- The paper reveals that agentic coding tasks incur token costs up to 1000× higher than single-turn tasks due to persistent context ingestion and redundant operations.
- The paper demonstrates that token efficiency varies significantly among LLMs, with models like GPT-5 consuming far fewer tokens compared to others by over 1.5 million tokens in similar tasks.
- The paper shows that cost prediction using self-estimation is challenging due to substantial underestimation and weak correlation with actual token usage, impacting cost transparency.
Systematic Analysis of Token Consumption in Agentic Coding Tasks
Introduction
The proliferation of agentic coding workflows utilizing frontier LLMs has dramatically escalated token consumption, presenting both economic and technical challenges for practitioners and system designers. "How Do AI Agents Spend Your Money? Analyzing and Predicting Token Consumption in Agentic Coding Tasks" (2604.22750) addresses three central questions: (1) What dominates the token expenditure in agentic coding tasks? (2) How do different LLMs compare in token efficiency under identical workloads? (3) Can token usage be reliably predicted prior to execution, enabling cost transparency and budget-aware deployment?
Token Consumption Patterns in Agentic Coding Tasks
Empirical analysis across eight frontier LLMs on SWE-bench Verified demonstrates that agentic coding tasks incur orders of magnitude higher token costs than both single-turn code reasoning (e.g., CRUXEval) and code chat (e.g., ShareGPT-style code feedback dialogs). The primary cost driver is input token accumulation due to persistent context ingestion, tool-based exploration, and repeated context reuse—even under token caching regimes.
