BitDance: Scaling Autoregressive Generative Models with Binary Tokens
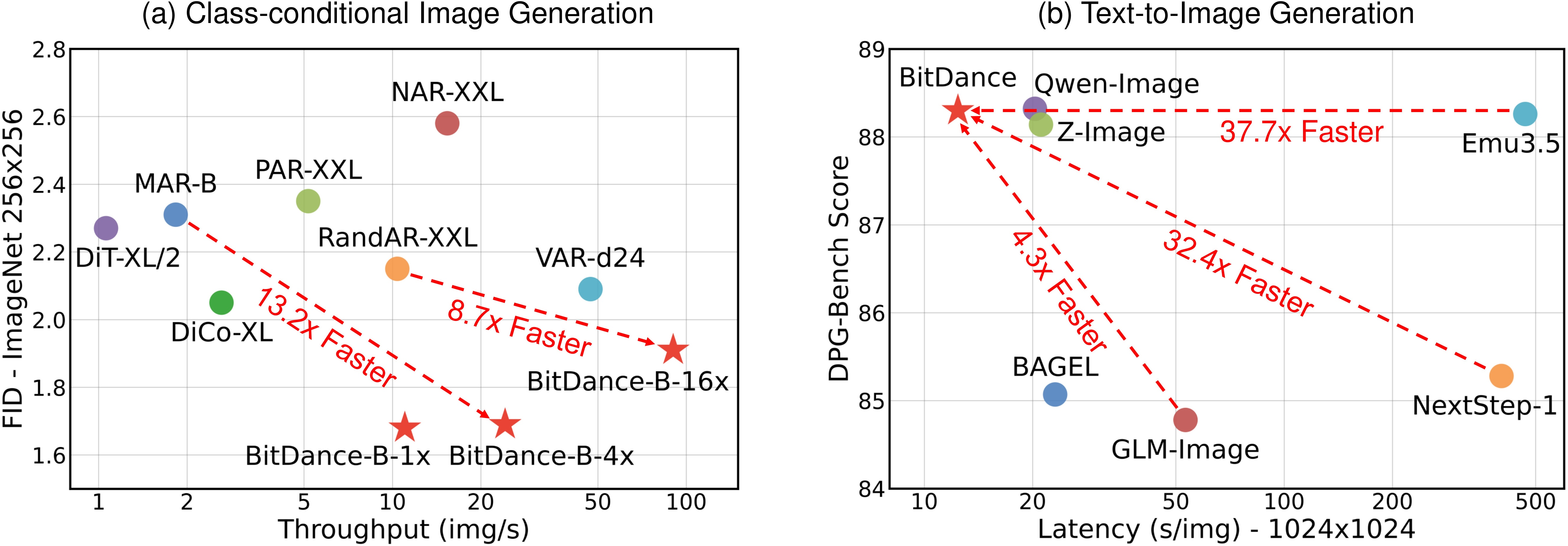
Abstract: We present BitDance, a scalable autoregressive (AR) image generator that predicts binary visual tokens instead of codebook indices. With high-entropy binary latents, BitDance lets each token represent up to $2{256}$ states, yielding a compact yet highly expressive discrete representation. Sampling from such a huge token space is difficult with standard classification. To resolve this, BitDance uses a binary diffusion head: instead of predicting an index with softmax, it employs continuous-space diffusion to generate the binary tokens. Furthermore, we propose next-patch diffusion, a new decoding method that predicts multiple tokens in parallel with high accuracy, greatly speeding up inference. On ImageNet 256x256, BitDance achieves an FID of 1.24, the best among AR models. With next-patch diffusion, BitDance beats state-of-the-art parallel AR models that use 1.4B parameters, while using 5.4x fewer parameters (260M) and achieving 8.7x speedup. For text-to-image generation, BitDance trains on large-scale multimodal tokens and generates high-resolution, photorealistic images efficiently, showing strong performance and favorable scaling. When generating 1024x1024 images, BitDance achieves a speedup of over 30x compared to prior AR models. We release code and models to facilitate further research on AR foundation models. Code and models are available at: https://github.com/shallowdream204/BitDance.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces BitDance, a new way for computers to create images. BitDance is an “autoregressive” model, which means it builds pictures step by step, predicting the next piece from what it has already drawn. The key idea is to use simple binary tokens (like long strings of 1s and 0s) to represent images, and a special “diffusion” method to predict those tokens quickly and accurately. This lets BitDance make very realistic, high-resolution pictures much faster than many previous methods.
