- The paper presents a novel DAMI framework that modulates cognitive depth by interpolating between System 1 and System 2 checkpoints.
- It introduces two strategies—preference learning and confidence-based methods—to achieve a smooth and monotonic Pareto frontier between accuracy and efficiency.
- Experiments on mathematical benchmarks show DAMI improves accuracy by up to 3.4% and reduces token use by up to 40%, highlighting its practical benefits.
System 1&2 Synergy via Dynamic Model Interpolation
Introduction
The dichotomy in LLMs between intuitive "System 1" models and deliberative "System 2" models remains a significant challenge. System 1 models are optimized for rapid and intuitive responses, excelling in scenarios demanding immediate and straightforward solutions. Conversely, System 2 models deliver superior reasoning capabilities by engaging in more complex, chain-of-thought (CoT) processes, catering to problems requiring deep cognitive deliberation. Recent advancements have focused on improving the efficiency of System 2 models; however, they primarily revolve around output control strategies, which target what the models produce rather than optimizing their underlying cognitive processes.
The paper "System 1&2 Synergy via Dynamic Model Interpolation" (2601.21414) introduces a novel perspective by shifting from output control to capability control. This approach modulates the cognitive intensity of models using dynamic parameter interpolation between System 1 and System 2 checkpoints, leveraging existing models without necessitating additional training. This method results in a convex, monotonic Pareto frontier between accuracy and efficiency, establishing representation continuity and structural connectivity as foundational pillars of this technique.
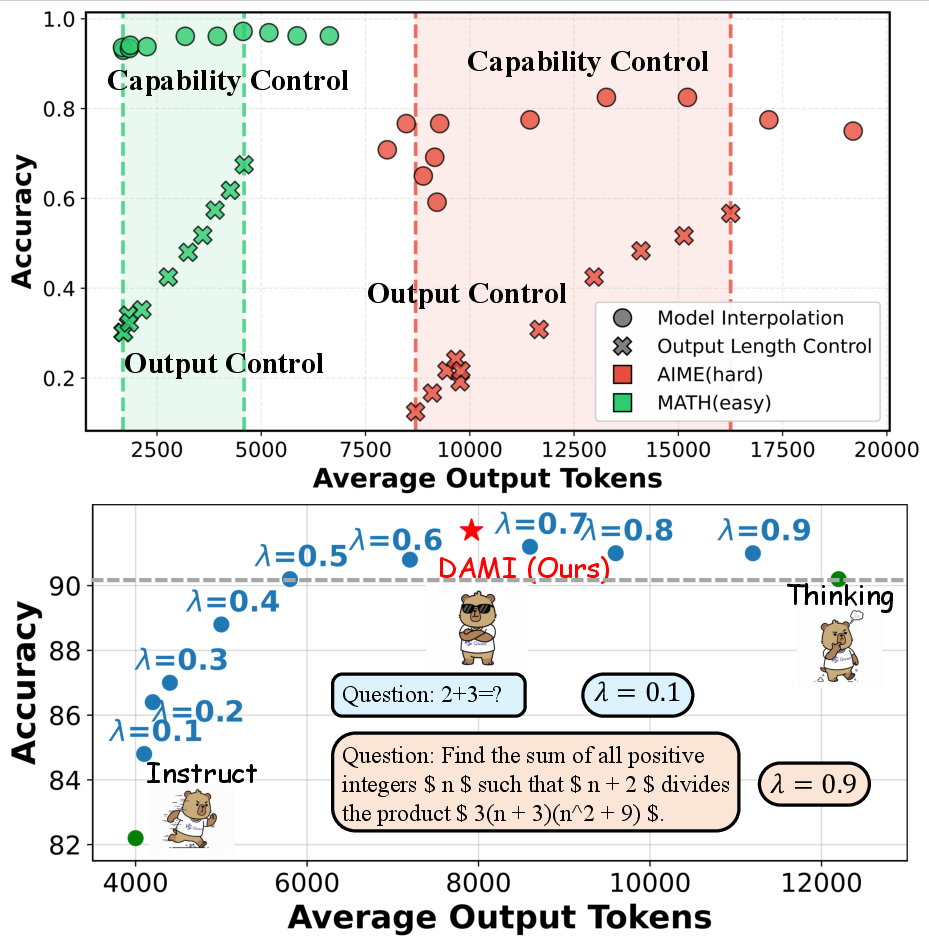
Figure 1: Capability control outperforms output control across different efficiency levels on both tasks. Linear interpolation between Instruct and Thinking yields a monotonic Pareto frontier.