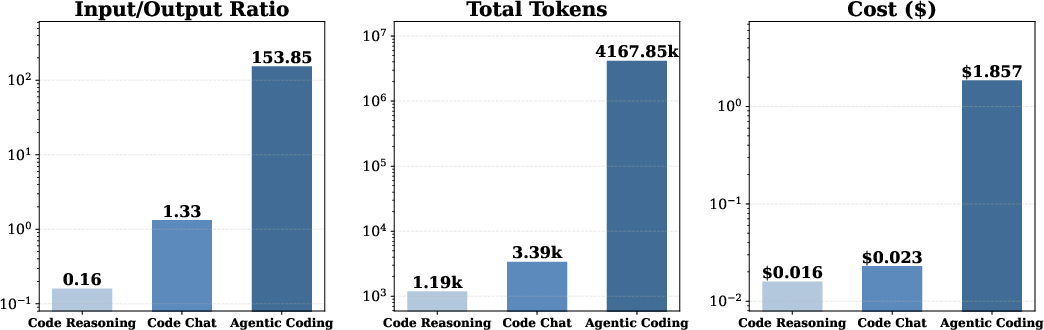
Figure 1: Agentic coding task token costs exceed code reasoning and code chat by 1000×, dominated by input token growth.
Token usage exhibits high stochasticity both across tasks and across repeated runs of the same problem; individual runs can vary by up to 30× in total tokens. The heaviest tail is observed in complex tasks, which also present the largest cross-run variance—making upfront cost prediction difficult.
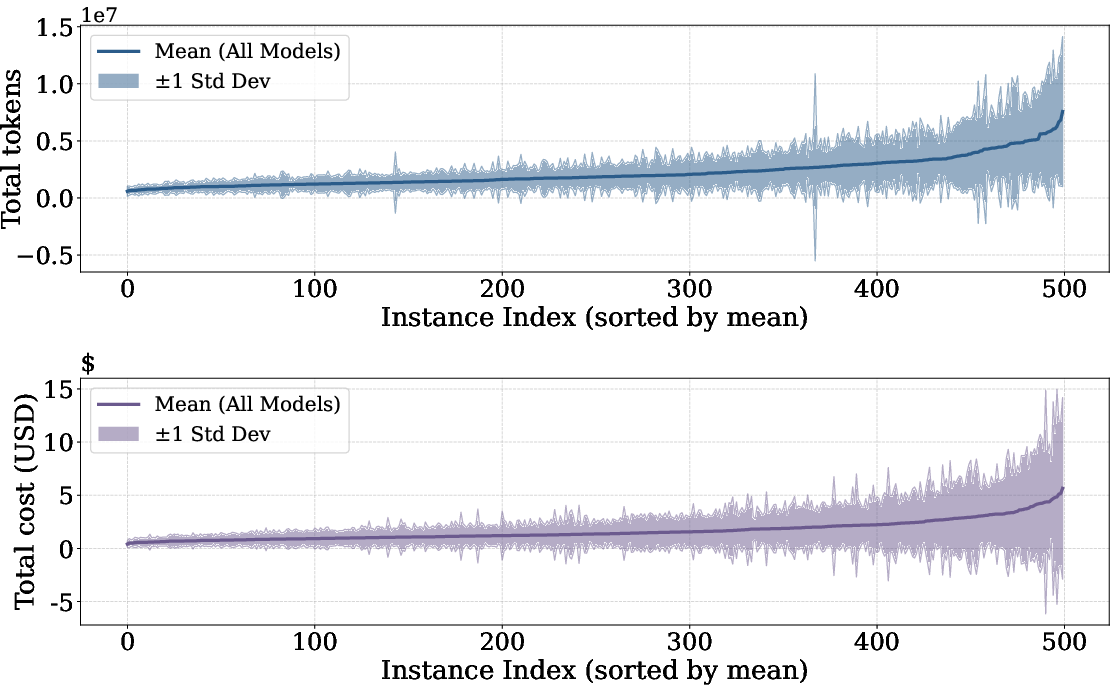
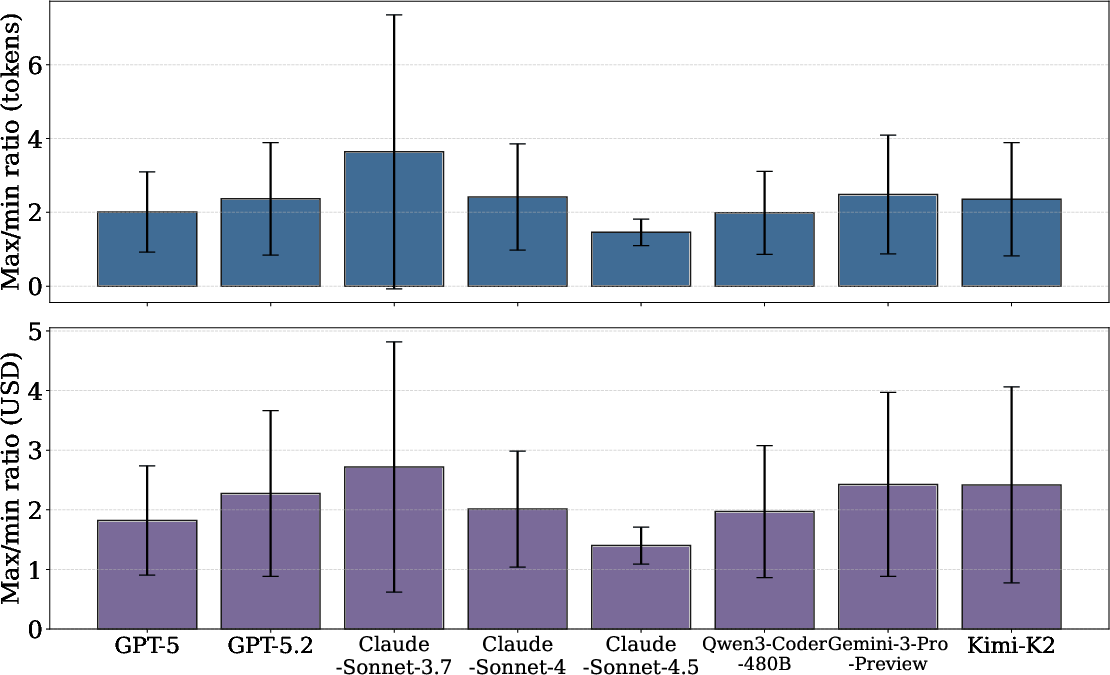
Figure 2: Token cost variance is substantial across problems and repeated runs, with high-cost tasks showing the greatest unpredictability.
Cost-Accuracy Dynamics and Behavioral Patterns
Scaling token expenditure does not monotonically improve agentic task accuracy. Aggregate results show that accuracy saturates or even declines at the highest cost regimes—reflecting inefficiency, redundancy, or ineffective exploration. Intermediate cost runs often peak in accuracy, consistent with empirical findings on inverse test-time scaling laws for reasoning agents.
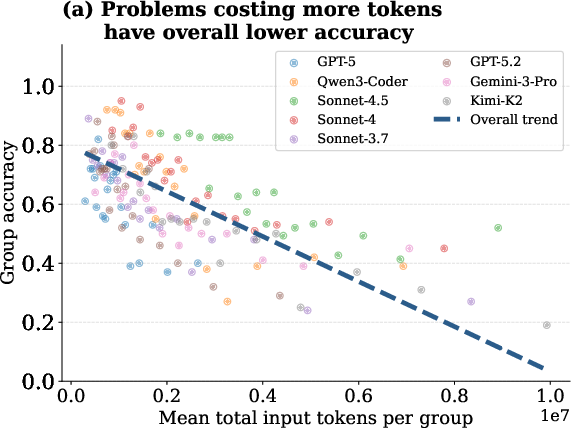
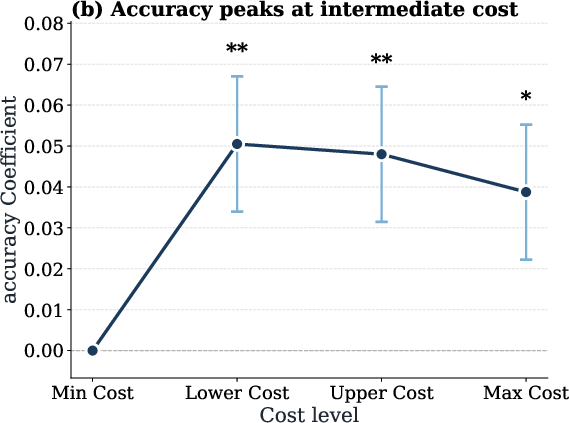
Figure 3: Task accuracy peaks at intermediate token cost and saturates or declines at higher costs across all evaluated models.