What are the key questions?
The researchers focused on three main questions:
- How can we represent images with tokens that carry a lot of detail, but still keep generation stable and reliable?
- If each token can have a huge number of possible states (up to ), how can we sample the right token efficiently without using a slow or huge classifier?
- Can we predict multiple image tokens at once (instead of one-by-one) to speed up image generation, while keeping the results sharp and coherent?
How did they do it? (Methods in everyday terms)
Think of image generation like building a mosaic:
- Autoregressive modeling is like placing one tile at a time, choosing each tile based on the tiles already placed.
- Tokens are like the instructions for each tile. The more information a token can hold, the more detailed and accurate the final image.
Here’s what BitDance changes:
1) Binary visual tokens: “barcodes for pictures”
- Instead of picking from a fixed dictionary of image pieces, BitDance turns image features into long binary strings (1s and 0s)—like a barcode that can represent up to different states.
- This “high-entropy” design means each token can store a lot of detail, helping the model reconstruct images with fine textures and text.
- To make this efficient, they use a method called Lookup-Free Quantization (LFQ) and a “group-wise” trick to manage memory when training. In simple terms: they split the long barcode into smaller groups to keep training fast and stable.
2) Binary diffusion head: “finding the right corner of a cube”
- Predicting the exact token by classification would be like picking from a menu with trillions of items—too slow and too big.
- Instead, they imagine all binary tokens as corners of a big geometric shape (a hypercube). The model starts at random inside this space and uses a diffusion process (think “guided drifting”) to move toward the correct corner.
- This “continuous-space diffusion” avoids the massive classification step and naturally captures how bits in a token depend on each other (so it doesn’t treat each bit as independent when they aren’t).
3) Next-patch diffusion: “painting tiles in groups”
- Standard models place one token at a time. BitDance predicts a whole small patch (like a 2×2 or 4×4 block of tokens) at once.
- Why this works: nearby tiles in an image are related, so predicting them together keeps local details aligned (edges match, textures flow).
- The same diffusion head is extended to model the joint distribution of all tokens in the patch, so they come out coherent rather than independently guessed.
What did they find, and why is it important?
BitDance shows strong image quality and speed:
- On ImageNet 256×256 (a standard benchmark), BitDance achieves an FID of 1.24. FID is a number where lower is better—it measures how close generated images are to real ones. 1.24 is excellent for autoregressive models.
- With next-patch diffusion, BitDance generates images much faster. A 260 million–parameter BitDance model beats a state-of-the-art 1.4 billion–parameter parallel AR model, while being about 8.7× faster.
- For text-to-image tasks, BitDance scales up to 14 billion parameters, produces high-resolution images (up to 1024×1024), and shows more than 30× speedup compared to earlier AR models, while scoring well on multiple benchmarks:
- GenEval: 0.86 (tests following instructions like counts, colors, positions)
- DPG-Bench: 88.28 (tests understanding entities, attributes, relations)
- OneIG-EN: 0.532 and OneIG-ZH: 0.512 (tests text alignment, reasoning, style, diversity)
Why these numbers matter:
- Better FID means images look more real.
- Faster generation means practical use at high resolutions.
- Strong instruction-following scores mean the model aligns well with text prompts (important for creative tools and AI assistants).
Why this research matters (Implications)
- More detail with fewer mistakes: Binary tokens carry lots of information and are naturally “discrete,” which helps prevent small errors from snowballing when generating long sequences.
- Practical high-res image synthesis: Predicting patches together greatly speeds up generation, making high-resolution, photorealistic images much more efficient.
- A unified path with LLMs: Since BitDance is autoregressive like LLMs, it fits neatly into the growing world of multimodal AI (text, images, and potentially audio or video), and can share similar training strategies.
- Open research and development: The authors release code and models, helping others build faster, high-quality generative systems for art, design, education, and creative tools.
In short, BitDance shows that using binary tokens plus diffusion for sampling, and predicting patches in parallel, can make image generation both very accurate and much faster—pushing forward what autoregressive models can do.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues that future work could address:
- Quantifying vocabulary utilization at 2256: How many effective bits per token are actually used during generation? Provide code utilization, entropy per channel, and occupancy statistics to verify that the enlarged code space is meaningfully populated.