Methodology
Dynamic Model Interpolation Framework
The Dynamic Model Interpolation (DAMI) framework estimates query-specific Reasoning Intensity λ(q) to dynamically adjust cognitive depth. DAMI leverages:
- Preference Learning (DAMI-Pref): Tailored for scenarios where domain-specific training data is available, this method encodes accuracy and efficiency criteria to guide reasoning intensity adjustments.
- Confidence-based Method (DAMI-Conf): Suitable for rapid, zero-shot deployment across diverse domains, leveraging inter-model cognitive discrepancies to estimate difficulty without needing training data.
The interpolation method aligns with the structural properties of parameter space, adhering to Linear Mode Connectivity, enabling predictable transitions in accuracy-efficiency trade-offs.
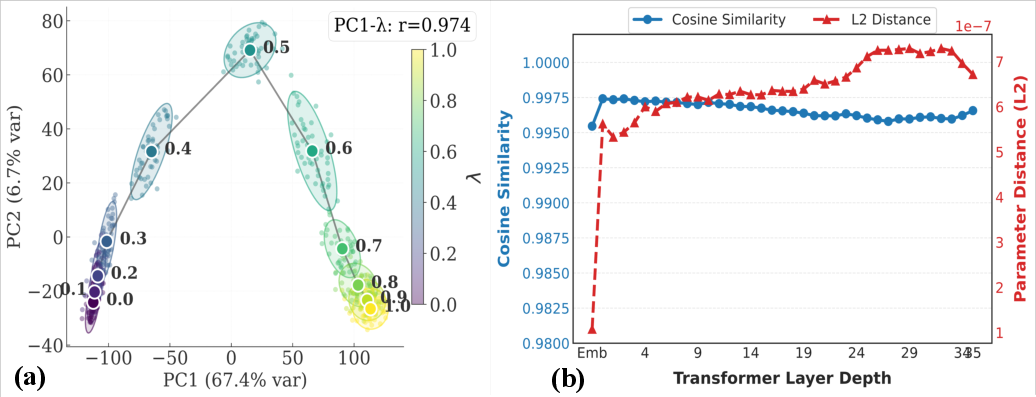
Figure 2: The monotonicity and continuity of reasoning intensity.
Theoretical Insights
Parameter interpolation between existing checkpoints provides a principled mechanism for reason control via structural connectivity. Empirical evidence supports a smooth Pareto frontier between accuracy and efficiency when interpolating between System 1 and System 2 models. The foundational properties include representation continuity, as illustrated by continuous trajectories in PCA space correlating with interpolation constants, further bolstering the efficacy of DAMI in configuring cognitive depth dynamically.
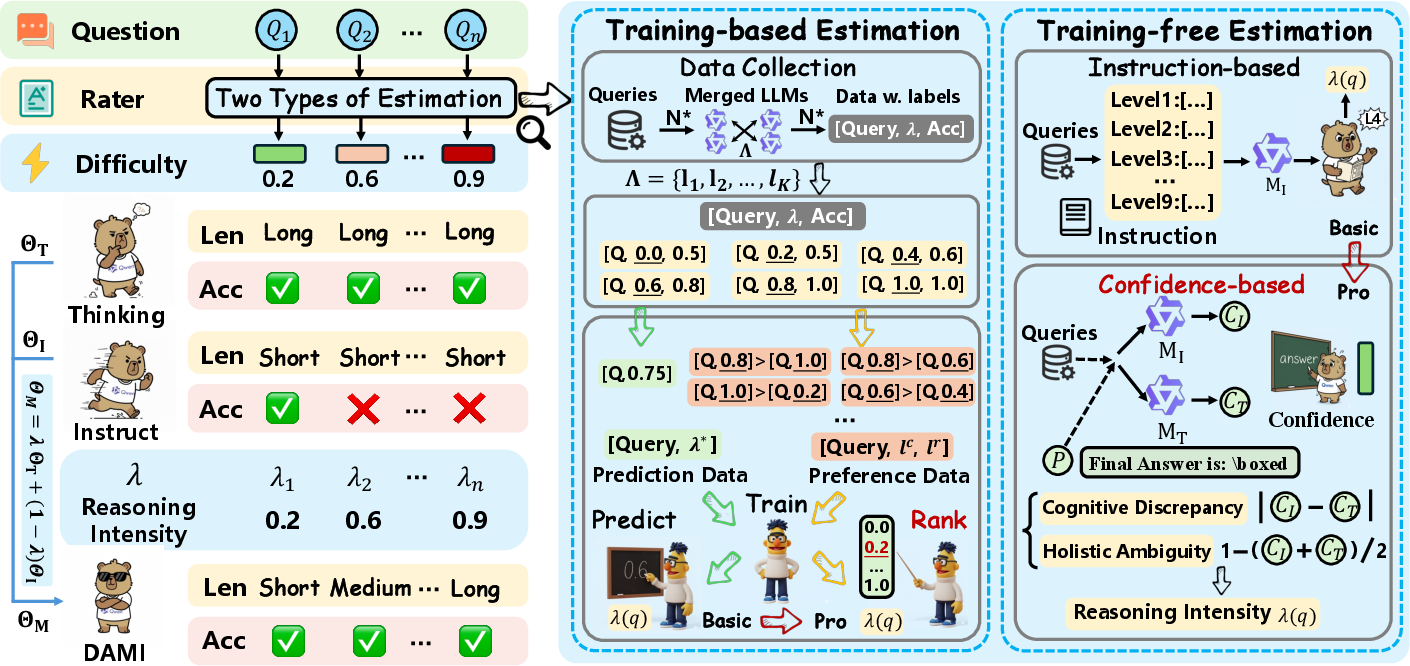
Figure 3: An overview of our DAMI method. DAMI estimates query difficulty through either preference learning (training-based) or confidence signals (training-free), then dynamically adjusts the Reasoning Intensity λ(q) to configure cognitive depth accordingly.
