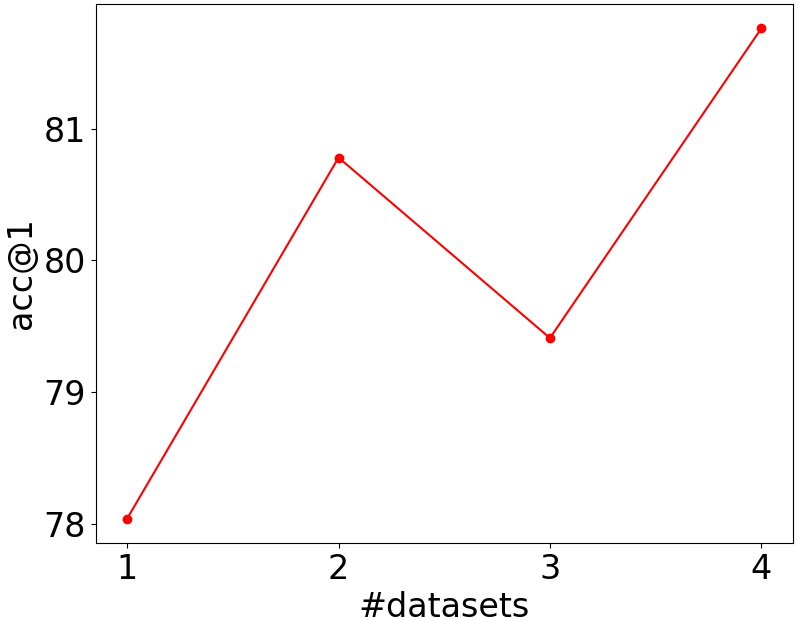
Figure 5: Accuracy rates of the student models on Caltech-101 (left) and Flowers-102 (right) when the number of datasets is increased from one to four. Best viewed in color.
A supplementary evaluation emphasized enhanced feature space visualization, demonstrated by t-SNE. This indicates a more discriminative representation, affirming MLFD's impact on latent space structuring for improved inference.

