A Simple Baseline for Streaming Video Understanding
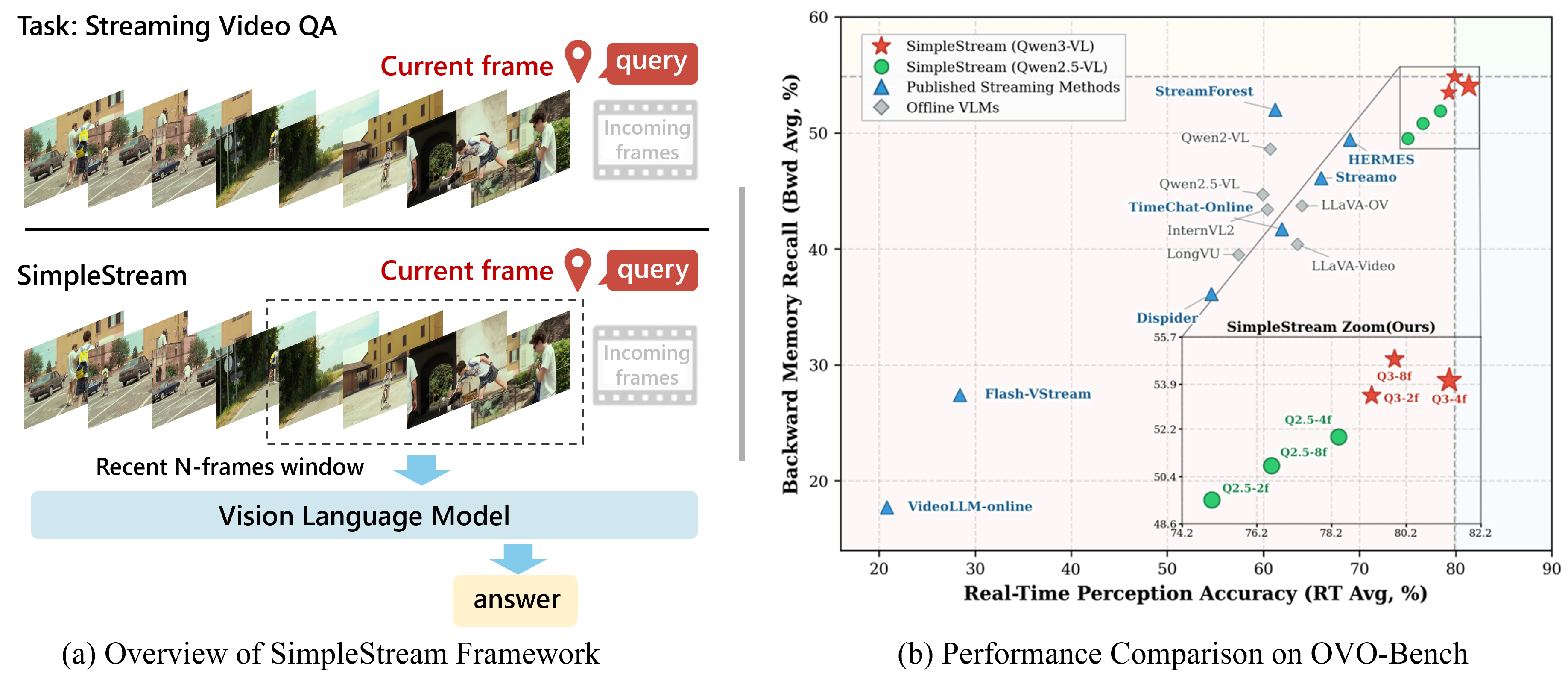
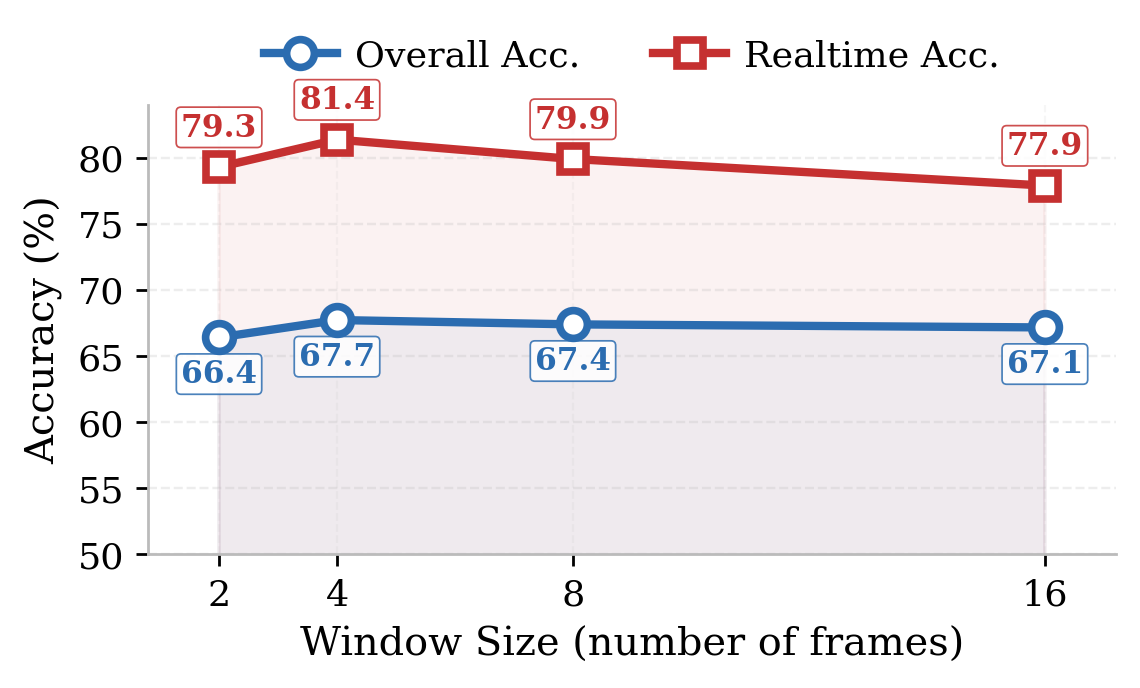
Abstract: Recent streaming video understanding methods increasingly rely on complex memory mechanisms to handle long video streams. We challenge this trend with a simple finding: a sliding-window baseline that feeds only the most recent N frames to an off-the-shelf VLM already matches or surpasses published streaming models. We formalize this baseline as SimpleStream and evaluate it against 13 major offline and online video LLM baselines on OVO-Bench and StreamingBench. Despite its simplicity, SimpleStream delivers consistently strong performance. With only 4 recent frames, it reaches 67.7% average accuracy on OVO-Bench and 80.59% on StreamingBench. Controlled ablations further show that the value of longer context is backbone-dependent rather than uniformly increasing with model scale, and reveal a consistent perception-memory trade-off: adding more historical context can improve recall, but often weakens real-time perception. This suggests that stronger memory, retrieval, or compression modules should not be taken as evidence of progress unless they clearly outperform SimpleStream under the same protocol. We therefore argue that future streaming benchmarks should separate recent-scene perception from long-range memory, so that performance improvements from added complexity can be evaluated more clearly.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Plain-English Overview
This paper looks at how computers can understand a live video stream while it’s happening, and answer questions about it in real time. Many recent systems use complicated “memory” tricks to remember lots of past video. The authors ask a simple question: do we really need all that complexity? They try a super simple approach that only looks at the last few frames of the video before answering—and surprisingly, it beats many fancy methods.
The Big Questions
The paper explores a few clear questions in simple terms:
- If a model just looks at the most recent few frames, can it already do really well?
- Does giving the model more and more past video always help, or can it sometimes hurt?
- Does the best amount of “past” depend on how big/strong the model is?
- Can a simple method also be fast and use less computer memory?
What Did They Do? (Methods explained with everyday ideas)
First, a couple of quick definitions in everyday language:
- Streaming video understanding: Imagine you watch a live sports game. When someone asks you a question at minute 30, you can only use what you’ve seen up to that moment—no peeking into the future. That’s the rule the models have to follow.
- Vision-LLM (VLM): A model that can look at images/video and read text, then answer questions in words.
Their approach, called SimpleStream, is intentionally minimal:
- When a question arrives at time t, they take only the last N frames (like the last 2, 4, 8, or 16 snapshots) and the question, and feed them to a strong, off-the-shelf VLM.