Detailed behavioral analysis reveals that high-cost runs are associated with frequent repeated views and modification actions on the same files, indicating unproductive redundancy and inefficient search patterns.
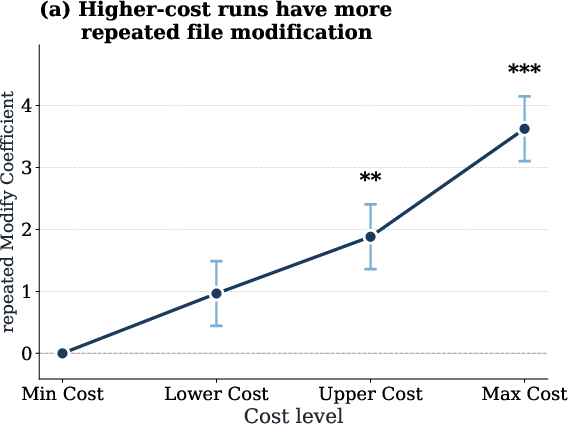
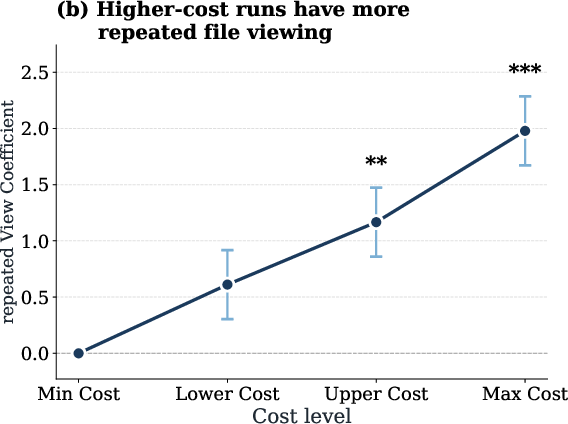
Figure 4: High token-cost runs correlate with increased repeated file access operations, driving up token consumption.
Human expert-rated task difficulty is only weakly correlated with agent token expenditure. The gap between perceived complexity and agent computational effort is statistically significant but modest (τb=0.32), with substantial distributional overlap.
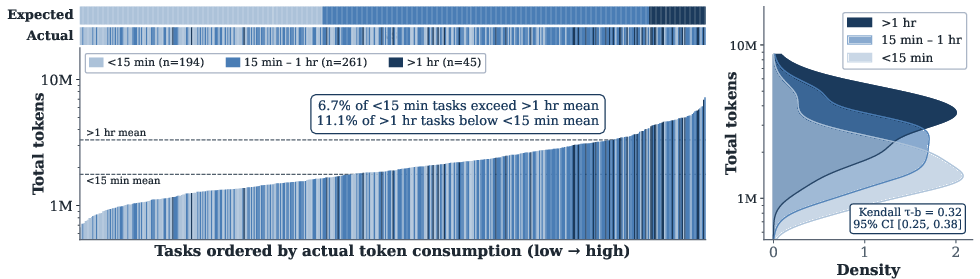
Figure 5: Human-assessed problem difficulty fails to reliably predict agent token consumption, highlighting a misalignment.
Token Efficiency of Frontier LLMs
Direct comparative evaluation reveals systematic differences in token efficiency between models. For identical tasks, models such as Kimi-K2 and Claude Sonnet-4.5 consume, on average, over 1.5 million more tokens than GPT-5. These efficiency differences persist even when restricting analysis to task subsets with universal success/failure, confirming that efficiency is primarily model-dependent rather than task-dependent.
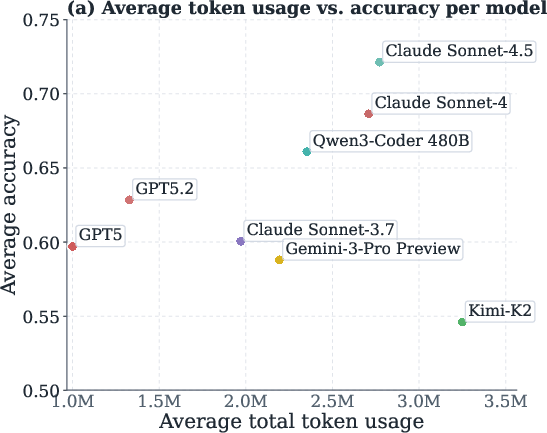
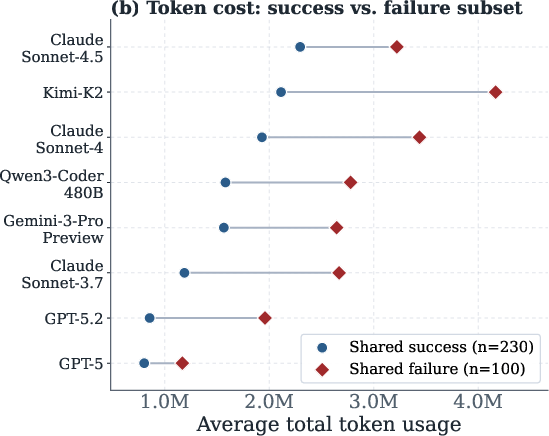
Figure 6: Model token efficiency varies intrinsically and consistently, regardless of task success/failure.