- Impact of group-wise entropy on token quality: The tokenizer approximates entropy with grouped channels; quantify how the number/size of groups affects cross-group dependence, reconstruction quality, and downstream generation.
- Small-model usability of high-entropy tokens: The paper notes small Transformers struggle with large vocabularies. Explore curricula, token factorization, or distillation schemes that enable smaller models to benefit from high-entropy binary tokens.
- End-to-end joint training of tokenizer and AR model: BitDance appears to use a separately trained tokenizer. Assess whether joint finetuning improves generation, reduces error accumulation, or changes entropy utilization.
- Binary diffusion head likelihood and calibration: The head produces samples but lacks tractable likelihoods or calibration metrics. Can we estimate or bound log-likelihood/perplexity, assess probability calibration, or design flow variants with exact/approximate likelihoods?
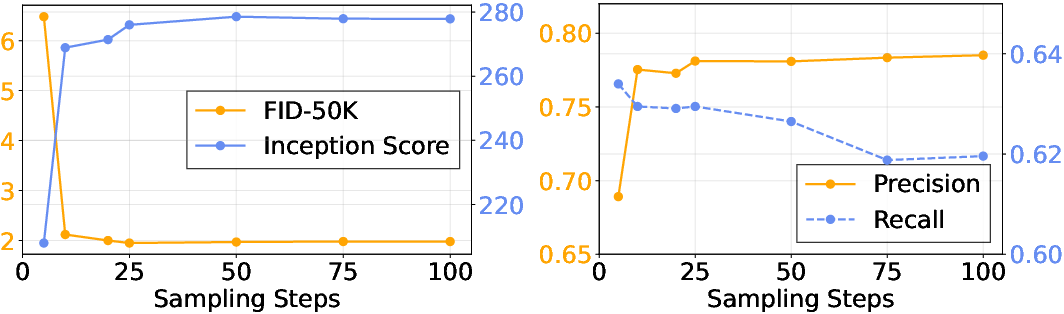
- Diffusion solver and step-count sensitivity: Provide ablations on solver choice (e.g., Euler vs higher-order), step counts N, noise schedules, and their speed–quality trade-offs for both single- and multi-token prediction.
- Head compute/memory overheads: Report FLOPs/parameters/activation memory for the binary diffusion head versus index softmax and bit-wise classification baselines, including how cost scales with d (bits per token) and p2 (parallel tokens).
- Failure modes and robustness of the diffusion head: Analyze mode collapse, diversity–fidelity trade-offs, and robustness to conditioning noise or previous-token errors; propose and evaluate regularizers or guidance strategies.
- Next-patch size p and boundary effects: Systematically study quality vs speed for different patch sizes, quantify patch-boundary artifacts, and characterize when increasing p harms coherence.
- Non-local joint sampling: Next-patch diffusion models local groups. Can we jointly sample non-local token sets (e.g., interleaved grids) to capture long-range dependencies within a step?
- Training–inference alignment for parallel prediction: Intra-patch tokens see each other during training but are unknown at inference; analyze leakage or mismatch and compare to iterative/masked refinement baselines.
- Error correction and iterative refinement: Investigate multi-pass refinement after initial parallel sampling to correct local errors without sacrificing speed.
- Long-horizon drift quantification: The paper claims reduced error accumulation vs continuous latents; provide explicit long-sequence drift metrics and controlled studies at increasing resolutions/sequence lengths.
- High-resolution (512–1024+) quantitative quality: Beyond speedups, report FID/CLIPScore/aesthetic/human preference for 512 and 1024 images, and analyze memory/latency breakdowns at scale.
- Aspect ratio and layout generalization: Characterize performance across diverse aspect ratios and complex spatial layouts; evaluate text rendering and typography fidelity in long captions.
- Multilingual generalization beyond EN/ZH: Test on more languages and scripts; quantify text rendering accuracy and failure cases (e.g., ligatures, vertical text).
- Data transparency and safety: Disclose training corpora composition/licensing, filtering, and bias/safety analyses; assess memorization, harmful content, and watermark preservation/removal.
- Compute and energy cost: Report training/inference GPU-days, energy, and carbon estimates for tokenizer and 14B AR model to assess accessibility and efficiency.
- Controlled comparisons across tokenizers: Hold the Transformer and training recipe fixed while swapping tokenizers (VQ, LFQ-binary, continuous VAE) to isolate the contribution of token design versus modeling.