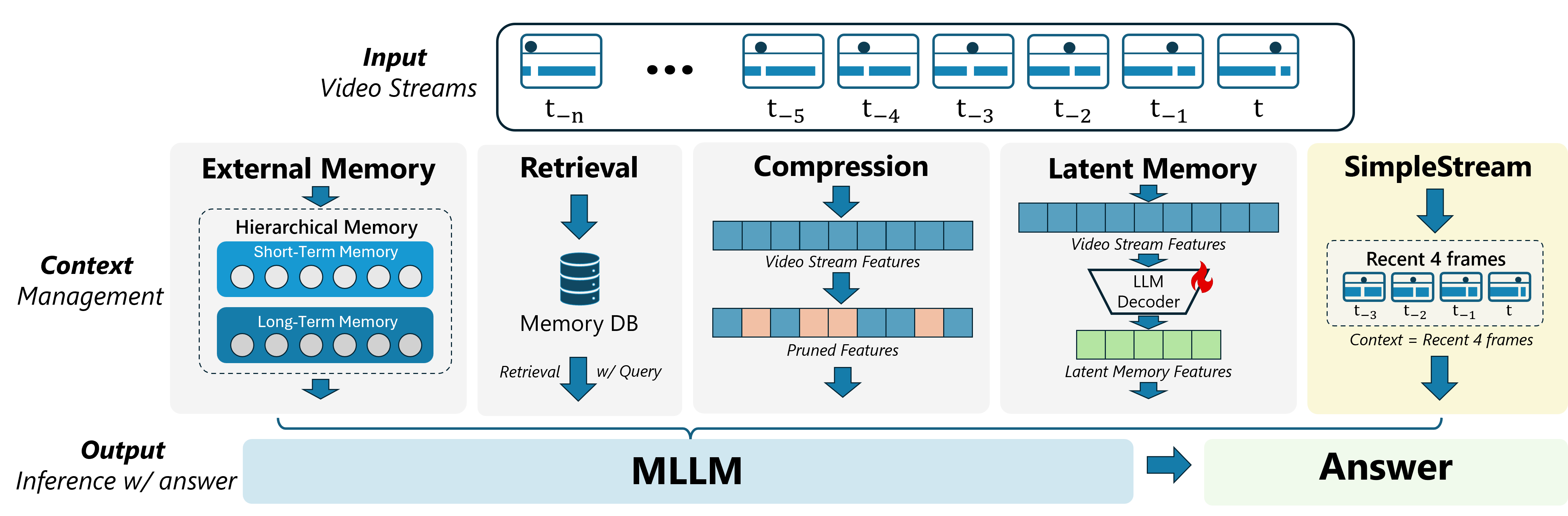
- They do not store long-term memories, do not retrieve past notes, and do not compress anything. Picture it like using your short-term memory only: you look at what just happened and answer.
To test this, they ran the method on two public test suites (benchmarks):
- OVO-Bench: asks 12 types of questions, split into “Real-Time Visual Perception” (what’s happening now—reading text on screen, recognizing objects/actions, etc.) and “Backward Tracing” (what happened earlier—episodic memory, action sequences, and a “hallucination detection” test).
- StreamingBench: focuses on real-time understanding across many question types.
They also ran controlled studies:
- Window size: try N = 2, 4, 8, 16 recent frames to see how much past is actually useful.
- Model scale: test small to large base models to see if bigger models benefit from longer windows.
- Visual-RAG: a retrieval trick that searches old frames for relevant pieces and appends them to the current input, like flipping back through a notebook for helpful snippets.
- Efficiency: measure speed to start answering (startup lag) and graphics card memory used.
What Did They Find? (Main results and why they matter)
Key takeaways, explained simply:
- A very simple recent-window method can be state-of-the-art. Using just the last 4 frames with a strong VLM outperformed more complex “memory-heavy” systems on major benchmarks. For example, on OVO-Bench overall, their simple setup reached about 67.7% versus 59.2% for a leading memory method. It was especially strong at “what’s happening now” tasks (like reading on-screen text, recognizing objects, and tracking actions).
- On memory-type tasks (questions about earlier moments), the simple method stayed competitive. Sometimes adding more past helped a bit, but not always.
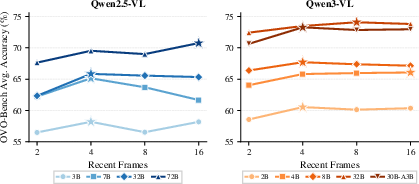
- Longer context is not always better. Going from 2 to 4 frames often helped, but going to 8 or 16 frames sometimes made results worse. Think of it like cluttering a clean desk: more papers can distract you from the important page on top.
- Bigger models don’t always want longer windows. The ideal number of recent frames depends on the model family and size. Some larger models liked 8 or 16 frames, but many still peaked at just 4 frames.
- Retrieval can boost memory but hurt live perception. Visual-RAG (retrieving old snippets) improved some memory-focused tasks, but it often made the model worse at seeing what’s happening right now. Overall accuracy went down in that setup.
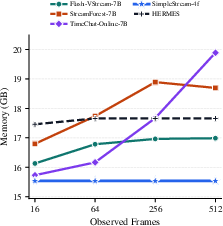
- Efficiency is excellent. Because SimpleStream only keeps a tiny recent window, it uses very little GPU memory and starts answering quickly. Its memory use stays almost flat even as the video gets longer, because it never piles up long-term storage.
Why this matters: It shows there’s a trade-off. Adding more history can help the model remember, but it can also distract it from the present. The paper calls this the perception–memory trade-off.
What This Means Going Forward (Impact and implications)
For researchers and builders:
- Always compare against a strong “simple recent frames” baseline. If a new memory system can’t beat this simple approach, the extra complexity may not be worth it.
- Design principle: recent-first, history-on-demand. Keep the present view clean and only bring in older frames when absolutely needed, and in a way that doesn’t clutter the model’s focus.
- Report results in a clearer way. Separate scores for “present-scene perception,” “true memory recall,” and “hallucination resistance,” instead of mixing them all together. The paper also points out that one of the “memory” tests (hallucination detection) isn’t really about memory recall.