Token-inefficient models exhibit higher rates of exploratory actions (file viewing/modification), with a larger proportion of redundant operations.
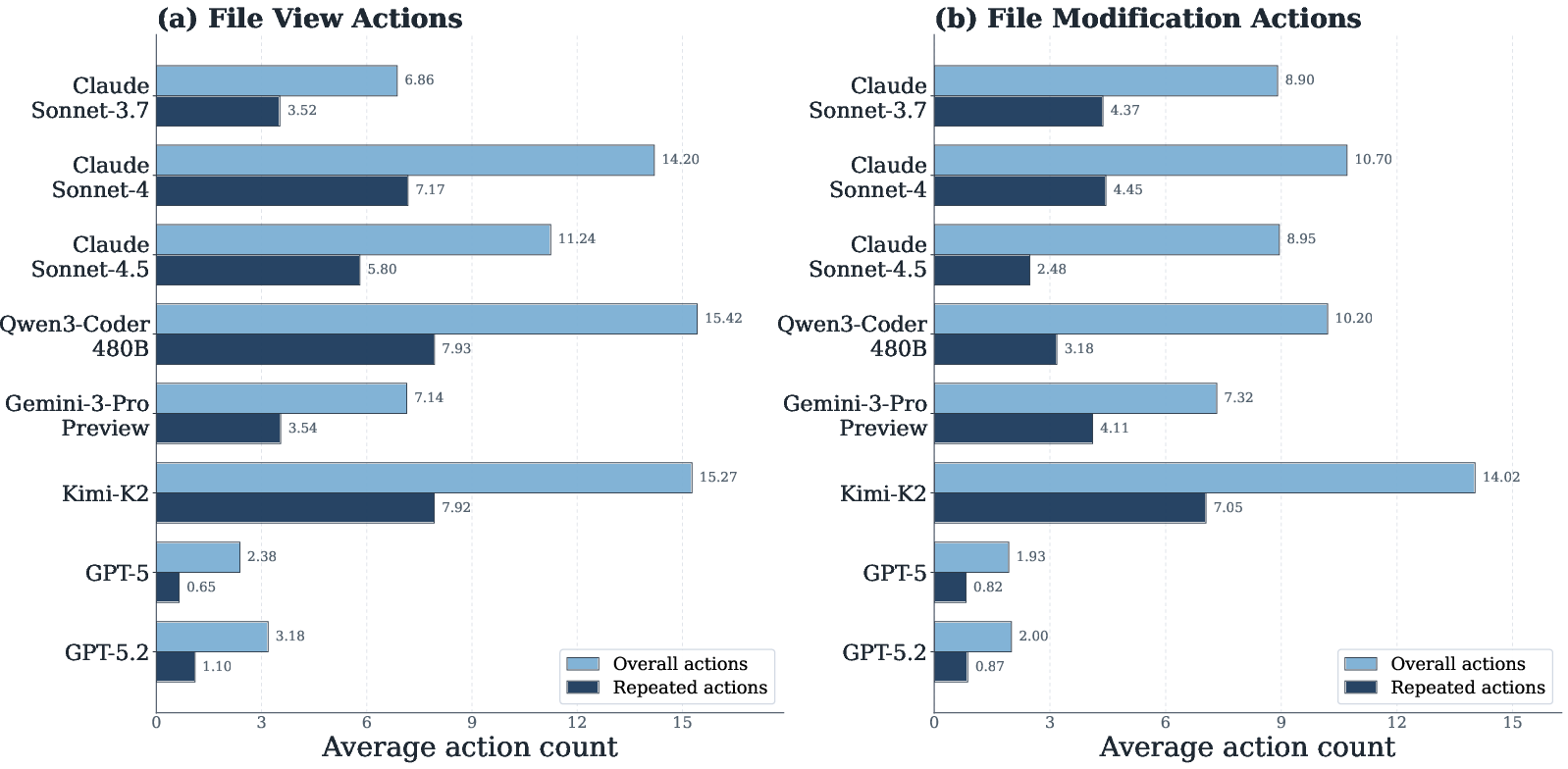
Figure 7: Fine-grained file action statistics indicate consistent inefficiency patterns across models.
Cost Dynamics Across Execution Phases
Phase-level and round-level analyses using Claude Sonnet-4.5 demonstrate that input tokens (especially cache-read tokens) dominate both total token volume and dollar cost throughout the agentic workflow. Despite steep discounts on cache reads, their cumulative volume can outweigh output token costs.