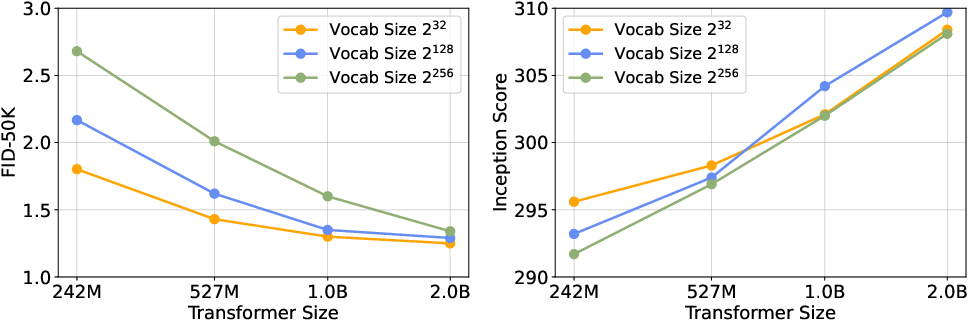
- Compression–generation trade-offs: Explore how downsampling ratios (16× vs 32×) and code sizes (232/2128/2256) affect downstream generation quality, not just reconstruction.
- Distillation for larger p: The text mentions distilling from p=4 to p=8; specify the teacher–student signals, objectives, and stability, and quantify the quality–speed curve across p.
- Guidance and sampling controls: Document or develop classifier-free guidance analogs for binary diffusion heads, temperature/top-k strategies, and their impact on diversity, text alignment, and artifacts.
- Token interpretability and control: Investigate whether bits or groups correspond to semantically meaningful factors; explore bit-level editing or controlled attribute manipulation.
- Robustness and OOD: Evaluate performance on out-of-distribution classes, corrupted prompts, and adversarial/noisy conditions; measure stability under token corruptions during AR rollout.
- Extension to video/audio/3D: Assess whether binary tokens and next-patch diffusion scale to temporal and volumetric data, and what modifications (ordering, conditioning, memory) are required.
- Maximum feasible parallelism limits: Determine practical ceilings for p2 and d given head memory constraints; propose architectural or factorized heads to push beyond current limits.
- Reproducibility details: Clarify inference hyperparameters (temperature, step counts), tokenizer training tricks (e.g., STE usage for sign), and implementation choices needed to replicate reported scores.
Glossary
- Autoregressive (AR): A modeling paradigm that generates sequences by predicting each token conditioned on previous ones. "We present BitDance, a scalable autoregressive (AR) image generator that predicts binary visual tokens instead of codebook indices."
- bfloat16: A 16-bit floating-point format that trades precision for range, commonly used to reduce memory while retaining training stability. "For continuous tokenizers, we assume that latent features are stored in the commonly used bfloat16 format to calculate the compression ratio."
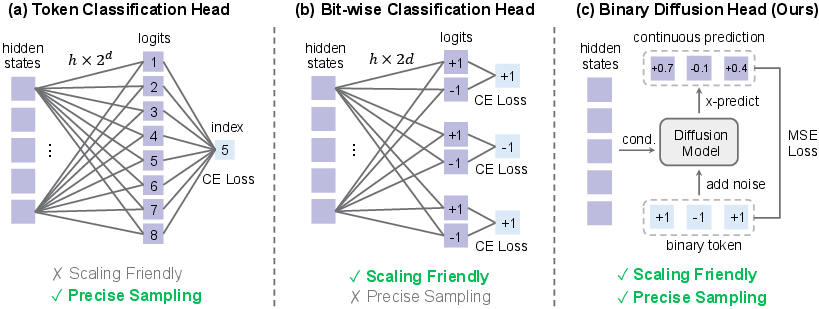
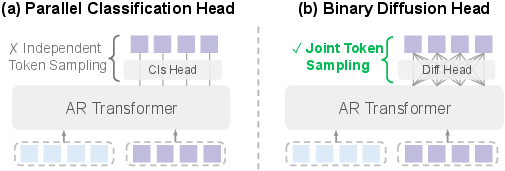
- Binary diffusion head: A diffusion-based output module that models binary tokens in continuous space to sample from extremely large discrete vocabularies. "BitDance uses a binary diffusion head: instead of predicting an index with softmax, it employs continuous-space diffusion to generate the binary tokens."