For practical use:
- If you need a reliable, fast system to understand what’s happening right now in a live video, a simpler, cheaper method that focuses on the last few frames can be a great choice.
- If long-term recall is crucial, be careful: adding lots of history can slow the system down and make it less accurate about the current scene. A smarter, selective way to use history is likely better than dumping all past frames into the model.
One-Sentence Takeaway
A simple method that looks only at the last few frames can beat complex memory systems for live video understanding—so more memory isn’t always better, and keeping the present clear often wins.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, formulated so future researchers can act on them.
- Generalizability across backbone families: SimpleStream is only instantiated on Qwen2.5-VL and Qwen3-VL. It is unclear whether the recency-only advantage holds for other popular VLM families (e.g., LLaVA, InternVL, Idefics, MM1, Kosmos) when used as the backbone under identical protocols.
- Effect of frame rate and sampling policy: All SimpleStream experiments use 1 fps. The impact of fps, adaptive sampling (e.g., motion- or event-triggered), or multi-scale sampling on the perception–memory trade-off is unstudied.
- Adaptive window sizing: The window size N is fixed per run. There is no method to choose N per query based on uncertainty, query type, or perceived memory need, nor a policy to dynamically expand/contract context without harming present-scene perception.
- Query classification and memory gating: There is no mechanism to detect memory-intensive queries and selectively invoke history (e.g., retrieval or larger windows) while defaulting to recency-only for perception-heavy queries.
- Broader benchmark coverage: Validation is limited to OVO-Bench and StreamingBench. Generalization to other causal/online benchmarks (e.g., RIVER, LiViBench, PhoStream) and to egocentric or surveillance streams with different temporal statistics is not tested.
- Extremely long-horizon dependencies: The datasets used may underrepresent queries requiring recall over tens of minutes/hours. Whether SimpleStream’s advantage persists under truly long-range, sparse-cue memory tasks is unknown.
- Audio and multimodal streams: The approach ignores audio. Whether the recency-only conclusion holds when audio, ASR transcripts, or other modalities are present is unexamined.
- Domain robustness: Robustness to varied domains (egocentric, sports, animation, medical, low-light, motion blur, heavy occlusion) or to domain shift is not evaluated.
- Failure-mode analysis: The paper does not characterize where SimpleStream fails (e.g., identity re-identification across long gaps, cross-scene event linking) or provide per-task error taxonomies to guide memory-module design.
- Statistical significance and variability: Results are reported as point estimates without confidence intervals, multiple seeds, or significance tests. The stability of observed deltas across runs and prompts is unknown.
- Token-budget alignment and fairness: Comparisons do not normalize for visual/text token budgets across methods. It remains unclear whether SimpleStream’s gains persist when all models are constrained to identical token budgets.
- Prompt formatting and instruction tuning effects: The impact of prompt templates, instruction hierarchy, and system messages on the perception–memory trade-off (especially with retrieval) is not ablated.
- Mechanistic explanations for trade-off: The hypothesized attention dilution/competition is not empirically probed. Analyses of attention maps, token-level saliency, or interference between recent and retrieved tokens are missing.
- Retrieval design space: Visual-RAG is limited to CLIP-based nearest-neighbor over fixed chunks with naive concatenation. Alternative indexing (temporal-aware, query-conditioned encoders), reranking, chunking strategies, and placement/integration (separate channels or gated fusion) are not explored.
- Causal retrieval protocol: The paper does not detail whether the retrieval index is updated strictly online to avoid future leakage, nor how retrieval latency scales in a real-time setting.
- Mitigating retrieval-induced perception loss: Strategies to prevent retrieved context from degrading current-scene perception (e.g., recency-first routing, attention masks, priors favoring recency, or separate memory streams) are not attempted.
- Continuous-stream latency and throughput: Only TTFT and peak VRAM are reported. End-to-end throughput under sustained streaming with frequent queries, amortized costs, and jitter under varying stream lengths are unreported.
- Energy and deployment constraints: No measurements on power/energy, CPU/GPU utilization, or performance on edge devices are provided, limiting practical deployability insights.
- Multi-turn/dialog streaming: The setup treats each query independently. Interaction histories, dialogue coreference, and cross-turn memory (and whether recency-only still suffices) are not evaluated.
- Integration with proactive systems: The baseline does not consider answer readiness prediction or response timing; how SimpleStream interoperates with proactive/interactive policies is open.
- Temporal feature alternatives: Only raw frames are used. Whether lightweight online temporal features (e.g., optical flow, tubelets) or token-level motion priors could improve recency windows without memory modules remains unexplored.
- Window composition and ordering: The effect of frame ordering, interleaving (e.g., keyframe + deltas), spatial crops, or per-frame resolutions within the window is not ablated.
- Adaptive selection within the recent horizon: Choosing the most informative frames from the last M seconds (rather than taking the last N) is not studied.