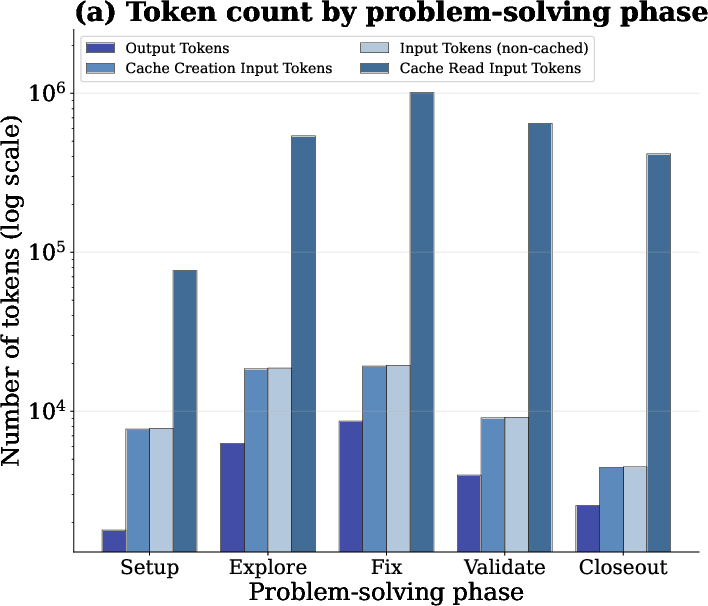
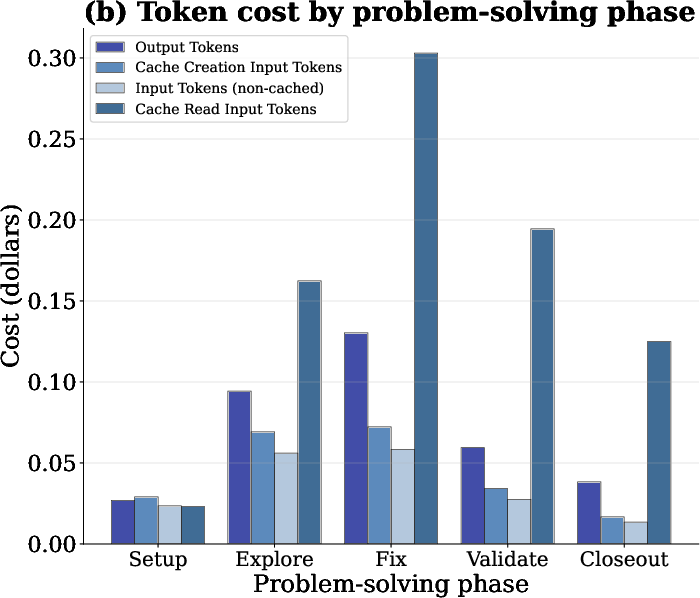
Figure 8: Input tokens—primarily cache reads—are the principal contributors to agentic task cost across all phases.
Cost spikes in trajectory execution are attributable to discrete actions such as new file views and test execution, which add new context.
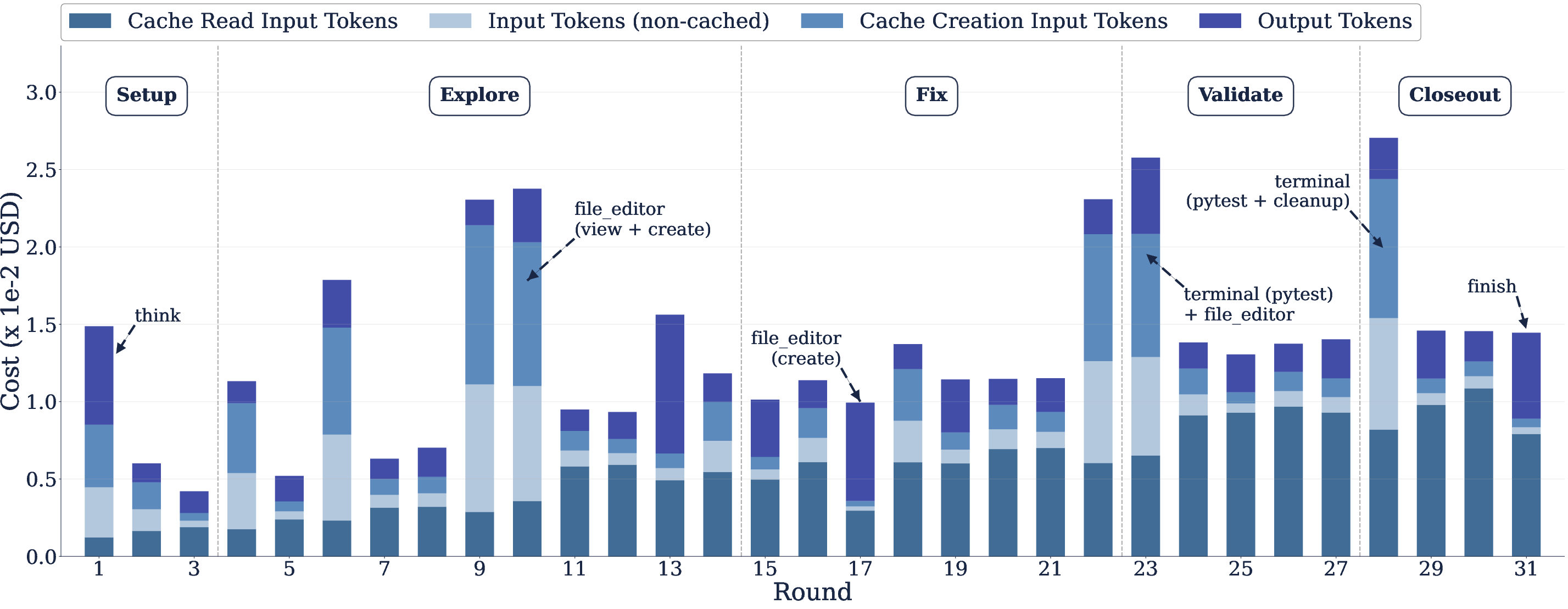
Figure 9: Round-level analysis demonstrates stable cache-read costs with expense spikes from specific actions.