- Binary quantization: Representing features using binary values (e.g., −1/1) to create large discrete vocabularies with efficient codebooks. "Inspired by recent advances in binary quantization~\cite{yulanguage,zhao2024image}, we scale the entropy of binary representations, expanding the vocabulary size up to ."
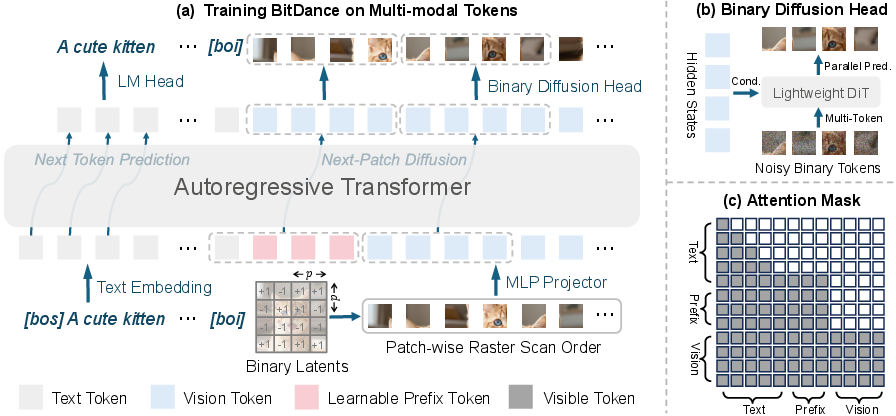
- Binary tokenizer: A tokenizer that converts visual features into high-entropy binary codes rather than categorical indices. "BitDance is built upon three key components: (i) a large-vocabulary binary tokenizer, (ii) a binary diffusion head for sampling in extremely large discrete spaces, and (iii) a next-patch diffusion paradigm that enables efficient multi-token prediction."
- Bit-wise classification: Predicting each bit of a binary token independently, assuming inter-bit independence. "Bit-wise classification~\cite{han2025infinity} reduces the parameter count to by assuming bit independence, i.e., ${\textstyle \prod_{i=1}^{d} p(b_i)$, but this restrictive assumption compromises sampling fidelity."
- Block-wise causal attention mask: An attention mask that enforces causality across groups (blocks) while allowing full visibility within a block for parallel token prediction. "To implement this within the AR Transformer, we employ a block-wise causal attention mask."
- Codebook collapse: A failure mode in quantization where only a small subset of codebook entries are used, limiting representation capacity. "However, traditional Vector Quantization (VQ) often encounters codebook collapse as the vocabulary expands."
- Cross-entropy loss: A standard classification loss measuring the divergence between predicted and true distributions, used here to preserve text understanding. "we additionally incorporate a standard cross-entropy loss on text tokens to preserve the model's text-understanding capabilities."
- DiT: Diffusion Transformer, a transformer architecture tailored for diffusion modeling in image generation. "To effectively model the tokens within the head, we design the architecture of prediction network as a lightweight DiT~\cite{dit}."
- Entropy loss: A regularizer that encourages uniform usage of codebook entries to maximize information capacity. "To prevent codebook collapse and maximize information capacity, an entropy loss~\cite{Jansen2019CoincidenceCA} is typically employed:"
- Euler solver: A numerical integration method used to step through the learned velocity field during diffusion sampling. "we initialize and integrate the learned velocity field using an Euler solver with uniform steps :"
- Exponential Moving Average (EMA): A technique that maintains a smoothed copy of model parameters to stabilize training and improve evaluation. "Additionally, an Exponential Moving Average (EMA) decay rate of 0.9999 is applied."
- Fréchet Inception Distance (FID): A metric comparing statistics of generated and real images’ features to assess generative quality. "The main evaluation metric is the Fréchet Inception Distance (FID)~\cite{heusel2017gans}."
- Group-wise LFQ: A strategy that computes entropy over channel groups to scale Lookup-Free Quantization efficiently. "To address this bottleneck, we adopt a group-wise LFQ strategy~\cite{zhuang2025wetok}, which partitions channels into distinct groups for entropy calculation."
- Hard binarization constraint: A projection step forcing continuous predictions back onto binary values by taking the sign. "After steps, we apply a hard binarization constraint: ."
- Hypercube: The geometric structure whose vertices represent all possible binary token configurations in d dimensions. "we embed binary tokens as vertices of a -dimensional hypercube in continuous space."