- Benchmark metrics and weighting: Although the paper critiques OVO-Bench (e.g., HLD placement, macro-average bias), it does not provide or evaluate a standardized alternative metric suite nor release a reweighted scorer for community use.
- Privacy/security considerations: Memory-heavy systems may store past content; SimpleStream reduces storage but the trade-offs regarding privacy, retention policies, and susceptibility to prompt/visual injections are not investigated.
- Generalization to non-QA tasks: The approach is only tested on QA. Applicability to streaming detection, tracking, segmentation, or action localization with causal constraints is untested.
- Scaling laws beyond tested sizes and closed-source backbones: Whether trends persist with larger open models or closed-source frontier models (e.g., GPT-4V, Gemini) is unknown.
- Combined training strategies: The model uses inference-only policies. Whether light fine-tuning (e.g., instruction/posterior alignment for recency-first behavior) could improve performance or reduce the trade-off is not assessed.
- Adaptive cost control: There is no policy to jointly optimize accuracy and efficiency online (e.g., selecting N or retrieval depth under latency/VRAM budgets per query).
- Causal verification of hypothesized mechanisms: No controlled experiments isolate whether performance drops stem from redundancy, noise, attention budget limits, or prompt interference; disentangling these factors remains open.
Practical Applications
Overview
Based on the paper “A Simple Baseline for Streaming Video Understanding,” the central practical insight is that many real-time video tasks can be served competitively by a recent-context policy that feeds only the last N frames (often 4 frames at ~1 fps) into a strong off‑the‑shelf VLM, avoiding complex memory, retrieval, or compression. This design delivers strong accuracy on real‑time perception, competitive memory performance for many tasks, low latency, and minimal GPU memory growth—making it particularly attractive for edge and cost‑sensitive deployments. Below are concrete applications, categorized by immediacy, with sector tags, potential tools/workflows, and feasibility notes.
Immediate Applications
These can be deployed today with off‑the‑shelf VLMs and the paper’s SimpleStream policy (e.g., 2–8 recent frames, typically 4f at ~1 fps), plus basic MLOps.
- Real-time smart cameras for retail and logistics (Retail, Logistics)
- Use cases: queue length monitoring, out-of-stock/shelf-gap detection, package orientation verification, barcode/label OCR in constrained views.
- Tools/workflows: RTSP/GStreamer ingest → frame sampling (N=4) → VLM inference → event/alert stream; integrate with existing VMS dashboards.
- Assumptions/dependencies: Sufficient OCR capability in chosen VLM; stable lighting; permissions for in-store analytics; 1–4 fps may suffice for slow scene changes.
- Industrial quality and safety monitoring at the edge (Manufacturing, Energy)
- Use cases: PPE detection, presence/absence checks, indicator/OCR readouts (gauges, screens), simple anomaly spotting in assembly lines.
- Tools/workflows: Edge accelerator (Jetson/TPU/GPU) + SimpleStream windowing microservice; on-device buffering avoids memory accumulation.
- Assumptions: Recent-window detection is adequate for most safety checks; latency and VRAM constraints match SimpleStream’s strengths.
- Sports and broadcast overlays (Media, Sports Tech)
- Use cases: real-time captioning, scoreboard OCR, player/ball localization for overlays, quick highlight triggers where precise long-term context is not required.
- Tools/workflows: Live ingest → last-N frames → VLM captions/labels → overlay compositor; optional Visual-RAG toggle for episodic queries.
- Assumptions: Short context suffices for overlays; legal rights for using VLMs in broadcast.
- Assisted-driving perception adjuncts (Automotive/ADAS prototyping)
- Use cases: lane marking presence, sign OCR, obstacle confirmation in stop-and-go or low-speed autonomy.
- Tools/workflows: Sensor fusion pipeline with a SimpleStream branch for robust OCR/object confirmation; acts as a secondary model for redundancy.
- Assumptions: Not safety-certified; must operate as advisory only unless validated; higher fps may be needed for fast motion.
- Robotics on-device perception (Robotics, Drones)
- Use cases: grasp target confirmation, tool-in-hand verification, navigation waypoint cues, immediate scene description for teleop.
- Tools/workflows: ROS node providing “recent-frame VLM” service; dynamic N (2–8) based on compute budget; quantized models for edge.
- Assumptions: Works best for recognition and short-horizon tasks; low VRAM profile is ideal for onboard compute.
- Hospital operations and facility monitoring (Healthcare operations—not diagnostic)
- Use cases: equipment presence checks, signage OCR (room numbers), occupancy/bed availability indicators, fall risk zones monitoring (with caution).
- Tools/workflows: Privacy-preserving deployment with short-window inference (no long-term storage by default); only structured alerts logged.
- Assumptions: Not for clinical diagnosis; stringent privacy/compliance; short-window design reduces retention risk.
- Live content moderation for streams (Online Platforms)
- Use cases: logo/brand detection, basic policy-violating object presence checks, text-on-screen moderation.