Pre-execution Token Usage Prediction: Feasibility and Limitations
Self-prediction experiments task agents to estimate their own token consumption before execution, leveraging their full tool-calling and analysis capabilities. However, observed prediction correlations with actual token usage are weak-to-moderate (max ∼0.39 across tested models), with consistent systematic underestimation—especially for input tokens. Prediction overhead is generally lower than execution cost, but does not scale linearly with prediction accuracy.
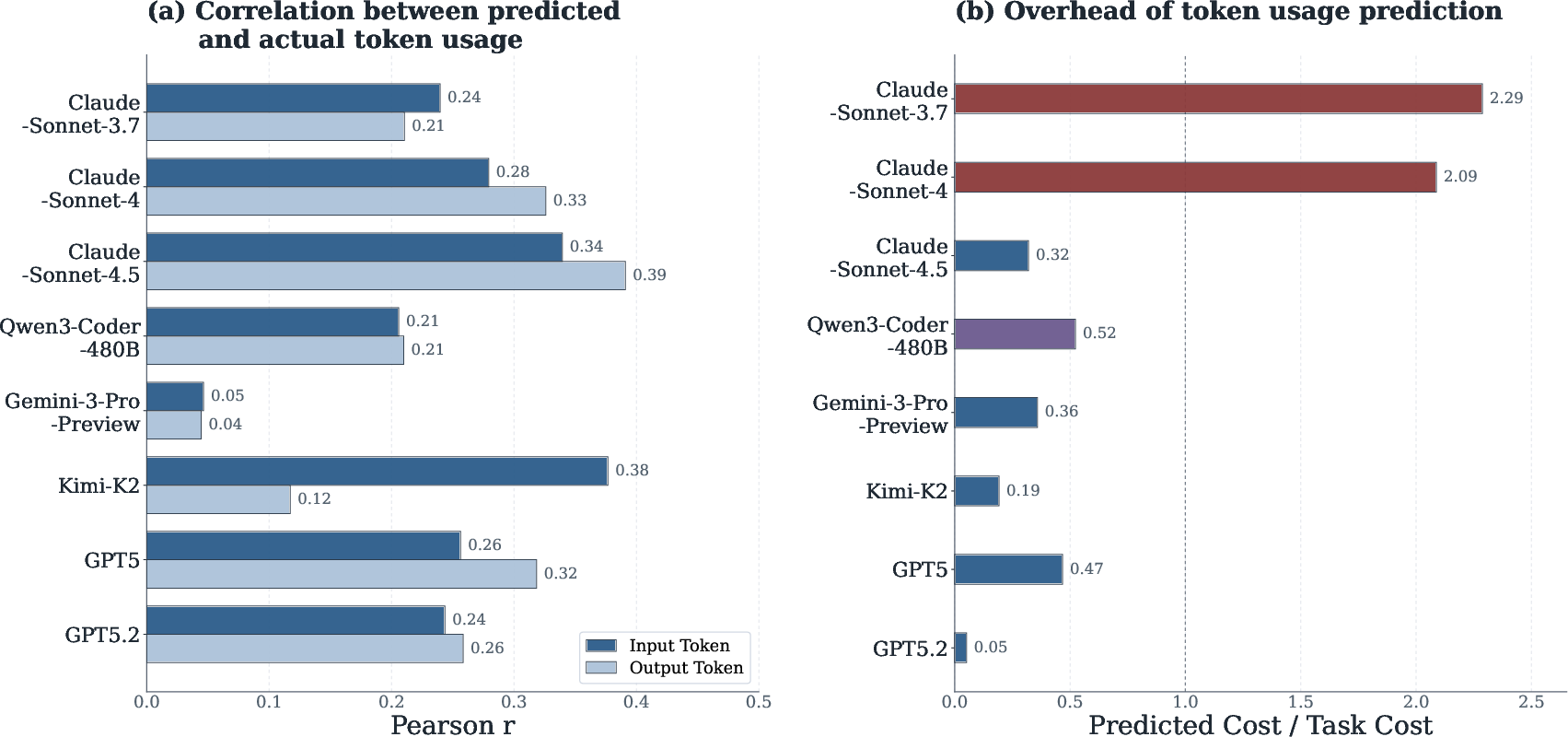
Figure 10: Prediction performance is modest; prediction overhead varies across models and is not strictly associated with accuracy.