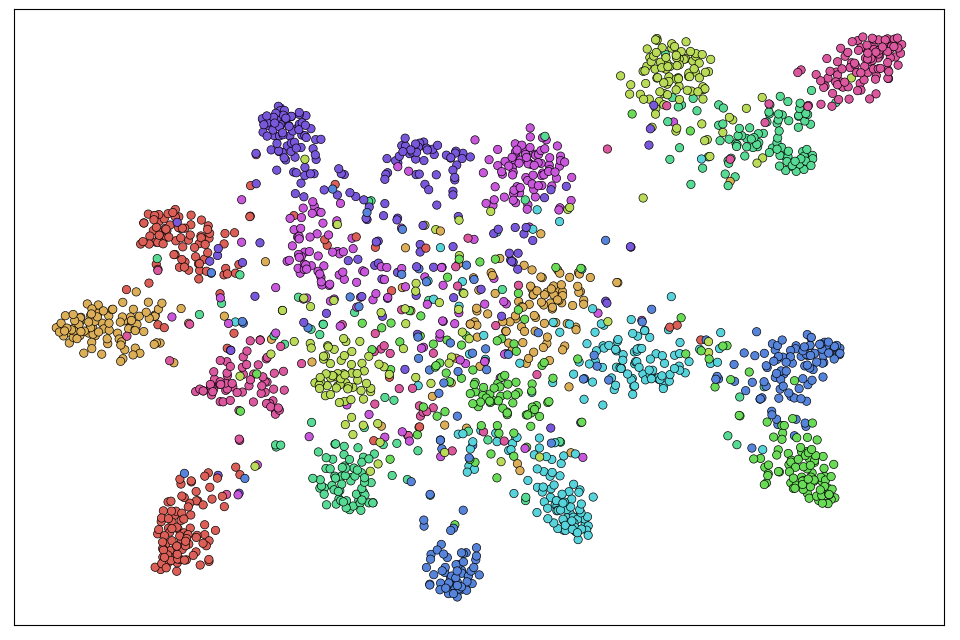
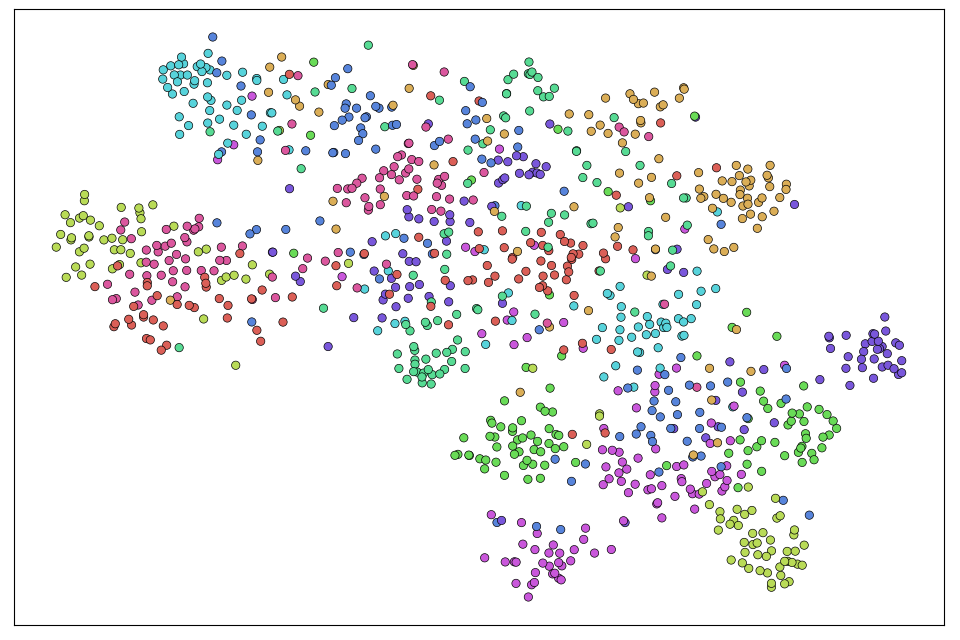
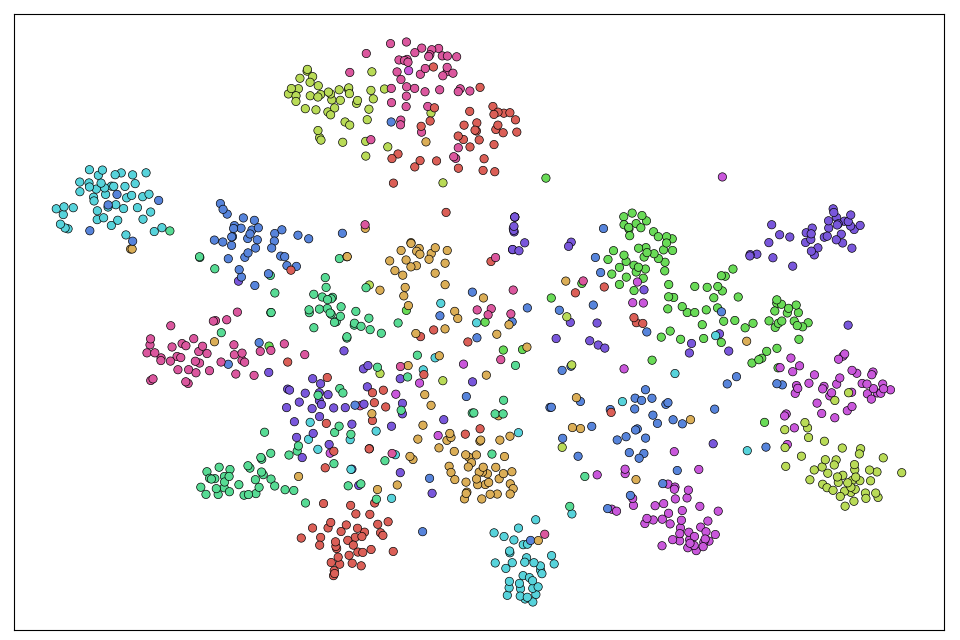
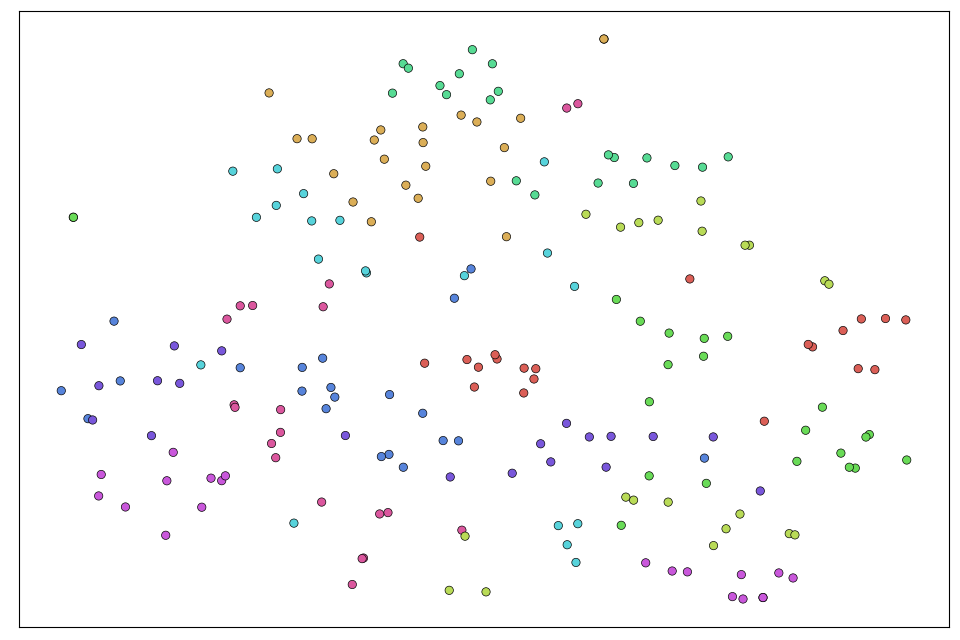

Figure 6: Visualizations based on t-SNE projections of image embeddings learned by the dataset-specific models (left) and those learned by our student models (right) for the three datasets: CIFAR-100 (first row), TinyImageNet (second row), ImageNet-Sketch (third row). Best viewed in color.