- Tools/workflows: Distributed inference with last-N frames; rule-based moderation pipeline.
- Assumptions: Complex spatiotemporal policy violations may need additional logic; high recall demands careful calibration.
- AR/VR real-time assistants (Consumer, Enterprise AR)
- Use cases: read signage/labels, object naming, immediate spatial cues for overlays.
- Tools/workflows: On-device or proximate edge server; SimpleStream with small window to minimize latency and energy.
- Assumptions: Works best in well-lit, near-field settings; model size and battery constraints.
- Smart home cameras with lower privacy risk (Consumer IoT)
- Use cases: door-step package confirmation, pet activity summaries, basic safety alerts without long-term memory storage.
- Tools/workflows: Local inference; store only alerts; no persistent memory module aligns with privacy expectations.
- Assumptions: Consumer-grade hardware; robust performance under varied illumination.
- Cost-efficient cloud inference routing (Software/Cloud)
- Use cases: reduce per-session token/state footprint, flatten memory growth across long sessions, control TTFT at scale.
- Tools/workflows: “Recent-window adapter” for VLM APIs; autoscaling; dynamic frame sampling policy; pay-per-token optimization.
- Assumptions: Strong base VLM available; throughput and SLOs benefit from the stable VRAM profile.
- Evaluation and procurement standards (Policy, Standards Bodies, Enterprise IT)
- Use cases: mandating strong recency baselines and disaggregated metrics (perception vs memory) in RFPs and benchmarks.
- Tools/workflows: “Perception–Memory dashboard” reporting ΔP (real-time) and ΔM (memory) vs a SimpleStream baseline.
- Assumptions: Stakeholders adopt common protocol; clarity improves fair comparison and avoids paying for unnecessary complexity.
- Academic baselining and reproducible benchmarks (Academia)
- Use cases: course/benchmark kits that include SimpleStream as a default strong baseline; ablation templates for window size and Visual-RAG toggles.
- Tools/workflows: Open-source reference pipelines; standardized reporting sheets separating tracks; CI for ablations.
- Assumptions: Community uptake; models with compatible licenses for teaching.
- Field service and remote inspections (Utilities, Telecom)
- Use cases: label/plate OCR, presence checks on panels/connectors, immediate anomaly flags during live inspections.
- Tools/workflows: Mobile app streaming → edge SimpleStream inference → operator HUD with highlights.
- Assumptions: Intermittent bandwidth; short-window approach is resilient to packet loss.
- Finance/compliance floor monitoring (Finance, Corporate Security)
- Use cases: restricted device spotting, badge/zone compliance (visual cues only), occupancy patterns.
- Tools/workflows: On-prem deployment, minimal retention; rule-based alerts.
- Assumptions: Strict compliance/privacy; avoid long-term memory; human-in-the-loop review mandatory.
- Smart city traffic and parking analytics (Public Sector, Transportation)
- Use cases: lane obstruction detection, sign OCR, parking availability indicators.
- Tools/workflows: Edge nodes with SimpleStream; aggregate insights upstream for dashboards.
- Assumptions: Permits for public video; variable weather/lighting robustness.
- Streaming studio assistants for creators (Media Tools)
- Use cases: automatic lower-thirds, scene/subject tags, real-time “what’s on screen” cues for switching.
- Tools/workflows: OBS/NDI plugin + SimpleStream microservice; small N reduces latency for live production.
- Assumptions: Creative workflows tolerate occasional misses on long-term callbacks.
- MLOps governance for streaming AI (Enterprise AI Ops)
- Use cases: tracking perception vs memory trade-offs in production; setting guardrails to prevent retrieval-induced perception degradation.
- Tools/workflows: Canary rollouts toggling Visual-RAG; ΔP/ΔM monitoring linked to SLOs; dynamic window-size control.
- Assumptions: Telemetry and labeling pipelines exist; clear success metrics per task family.
- Education/classroom capture assistants (Education)
- Use cases: board OCR, slide key-point extraction, instructor action tags in real-time.
- Tools/workflows: Camera → SimpleStream → transcript/notes pipeline; minimal hardware.
- Assumptions: Institutional privacy policies; OCR quality for handwriting varies.
- Drone inspections (Construction, Agriculture)
- Use cases: immediate label reading, defect presence confirmation, signage checks in slow flyovers.
- Tools/workflows: Onboard or tethered edge compute; small-window inference aligns with limited power/compute.
- Assumptions: Slow maneuvers or hover preferred for 1–4 fps sampling; fast passes may require higher fps.
Long-Term Applications
These require further R&D, scaling, or validation to ensure reliability or to overcome the perception–memory trade-off documented in the paper.
- Recent-first, history-on-demand controllers (Software, Robotics)
- Concept: Gated retrieval/summary only when model uncertainty is high or question requires recall—minimizing perception dilution.