- Hyperspherical constraints: Regularization that restricts latent representations to a hypersphere to improve stability and prevent drift. "SphereAR~\cite{ke2025hyperspherical} employs hyperspherical constraints to regularize the latent features of VAEs."
- Inception Score (IS): A metric assessing the quality and diversity of generated images using a pre-trained classifier’s predictions. "Additionally, we report Inception Score (IS)~\cite{salimans2016improved} as well as Precision and Recall~\cite{kynkaanniemi2019improved} as complementary measures of generative quality."
- Lookup-Free Quantization (LFQ): A quantization approach using an implicit binary codebook to avoid explicit codebook lookups. "we adopt binary quantization via Lookup-Free Quantization (LFQ)~\cite{yulanguage}."
- Next-patch diffusion: A decoding scheme that jointly predicts multiple tokens within a local patch via diffusion for faster AR generation. "Furthermore, we propose next-patch diffusion, a new decoding method that predicts multiple tokens in parallel with high accuracy, greatly speeding up inference."
- Parallel AR generation: An autoregressive formulation that predicts groups of tokens simultaneously while maintaining causal dependencies across groups. "The parallel AR generation can be expressed as:"
- Precision and Recall (for generative models): Metrics quantifying fidelity (precision) and coverage/diversity (recall) of generated images relative to real data. "Additionally, we report Inception Score (IS)~\cite{salimans2016improved} as well as Precision and Recall~\cite{kynkaanniemi2019improved} as complementary measures of generative quality."
- Raster-scan order: A sequential ordering of image tokens from left-to-right, top-to-bottom used in AR decoding. "Standard autoregressive (AR) visual generation typically quantizes images into discrete tokens and models their distribution via next-token prediction in a raster-scan order~\cite{sun2024autoregressive,wang2024emu3,cui2025emu35}."
- Rectified Flow: A flow-based diffusion formulation that learns a velocity field to transport noise to data. "To model the conditional probability distribution , we adopt the Rectified Flow~\cite{liuflow} formulation and optimize the head using -prediction with a velocity-matching loss~\cite{li2025back}:"
- Token entropy: The information capacity of tokens; higher entropy allows more expressive representations and better reconstructions. "For discrete visual tokenizers, scaling up the vocabulary size to increase token entropy is critical for enhancing both reconstruction fidelity and downstream generation quality."
- Variational Autoencoders (VAEs): Generative models that encode data into a continuous latent space and decode back, enabling efficient modeling. "Variational Autoencoders (VAEs)~\cite{kingma2013auto} are widely used to project visual content into continuous latent spaces."
- Vector Quantization (VQ): A discrete tokenization method mapping continuous vectors to nearest entries in a learned codebook. "Existing discrete AR models typically leverage Vector Quantization (VQ)~\cite{van2017neural,esser2021taming} for tokenization"
- Velocity field: The learned vector field in flow-based diffusion guiding samples from noise to data. "we initialize and integrate the learned velocity field using an Euler solver with uniform steps"
- Velocity-matching loss: A training objective that aligns the model’s predicted velocity with the target velocity in flow/diffusion frameworks. "we adopt the Rectified Flow~\cite{liuflow} formulation and optimize the head using -prediction with a velocity-matching loss~\cite{li2025back}:"
Practical Applications
Immediate Applications
Below are concrete ways the BitDance findings and methods can be put to use today, with sector tags, likely tools/workflows, and feasibility notes.