Calibration plots confirm persistent underestimation of token usage for both input and output, regardless of model or in-context demonstration.
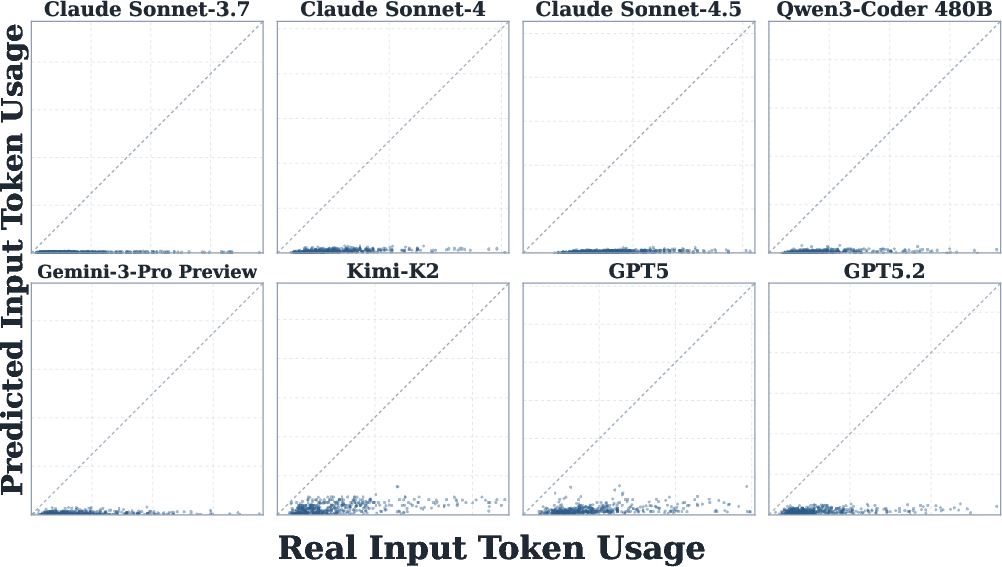
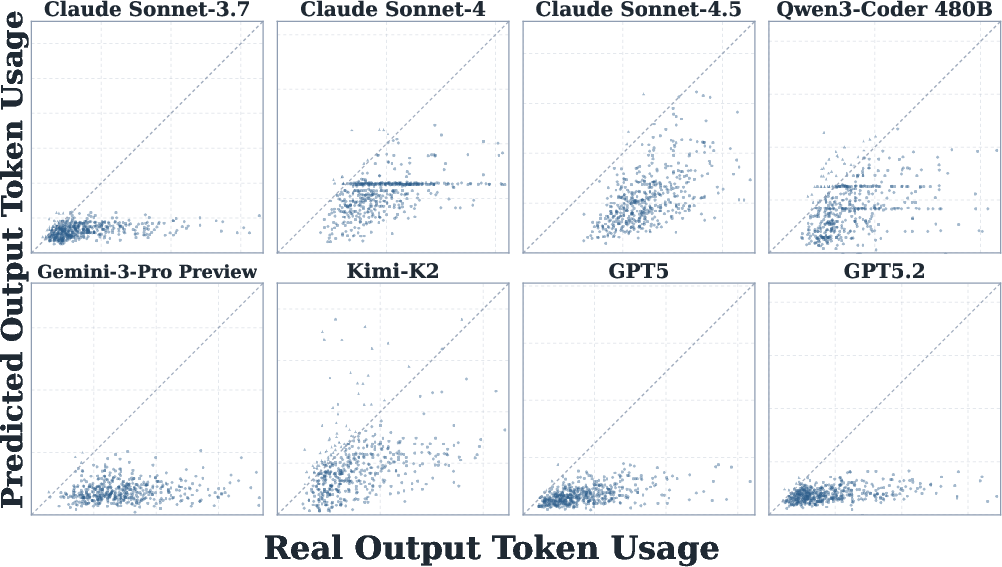
Figure 11: Agents systematically underestimate both input and output tokens in self-prediction.
Output Token Analyses
Supplementary analyses demonstrate that results using output tokens mirror those found for input tokens: higher output token expenditure correlates with reduced accuracy and increased redundant file operations.