- Dependencies: Reliable uncertainty estimation; lightweight retrieval indexes; policy learning for when to invoke memory.
- Memory modules that preserve present-scene perception (Core AI, Hardware/AI Accel)
- Concept: Architectures or attention mechanisms that inject history without harming current perception (e.g., orthogonal attention heads, constrained KV mixing).
- Dependencies: Training/fine-tuning; architectural changes; compute for large-scale experiments.
- Dynamic window sizing policies (MLOps, Edge)
- Concept: Auto-tune N per task/model capacity/environment, based on observed ΔP/ΔM and latency budgets.
- Dependencies: Online performance monitoring; policy optimization; closed-loop control.
- Task-aware Visual-RAG with noise control (Multiple sectors)
- Concept: Retrieval policies that avoid spurious context for perception-heavy tasks and selectively enrich memory tasks (EPM/ASI-like).
- Dependencies: High-quality CLIP-like indexing; relevance calibration; privacy safeguards for stored frames.
- Benchmark and policy reform for streaming AI (Policy, Standards, Academia)
- Concept: New causal benchmarks separating perception, episodic memory, and hallucination robustness; procurement rules emphasizing disaggregated reporting.
- Dependencies: Community coordination; dataset curation; agreement on capability weights.
- Safety-critical certification pathways (Healthcare, Automotive, Industrial)
- Concept: Certify recent-window systems for constrained functions (e.g., advisory cues), with validated failure modes and guardrails.
- Dependencies: Formal verification, extensive field trials, explainability and audit trails.
- Privacy-first analytics with ephemeral context (Public Sector, Enterprise)
- Concept: Default stateless processing with verifiable “no-retention” modes and provable data minimization.
- Dependencies: Auditable pipelines; secure enclaves; differential logging frameworks.
- Energy-aware streaming AI (IoT, Green Computing)
- Concept: Exploit SimpleStream’s flat VRAM/TTFT to design low-power camera nodes; co-design with duty-cycled sensing.
- Dependencies: Hardware co-design; model quantization; thermal and power validation.
- Multi-camera recent-context fusion (Smart Buildings, Transportation)
- Concept: Fuse last N frames across cameras with spatial calibration for better current-scene understanding without long-term memory.
- Dependencies: Calibration infrastructure; synchronized ingest; scalable multi-stream inference.
- Human-in-the-loop recall escalation (Ops Centers, Security)
- Concept: Start with SimpleStream; if operator requests context, selectively pull historical clips or summaries.
- Dependencies: Retrieval infrastructure; UX for rapid context access; policy for retention and access control.
- Domain-adapted small-window fine-tuning (Sector-specific AI)
- Concept: Light fine-tuning to improve short-window performance in specialized domains (e.g., medical device panels, industrial gauges).
- Dependencies: Curated labeled data; compliant training workflows; license-permitted adaptation.
- On-device explainability for streaming VLMs (AI Safety, Compliance)
- Concept: Summaries highlighting which recent-frame evidence drove an output, helping operators trust low-memory systems.
- Dependencies: Saliency/attribution tooling for VLMs; UI integration; user studies.
Notes on Feasibility, Assumptions, and Dependencies
- Base model strength is pivotal: The reported gains rely on strong VLMs (e.g., Qwen2.5‑VL/3‑VL). Different backbones may need tuning to match accuracy.
- Window size and fps matter: 4 frames at ~1 fps often balances performance and efficiency, but fast actions may require higher fps or small N with higher sampling.
- Trade-off awareness: Adding long-range context or Visual-RAG can improve episodic recall but may degrade real-time perception; monitor ΔP/ΔM in production.
- Hardware and latency: SimpleStream’s flat VRAM and competitive TTFT favor edge deployments; quantization and TensorRT/OpenVINO backends can further help.
- Privacy and compliance: Short-window, no-memory designs reduce data retention risk; any retrieval or storage introduces additional obligations.
- Domain variability: OCR and recognition performance vary with lighting, language, fonts, and camera angles; domain adaptation may be needed.
- Licensing and governance: Check commercial use rights for chosen VLMs; implement logging, guardrails, and human oversight in regulated settings.
In summary, many real-world, perception-centric streaming video tasks can benefit immediately from a SimpleStream-style recent-window policy, reducing system complexity and cost. For tasks demanding long-horizon recall, future work should adopt recent-first, history-on-demand strategies and evaluation practices that explicitly measure—and mitigate—the perception–memory trade-off.
Glossary
- Action Sequence Identification (ASI): An evaluation track measuring whether a model can recognize and order actions over time. "EPM, ASI, and HLD denote Episodic Memory, Action Sequence Identification, and Hallucination Detection."
- attention dilution: A hypothesized failure mode where excessive context diverts the model’s focus away from the most relevant current evidence. "One plausible mechanism is attention dilution: when too much retrieved or summarized context is injected, the model may allocate capacity away from the most relevant recent evidence."