Experiments
Experiments conducted across five mathematical reasoning benchmarks demonstrate DAMI achieving superior accuracy-efficiency trade-offs. Results showcase DAMI improving accuracy by 1.6--3.4% while simultaneously reducing token consumption by 29--40% compared to the standalone Thinking model, outperforming various static and dynamic models.
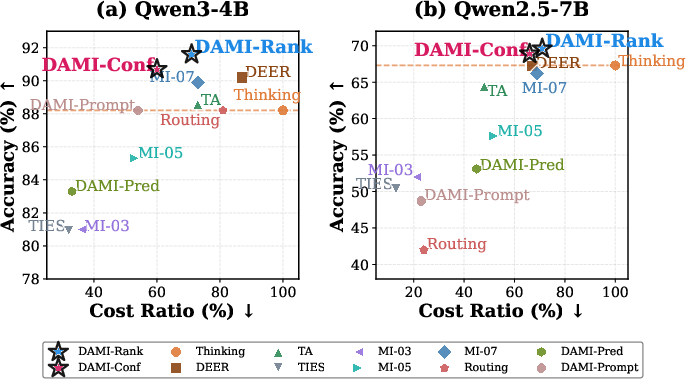
Figure 4: Accuracy-efficiency scatter plot aggregated over five benchmarks. DAMI methods (starred) achieve the best accuracy-efficiency trade-offs on both Qwen3-4B and Qwen2.5-7B.
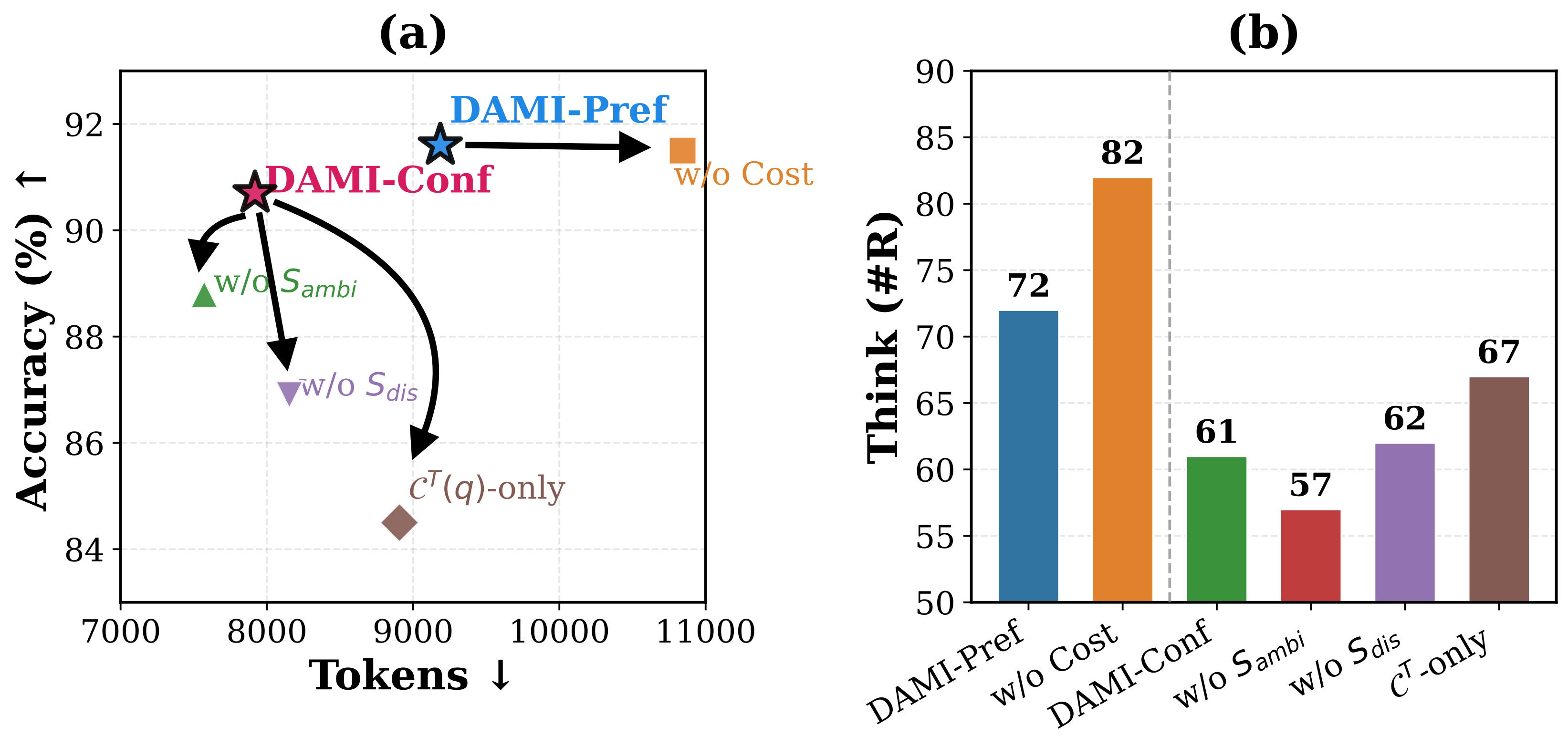
Figure 5: Ablation study results on the Qwen3-4B model pair.
Implications and Future Directions
The shift from output control to capability control represents a significant paradigm transition, suggesting broader implications for the adaptive architectures in reasoning models. DAMI's ability to fine-tune the cognitive processes underpinning reasoning depth highlights the potential for more sophisticated, query-specific adjustments, paving the way for more efficient, versatile models. This approach aligns with the notion of continuous cognitive