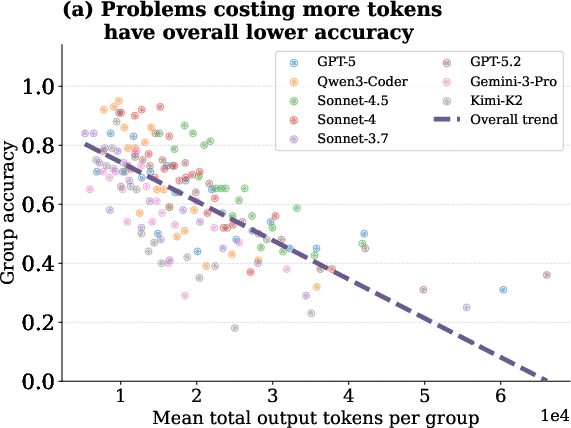
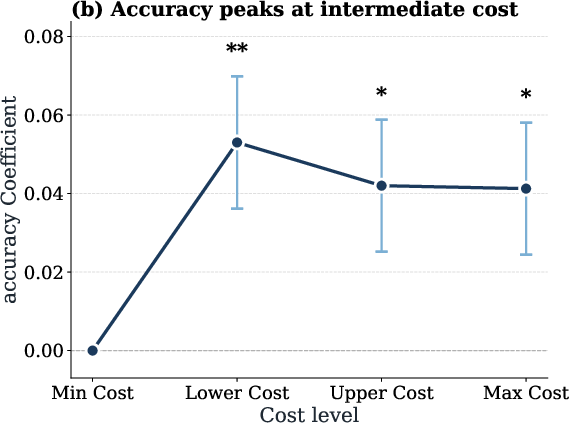
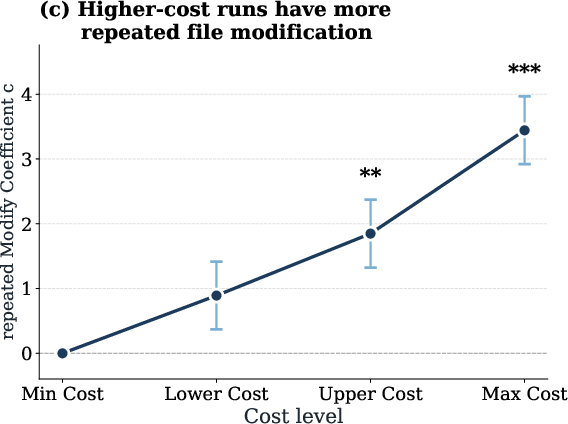
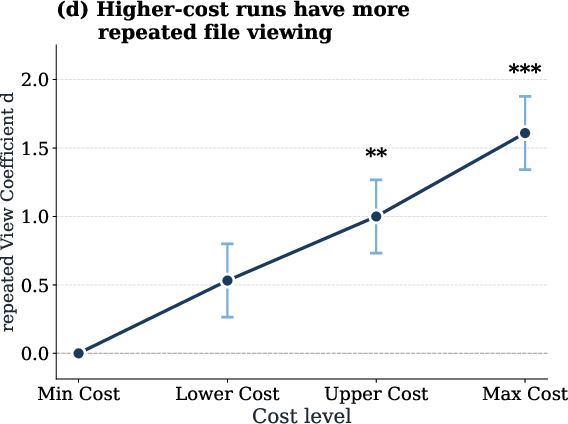
Figure 12: Excess output tokens do not improve accuracy and are linked to inefficient file interaction patterns.
Implications and Future Directions
The findings highlight several important implications:
- Transparency Gap: The unpredictability and stochasticity of token consumption in agentic workflows make fixed-price or upfront cost estimation currently impractical. Coarse-grained self-prediction can provide budgeting signals but lacks precision for instance-level pricing.
- Runtime Efficiency and Control: Model-specific inefficiencies necessitate deployment of budget-aware tool-use and runtime token constraint policies for cost control (Liu et al., 21 Nov 2025, Lin et al., 30 Oct 2025). More adaptive stopping and dynamic compute strategies are essential.
- Benchmarking and Strategy Design: Accurate agent benchmarking must account for token efficiency and behavioral redundancy, not just success rate. Energy-per-token and Green AI metrics merit further integration (Schwartz et al., 2019, Alomrani et al., 2 Jul 2025).
- Research Directions: Enhancements in agent memory management (Hu et al., 15 Dec 2025, Xiong et al., 21 May 2025), dynamic context evolution (Wan et al., 9 Oct 2025), and execution trajectory diagnosis (Barke et al., 2 Feb 2026) are promising venues. Formal modeling of cost variance and agent self-modeling may improve prediction reliability.
Conclusion
This systematic study elucidates the sources, dynamics, and predictability limits of token consumption in agentic coding settings. Token costs are dominated by input context, highly variable, and only weakly predictable both by models themselves and by expert perception. Model-level behavioral patterns drive efficiency differences independent of task difficulty. While current agents can provide coarse-grained cost signals, robust upfront prediction of execution tokens remains an open challenge, warranting continued research into adaptive and controllable agent deployments, runtime cost constraints, and transparent pricing schemes for real-world applications.