- High-throughput text-to-image for creative production
- Sectors: media and entertainment, advertising, design, social media
- What it enables: rapid generation of 512–1024 px photorealistic images with accurate prompt adherence and readable text (30× faster than prior AR at 1024×1024; strong GenEval, DPG-Bench, OneIG scores)
- Tools/products/workflows: plugins for Figma/Adobe/Canva; internal asset generators for marketing teams; campaign A/B testing pipelines that render hundreds of variants per prompt; prompt-to-poster and prompt-to-banner tools that require embedded typography
- Dependencies/assumptions: access to released BitDance weights/code; safety filters for commercial use; prompts and brand style guides; GPU/accelerator capacity sized to chosen model (e.g., 260M variant for low-latency, 14B for highest fidelity)
- On-device and edge image generation with small AR models
- Sectors: mobile, embedded/edge AI, consumer apps, gaming
- What it enables: near-real-time local rendering using the ~260M-parameter BitDance-B with next-patch diffusion, enabling private, offline image creation and in-app texture/skin generation
- Tools/products/workflows: smartphone/NPU inference builds; desktop apps for creators; in-game runtime texture synthesis for modding or dynamic skins
- Dependencies/assumptions: kernel support for the binary diffusion head; mixed-precision/quantization; memory bandwidth limits; thermal budgets on edge devices
- E-commerce product imagery and localization
- Sectors: retail/e-commerce
- What it enables: fast production of catalog images, backgrounds, and localized creatives with readable multilingual text (e.g., English/Chinese signs and labels)
- Tools/products/workflows: batch renderers connected to PIM/DAM systems; localization pipelines that adapt product packaging/posters per market
- Dependencies/assumptions: brand and product constraints; human-in-the-loop QA for regulatory claims and trademark usage; fine-tuning or prompt engineering for product categories
- Diagram, signage, and layout generation with textual elements
- Sectors: education, publishing, enterprise knowledge, public sector communications
- What it enables: prompt-to-worksheet/infographic/poster with legible text embedded in images (BitDance reports strong text rendering)
- Tools/products/workflows: LMS-integrated worksheet creators; city signage mock-up generators; automated marketing collateral builders
- Dependencies/assumptions: typography fidelity varies by prompt/style; accessibility and localization requirements; content safety
- Synthetic data generation for computer vision
- Sectors: autonomous systems, robotics, retail, manufacturing, healthcare (non-diagnostic)
- What it enables: large, diverse, labeled synthetic images for training detection/recognition systems; quick scenario coverage with controllable attributes/relations (good GenEval/DPG compositional scores)
- Tools/products/workflows: data augmentation services; active learning loops that request targeted synthetic samples from BitDance
- Dependencies/assumptions: domain gap management and bias audits; labeling standards; legal review of data usage policies; careful use in medical contexts (non-diagnostic unless validated)
- Server-side throughput gains for image platforms
- Sectors: cloud platforms, creative SaaS, social media
- What it enables: lower latency and higher QPS for text-to-image services via next-patch diffusion parallelism (8–30× speedups compared to standard AR baselines; 90 img/s class-conditional throughput reported on A100 for 16× parallel)
- Tools/products/workflows: autoscaling microservices with token-parallel decoding; cost-aware schedulers that choose patch size p for SLA targets
- Dependencies/assumptions: engineering integration of block-wise causal attention; scheduler tuning for image sizes; monitoring for quality-speed trade-offs
- Discrete binary tokenizer as an image compression/archival format
- Sectors: content delivery networks (CDNs), storage, MLOps
- What it enables: storing images as high-entropy binary latents with reconstruction quality on par with or exceeding continuous VAEs at comparable compression ratios (2256 vocabulary; strong PSNR/SSIM)
- Tools/products/workflows: “binary-latent” codecs for dataset storage; training-time dataset streaming in latent space; caching of generated content as tokens
- Dependencies/assumptions: availability of decoders; standardization of bitstream format; acceptance of lossy characteristics; legal constraints for re-encoding licensed assets
- Research baselines and methodological studies
- Sectors: academia, industrial research
- What it enables: reproducible baselines for AR image generation; studies of scaling laws linking vocabulary entropy and model size; exploration of joint multi-token diffusion heads
- Tools/products/workflows: open-source training/evaluation recipes (PT/CT/SFT, optional distillation to larger p); benchmarking on ImageNet, GenEval, DPG, OneIG, TIIF
- Dependencies/assumptions: compute budgets; dataset access/licensing; alignment and safety evaluations for broader deployment
- Upgrading existing AR pipelines with parallel decoding
- Sectors: software/tools vendors, model providers
- What it enables: retrofitting AR decoders with next-patch diffusion and a binary diffusion head to replace per-token softmax, improving speed and coherence of parallel sampling
- Tools/products/workflows: model conversion scripts; head-swapping adapters; inference graphs that add multi-token DiT head
- Dependencies/assumptions: compatibility with current tokenizers (may require switching to LFQ/binary); retraining or fine-tuning for stability
Long-Term Applications
These use cases will benefit from further research, scaling, or standardization before broad deployment.