- attention tokens: The discrete token budget processed by transformer attention, often constrained in streaming settings. "limits on memory, attention tokens, and per-step computation."
- Backward Tracing: An OVO-Bench category focused on recalling and reasoning over previously observed content. "Backward Tracing and Real-Time Visual Perception categories"
- budgeted context management: Viewing streaming inference as selecting a bounded set of inputs under resource limits to answer each query. "causal, budgeted context management."
- causal constraints: Restrictions that allow conditioning only on past (not future) observations during streaming inference. "under causal constraints"
- causal observation protocol: An evaluation setting where the model answers using only information observed up to the query time. "under a causal observation protocol"
- CLIP-based index: A retrieval index built with CLIP embeddings to find similar visual chunks from history. "A CLIP-based~\citep{Radford2021CLIP} index over historical chunks is built offline;"
- disk-backed historical KV cache: Persisting key-value attention states on disk for later, query-conditioned reuse. "stores a disk-backed historical KV cache"
- Episodic Memory (EPM): An evaluation track targeting the recall of specific past events from the stream. "EPM, ASI, and HLD denote Episodic Memory, Action Sequence Identification, and Hallucination Detection."
- event-level tree: A structured memory that organizes past events hierarchically for efficient insertion and retrieval. "maintains an event-level tree whose insertion rule balances an explicit penalty with temporal distance, content similarity, and merge frequency"
- external-memory streaming systems: Methods that keep explicit, structured histories outside the model’s immediate context. "External-memory streaming systems maintain structured history online"
- Flash Memory: A fixed-size memory component with dedicated slots for global summaries and salient details in streaming systems. "Flash Memory with slots reserved for global summaries and salient frame details."
- Hallucination Detection (HLD): A track measuring whether a model avoids making unsupported or inconsistent claims. "EPM, ASI, and HLD denote Episodic Memory, Action Sequence Identification, and Hallucination Detection."
- hallucination robustness: The model’s ability to resist generating unsupported content despite misleading inputs. "primarily reflects hallucination robustness rather than episodic event recall."
- hierarchical memory: A memory design that maintains multi-level abstractions (e.g., coarse-to-fine) over stored information. "maintains a hierarchical memory view over the KV state"
- KV states: Transformer key-value caches that store past attention keys/values for reuse. "tokens or KV states"
- latent representations: Compressed hidden-state vectors that summarize visual information. "compression of visual and latent representations under bounded budgets."
- latent-memory approaches: Methods that maintain a learned, fixed-length state summarizing the observed stream. "latent-memory approaches learn a constant-length state"
- macro-average: Averaging metric computed equally over multiple tracks, regardless of track type. "OVO-Bench reports a macro-average over 12 tracks"
- memory bank: An explicit store of past features or tokens used to augment current context. "explicit memory banks"
- memory-centric context management: Approaches emphasizing how to preserve and reuse historical information during streaming. "memory-centric context management"
- observed prefix: The portion of the video stream available up to the current time step. "observed prefix of the video stream up to "
- off-the-shelf VLM: A pretrained vision-LLM used without architecture changes or additional training. "off-the-shelf VLM"
- OVO-Bench: A causal streaming video understanding benchmark with diverse tasks spanning perception and memory. "OVO-Bench contains 1,640 questions over 12 tasks"
- peak GPU memory: The maximum VRAM consumption during inference. "the lowest peak GPU memory"
- query-conditioned KV states: Key-value caches selectively loaded or used based on the incoming question. "loads query-conditioned KV states"
- Real-Time Visual Perception: An OVO-Bench category focused on understanding the current scene promptly and accurately. "Real-Time Visual Perception"
- recency-window: The number of most recent frames retained as input context for answering a query. "recency-window, model-scaling, and Visual-RAG ablations"
- retrieval-based methods: Techniques that store and later fetch historical representations relevant to a new query. "Retrieval-based methods retain past representations so they can be selected at query time."
- retrieval noise: Irrelevant or misleading information introduced by imperfect retrieval. "retrieval noise, abstract latent states, or large memory injection"
- sliding window: A rolling window of the latest frames used as the model’s input context. "Frames outside the sliding window are discarded"
- state-of-the-art performance: The highest reported performance among available methods at the time. "state-of-the-art performance"
- StreamingBench: A benchmark emphasizing real-time visual understanding across multiple task types. "For StreamingBench, we use the official real-time visual understanding subset"
- time to first token (TTFT): The latency until a model emits its first output token. "time to first token (TTFT)"
- Vision-LLM (VLM): A model architecture that jointly processes visual inputs and text to generate answers. "base VLM"
- Visual-RAG: Retrieval-augmented generation applied to visual streams by appending retrieved visual chunks to the input. "Visual-RAG ablations"
- working context : The bounded set of inputs the model conditions on at time during streaming inference. "bounded working context "
Collections
Sign up for free to add this paper to one or more collections.