transitioning rather than discrete paradigm shifts during training, offering expanded potential in the development of LLMs capable of bridging the gap between rapid response and deep reasoning. The efficiency gains and improved accuracy demonstrated by DAMI suggest that similar principles could inform future innovations in adaptive, dynamic model architectures.
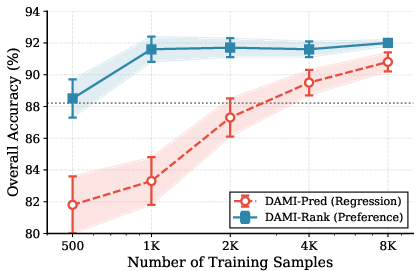
Figure 6: Effect of training data size on training-based lambda estimation.
Conclusion
"System 1&2 Synergy via Dynamic Model Interpolation" (2601.21414) introduces a transformative approach in LLMs, advocating for capability control via dynamic model interpolation. By seamlessly adjusting cognitive depth according to query complexity, DAMI not only enhances efficiency but also offers a robust mechanism to integrate the strengths of two disparate cognitive systems into a unified model architecture. Future developments could explore broader applications of dynamic model interpolation, informed by the insightful empirical and theoretical foundations laid in this research.
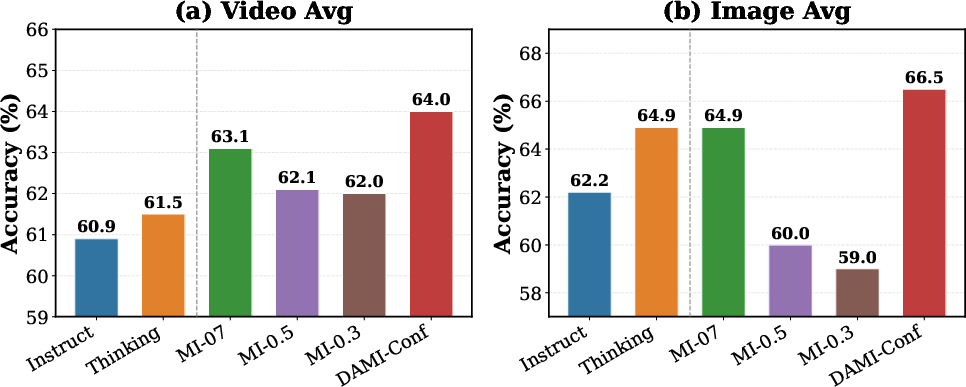
Figure 7: Generalization to multimodal tasks of DAMI.