- Video generation via next-cuboid diffusion
- Sectors: media, entertainment, simulation, robotics
- What it could enable: joint spatiotemporal token prediction (patch × time) for coherent, fast video synthesis leveraging binary tokens and diffusion heads
- Tools/products/workflows: video editors with prompt-to-shot; simulation engines producing synthetic footage at scale
- Dependencies/assumptions: temporal tokenizers for binary latents; scalable training corpora; compute-efficient schedulers for longer sequences
- Unified multimodal AR foundation models
- Sectors: AI assistants, productivity, education
- What it could enable: a single AR model operating on high-entropy discrete tokens across text, image, diagram, and potentially audio, with fast joint generation and stronger regularization (reduced error accumulation)
- Tools/products/workflows: co-creative agents that draft, diagram, and render in one pass; multimodal tutoring systems
- Dependencies/assumptions: multimodal tokenization design; instruction-tuning/RLHF; safety and grounding stacks
- Standardized binary latent image codec
- Sectors: CDNs, browsers, camera pipelines, standards bodies
- What it could enable: a new, efficient, neural image format where assets are shipped as binary latents and decoded locally, reducing bandwidth/compute
- Tools/products/workflows: encoder/decoder SDKs; browser/native runtime support; hardware acceleration
- Dependencies/assumptions: open standardization; IP/licensing; predictable latency on commodity hardware
- Domain-specialized generators (medical, geospatial, industrial)
- Sectors: healthcare, remote sensing, manufacturing
- What it could enable: controllable, high-resolution, text-grounded imagery in specialized modalities with better parallel decoding for large canvases
- Tools/products/workflows: data simulators for rare pathologies; synthetic satellite imagery for pretraining
- Dependencies/assumptions: rigorous validation; regulatory compliance (e.g., FDA/EMA) for any diagnostic use; domain tokenizers and curated datasets
- 3D asset and scene synthesis
- Sectors: gaming, VFX, AR/VR, robotics simulation
- What it could enable: pipelines that use image generators as front-ends to 3D reconstruction (e.g., NeRF/GS distillation) or directly tokenize 3D/binary latents for fast, consistent multi-view generation
- Tools/products/workflows: prompt-to-3D asset creators; layout-to-scene generation with readable signage
- Dependencies/assumptions: multi-view/3D tokenizers; geometric consistency losses; cross-view joint token diffusion
- Cross-domain discrete generation with binary diffusion heads
- Sectors: audio/music, speech, code, time-series
- What it could enable: apply joint multi-token diffusion to other discrete domains (e.g., music tokens, symbolic control, program tokens) to improve parallel sampling fidelity
- Tools/products/workflows: sequencer plugins; code copilot “design → render” loops using discrete program tokens
- Dependencies/assumptions: suitable tokenizers with high-entropy binary representations; domain-specific conditioning
- Energy- and cost-aware AI deployment policies
- Sectors: policy/regulation, cloud providers, sustainability
- What it could enable: guidelines/incentives to favor architectures with better quality/latency/parameter trade-offs (e.g., BitDance vs larger AR baselines), reducing carbon per image generated
- Tools/products/workflows: procurement checklists; carbon dashboards comparing architectures under identical SLAs
- Dependencies/assumptions: transparent energy metering; lifecycle assessments; standardized efficiency benchmarks
- Content authenticity and watermarking in discrete latent space
- Sectors: policy, platforms, media provenance
- What it could enable: robust, low-overhead watermarking/signatures embedded in selected binary channels/tokens for provenance and moderation
- Tools/products/workflows: watermark encoders/validators at the token level; platform-side provenance checks
- Dependencies/assumptions: research to assess watermark robustness under decoding/post-processing; interoperability with C2PA or similar standards
- Federated and privacy-preserving creative systems
- Sectors: enterprise, consumer apps, healthcare (non-diagnostic)
- What it could enable: on-device generation with occasional server-side adaptation using token-level updates, limiting raw image/data sharing
- Tools/products/workflows: federated fine-tuning on binary latents; secure aggregation
- Dependencies/assumptions: communication-efficient updates; privacy threat modeling; device diversity handling
Notes on cross-cutting assumptions
- Data quality and licensing govern output reliability and legality.
- Reported metrics (FID/IS/GenEval/DPG/OneIG) indicate strong performance but do not guarantee correctness for safety-critical domains without domain validation.
- Engineering effort is required to integrate the binary diffusion head and block-wise causal attention into existing stacks.
- Scaling vocabulary entropy is more effective with larger Transformers; small models may underutilize large binary vocabularies (paper’s scaling observations).
Collections
Sign up for free to add this paper to one or more collections.